4.Pig
Exercise 1 Working with Pig
Lab 1 Working with Pig
这个练习让您有机会学习一些基本的Pig知识,以便开始熟悉这个环境。
在完成这个动手实验之后,您将能够:
-从Grunt shell执行Pig语句
-执行Pig脚本
-将参数传递给Pig脚本
-加载在Pig中使用的数据
给10分钟来完成这个实验。
这个版本的实验室是使用InfoSphere BigInsights 2.1 Quick Start版本设计的,但是已经在2.1.2图像上进行了测试。在整个实验过程中,您将使用以下帐户登录信息。如果您的密码不同,请注意差异。

1.1Pig基础
__ 1。 如果Hadoop没有运行,那么使用桌面上的图标启动它及其组件。
__ 2。打开命令行。右键单击桌面并选择Open in Terminal。
__ 3。接下来开始the Grunt shell。切换到Pig bin目录,并启动在本地模式下运行的shell。
cd $PIG_HOME/bin
./pig -x local
__ 4。将数据从逗号分隔的文件
/home/labfiles/SampleData/books.csv读取到名为data的关系中使用默认的PigStorage()加载器。
data = load ’ /home/labfiles/SampleData/books.csv ';
__ 5。接下来,访问每个元组中的第一个字段,然后将结果写到控制台。您必须使用foreach操作符来完成此操作。据我所知,我们还没有涉及到那个操作。跟我坦白。
b = foreach data generate
0记住,职位从零)和投射到一个字段称为f1的关系称为b。
列出的数据显示了一个元组在每一行和每一个元组包含一个字符串,其中包含的所有数据。这可能不是您所期望的,因为每行包含几个用逗号分隔的字段。
__ 6。上一步的问题是默认字段分隔符是制表符(\t);重新读取数据,但这次指定逗号作为分隔字符。然后将每个元组中的第一个字段投射到新关系中的一个字段中。然后转储新关系。(您可以使用上下光标键来回忆前面的命令)
data = load ’/home/labfiles/SampleData/books.csv’using PigStorage(’,’);
b = foreach data generate $0;
dump b;
注意,现在逗号分隔的字段变成了元组中的各个字段。第一个字段是一个数字。
__ 7。如果您希望能够通过名称而不是仅通过位置访问元组中的字段,该怎么办?您必须使用LOAD操作符并指定一个模式。
data = load ‘/home/labfiles/SampleData/books.csv’ using PigStorage(’,’) as (booknum:int, author:chararray, title:chararray, published:int);
b = foreach data generate author, title; dump b;
__ 8。说明表明关系和字段都是区分大小写的。验证这一点。使用以下模式重新阅读图书信息。
data = load ‘/home/labfiles/SampleData/books.csv’ using PigStorage(’,’) as (f1:int, F1:chararray, f2:chararray, F2:int);
令人惊讶的是,这确实奏效了。

__ 9。现在使用以下命令转储数据文件。
dump DATA;
你应该得到一个错误。
__ 10。这一次转储数据,但是要大写转储命令。
DUMP data;
__ 11。终止你的 Grunt shell。
quit;
虽然向上和向下游标会让人回想起前面的命令,但是我发现当一个被回想的命令跨越两行时,我无法将游标移动到第一行。另外,我喜欢使用脚本,因为我可以复制和粘贴前面的命令。
__ 12。创建一个包含Pig命令的脚本。打开另一个命令行并执行gedit。
gedit &
__13。可以将参数传递给Pig脚本。创建一个参数,该参数传递数据的目录结构。在gedit编辑区域,输入如下:
dir = /home/labfiles/SampleData
__ 14。将文件保存为/home/biadmin/myparams
__ 15。接下来,在gedit中,打开一个新的编辑窗口。键入LOAD命令,该命令将从一个名为/home/labfiles/SampleData/pig_bookreviews.json的字段读取数据。
正如文件扩展名所示,这是一个JSON文件。这需要您使用JsonLoader()。
__ 16。以下类型。注意
dir/pig_bookreviews.json’ using JsonLoader();
dump data;
__ 17。将您的工作保存到/home/biadmin/pig.script。
__ 18。在命令行中,调用Pig脚本并传入参数文件.
./pig -x local -param_file ~/myparams ~/pig.script
脚本中应该有一个错误。它说找不到模式文件。JsonLoader()需要一个模式。没有默认值。如果没有在LOAD语句中编写模式代码,那么函数期望在与数据相同的目录中找到一个模式文件。
__ 19。如果查看pig_bookreviews.json文件中数据的格式,可能会更有帮助。这样您就可以看到模式是如何匹配的。对于那些没有动力的人,这里有一些数据。需要注意的重要一点是,每个JSON记录都在一行上。
[{“author”: “J. K. Rowlings”, “title”: “The Sorcerers Stone”, “published”: 1997, “reviews”: [{“name”: “Mary”, “stars”: 5},{“name”: “Tom”, “stars”: 5}]}, …
{“author”: “David Baldacci”, “title”: “First Family”, “published”: 2009, “reviews”: [{“name”: “Andrew”, “stars”: 4},{“name”: “Katie”, “stars”: 4},{“name”: “Scott”, “stars”: 5}]}]
__ 20。在Pig脚本中,修改它,使JsonLoader()具有一个模式。
data = load ‘$dir/pig_bookreviews.json’ using JsonLoader(‘author:chararray,title:chararray,year:int,reviews:{review:(name:c hararray,stars:int)}’);
dump data;
__ 21。这应该已经解决了你的问题,这就结束了这个练习。
Exercise 2 Pig Relational Operators
Lab 1 Pig Relational Operators
这个练习让您有机会使用一些Pig关系操作符。
完成这个动手实验后,您将能够:
-过滤记录
-排序记录
-分组记录
-项目字段到新关系
-连接两个文件的数据
给10分钟来完成这个实验。
这个版本的实验室是使用InfoSphere BigInsights 2.1 Quick Start版本设计的,但是已经在2.1.2图像上进行了测试。在整个实验过程中,您将使用以下帐户登录信息。如果您的密码不同,请注意差异。

1.1核心运算符
__1。 如果Hadoop没有运行,那么使用桌面上的图标启动它及其组件。
__ 2。调出命令行。右击桌面,选择 Open in Terminal。
__ 3。您可以选择从Grunt shell或从Pig脚本运行Pig命令。在这两种情况下,您都需要切换到Pig bin目录并启动在本地模式下运行的shell。
cd $PIG_HOME/bin
__ 4。如果要在本地从Grunt shell运行,那么执行;
./pig -x local
如果你想用你的 pig.script 。然后执行脚本并传递目录参数,方法如下:
./pig -x local -param_file ~/myparams ~/pig.script
你可以编辑你的 pig.script 。使用gedit编写脚本。还请记住,在脚本中,可以通过在命令之前编写两个破折号(——)来注释掉任何命令。
__ 5。读取/home/labfiles/SampleData/books.csv文件。过滤结果关系,使您只拥有那些在2002年之前出版的图书。在下面的LOAD操作符中,它引用目录结构的一个参数。如果您从Grunt shell运行该命令,那么您将使用限定的目录路径替换
dir/books.csv’ using PigStorage(’,’) as (bknum: int, author:chararray, title:chararray, pubyear:int);
b = filter a by pubyear < 2002;
dump b;
如果您想随时查看来自任何关系的数据,只需为该关系编写一个dump语句即可。
__ 6。接下来获取过滤器的结果,并按pubyear按降序对记录进行排序。转储生成的关系。
c = order b by pubyear desc;
__ 7。接下来,将排序后的关系按pubyear进行分组。
d = group c by pubyear;
对于发布了两个元组的年份,请注意内部包包含两个元组。
__ 8。做一些投影。获取LOAD操作符的结果关系,并创建只有作者和图书的元组。
e = foreach a generate author, title;
__ 9。现在对GROUP操作符生成的关系执行相同的操作,只是将分组值添加到项目中。在这种情况下,您必须取消对字段名称的引用。
f = foreach d generate group, c.author, c.title;
__ 10。将上述关系的内袋压平,以便只返回作者。
g= foreach f generate flatten($1);
__ 11。取原始LOAD操作符创建的关系并分割文件,使David Baldacci的书在一个关系中,所有其他作者的书在第二个关系中。转储两个新创建的关系。
split a into h if author == ‘David Baldacci’, i if author != ‘David Baldacci’;
dump h;
dump i;
__ 12。最后,读入第二个文件。这个文件有书评人的名字和他们给每本书的星级。然后连接bknum上的图书文件和评论文件的关系。
j = load ‘$dir/reviews.csv’ using PigStorage(’,’) as (bknum:int, reviewer:chararray, stars:int);
k = join a by bknum, j by bknum;
dump k;
__ 13。这个练习到此结束。
Exercise 3 Pig Evaluation Functions
Lab 1 Pig Evaluation Functions
这个练习让您有机会使用一些Pig关系运算符来使用一些Pig计算函数。
在完成这个实践实验之后,您将能够:
-将计算函数应用到元组中的字段中
-从Grunt shell调用FSShell
给10分钟来完成这个实验。
这个版本的实验室是使用InfoSphere BigInsights 2.1 Quick Start版本设计的,但是已经在2.1.2图像上进行了测试。在整个实验过程中,您将使用以下帐户登录信息。如果您的密码不同,请注意差异。

1.1Evaluation functions
__1。如果Hadoop没有运行,那么使用桌面上的图标启动它及其组件。
__ 2。调出命令行。右击桌面并选择“在终端中打开”。
__ 3。您可以选择从Grunt shell或从Pig脚本运行Pig命令。在这两种情况下,您都需要切换到Pig bin目录并启动在本地模式下运行的shell。
cd $PIG_HOME/bin
__ 4。如果要在本地从Grunt shell运行,那么执行
./pig -x local
如果你要用你的pig.script。然后执行脚本并传递目录参数,方法如下:
./pig -x local -param_file ~/myparams ~/pig.script
你可以编辑你的pig.script。使用gedit编写脚本。还请记住,在脚本中,可以通过在命令之前编写两个破折号(——)来注释掉任何命令。
在这些方向中,转储操作符将仅为最终输出指定。但这并不妨碍您添加中间转储操作符,以查看每个操作符的影响。
__ 5。读取/home/labfiles/SampleData/books.csv文件。
books = load ‘$dir/books.csv’ using PigStorage(’,’) as (bknum: int, author:chararray, book:chararray, pubyear:int);
__ 6。读取/home/labfiles/SampleData/reviews.csv文件。
reviews = load ‘$dir/reviews.csv’ using PigStorage(’,’) as (bknum:int, reviewer:chararray, stars:int);
__ 7。按出版年份对图书关系进行分组。
booksInYear = group books by pubyear;
__ 8。计算每年出版的书的数量。
booksPerYear = foreach booksInYear generate group, COUNT($1); dump booksPerYear;
__ 9。这会更有趣一些。计算每本书的平均星星数。首先连接bknum上的图书关系和评论关系。
booksAndReviews = join books by bknum, reviews by bknum;
__ 10。下一个项目是一个新的关系,这样你只需要处理书名和每个书评人的星号。
booksAndStars = foreach booksAndReviews generate book, stars;
__ 11。将booksAndStars关系按书名分组。
starsInBooks = group booksAndStars by book;
__ 12。现在看看starsInBooks的模式可能是个好主意。
describe starsInBooks;
__ 13。接下来,您必须使用FOREACH操作符。访问书名很容易,因为记录是如何分组的。但是恒星的数量呢?在第一个分组中使用了哪个关系?这是booksAndStars。因此,必须使用booksAndStars取消引用星形。
avgStars = foreach starsInBooks generate group, AVG(booksAndStars.stars); dump avgStars;
__ 14。将星星的值作为double可能不是您想要的。你不能给出一个星的一半或三分之一,所以在计算平均值时,你可能希望它保持整数。为此,将平均值转换为int.
avgStars = foreach starsInBooks generate group, (int)AVG(booksAndStars.stars);
dump avgStars;
__ 15。如果你想消除任何低于四星的评级。(我知道这可能说不通,但谁说学习机会必须有意义呢?)可以使用带有嵌套块的FOREACH操作符。
bogusAvgStars = foreach starsInBooks {filteredStars = filter
booksAndStars by stars > 3;
numStars = filteredStars.stars;
generate group, (int)AVG(numStars);}
dump bogusAvgStars;
__ 16。使用EXPLAIN操作符,可以了解Pig将如何攻击特定的MapReduce问题。
explain bogusAvgStars;
__ 17。快速查看从Grunt shell运行hdfs命令。如果您没有在本地模式下打开Grunt shell,请执行以下操作:
./pig -x local
__ 18。接下来,使用Grunt shell中的FSShell命令列出当前目录。
fs -ls
是什么?它是$PIG_HOME/bin目录。有趣。为什么它没有列出hdfs中的目录和文件?您正在本地模式下运行。
__ 19。退出Pig本地模式。
quit;
__ 20。在MapReduce模式下调用Grunt shell。记住这是默认模式。
./pig
__ 21。再次执行FSShell并执行目录列表。这次它在hdfs中列出了数据。
fs -ls
__ 22。你可以退出Pig了。您可以停止Hadoop。练习到此结束。
5.Hive
HiveLab1-Exploring_Hive_3_0
Accessing Hadoop Data Using Hive
Unit 1: Exploring Hive
内容
实验室探索蜂巢
1.1开始
1.2蜂巢和WEB控制台
1.2.1启动/停止蜂巢从BIGINSIGHTS WEB控制台
1.2.2蜂巢 WEB界面蜂巢
1.3探索环境
1.3.1调查蜂巢与控制台目录结构
1.3.2探索蜂巢直线命令行接口(CLI)
1.4总结
Lab 1 Exploring Hive
数字服务的压倒性趋势,加上廉价的存储,已经产生了大量的数据,企业需要有效地收集、处理和分析这些数据。来自数据仓库和高性能计算社区的数据分析技术对许多企业来说是非常宝贵的,但是它们的成本或扩展的复杂性常常会在没有立即需要的情况下阻碍数据的积累。由于这些数据中可能埋藏着宝贵的知识,因此已经发展了有关的扩大技术。示例包括谷歌的MapReduce和开源实现Apache Hadoop。
编写MapReduce程序来分析大数据可能会变得复杂。Apache Hive可以帮助您更轻松地查询数据。Hive最初是在Facebook上创建的,它是Hadoop的数据仓库系统,可以方便地进行数据汇总、特别查询和分析存储在Hadoop兼容文件系统中的大型数据集。Hive提供了一种机制,可以将结构投射到该数据上,并使用名为HiveQL的类似sql的语言查询数据。
完成这个动手实验后,你将能够:
•从命令行和BigInsights Web控制台启动和停止Hive。
•使用Linux命令行探索Hive目录结构。
•与Hive Beeline CLI以交互模式、一次性模式和通过文件进行交互。
给30分钟到45分钟来完成这部分实验。
这个版本的实验室是使用InfoSphere BigInsights 3.0快速启动版设计的。在整个实验过程中,我们假定您将使用以下帐户登录信息:
1.1开始
为了准备这个实验室的内容,您必须经历启动所有Hadoop组件的过程。这些说明假设您已经遵循了IBM InfoSphere BigInsights快速启动版v3.0 README安装指南。
__1。启动VMware映像时,如果VMware Player中尚未打开,则单击Play virtual machine按钮。
__2。使用以下凭证登录VMware虚拟机。
用户:biadmin
密码:biadmin
__3。登录之后,您的屏幕应该与下面的屏幕类似。

