视频游戏的发布受到游戏剧情的困扰。 从误导性的预购套装到发布时远未完成的游戏,大型发布商在决定游戏的发布方式和时间方面存在相当大的风险。 我认为这可能是一个有趣的项目,可以看到游戏周围的情绪如何变化,而AAA冠军Anthem是这个小项目的完美游戏。 (作为一个FYI,我在2月22日官方正式发布之前写这篇文章)
在我们开始之前,Anthem有一个独特的发布时间表,可能会影响个人对游戏的看法。
Anthem从2月1日星期五到2月3日星期日进行了“演示周末”
Anthem于2月15日星期五为EA Access的成员推出了“Early”
Anthem于2月22日正式面向所有人推出
让我们开始吧!
我会尽力描述我在使用过程中使用的所有软件包,但这里的参考是我的导入语句!
%matplotlib inline
from twitterscraper import query_tweets
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
import datetime as dt
import pandas as pd
from langdetect import detect
import matplotlib.pyplot as plt
import seaborn as sns
analyzer = SentimentIntensityAnalyzer()
- Scraping Twitter Data
有一百万种从twitter获取数据的方法,但我选择使用twitterscraper by taspinar, 这是beautifulSoup的包装,可以轻松获取推文。 我喜欢这个软件包,因为你不仅要避免从twitter请求API密钥,还因为webscraper没有twitter的API的任何限制。
With
from twitterscraper import query_tweets
, getting all the tweets I needed was simple.
begin_date = dt.datetime.strptime("Jan 15 2019", "%b %d %Y").date()
tweets = query_tweets("#Anthem OR #AnthemGame",begindate=begin_date)
这需要一些时间…所以在你等待的时候去解决一个据点! 当你完成后,你应该有一个很好的twitterscraper对象列表。
print(len(tweets))
102418
关于Anthem的102,418条推文!
Twitterscraper对象有一个易于使用的__dict__方法,它返回字典形式的推文所需的所有数据。
tweets[1].__dict__
{'user': '_WECKLESS',
'fullname': 'WECKLESS™',
'id': '1085323189738192897',
'url': '/_WECKLESS/status/1085323189738192897',
'timestamp': datetime.datetime(2019, 1, 15, 23, 49, 47),
'text': 'Here is my GIF #AnthemGame pic.twitter.com/jCNjiWQnmJ',
'replies': 0,
'retweets': 0,
'likes': 2,
'html': '<p class="TweetTextSize js-tweet-text tweet-text" data-aria-label-part="0" lang="en">Here is my GIF <span class="twitter-hashflag-container"><a class="twitter-hashtag pretty-link js-nav" data-query-source="hashtag_click" dir="ltr" href="/hashtag/AnthemGame?src=hash"><s>#</s><b><strong>AnthemGame</strong></b></a><a dir="ltr" href="/hashtag/AnthemGame?src=hash"><img alt="" class="twitter-hashflag" draggable="false" src="https://abs.twimg.com/hashflags/AnthemGame_Anthem/AnthemGame_Anthem.png"/></a></span> <a class="twitter-timeline-link u-hidden" data-pre-embedded="true" dir="ltr" href="https://t.co/jCNjiWQnmJ">pic.twitter.com/jCNjiWQnmJ</a></p>'}
我们可以看到这个字典有用户名,独特的推文ID,回复数量,转发数量,以及推文的喜欢,最重要的是推文的文字! 我们会将所有这些推文放入pandas数据框中,以便它们易于使用! (此时我还将我的推文保存到一个文件中,所以如果我想重新运行我的分析,我就不必再次通过webscraping过程了。)
tweet_list = (t.__dict__ for t in tweets)
df = pd.DataFrame(tweet_list)
这是我们的新数据帧的样子!


请注意一些推文不是英文的。 我们将在下一步处理这个问题!
- Language and Sentiment Analysis
我们将在下一步中解决两件事。 首先请注意我们的所有推文都不是英文的? 虽然我们可以翻译我们的推文并尝试从他们那里得到一些情绪,但我认为删除非英语的推文会更容易和更清晰。 为此,我们需要使用其语言标记每条推文。 不用担心,这是一个图书馆! Langimtect by Mimino66的检测功能是我们识别推文语言所需要的全部内容。 我们可以使用langdetect import detect加载必要的功能
我们将在数据框中创建一个新列,方法是将detect()函数映射到我们的文本数据上,然后只保留英文的推文。
df['lang'] = df['text'].map(lambda x: detect(x))
df = df[df['lang']=='en']
当这一步完成后,我只剩下77,740条推文。
现在,我们可以开始在我们的推文上运行一些文本分析。VADER Sentiment Analysis 是一个流行的python包,用于获取一段文字的情感,它特别适合社交媒体数据,并准备开箱即用!
