范涛
发表于2017-04-08
主要分享下《Parallel Streaming Signature EM-tree: A Clustering Algorithm for Web Scale Applications》这篇文章。
15年末的时候,组内同事分享过这个算法,当时吸引大家眼球的是文章号称可以对亿级别的文档进行单机并行聚类,速度快并scalable,支持单机并行和分布式。当时我正好在做事件聚类相关的项目,十分需要一种能快速聚类海量文本的一种聚类工具。所以,后面就重点研究下这个算法,并做了点改进,让这个算法和Paragraph2vector进行结合起来,优势互补。现在重点介绍下这个算法。
EM-Tree算法核心步骤如下:
1 利用topsig为每篇文档生成一个signature(4096)来作为文档的向量表示
2 从聚类文档随机选出一个小集合,采用TSVD聚类,建一个m叉树,树深d的聚类树(每一层节点都做一次聚类,聚类数为m,形成子节点,最后文档都在树的叶子节点上,树的中间节点存放的是每个类的中心向量)。
3 以下为循环,直到算法收敛:
3.1 读取每一篇文档,每一次从树的根结点向下选一个离这篇文档最近的结点的分支,直到叶子结点。
3.2 进行剪枝,去掉没有叶子的结点
3.3 从底向上进行update,更新中心点
4 聚类结束,每篇文档在深度为d,m叉树的每一层都可以一个聚类中心,所以可以根据需要和分析结果,划分不同的聚类方式。
算法的优势: 速度快(300w样本,大约时间控制40-60分钟之间),可并行和分布式;EM-Tree的框架可以应用到很多场景。我觉得好的设计模式是把文档表示独立出来,EM-Tree支持多种文档表示。
缺点:和kmeans算法类似, 如果样本类别不均衡分布,对小类别的样本聚类效果不好。解决的办法增加树的m值或者深度d。
改进: EM-Tree算法文档的默认支持方式是用哈希签名的方法,个人觉得这种文档签名方式不够准确,用之前分享的Paragraph2vector技术(在文档表示上效果较好)来替换EM-tree文档默认签名方式。下面在一些分类文档的上的聚类实验效果:
附录1:
在原有的EM-Tree聚类算法源码基础上修改的代码放在github上,
github路径:https://github.com/dylan-fan/paragraph2vector_emtreecluster
附录2:聚类评估常用方法
1:内部质量评价
样本无类别标记。根据类内相似度和类间距离。

其中,k为最终的聚类数, 表示聚类簇,
表示聚类簇, 表示聚类v的质心,d 是距离函数。(1)表示聚类的类簇的内差和,(2)表示整个聚类的类簇间的距离和,(3)表示聚类的总体质量:类簇间的距离和与类内距离的之比来衡量。总的来说:对于相同数据集,类簇间的距离越大,类内的距离越小,聚类质量相对越好,也就是总体质量值越大。
表示聚类v的质心,d 是距离函数。(1)表示聚类的类簇的内差和,(2)表示整个聚类的类簇间的距离和,(3)表示聚类的总体质量:类簇间的距离和与类内距离的之比来衡量。总的来说:对于相同数据集,类簇间的距离越大,类内的距离越小,聚类质量相对越好,也就是总体质量值越大。
2:外部质量评价
样本有类别标记。当样本本身含有类别标记的时候,我们就可以根据类别标记来衡量聚类后的结果准确性相关指标。指标含有(1)簇纯度pure;(2)F1-measure等。
2.1 类簇纯度Purity
对于聚类形成后的任意类别r,聚类纯度定义为:
 (4)
(4)
整个聚类结果的纯度定义为:
 (5)
(5)
这里, 是属于预定类i且被分配到第r个聚类的文档个数,
是属于预定类i且被分配到第r个聚类的文档个数, 为第r个聚类类别中的文档个数。
为第r个聚类类别中的文档个数。
同一数据集,Purity值越大,聚类效果相对越好。
2.2 类簇F1-measure
类簇F1-measure的定义结合准确率和召回率的。对于聚类后聚类类别r和原来预定的类别i,
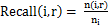 (6)
(6)
 (7)
(7)
F1-measure(i,r) = 2 * Recall(i,r) * Precision(i,r)/ (Recall(i,r) + Precision(i,r)) (8)
其中,n(i,r) 表示聚类r中包含预定义类别i的文档个数, 表示聚类r的文档个数,
表示聚类r的文档个数, 表示预定义类的文档个数。
表示预定义类的文档个数。
最终聚类结果的评价函数:
 (9)
(9)
同一数据集,F1值越大,聚类效果相对越好。
参考文献
De Vries C M, De Vine L, Geva S, et al. Parallel Streaming Signature EM-tree: A Clustering Algorithm for Web Scale Applications[J]. Computer Science, 2015:216-226.