在开始使用Hive和Hadoop分布式文件系统之前,我们必须首先启动所有的BigInsights组件。有两种方法可以做到这一点,通过终端和简单的双击图标。这两个方法将在以下步骤中显示。
__4。现在双击BigInsights Shell图标打开终端。

__5。单击终端图标

__6。打开终端后,更改为$BIGINSIGHTS_HOME/bin目录(默认为/opt/ibm/biginsights)
cd $BIGINSIGHTS_HOME/bin
或
cd /opt/ibm/biginsights/bin
__7。在BigInsights服务器上启动Hadoop组件(守护进程)。您可以使用这些命令练习启动所有组件。请注意,它们需要几分钟的运行时间。
./start-all.sh
__8。有时某些Hadoop组件可能无法启动。通过分别使用start.sh和stop.sh,可以一次启动和停止一个失败的组件。例如,启动和停止蜂巢使用:
./start.sh hive
./stop.sh hive
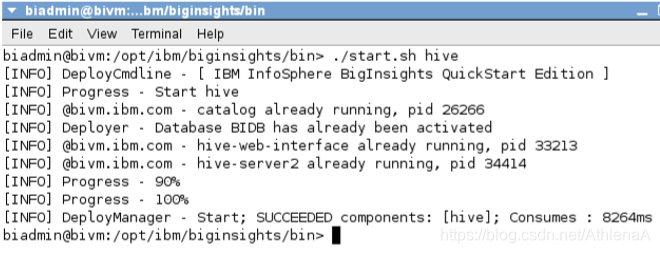
注意,由于Hive最初没有失败,终端告诉我们Hive已经在运行了。
__9。一旦所有组件都成功启动,您就可以继续前进了。

__10。如果您想停止所有组件,请执行下面的命令。但是,对于这个实验室,请让所有的部件都处于启动状态。
./stop-all.sh
接下来,让我们看看如何通过双击图标来启动所有组件。
__11。双击Start BigInsights图标将执行执行上述步骤的脚本。一旦所有的组件都启动了,终端出口就设置好了。

__12。我们可以用类似的方式停止组件,双击stop Biginsights图标。(在Start BigInsights图标下面)

现在组件已经启动,您可以继续下一节了。
1.2 Hive和Web控制台
Hive也可以很容易地从BigInsights Web控制台启动和停止。此外,我们还可以从与Apache Hive打包的Hive web接口使用Hive。
1.2.1从BigInsights Web控制台启动/停止Hive
__1。双击BigInsights WebConsole图标启动Web控制台。

__2。登录后,单击页面顶部的Cluster Status选项卡。

__3。单击Hive服务,并注意右侧窗格中为该服务提供的详细信息。从这里,您可以根据需要启动或停止Hive服务。例如,您可以看到Hive的Web界面的URL及其进程ID。
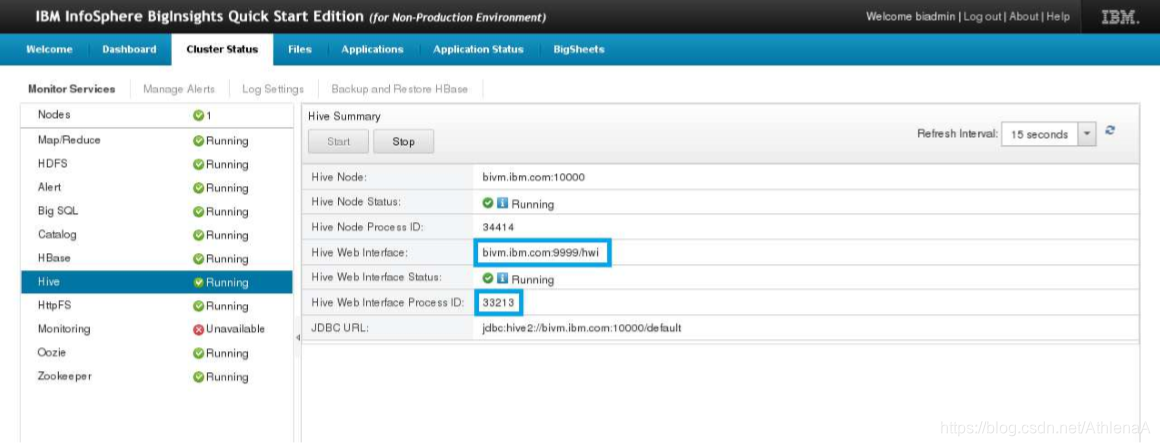
__4。在右边的窗格中(显示Hive状态),单击Stop按钮停止服务
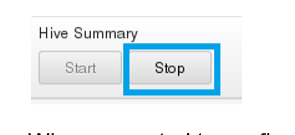
__5。当提示确认要停止Hive服务时,单击OK并等待操作完成。右边的窗格应该类似于下面的图像
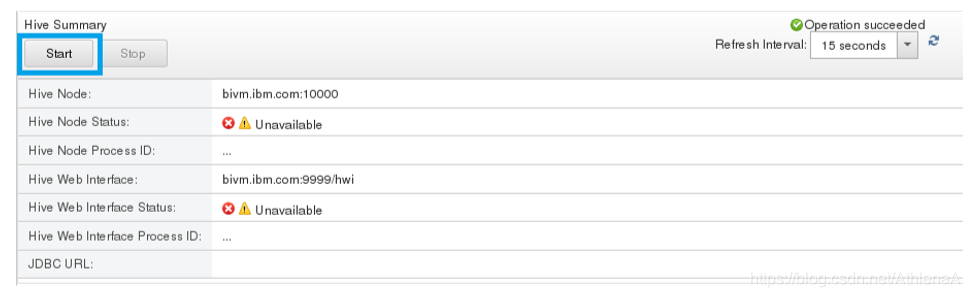
__6。单击Hive状态标题下的Start按钮重新启动Hive服务。(请参见前面的图)当操作完成时,Web控制台将指示Hive再次运行,很可能是在一个进程ID下运行,这个进程ID与这个lab模块开头显示的较早的Hive进程ID不同。(您可能需要使用Web浏览器的Refresh按钮来重新加载显示在左侧窗格中的信息。)
1.2.2 Hive Web接口
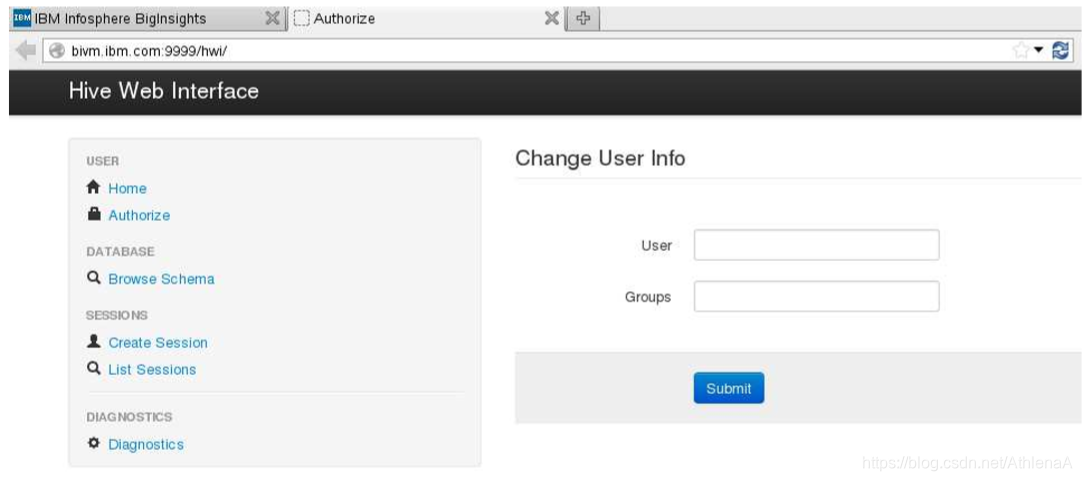
__1。剪切并粘贴Hive Web界面的URL (http://bivm.ibm.com:9999/hwi)到浏览器的新选项卡中。您将看到为管理目的提供的开源Hive Web接口,如下所示。
1.3探索蜂巢环境
1.3.1使用控制台研究Hive目录结构
让我们导航到Linux文件系统上的Hive主目录,并研究Hive由哪些目录组成。
__1。双击桌面上的BigInsights Shell图标,打开Linux终端。

__2。单击终端图标

__3。在终端中切换到Hive主目录
$ cd $HIVE_HOME
注:这相当于
$ cd $BIGINSIGHTS_HOME/hive
__4。检查当前目录
$ pwd
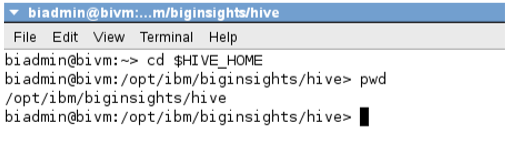
您现在处于/opt/ibm/biginsights/hive目录中。这就是在BigInsights虚拟机上设置Hive的地方。
__5。通过运行ls命令来研究hive文件夹中的目录结构。
$ ls
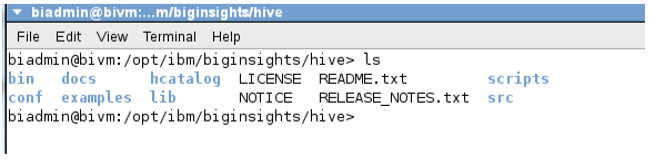
__6。您将注意到以下目录
•bin -启动/停止/配置/检查hive状态的可执行文件
•docs - Hive文档
•hcatalog - hcatalog文件
•scripts —用于将derby和MySQL从一个Hive版本升级到下一个Hive的脚本
•conf - Hive环境,metastore,安全和日志配置文件
•examples -蜂巢的例子
•lib -服务器的JAR文件
•src - Hive源代码和测试脚本
1.3.2探索Hive Beeline命令行界面(CLI)
从Hive Beeline CLI shell中,您可以执行查询、DML、DDL等。我们将在蜂巢直线CLI中做很多工作,所以让我们简单地检查一下!
__1。在Linux终端中切换到$HIVE_HOME/bin目录
$ cd $HIVE_HOME/bin
__2。在bin目录中,我们将运行一个命令,该命令将显示Hive CLI的命令行选项。
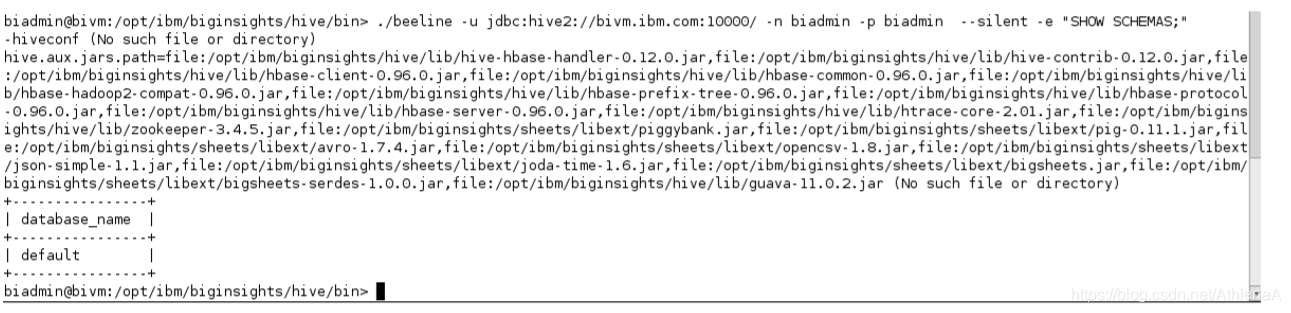
$ ./beeline –-help

__3。执行hive“one shot”命令(’ -e '指定了这个命令)来显示系统中的当前模式。您应该看到只列出了“默认”模式(在Hive中,模式和数据库是等效的术语)。
$ ./beeline –u jdbc:hive2://bivm.ibm.com:10000 –n biadmin –p biadmin -silent –e “SHOW SCHEMAS;”
注意,上面命令中的“-silent”表示“静默模式”,并删除了一些不必要的输出。“-u”告诉Beeline在以下URL连接到HiveServer2实例。“-n”后面是用户名,“-p”后面是密码。
__4。在/tmp目录中创建一个新文件,其中包含一个简单的HQL命令。
$ echo “SHOW DATABASES;” > /tmp/myfile.hql