我们需要导入它的SentimentIntensityAnalyzer并初始化它。
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
VADER将为您传递的任何文本返回4分的字典; 积极,中性,负面和复合得分,均为-1到1.我们最感兴趣的是跟踪推文整体情绪的复合得分。
从这里开始,我们制作了一系列新数据,其中包含了我们推文文本的情感,并将其与原始数据框连接起来。
sentiment = df['text'].apply(lambda x: analyzer.polarity_scores(x))
df = pd.concat([df,sentiment.apply(pd.Series)],1)
这是我们的最终数据框架的样子。 我们可以看到我们的推文是英文的,每个推文都有一组与之相关的情绪分数。

- Analyzing Sentiment
首先,让我们调用df.describe()并获取有关我们数据集的一些基本信息。
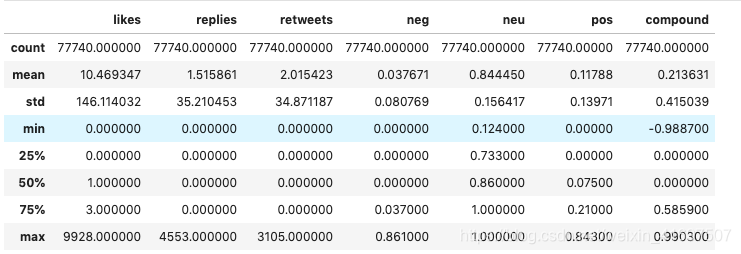
我们有77,740条推文,平均10条赞,35条回复和2条转推。 看看复合得分我们可以看到平均推文是正面的,平均情绪为.21。
绘制这些数据可以让我们更好地了解它的外观。 在我们绘制之前,我对我的数据框进行了一些更改以便于使用,按时间戳对所有值进行排序,使它们按顺序排列,将时间戳复制到索引以使绘图更容易,并计算复合情绪的扩展和滚动平均值分数。
df.sort_values(by='timestamp', inplace=True)
df.index = pd.to_datetime(df['timestamp'])
df['mean'] = df['compound'].expanding().mean()
df['rolling'] = df['compound'].rolling('6h').mean()
现在使用matplotlib,导入matplotlib.pyplot作为plt,我们可以创建一个快速的推文图表及其随时间推移的情绪。
fig = plt.figure(figsize=(20,5))
ax = fig.add_subplot(111)
ax.scatter(df['timestamp'],df['compound'], label='Tweet Sentiment')
ax.plot(df['timestamp'],df['rolling'], color ='r', label='Rolling Mean')
ax.plot(df['timestamp'],df['mean'], color='y', label='Expanding Mean')
ax.set_xlim([dt.date(2019,1,15),dt.date(2019,2,21)])
ax.set(title='Anthem Tweets over Time', xlabel='Date', ylabel='Sentiment')