__5。告诉Hive通过传递-f选项来运行文件中的命令。
$ ./beeline –u jdbc:hive2://bivm.ibm.com:10000 –n biadmin –p biadmin -silent -f /tmp/myfile.hql
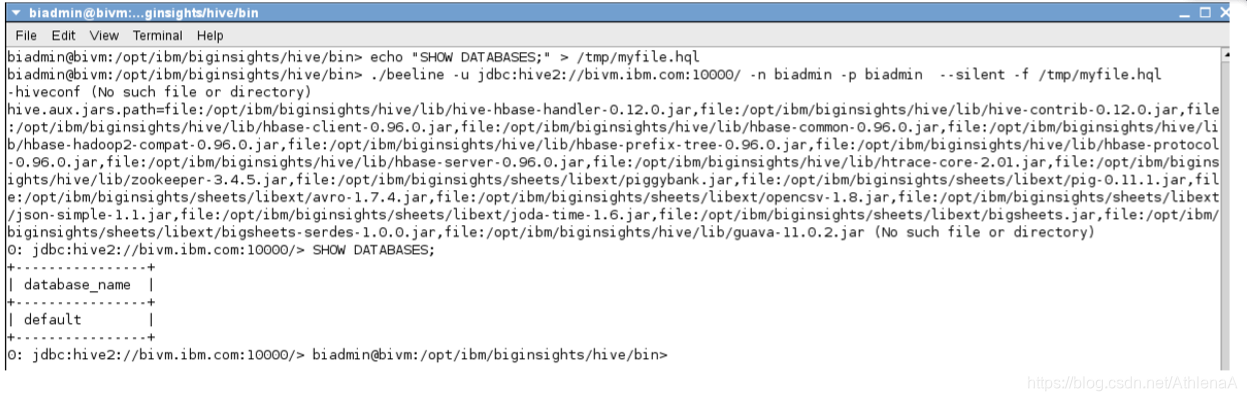
注意输出- Hive只列出一个数据库-“默认”Hive数据库。
__6。启动交互式Hive shell会话。
$ ./beeline –u jdbc:hive2://bivm.ibm.com:10000 –n biadmin –p biadmin
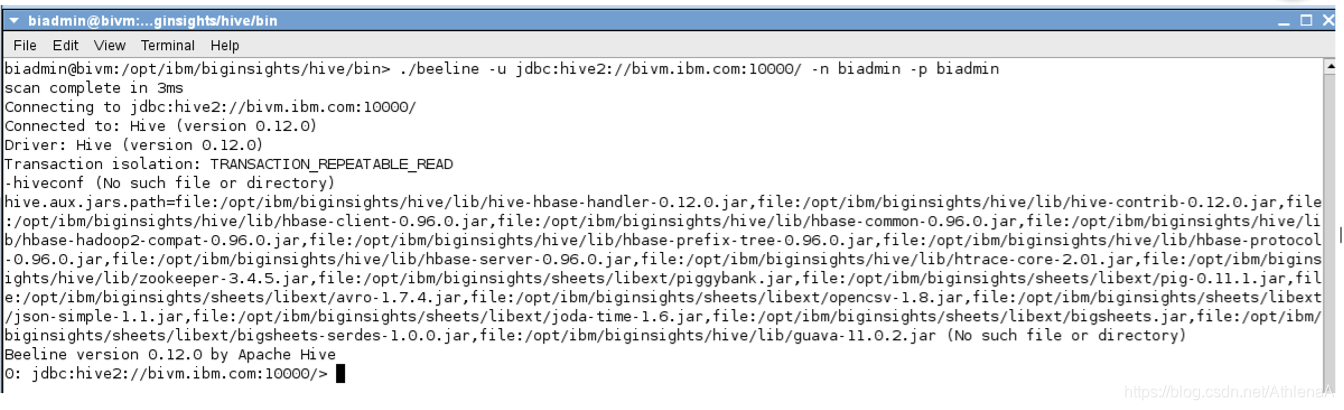
__7。在交互式Hive会话中运行SHOW DATABASES语句。
hive> SHOW DATABASES;

__8。离开蜂巢。
hive> !quit
1.4总结
恭喜你!现在您已经知道如何使用终端和BigInsights Web控制台启动和停止Hive。您可以导航到Hive目录并了解这些目录的内容。您还知道如何与Hive Beeline CLI交互。你可以换到下一个单元。
HiveLab2-HiveDDL_3_0
Accessing Hadoop Data Using Hive
Unit 2: Working with Hive DDL
内容
实验2处理蜂巢DDL
1.1访问蜂巢直线CLI
1.2蜂巢工作与数据库
1.3探索样本数据集
1.3.1找到示例数据
1.3.2数据描述蜂巢
1.4表中
1.4.1 管理非分区表
1.4.2分区表管理
1.4.3外部表
1.5总结
lab2 使用Hive DDL
在开始使用和分析Hive中的数据之前,我们必须首先使用Hive的数据操作语言。使用Hive DML将使我们能够创建数据库、表、分区等,稍后我们可以用可以查询和操作的数据加载它们。
完成这个动手实验后,你将能够:
•在Hive中创建、修改和删除数据库。
•在Hive中创建托管表、外部表和分区表。
•能够在HDFS中定位数据库和表。
1 - 1.5小时完成这部分实验。
这个版本的实验室是使用InfoSphere BigInsights 3.0快速启动版设计的。在整个实验过程中,我们假定您将使用以下帐户登录信息:

如果您在使用Hive Unit 1: explore Hive完成对Hadoop数据的访问后,还在继续这个系列的实验,那么您可以转到这个实验的1.1节。否则,请参考使用Hive Unit 1: explore Hive section 1.1来访问Hadoop数据。(应该运行所有Hadoop组件)
1.1访问Hive Beeline CLI
在本节中,我们将导航到Hive Beeline CLI并启动交互式CLI会话。
__1。在桌面上的BigInsights Shell目录中双击终端图标,打开Linux终端。

注意:您还可以通过单击BigInsights shell目录中的Hive shell图标,直接启动“原始Hive CLI shell”。然而,这个实验室使用的是更新的Beeline CLI。
__2。在Linux终端中切换到Hive home bin目录
~> cd $HIVE_HOME/bin
__3。启动交互式Hive shell会话。
~> ./beeline –u jdbc:hive2://bivm.ibm.com:10000 –n biadmin –p biadmin
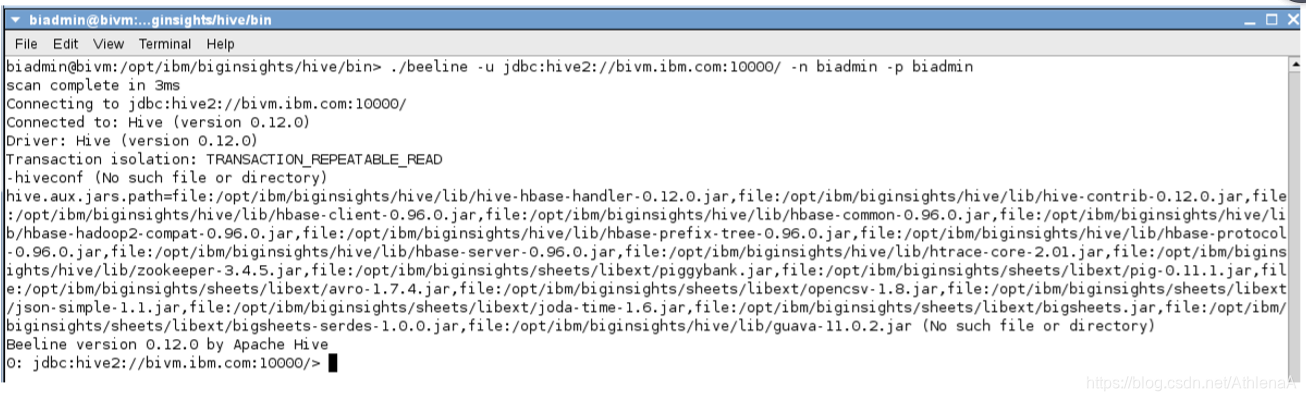
__4。在交互式Hive会话中运行SHOW DATABASES语句。
hive> SHOW DATABASES;

1.2使用Hive中的数据库
如果我们忽略在Hive中创建一个新数据库,那么将使用“default”数据库。让我们创建一个新的数据库并使用它。在这个练习中,我们将在Hive系统中创建两个数据库。其中一个将用于未来的演习。另一个将被删除。
__1。在Hive shell中创建一个名为testDB的数据库。
hive> CREATE DATABASE testDB;

__2。让我们确认新的数据库已添加到Hive的目录中。
hive> SHOW DATABASES; ;

请注意,Hive将“testDB”转换为小写。
__3。现在我们已经创建了一个新的数据库,让我们来描述它。
hive> DESCRIBE DATABASE testdb;

description数据库显示了testdb在HDFS上的位置。注意,testdb.db模式存储在/biginsights/hive/warehouse目录下的HDFS中。
__4。让我们确认新的testdb.db目录实际上是在HDFS上创建的。在桌面上的BigInsights Shell目录中双击终端图标,打开第二个Linux终端。

__5。检查HDFS以确认创建了新的数据库目录。
~> hadoop fs –ls /biginsights/hive/warehouse

创建testdb.db目录。
为这个实验室的其余部分打开第二个Linux控制台。我们将继续使用它来查看HDFS。您将在Hive控制台和这个Linux控制台之间来回切换。
__6。向testdb数据库的DBPROPERTIES元数据添加一些信息。我们通过使用ALTER数据库语法来实现这一点。
hive> ALTER DATABASE testdb SET DBPROPERTIES (‘creator’ = ‘bigdatarockstar’);

__7。让我们查看testdb数据库的扩展细节。
hive> DESCRIBE DATABASE EXTENDED testdb;

请注意更新的数据库属性。
__8。继续并删除testdb数据库。
hive> DROP DATABASE testdb CASCADE;
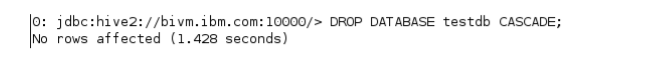
注意CASCADE关键字。这是可选的。使用它将导致Hive在删除数据库之前删除数据库中的所有表(如果有的话)。如果您试图删除没有CASCADE关键字的表的数据库,Hive不会允许您这样做。
__9。确认testdb不再在Hive metastore目录中。
hive> SHOW DATABASES;

__10。现在我们要创建一个数据库来存放我们在本课程的许多练习中使用的表。这个数据库将被称为“computersalesdb”。
hive> CREATE DATABASE computersalesdb;

__11。验证创建了数据库。注意数据库目录在HDFS中的位置。
hive> DESCRIBE DATABASE computersalesdb;

我们可以看到computersalesdb实际上是存在的,并且新的目录是在/biginsights/hive/warehouse/computersalesdb.db文件夹中的HDFS上创建的。
__12。告诉Hive使用computersalesdb(我们将在这个交互会话的其余部分使用这个数据库)。
hive> USE computersalesdb;
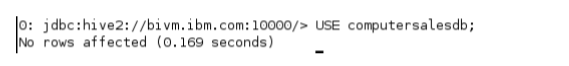
保持CLI打开—我们将在接下来的练习中使用它。
1.3研究我们的样本数据集
在开始在新数据库中创建表之前,务必了解示例文件中的数据是什么以及这些数据是如何结构化的。
在本课程的前面,您将实验室数据放在/home/biadmin目录中。现在我们来看看这些文件的内容。
1.3.1样本数据的查找
__1。在桌面上单击biadmin的Home快捷方式

将打开一个新窗口,显示/home/biadmin目录的内容。
__2。导航到以下目录sampleData->Computer_Business
__3。在Hive中,没有一种简单的方法可以从文件中删除标题行。为了简单起见,我们有两个目录—— WithoutHeaders和 WithRowHeaders。
WithRowHeaders -包含3个csv格式的数据文件。每个文件中的第一行是标题行。我们创建这个目录只是为了让您能够看到表的元数据(每个列包含哪些数据)。在这个练习中,您将只使用这个目录—并且只检查数据的外观。
WithoutHeaders – 包含与withrowheader目录相同的3个数据文件,除了从该数据中删除第一行(头数据)。此数据已准备好与Hive一起使用。
__4。让我们看看我们的数据。导航到WithRowHeaders目录。
__5。要查看其中一个文件的内容,右键单击该文件,然后从菜单中单击。然后点击弹出框上的“Display”按钮。检查这3个文件。
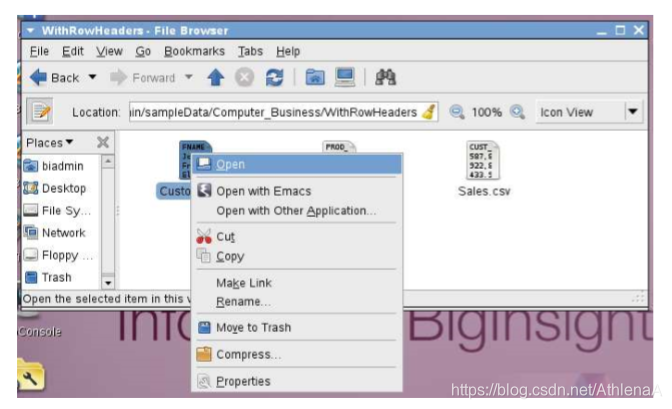
1.3.2样本数据描述
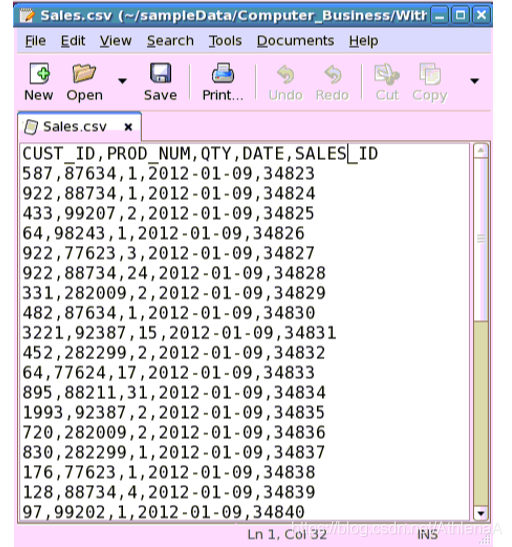
我们的示例数据来自一个虚构的计算机零售商。这家公司销售电脑零件,通常服务于美国的一个州。
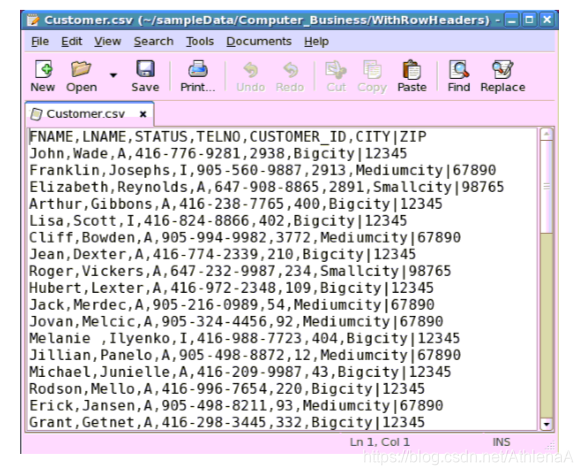
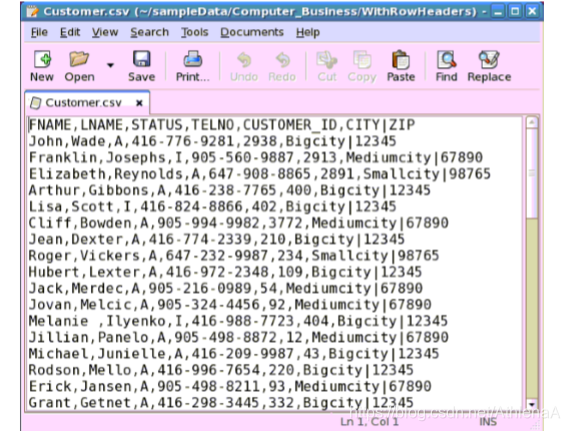
Customer.csv:
用途:保存客户记录。
列:
客户的名字
客户的姓
活动或非活动状态
电话号
客户的惟一的ID
城市和邮政编码由“|”字符分隔。