ax.legend(loc='best')
fig.tight_layout()
plt.show(
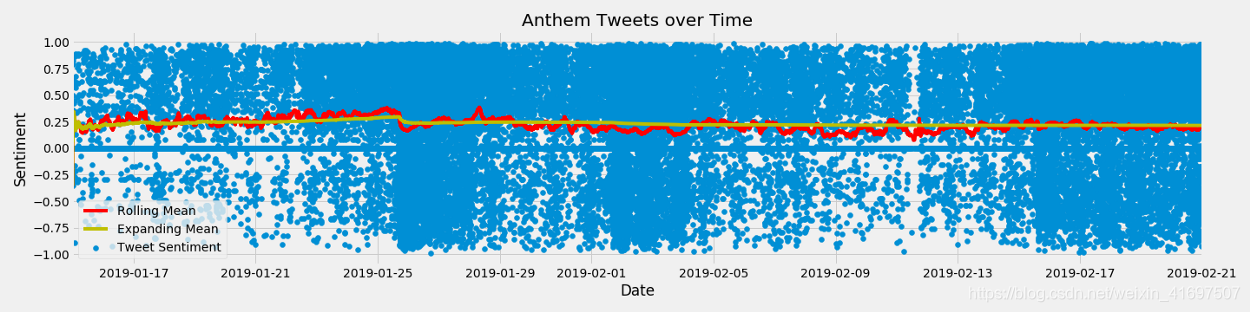
我们可以在这里注意到一些有趣的事情。
有很多推文的情绪评分为0。
我们有很多数据。
我们的数据中的平均值似乎有些稳定,除了第25位,负面推文有所增加,扩张均值受到严重影响。
似乎有更高密度的区域发生了更多的推文。 我们将看看我们是否可以将这些与游戏发布周围的事件联系起来。
我们试着在这里一次解决一件事。 首先让我们看看那些情绪为0的推文.Seborn的distplot是一种快速查看我们推文中情绪分数分布的方法。
fig = plt.figure(figsize=(10,5))
ax = fig.add_subplot(111)
sns.distplot(df['compound'], bins=15, ax=ax)
plt.show()
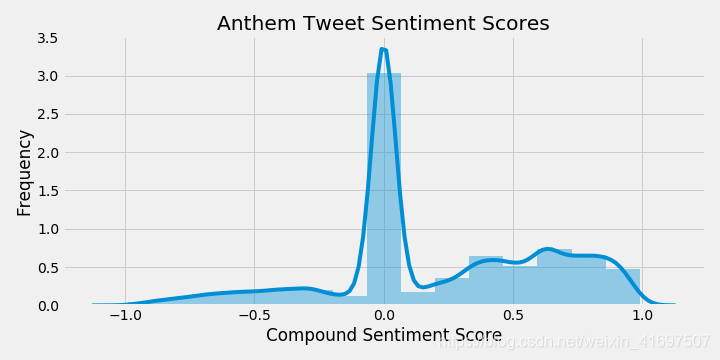
超过30%的推文都有0的情绪。
我选择暂时将这些推文留在我的数据集中。 但值得注意的是,如果不包括这些,平均情绪会高得多。
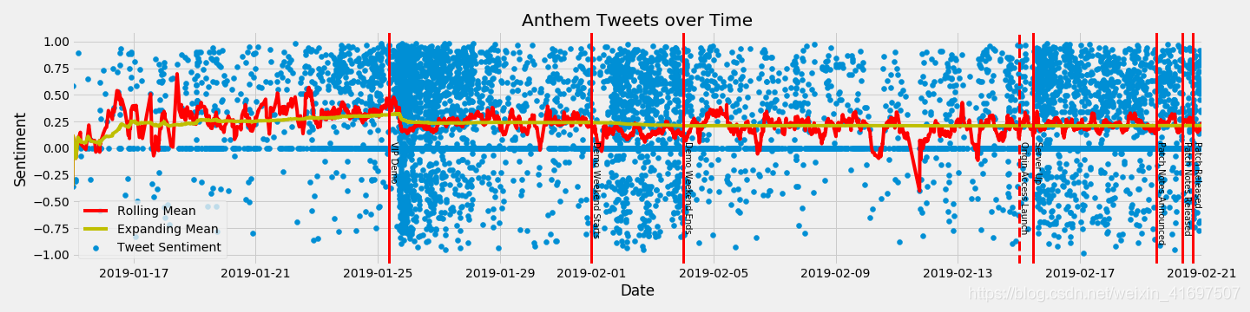
让我们看看我们是否可以随着时间的推移更清楚地了解我们的情绪。 总的来说,我们的数据很嘈杂,而且数据太多了。 对我们的数据进行抽样可能会更容易看到趋势的发生。 我们将使用pandas sample()函数来保留我们77,740条推文中的十分之一。
ot = df.sample(frac=.1, random_state=1111)
ot.sort_index(inplace=True)
ot['mean'] = ot['compound'].expanding().mean()
ot['rolling'] = ot['compound'].rolling('6h').mean()
我按日期重新排序并为我们的数据计算新的扩展和滚动平均值并绘制新数据集。

这个图表要好得多,让我们能够实际看到随着时间推移情绪的下降和趋势。 现在剩下要做的就是弄清楚导致情绪变化的原因。
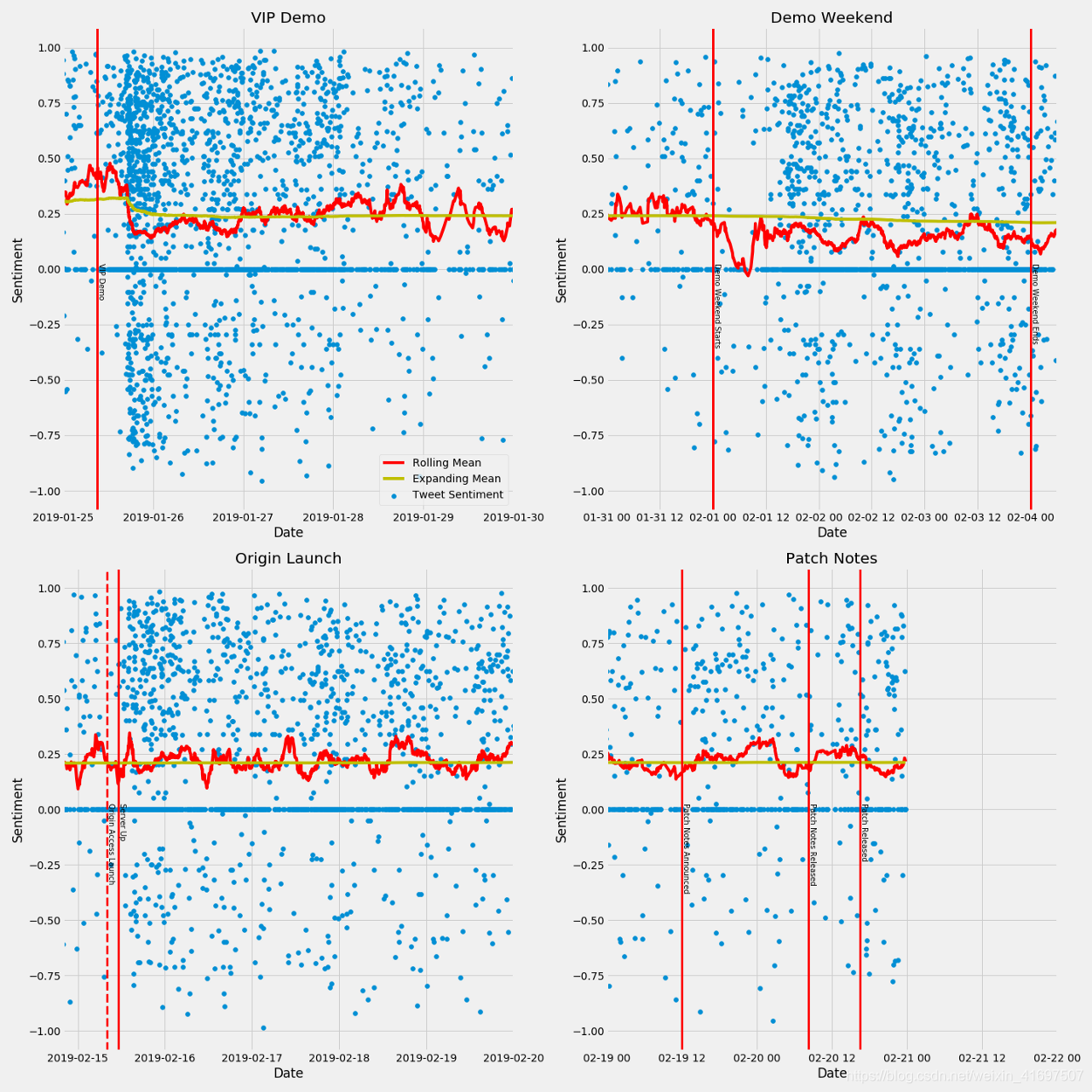
我在本文开头提到了一些关于Anthem发布的重要说明。 让我们在图表中添加一些重要日期,看看它们是否符合我们数据的趋势。
Anthem在2月1日到2月3日举行了“免费演示周末”。
Anthem于2月15日为Origin Access会员上线。
Anthem在2月15日发布后不久就发布了服务器问题,上午7:30发布到他们的Twitter帐户,这些问题得到了解决,EA在上午11:06发布了Twitter帖子。
EA Released在19日发布了第一天补丁,20日上午8:13发布了完整补丁说明,补丁在当天下午4:27发布。
使用.axvline()和.text()添加一些行我在这里结束了这个图。
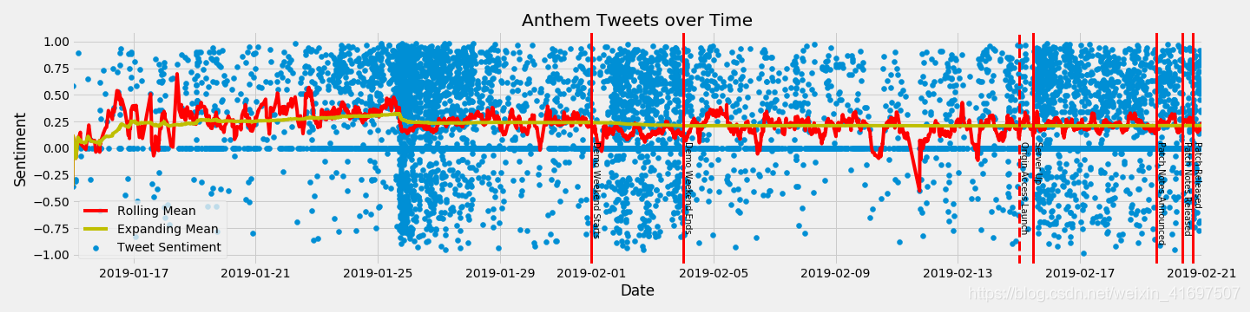
这些线可能不完美排列,因为我不确定每个版本的“官方”时间。
我们可以看到两个大型推文集合与游戏发布同时发生,包括“演示周末”和Origin Access发布。
此外,我们可以看到在演示周末期间情绪下降。演示周末的平均情绪为.138,而演示周末之前的同期平均情绪为.239。
您还可以快速注意到1月下旬有另一组推文没有下载。通过Twitter快速滚动我发现这实际上是一个VIP演示周末,它也遇到了服务器问题,加载时间过长以及需要多个补丁修复。这恰好与情绪的显着下降同时发生。我们还将该行添加到我们的图表中并创建一些子图,以便我们详细了解一些单独的事件。
以下是图表的最终代码,其后是图表本身。
fig = plt.figure(figsize=(20,5))
ax=fig.add_subplot(111)
ax.scatter(ot['timestamp'],ot['compound'], label='Tweet Sentiment')
ax.plot(ot['timestamp'],ot['rolling'], color ='r', label='Rolling Mean')
ax.plot(ot['timestamp'],ot['mean'], color='y', label='Expanding Mean')
ax.set_xlim([dt.date(2019,1,15),dt.date(2019,2,21)])
ax.set(title='Anthem Tweets over Time', xlabel='Date', ylabel='Sentiment')
ax.legend(loc='best')
#free demo weekend
ax.axvline(x=dt.datetime(2019,2,1) ,linewidth=3, color='r')
ax.text(x=dt.datetime(2019,2,1), y=0, s='Demo Weekend Starts', rotation=-90, size=10)
ax.axvline(x=dt.datetime(2019,2,4) ,linewidth=3, color='r')
ax.text(x=dt.datetime(2019,2,4), y=0, s='Demo Weekend Ends', rotation=-90, size=10)
#origin access launch
ax.axvline(x=dt.datetime(2019,2,15) ,linewidth=3, color='r', linestyle='dashed')
ax.text(x=dt.datetime(2019,2,15), y=0, s='Origin Access Launch', rotation=-90, size=10)
#server fix