Example of contents:
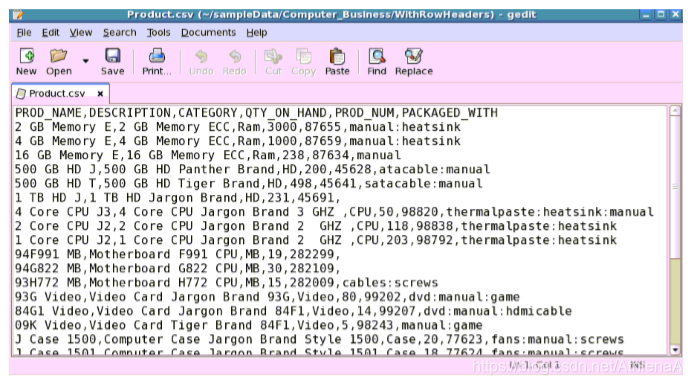
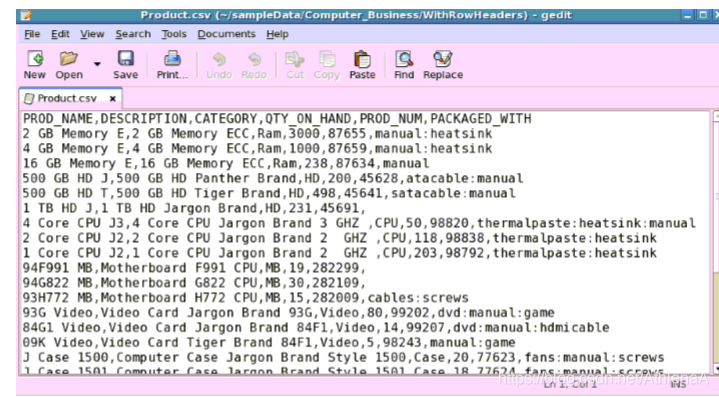
Product.csv:
用途:保存产品记录。
列:
PROD_
的名字
描述类别QTY_ON_HAND
PROD_
全国矿工工会
PACKAGED_
与
产品的名字
计算机产品描述
产品类别
仓库产品数量
独特的产品数量
以冒号分隔的产品包装清单。

Example of contents:
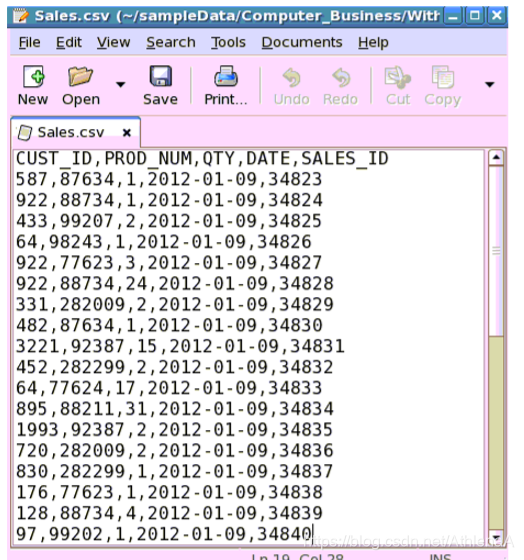
Sales.csv:
用途:保存所有历史销售记录。公司每月更新一次。
列:
购买产品的客户的身份证明
购买产品的ID
购买数量销售日期
独特的销售ID

Example of contents:
1.4 Hive中的表
1.4.1托管非分区表
我们将在Hive中创建的第一个表是products表。这个表将由Hive完全管理,不包含任何分区。
__1。在CLI中,在Hive中创建新产品表。
hive> CREATE TABLE products
(
prod_name STRING,
description STRING,
category STRING,
qty_on_hand INT,
prod_num STRING,
packaged_with ARRAY
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
COLLECTION ITEMS TERMINATED BY ‘:’
STORED AS TEXTFILE;
注意我们分配给不同列的数据类型。packaged_with列具有特殊的意义——它被指定为字符串数组。该数组将保存由冒号“:”字符分隔的数据,例如satacable:manual。我们还告诉Hive,行中的列由逗号“,”分隔。最后一行告诉Hive我们的数据文件是纯文本文件。

__2。让Hive显示数据库中的表。
hive> SHOW TABLES IN computersalesdb;

我们可以看到数据库中只存在一个表,它是我们刚刚创建的新产品表。
__3。在新产品表的TBLPROPERTIES中添加一个注释。
hive> ALTER TABLE products SET TBLPROPERTIES ( ‘details’ = ‘This table holds products’);

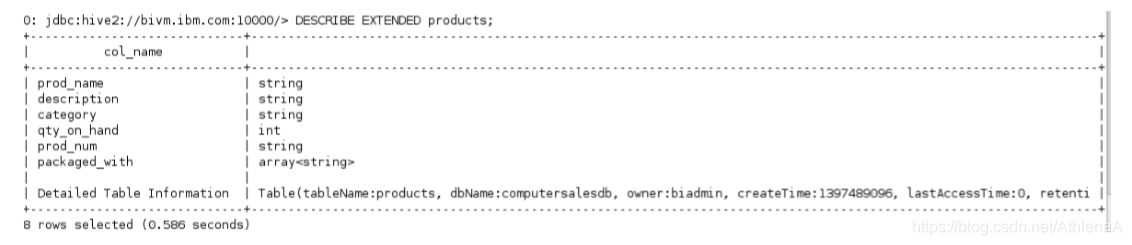
__4。列出products表的扩展详细信息。
hive>描述扩展产品;
Beeline的默认设置截断所有输出。让我们调整直线以不同的格式显示数据,这样我们就可以看到所有的输出。
Inside of Beeline:
hive> !set outputformat vertical

现在,重新运行DESCRIBE EXTENDED products;命令。

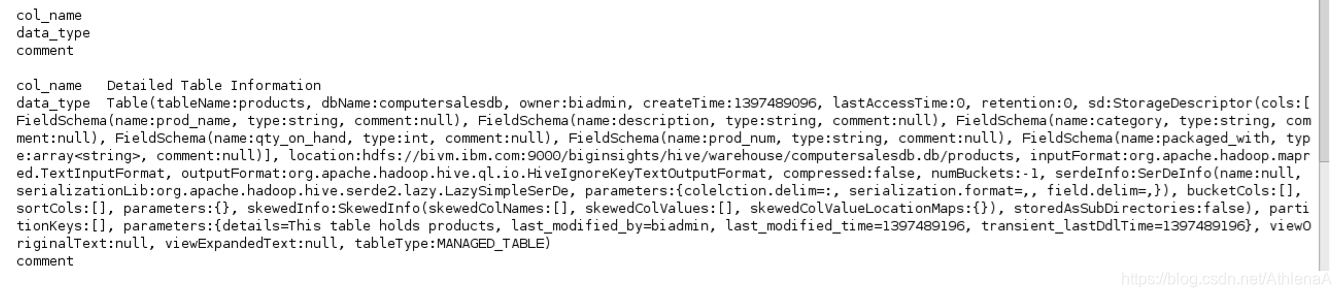
这是很多细节!注意,这里有一些有趣的信息,包括这个表在HDFS中的位置: /biginsights/hive/warehouse/computersalesdb.db/products
__5。让我们验证产品目录是在上面列出的位置上的HDFS上创建的。在Linux控制台中运行HDFS ls命令。首先列出数据库目录的内容,然后列出products表目录的内容。
~> hadoop fs –ls /biginsights/hive/warehouse/computersalesdb.db;
~> hadoop fs –ls /biginsights/hive/warehouse/computersalesdb.db/products;

第一个命令确认HDFS上实际上有一个products表目录。第二个命令显示产品目录中还没有文件。这个目录将是空的,直到我们在后面的练习中将数据加载到products表中。
__6。假设我们虚构的计算机公司在每个月底将销售数据添加到“sales_staging”表中。然后,从这个sales_staging表中,他们将想要分析的数据移动到一个分区的“sales”表中。分区销售表是他们实际用于分析的表。
现在我们知道了如何创建表,接下来将创建一个名为“sales_staging”的托管非分区表。该表将保存sales.csv文件中的所有销售数据。在后面的练习中,我们将把这个sales_staging数据分割成一个名为“sales”的分区表。
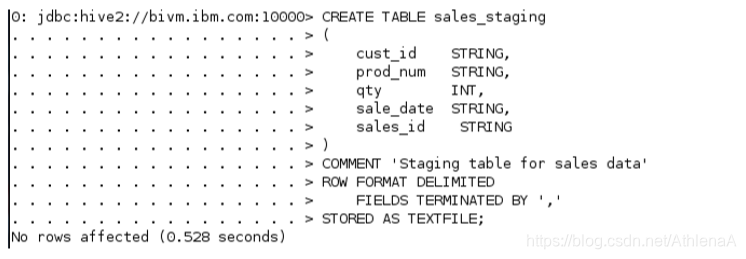
在CLI中,在Hive中创建新的sales_staging表。
hive> CREATE TABLE sales_staging
(
cust_id STRING,
prod_num STRING,
qty INT,
sale_date STRING,
sales_id STRING
)
COMMENT ‘Staging table for sales data’
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS TEXTFILE;
__7。现在我们可以假设新的sales_staging表目录位于以下文件夹中的HDFS上:/biginsights/hive/warehouse/computersalesdb.db/sales_staging。让我们在Linux控制台输入以下命令来快速确认:
~> hadoop fs –ls /biginsights/hive/warehouse/computersalesdb.db;

果然,创建了sales_staging目录,现在由Hive管理。
__8。让Hive显示数据库中的表。确认新的sales_staging表在Hive目录中。
hive> SHOW TABLES;

__9。假设我们已经决定要更新一些列元数据。我们将把sales_staging表中的sale_date列从字符串类型更改为日期类型。
hive> ALTER TABLE sales_staging CHANGE sale_date sale_date DATE;

1.4.2托管分区表
__1。现在我们将创建一个分区表。这个表将是一个托管表——Hive将管理这个表的元数据和生命周期,就像我们之前创建的表一样。
在CLI中创建sales表。该表将在销售日期进行分区。
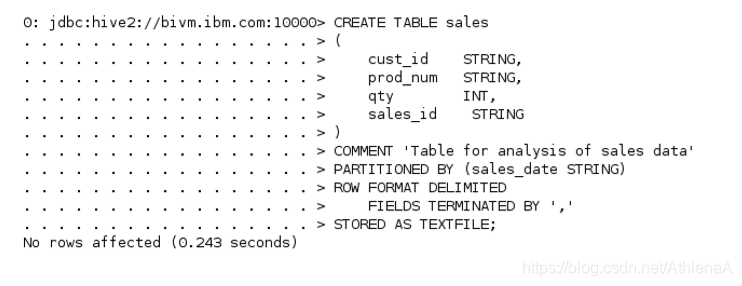
hive> CREATE TABLE sales
(
cust_id STRING,
prod_num STRING,
qty INT,
sales_id STRING
)
COMMENT ‘Table for analysis of sales data’
PARTITIONED BY (sales_date STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS TEXTFILE;
注意,我们在partition BY子句中列出sales_date,而不是在data列元数据中列出它。由于我们在sales_date上进行分区,Hive将在实际数据之外跟踪我们的日期。
__2。让我们查看新表的扩展细节。
hive> DESCRIBE EXTENDED sales;
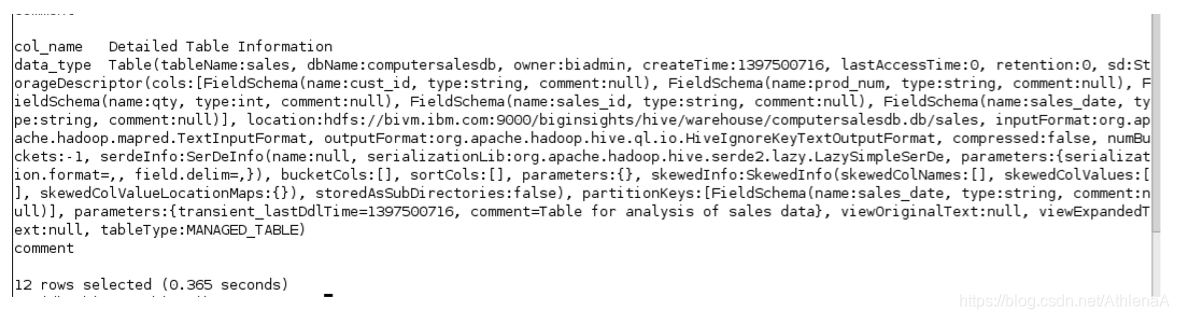
我们可以看到/biginsights/hive/warehouse/computersalesdb.db/sales创建了一个目录。
当我们稍后将数据放入该表时,将在sales目录中为每个分区创建一个新目录。
下面的行详细地展示了我们的表是如何分区的:partitionKeys: [FieldSchema(name:sales_date, typestring,comment:null)]
1.4.3外部表
我们虚拟计算机公司的另一个部门希望能够分析客户数据。因此,我们将客户表设置为外部的,这样他们可以在数据上使用他们的工具,而我们可以使用我们的(Hive),这是有意义的。我们将在HDFS中放置Customer.csv文件的副本,然后在Hive中创建一个指向该数据的新表。
__1。首先,我们需要在HDFS上创建一个新目录——我们将其命名为“shared_hive_data”——它可以存放我们的Customer.csv数据文件。让我们把它放到/user/biadmin目录中。我们将运行命令从Linux控制台创建新目录。
~> hadoop fs –mkdir /user/biadmin/shared_hive_data;

__2。现在我们将把Customer.csv 文件的副本移动到/user/biadmin/shared_hive_data目录中。我们可以在Linux控制台中运行这个命令来实现这一点。
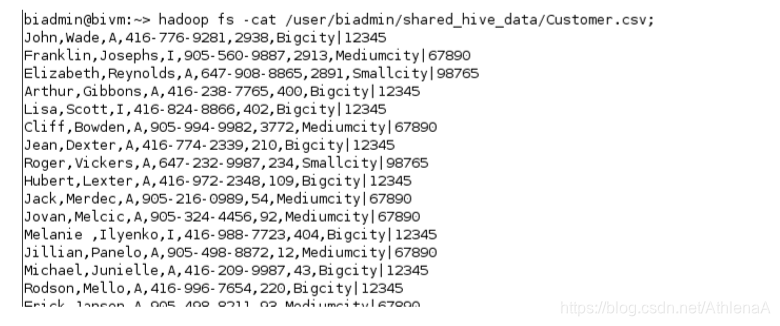
~> hadoop fs –put /home/biadmin/sampleData/Computer_Business/WithoutHeaders/Customer.csv /user/biadmin/shared_hive_data/Customer.csv;

__3。确认Customer.csv已成功复制到HDFS中。在Linux控制台中输入以下命令。
~> hadoop fs –ls /user/biadmin/shared_hive_data/;

如果您的输出类似于上面的屏幕截图,那么这很好!
如果您愿意,可以运行“cat”命令来验证数据是否位于HDFS上的 Customer.csv文件中。
~> hadoop fs –cat /user/biadmin/shared_hive_data/Customer.csv;
__4。现在我们只需要定义外部客户表。
hive> CREATE EXTERNAL TABLE customer
(
fname STRING,
lname STRING,
status STRING,
telno STRING,
customer_id STRING,
city_zip STRUCT<city:STRING, zip:STRING>
)
COMMENT ‘External table for customer data’
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
COLLECTION ITEMS TERMINATED BY ‘|’
LOCATION ‘/user/biadmin/shared_hive_data/’;
这里有几点需要注意。首先,我们在CREATE行中使用EXTERNAL关键字。在创建这个外部表时,我们省略了“stored as line”,因为默认格式已经设置为TEXTFILE。我们还将LOCATION ‘location/of/datadirectory’ 行添加到语句的末尾。
Hive希望这个位置是一个目录,而不是一个文件。对于我们的练习,shared_hive_data目录中只有一个文件。但是,您可以将多个客户数据文件放入shared_hive_data目录中,Hive将对您的外部表使用它们!这是一种常见的情况。

__5。让我们查看新表的扩展细节。
hive> DESCRIBE EXTENDED customer;
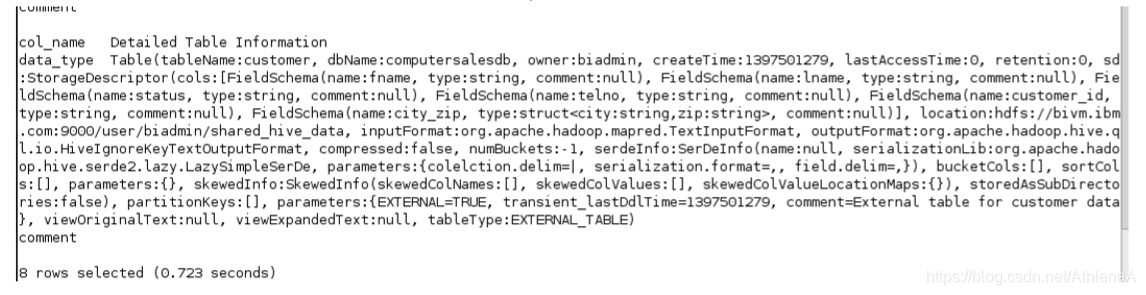
您可以看到该位置指向我们在HDFS上指定的/user/biadmin/shared_hive_data目录。还请注意,在输出的最后是tableType:EXTERNAL_TABLE。
__6。让我们将直线输出格式设置为表格样式。这将在运行查询时提供更清晰的输出。
hive> !set outputformat table

__7。由于customer是一个外部表,Hive已经知道数据所在的位置,所以您可以开始在该表上运行查询。通过运行一个简单的select查询作为证据来奖励自己完成了这个实验。
hive> SELECT * FROM customer LIMIT 5;
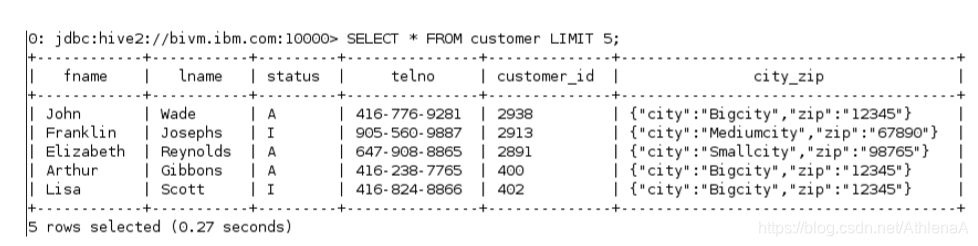
这个Hive查询没有运行任何MapReduce作业。Hive能够读取数据文件并将结果写入CLI,而不需要使用MapReduce,因为这是一个简单的SELECT和LIMIT语句。
1.5总结
恭喜你!现在您知道了如何在Hive中创建、修改和删除数据库。您可以创建托管的、外部的和分区的Hive表。您还熟悉本课程将使用的示例数据。你可以换到下一个单位。
HiveLab3-HiveDML_3_0_0
Accessing Hadoop Data Using Hive
Unit 3: Hive DML in action
内容
实验3蜂巢DML操作
1.1访问蜂巢CLI
1.1.1示例数据描述
1.2 加载数据
1.2.1从BIGINSIGHTS WEB控制台查看数据
1.2.2数据加载到管理非分区表
1.2.3数据加载到分区表.管理
1.3 运行查询
1.3.1选择数据
1.3.2大SQL子查询
1.3.3 利用分区的数据
1.3.4加入
1.3.5观点
1.4 导出数据
1.5解释
1.6总结
Lab 3 Hive DML in action
现在我们已经学习了如何在Hive中创建数据库、表和分区,现在可以使用Hive的数据操作语言并完成一些工作了!让我们加载一些数据并开始编写查询。
完成这个动手实验后,你将能够:
•将数据加载到Hive表和分区中。
•对数据运行各种HiveQL查询。
•利用分区加速查询。
•使用视图来减少查询的复杂性。
•从Hive导出数据。
•使用Explain了解更多关于查询的信息。
给45分钟到1小时来完成这部分实验。
这个版本的实验室是使用InfoSphere BigInsights 3.0快速启动版设计的。在整个实验过程中,您将使用以下帐户登录信息:
如果您在使用Hive Unit 2: Working with Hive DDL完成对Hadoop数据的访问之后,还在继续这个系列的实验,那么您可以继续学习这个实验的1.1节。(所有Hadoop组件应该都在运行,您应该已经创建了这个单元中使用的数据库、表和分区。)
1.1访问Hive CLI
在本节中,我们将导航到Hive Beeline CLI并启动交互式CLI会话。
__1。在桌面上的BigInsights Shell目录中双击终端图标,打开Linux终端。

__2。在Linux终端中切换到Hive home bin目录
$ cd $HIVE_HOME/bin
__3。启动交互式Hive shell会话。
~> ./beeline –u jdbc:hive2://bivm.ibm.com:10000 –n biadmin –p biadmin
__4。告诉Hive使用computersalesdb(我们将在这个交互会话的其余部分使用这个数据库)。
hive> USE computersalesdb;

1.1.1样本数据描述
在开始使用Hive之前,请先查看我们将要使用的数据。打印这些页面可能很有用,这样您就可以在运行查询时引用数据。我们的示例数据来自一个虚构的计算机零售商。这家公司销售电脑零件,通常服务于美国的一个州。
Customer.csv:
用途:保存客户记录。
列:
FNAME LNAME状态TELNO CUSTOMER_ID CITY|ZIP
客户的名字
客户的姓
活动或非活动状态
电话号
客户的惟一的ID
城市和邮政编码由“|”字符分隔。

内容的例子:
Product.csv:
用途:保存产品记录。
列:
PROD_
的名字
描述类别QTY_ON_HAND
PROD_
全国矿工工会
PACKAGED_
与
产品的名字
计算机产品描述
产品类别
仓库产品数量
独特的产品数量
以冒号分隔的产品包装清单。

内容的例子:
Sales.csv:
用途:保存所有历史销售记录。公司每月更新一次。
列:
CUST_ID PROD_NUM QTY DATE SALES_ID
购买产品的客户的身份证明
购买产品的ID
购买数量销售日期
独特的销售ID

内容的例子:
1.2加载数据
在我们之前的实验室中,我们创建了4个新表。这些表需要包含对我们有用的数据。表名是customer、products、sales_staging和sales。请记住,customer表是一个外部表,我们已经将数据“加载”到其中。
1.2.1从BigInsights Web控制台查看数据
在这个实验室,我们将利用BigInsights Web控制台在HDFS中查看数据。
__1。单击桌面快捷方式打开BigInsights Web控制台。如果需要登录。

__2。单击顶部的Files选项卡。在左侧的导航菜单中,导航到hdfs:/bivm:9000/>biginsights->hive->warehouse->computersalesdb.db这是我们所有hive管理表都将下行的路径。
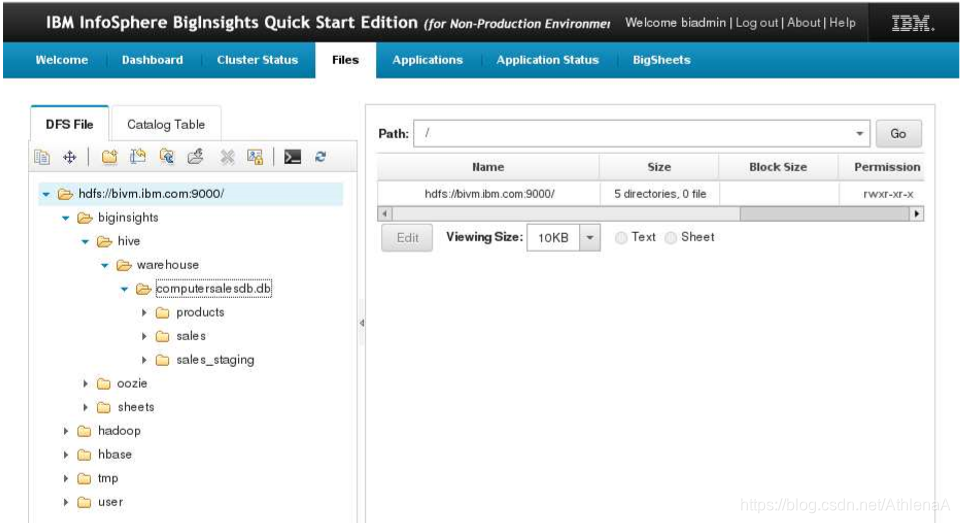
在使用Hive Beeline CLI时,请保持此浏览器打开。它将允许我们在使用Hive DML时快速检查HDFS并查看文件和目录的更改。
1.2.2将数据加载到托管的非分区表中
我们在前一个实验中创建的第一个表是products表。这个表完全由Hive管理,不包含任何分区。现在,我们将使用存储在local /home/biadmin/sampleData/Computer_Business/WithoutHeaders/Product.csv file.
中的数据加载products表。
__1。在CLI中,在Hive中创建新产品表。
hive> LOAD DATA LOCAL INPATH ‘/home/biadmin/sampleData/Computer_Business/WithoutHeaders/Product.csv’ OVERWRITE INTO TABLE products;
 Hive从文件中复制数据。我们的products表现在包含数据。让我们一起来看看吧!
Hive从文件中复制数据。我们的products表现在包含数据。让我们一起来看看吧!
__2。使用BigInsights Web控制台,导航到 hdfs:/bivm:9000/->biginsights->hive>warehouse->computersalesdb.db->products directory。单击该目录中的Products.csv文件。
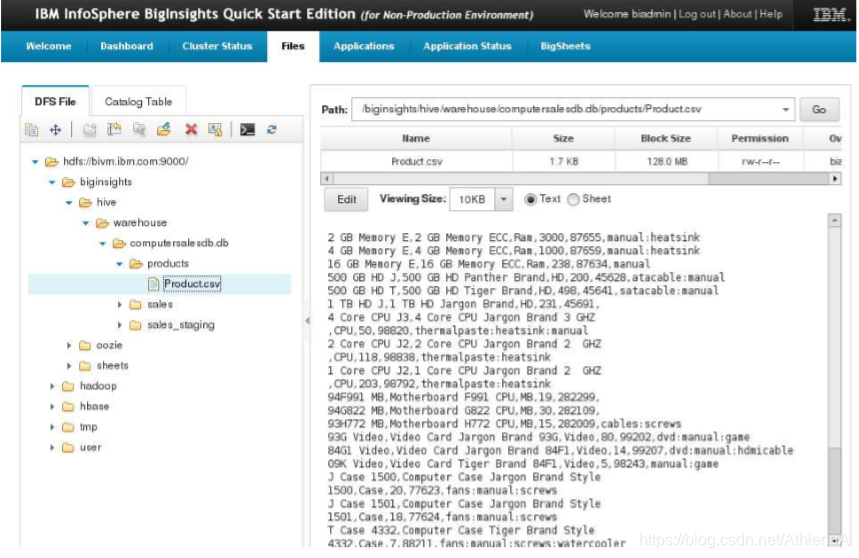
我们可以在这里轻松地查看Products.csv文件的内容。查看浏览器右侧显示的数据。我们的产品表现在已经加载!
__3。接下来,我们将把销售记录加载到sales_staging表中。
hive> LOAD DATA LOCAL INPATH ‘/home/biadmin/sampleData/Computer_Business/WithoutHeaders/Sales.csv’ INTO TABLE sales_staging;
注意,我们在这个语句中去掉了OVERWRITE关键字。这是因为我们通常希望将每月的销售数据添加到sales_staging表中已经存在的历史记录列表中。我们不希望仅用本月的数据覆盖该表中的所有记录。