ax.axvline(x=dt.datetime(2019,2,15,11,6) ,linewidth=3, color='r')
ax.text(x=dt.datetime(2019,2,15,11,6), y=0, s='Server Up', rotation=-90, size=10)
#patchnotes announced
ax.axvline(x=dt.datetime(2019,2,19,12) ,linewidth=3, color='r')
ax.text(x=dt.datetime(2019,2,19,12), y=0, s='Patch Notes Announced', rotation=-90, size=10)
#patchnotes released
ax.axvline(x=dt.datetime(2019,2,20,8,13) ,linewidth=3, color='r')
ax.text(x=dt.datetime(2019,2,20,8,13), y=0, s='Patch Notes Released', rotation=-90, size=10)
#patch realeased
ax.axvline(x=dt.datetime(2019,2,20,16,27) ,linewidth=3, color='r')
ax.text(x=dt.datetime(2019,2,20,16,27), y=0, s='Patch Released', rotation=-90, size=10)
#vip weekend
ax.axvline(x=dt.datetime(2019,1,25,9,0) ,linewidth=3, color='r')
ax.text(x=dt.datetime(2019,1,25,9,0), y=0, s='VIP Demo', rotation=-90, size=10)
fig.tight_layout()
plt.show()
这些线路可能并不完美,因为我不确定每次发射的“官方”时间。
这里是添加了VIP Demo的更大图表。
我们的最终图表显示了一些有趣的事情。首先,VIP演示对情绪产生了最重要的影响。显然,个人对VIP演示的所有问题感到不满。
公开演示周末也表现出明显的情绪下降。这两个都是有趣的案例,其中开发者决定允许公众在完全测试之前玩游戏。一方面,开发人员和发布者正在获得有关游戏,服务器容量和需要修复的错误的宝贵反馈。问题是,这是否以围绕游戏的情绪为代价?
也许不是!我们可以看到,当EA Access发布时,情绪已经恢复到原来的水平(尽管从未像VIP之前的演示情绪一样高。)
游戏开发商和发行商需要权衡将公众行为作为早期游戏发布的beta测试者与公众视野中的游戏感知的价值。如果演示周末作为“测试版”周末销售,也许个人情绪会更高。
总而言之,这是一个有趣的项目,相同的分析可以应用于各种事物,政治,电影等。现在我想我将从统计数据中休息一下,然后在我的标枪中进行飞行。