__4。同样,让我们通过签出BigInsights Web控制台中的文件来验证数据是否位于HDFS中。
首先单击refresh按钮更新导航树。
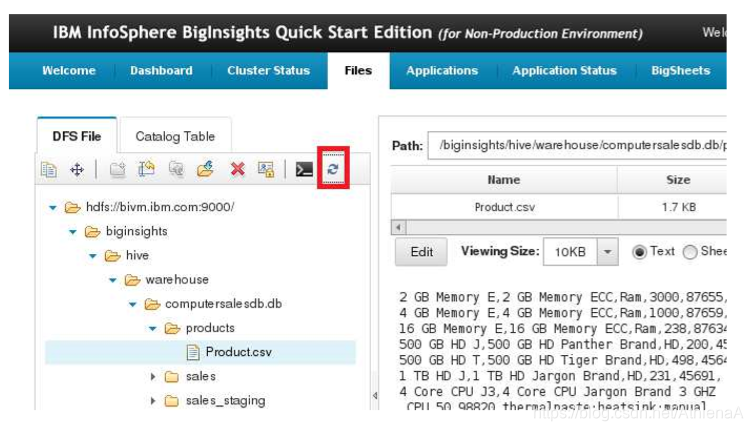
现在打开sales_staging文件夹,单击Sales.csv文件并浏览右侧的数据。
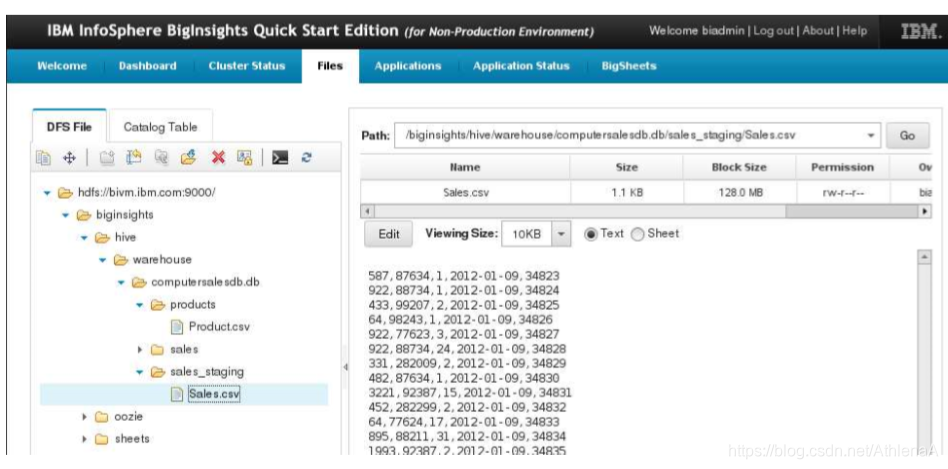
看起来很成功。
1.2.3将数据加载到托管分区表中
既然我们的sales_staging表有了可以使用的数据,那么让我们编写一些查询,以便使用来自sales_staging的数据加载分区的sales表(在sales_date上分区)。
__1。在CLI中,将来自“2012-01-09”的销售数据加载到销售表的一个分区中。
hive> INSERT OVERWRITE TABLE sales
PARTITION (sales_date = ‘2012-01-09’)
SELECT cust_id, prod_num, qty, sales_id
FROM sales_staging ss
WHERE ss.sale_date = ‘2012-01-09’;

注意,这需要一段时间才能完成。这是因为您调用了MapReduce作业(多亏了WHERE子句)!
__2。在BigInsights Web控制台中,刷新文件树并查看sales文件夹。您将看到一个名为sales_date=2012-01-09的新子目录。该目录中有一个名为000000_0的数据文件。如果您选择该文件,您将在右手预览中看到,它只包含我们2012-01-09年的销售数据。
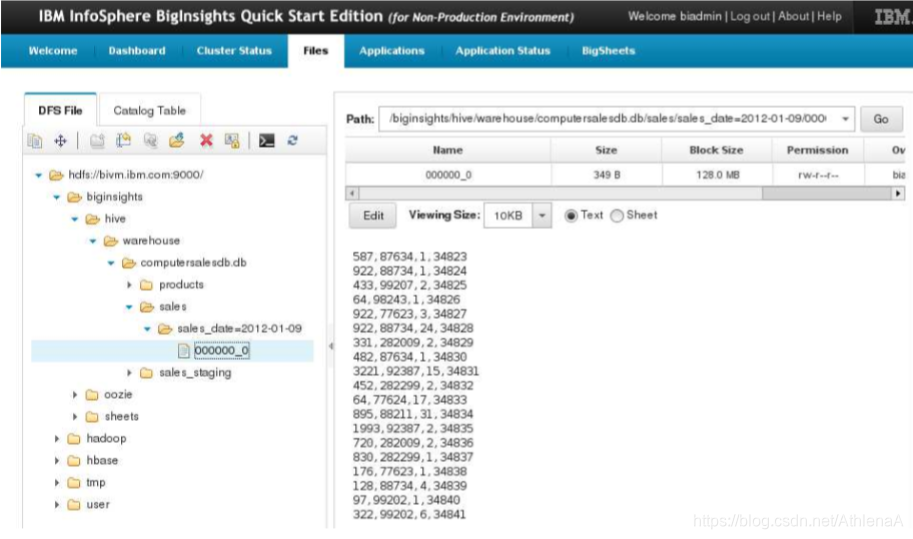
__3。按照相同的过程,将“2012-01-24”中的销售数据加载到销售表的新分区中。
hive> INSERT OVERWRITE TABLE sales
PARTITION (sales_date = ‘2012-01-24’)
SELECT cust_id, prod_num, qty, sales_id
FROM sales_staging ss
WHERE ss.sale_date = ‘2012-01-24’;

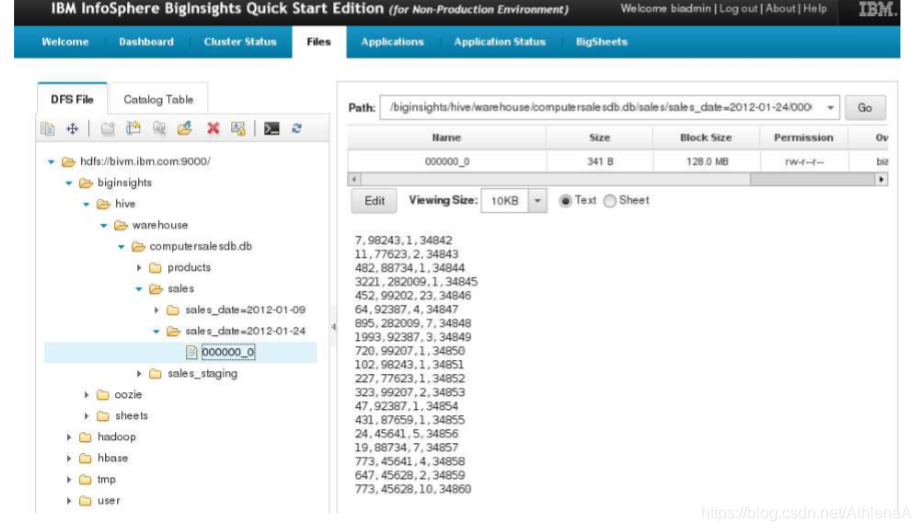
__4。在BigInsights Web控制台中,刷新文件树并查看sales文件夹。您将看到一个名为sales_date=2012-01-24的新子目录。该目录中有一个名为000000_0的数据文件。如果您选择该文件,您将在右手预览中看到,它只包含我们2012-01-24年的销售数据。
1.3运行查询
1.3.1选择数据
既然我们的表中有数据,让我们开始对该数据运行查询。
__1。在CLI中,选择products表中产品类别为“Video”的所有数据。
hive> SELECT * FROM products WHERE category=’Video’;

现在打开BigInsights Web控制台并导航到Application Status选项卡。您将看到在Jobs下列出的查询。点击它。
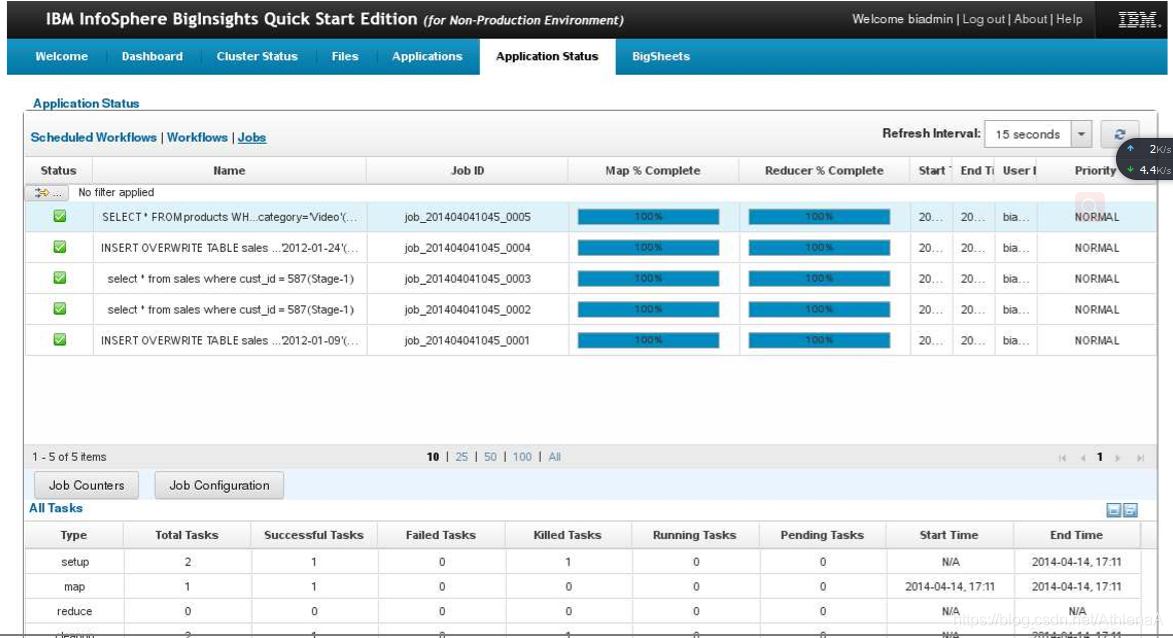
该查询导致一个MapReduce作业正在运行。MapReduce作业需要一个映射器和零还原器。运行这个简单的查询大约需要18秒。结果被打印到CLI。category= " Video "的3条记录实际上是在CLI中返回的!
__2。现在选择category= ’ Video ‘和PACKAGED_WITH数组的第一个元素包含’ dvd '的所有产品。
hive> SELECT * FROM products
WHERE category=’Video’ AND PACKAGED_WITH[0]=’dvd’;

__3。使用GROUP by子句,可以了解每个类别的产品数量。
hive> SELECT category, count(*) FROM products
GROUP BY category;
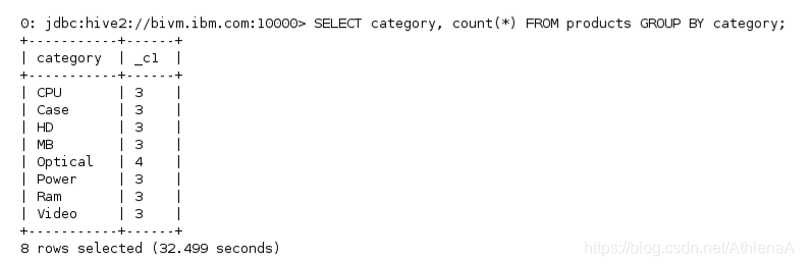
我们可以看到我们的结果,他们看起来很好。
__4。使用嵌套选择显示包含4个以上产品的产品类别。
hive> FROM(
SELECT category, count(*) as count FROM products
GROUP BY category) cats
SELECT * WHERE cats.count > 3;

您的输出应该类似于上面的屏幕截图。您将注意到,除了使用子查询之外,我们还使用了两个列别名(“count”和“cats”)
1.3.2大SQL子查询
假设您已经在Hadoop之外的RDBMS中使用这个数据集很多年了。您已经编写了许多在传统RDBMS上运行的查询,现在您只需复制其中一些查询并在大数据环境中使用它们。不幸的是,Hive不完全符合SQL,因此您可能需要花时间修改查询以在HiveQL中工作。一个更简单的选择可能是使用IBM的Big SQL运行查询。Big SQL与ANSI SQL兼容,并提供许多性能优势和特性。
__1。在Hive CLI中,运行以下子查询。我们的目标是获得属于“Ram”类别的所有产品的列表,其中包含每个产品的销售数量(而不是销售数量)。注意,子查询位于SQL的SELECT部分。
hive> SELECT prod_num, (SELECT count(*) FROM sales WHERE prod_num=prod.prod_num group by prod_num) as number_of_sales FROM products prod WHERE CATEGORY=‘Ram’;
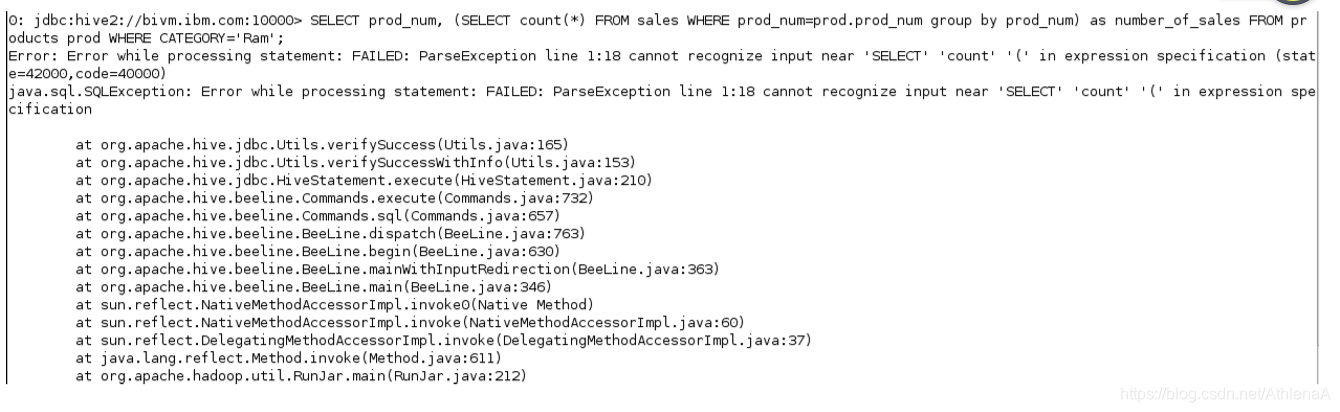
看起来不太好!Hive不允许子查询位于SQL语句的那个位置。
__2。IBM的Big SQL应该已经在您的Big Insights虚拟机上运行了。使用大SQL有很多方法——在本例中,我们将使用大SQL JSQSH命令行shell。在Linux桌面上打开BigInsights Shell文件夹。然后打开BigSQL Shell应用程序。

给shell一点时间启动。一旦它准备好了,它将看起来如下:
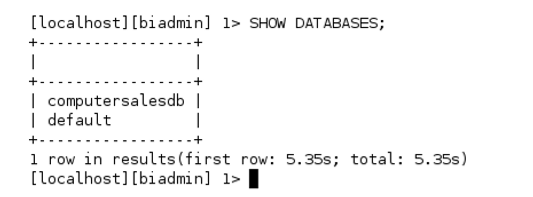
__3。要求大SQL显示数据库;您会注意到,Big SQL已经知道我们的Hive数据库!
__4。将computersalesdb数据库设置为这个会话的工作数据库。
USE computersalesdb;

__5。运行SELECT子句中包含子查询的前一个SQL查询。
SELECT prod_num, (SELECT count(*) FROM sales WHERE prod_num=prod.prod_num GROUP BY prod_num) as number_of_sales FROM products prod WHERE category=‘Ram’;

Big SQL能够快速返回我们的结果,这要归功于它的优化,它允许在服务器上运行对小数据集的查询,而不是运行MapReduce作业。
__6。进入退出;关闭大型SQL shell。
quit;
1.3.3利用分区数据
sales表在sales_date上分区。在前面的练习中,我们将数据加载到这个表的两个分区(2012-01-09和2012-01-24分区)中。让我们利用这个分区来改进延迟。
IBM软件
Hands-on-Lab 19页
__1。在CLI中,运行SELECT查询,只查找2012-01-24年发生的销售。根据sale_id对结果进行排序。
hive> SELECT * FROM sales
WHERE sales_date = ‘2012-01-24’
ORDER BY sales_id;
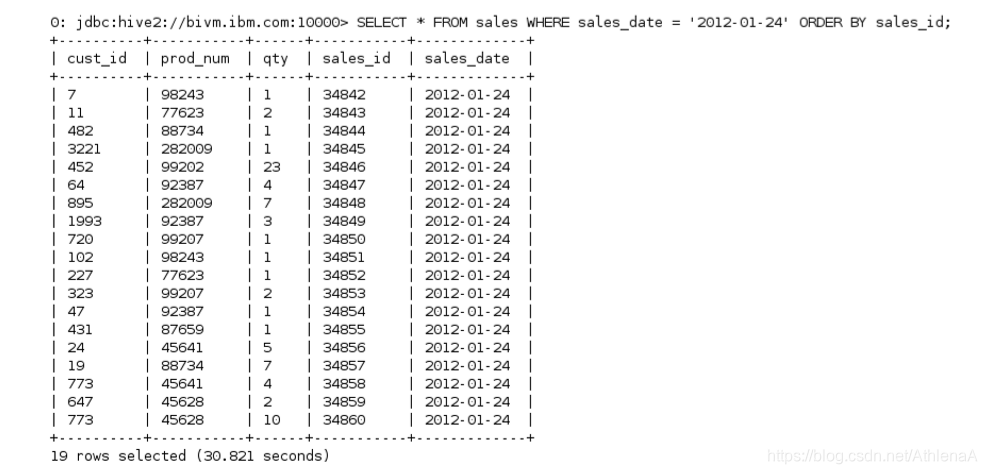
只有2012年01月24日的销售记录被退回。
__2。让我们看一下在Hadoop上运行的作业,以实现我们的Hive查询。我们可以在BigInsights Web控制台轻松地完成这项工作。在web控制台中,单击Application Status选项卡,然后单击Jobs链接(要单击的适当位置在下面的屏幕截图中以红色突出显示)。您将看到以我们的查询命名的作业—单击该作业并调查该作业。

完成这个查询需要一个MapReduce作业。这个作业包含一个Map任务和一个Reduce任务。只需要读入sales_id=2012-01-24分区文件就可以完成这个查询,从而节省了一些等待时间——理论上,如果我们有大量的历史销售数据,那么将节省大量的等待时间。
1.3.4连接
__1。让我们展示2012-01-09年度所有光学类产品的销售情况。我们需要在sales和products表之间做一个等值连接来收集这些信息。
hive> SELECT s.cust_id, s.prod_num, s.qty, s.sales_id, p.prod_name, p.category
FROM sales s JOIN products p
ON s.prod_num = p.prod_num
WHERE s.sales_date = ‘2012-01-09’ AND p.category = ‘Optical’;
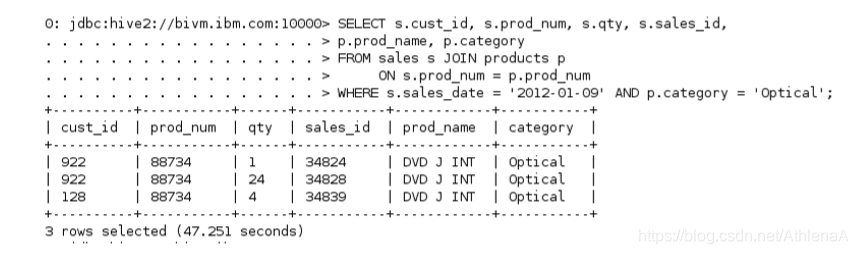
这次加入很成功。我们得到了我们要找的3条记录。
1.3.5视图
__1。现在让我们创建一个视图来存储一个查询,该查询返回产品类别为“Optical”的所有销售记录(与products表连接)。
hive> CREATE VIEW optical_sales AS
SELECT s.cust_id, s.prod_num, s.qty, s.sales_id, p.prod_name, p.category
FROM sales s JOIN products p
ON s.prod_num = p.prod_num
WHERE p.category = ‘Optical’;

视图已成功创建。
__2。现在我们有了optical_sales视图,我们可以在其他查询中使用它,就像它是一个表一样。注意这个查询有多短。
hive> SELECT * FROM optical_sales WHERE qty > 1;
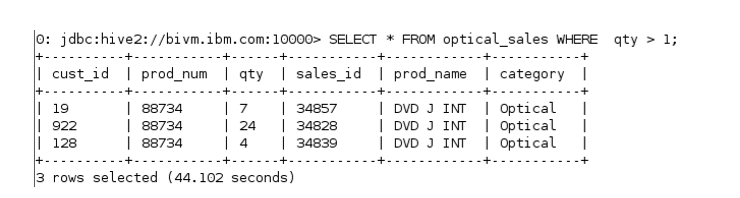
1.4出口数据
想象一下,我们的管理团队希望我们提取所有光学设备的销售数据,并以Hive CLI之外的格式提供给他们。我们可以通过从Hive导出数据来做到这一点。
__1。打开BigInsights Web控制台并打开Files选项卡。导航到user->biadmin文件夹。
__2。在HDFS上的/user/biadmin目录中,创建一个名为HiveReport的新目录。

__3。单击权限框,并将此新文件夹设置为可由所有用户写入。
__4。在Hive CLI中,我们将利用前面的查询,将数据写入HDFS文件系统上的/user/biadmin/HiveReport目录。
hive> INSERT OVERWRITE DIRECTORY ‘/user/biadmin/HiveReport’ SELECT * FROM optical_sales WHERE qty > 1;

__5。打开一个新的Linux终端。输入以下命令:
~> hadoop fs –ls ‘/user/biadmin/HiveReport’
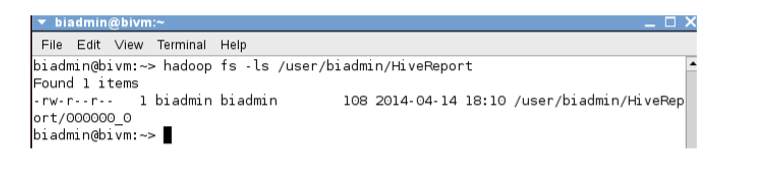
注意,我们有一个名为000000_0的新文件!这是Hive写出来的数据。
现在让我们cat这个文件,看看内容是什么样的:
~> hadoop fs –cat ‘/user/biadmin/HiveReport/000000_0’
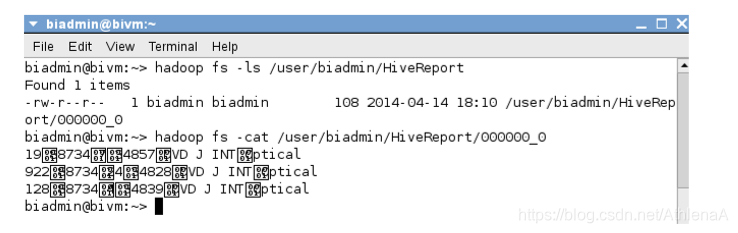
奇怪的看着因为蜂巢的默认显示字符分隔符分隔符是^字符。
您可以从HDFS中复制新的报告,并在您选择的工具中使用结果。
1.5解释
让我们简要了解一下如何在Hive查询中使用EXPLAIN。
__1。我们将让Hive解释一个简单查询的执行计划,该查询选择客户状态处于活动状态的所有客户记录。
hive> EXPLAIN SELECT * FROM customer;

您能告诉我们运行这个Hive查询需要多少个MapReduce作业吗?如果你没有猜错,那你就对了。Hive能够读取记录并将输出转储到控制台,而不需要使用MapReduce。Hive使用“本地模式”来完成这项工作。
1.6总结
恭喜你!现在您知道如何将数据加载到Hive中。您可以使用熟悉的子句(如SELECT、WHERE、GROUP BY、ORDER BY、JOIN等)运行各种查询。您可以从Hive导出数据,甚至可以运行Explain工具来获得查询的执行计划。你可以换到下一个单位。
HiveLab4-HiveOperatorsFunctions_3_0
Accesing Hadoop Data Using Hive
Unit 4: Hive Operators and Functions
实验4蜂巢运算符和函数
1.1访问蜂巢CLI
1.2运算符
1.2.1关系运算符
1.2.2算术运算符
1.2.3逻辑运算符
1.3函数
1.4扩展蜂巢的函数
1.4.1流
1.5总结
现在我们已经熟悉了Hive的数据操作语言(DML),我们可以使用Hive的一些内置操作符和函数来进一步分析数据。我们还可以研究扩展Hive的内置功能。
完成这个动手实验后,你将能够:
•使用各种内置的Hive运算符
•使用各种内置的Hive函数
•做基本的流媒体
给30分钟来完成这部分实验。
这个版本的实验室是使用InfoSphere BigInsights 3.0快速启动版设计的。在整个实验过程中,我们假定您将使用以下帐户登录信息:
如果您在使用Hive Unit 3: Hive DML完成对Hadoop数据的访问之后,还在继续这个系列的实验,那么您可以转到这个实验的1.1部分。(所有Hadoop组件应该都在运行,您应该已经创建了这个单元中使用的数据库、表和分区。)
1.1访问Hive CLI
在本节中,我们将导航到Hive Beeline CLI,就像我们在以前的实验室中所做的那样,并启动一个交互式CLI会话。
__1。在桌面上的BigInsights Shell目录中双击终端图标,打开Linux终端。

__2。在Linux终端中切换到Hive home bin目录
~> cd $HIVE_HOME/bin
__3。启动交互式Hive shell会话。
~> ./beeline –u jdbc:hive2://bivm.ibm.com:10000 –n biadmin –p biadmin
__4。告诉Hive使用computersalesdb(我们将在这个交互会话的其余部分使用这个数据库)。
hive> USE computersalesdb;

1.2运算符
在本节中,我们将试验Hive系统中的关系、算术和逻辑运算符。
1.2.1关系运算符
__1。使用IS NULL操作符查找packaged_with数组的零位置上没有项的products表中的所有记录。
hive> SELECT * FROM products WHERE packaged_with[0] IS NULL;

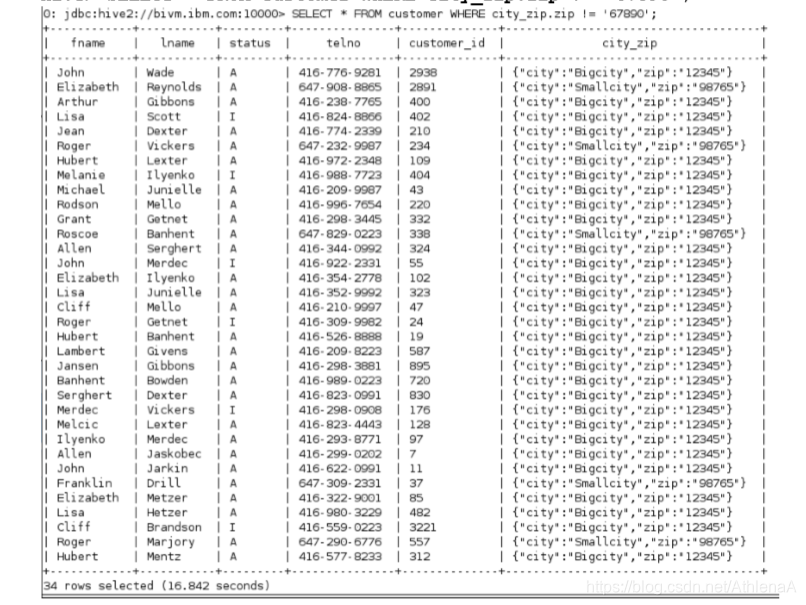
__2。寻找不在67890邮政编码区居住的客户。使用!=操作符检查customer表的city_zip结构列。提醒:city_zip在我们的表中被描述为structcity:string,zip:string。
hive> SELECT * FROM customer WHERE city_zip.zip != ‘67890’;
__3。使用LIKE操作符查找包含单词“Tiger”的所有产品描述。
hive> SELECT * FROM products WHERE description LIKE ‘%Tiger%’;

我们可以看到,表中的6条记录在description列中包含单词Tiger。Hive需要一个作业来满足我们的要求。
1.2.2算术运算符
__1。将公司销售的所有产品的名称、数量和产品编号返回给Hive。每种产品的数量加10。
hive> SELECT prod_name, qty_on_hand + 10, prod_num FROM products;
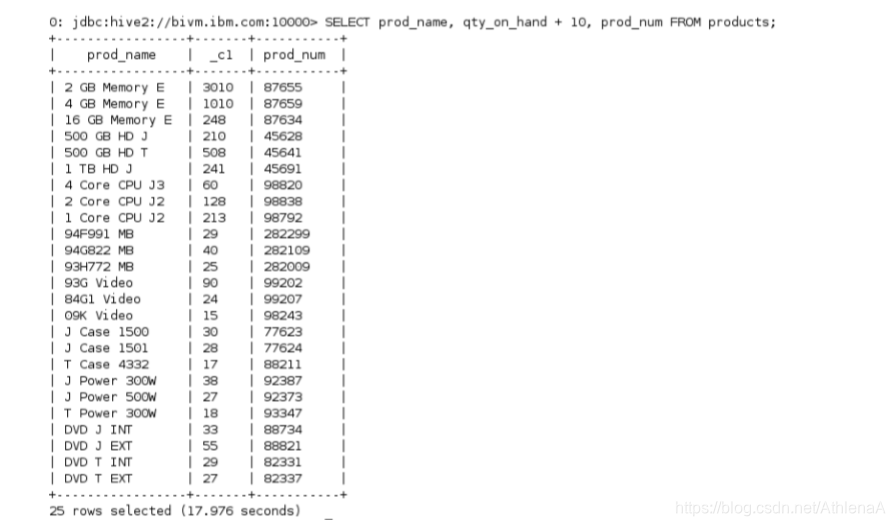
你会注意到每个量加了10。
1.2.3逻辑运算符
__1。查找所有姓“Merdec”或“Melcic”的客户。
hive> SELECT * FROM customer WHERE lname=’Merdec’ OR lname=’Melcic’;
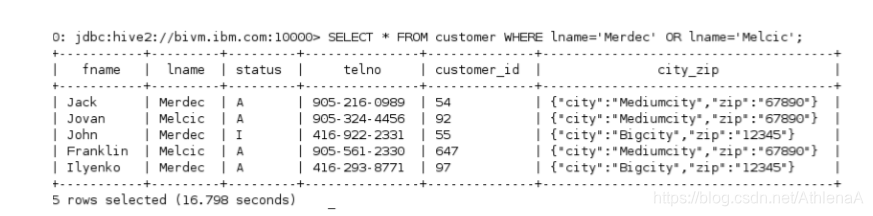 使用OR逻辑运算符可以检索与查询的姓氏匹配的5条记录。
使用OR逻辑运算符可以检索与查询的姓氏匹配的5条记录。
1.3函数
在本节中,我们将试验内置的Hive函数。
__1。让我们进一步了解上面的函数。在Hive CLI的上面运行description函数。
hive> DESCRIBE FUNCTION upper;

__2。将产品类别转换为大写,并查找类别为“大写”的产品。
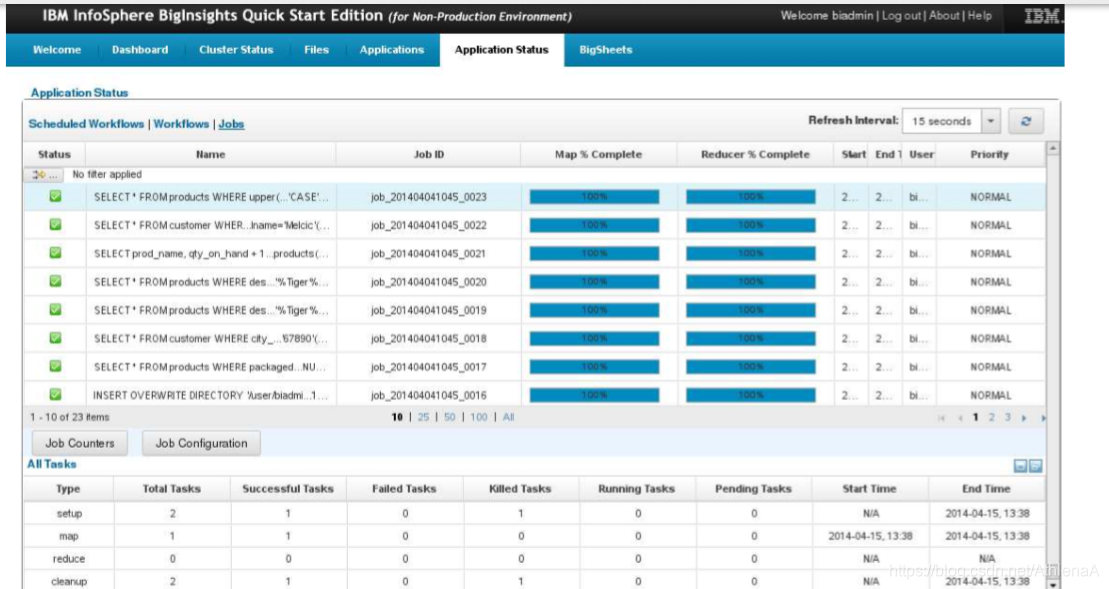
hive> SELECT * FROM products WHERE upper(category) = ‘CASE’;

电脑案件的3条记录被返回。如果打开BigInsights Web控制台,可以看到需要1个映射器和0个简化器来获得这个结果集。
__3。让我们对prod_num=98820的product的数组进行爆炸。
hive> SELECT explode(packaged_with) as package_contents FROM products WHERE prod_num=’98820’;

数组被分解,每个数组元素作为单独的行返回。
1.4扩展Hive的功能
有多种方法可以扩展Hive的功能,包括编写自定义用户定义函数(UDF)和流。在这个实验中,我们将介绍一个非常简单的流媒体例子。
1.4.1流
__1。让我们将qty和sales_id列流到Linux OS上的/bin/cat命令。
hive> SELECT TRANSFORM (qty, sales_id)
USING ‘/bin/cat’ AS newQty, newSalesID
FROM sales;
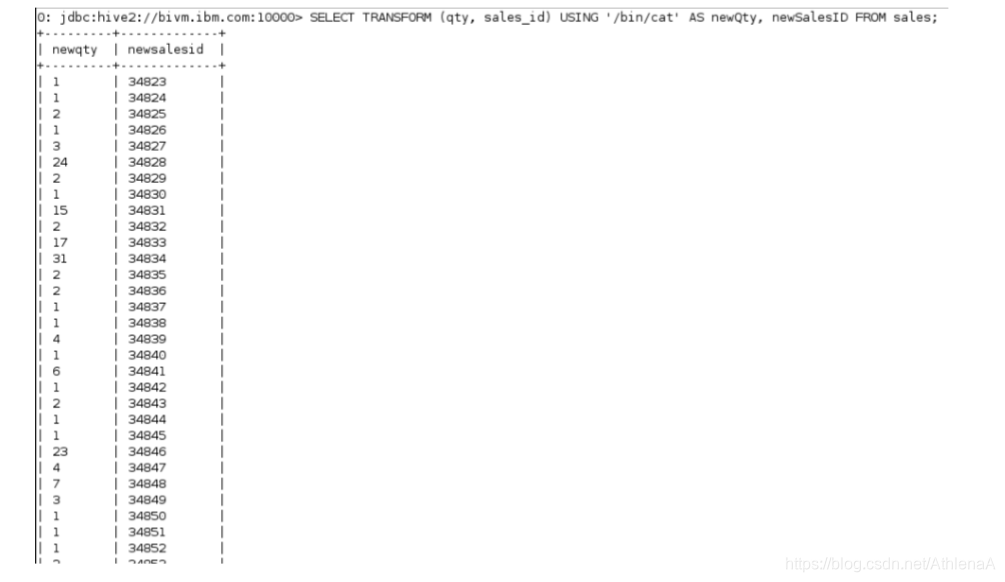
我们可以看到这两列是从/bin/cat/ process中收集的,并写入Hive控制台!
1.5总结
恭喜你!现在您已经知道如何使用各种内置的Hive运算符和函数。你也可以在Hive中做基本的流。你可以换到下一个单位。
HiveLab5-HiveStorageFormats_3_0
Using Hive for Data Warehousing
Unit 5: Hive Storage Formats
实验5蜂巢存储格式
1.1访问蜂巢CLI
1.2使用不同的文件和记录格式
1.2.1 SEQUENCEFILE
1.2.2 RCFILE
1.2.3 ORC文件
1.3压缩
1.4总结
Lab 5 Hive Storage Formats
我们可以使用Hive处理各种不同的文件和记录格式。在使用Hive和Hadoop时,理解如何使用简单的TextFile之外的格式可以帮助您做出更好的决定。我们还可以使用Hive的压缩来减少数据的占用——这可能会提高我们的性能和/或存储性能。
完成这个动手实验后,你将能够:
•创建SequenceFiles、RCFiles和ORC文件。
•在CREATE TABLE语句中显式地声明输入/输出格式和SerDe。
•在Hive中打开输出压缩。
给45分钟完成这部分实验。
这个版本的实验室是使用InfoSphere BigInsights 3.0快速启动版设计的。在整个实验过程中,您将使用以下帐户登录信息:

如果您在使用Hive Unit 4: Hive操作符和功能完成对Hadoop数据的访问后,还在继续这个系列的实验,那么您可以继续学习这个实验的1.1部分。(所有Hadoop组件应该都在运行,您应该已经创建了这个单元中使用的数据库、表和分区。)
1.1访问Hive CLI
在本节中,我们将导航到Hive Beeline CLI,就像我们在以前的实验室中所做的那样,并启动一个交互式Hive CLI会话。
__1。在桌面上的BigInsights Shell目录中双击终端图标,打开Linux终端。

__2。在Linux终端中切换到Hive home bin目录
~> cd $HIVE_HOME/bin
__3。启动交互式Hive shell会话。
~> ./beeline –u jdbc:hive2://bivm.ibm.com:10000 –n biadmin –p biadmin
__4。告诉Hive使用computersalesdb(我们将在这个交互会话的其余部分使用这个数据库)。
hive> USE computersalesdb;

1.2处理不同的文件和记录格式
在本节中,我们将在Hive中试验不同的文件和记录格式。我们已经在系统上创建了多个TEXTFILE格式的表。让我们利用这一点,创建一些不同格式的新表——然后通过在原始表上运行SELECT查询将数据插入到新表中。
1.2.1 SequenceFile
在之前的一个实验室中,您创建了products表,并使用“作为TEXTFILE存储”子句描述了该表。现在我们将创建一个名为products_sequenceformat的新表,它将作为SEQUENCEFILE存储。我们将通过简单地运行INSERT语句,让Hive为我们完成从TEXTFILE到SEQUENCEFILE的转换。
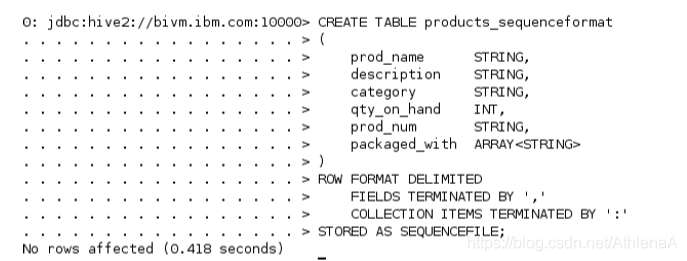
__1。在Hive中创建一个名为products_sequenceformat的新表。除了将STORED AS子句改为SEQUENCEFILE而不是TEXTFILE之外,我们将使用与创建原始products表完全相同的DDL。
hive> CREATE TABLE products_sequenceformat
(
prod_name STRING,
description STRING,
category STRING,
qty_on_hand INT,
prod_num STRING,
packaged_with ARRAY
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
COLLECTION ITEMS TERMINATED BY ‘:’
STORED AS SEQUENCEFILE;
__2。运行SHOW TABLES命令来验证表是否已经创建。
hive> SHOW TABLES;

__3。将Hive的outputformat设置为vertical,然后要求Hive提供products_sequenceformat 表的扩展细节。
hive> !set outputformat vertical
hive> DESCRIBE EXTENDED products_sequenceformat;
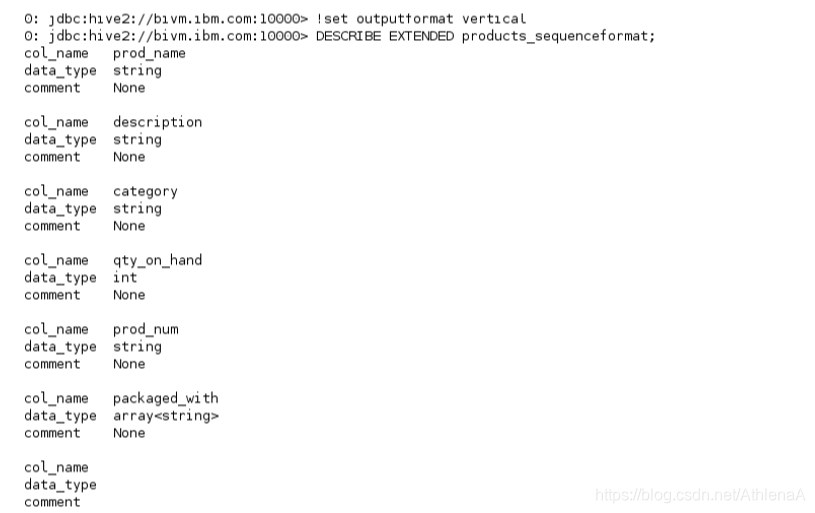

你会注意到这里列出的一些有趣的事情:
InputFormat is: org.apache.hadoop.mapred.SequenceFileInputFormat
OutputFormat is: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputformat
SerDe serializationLib is: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
The HDFS location of the data for this table is: /biginsights/hive/warehouse/computersalesdb.db/products_sequenceformat
重要的是要认识到,在create table语句中使用STORED AS SEQUENCEFILE子句可以在幕后适当地设置输入和输出格式。在创建表时,我们不必显式地指定这些值(尽管我们可以这样做)。
__4。是时候用数据加载products_sequenceformat表了。我们将通过运行INSERT查询来实现这一点。
hive> FROM products INSERT OVERWRITE TABLE products_sequenceformat SELECT *;

在后台,使用临时空间存储中间数据。
__5。让我们检查一下HDFS上的products_sequenceformat表,看看Hive为我们做了什么。打开BigInsights Web控制台并导航到/biginsights/hive/warehouse/computersalesdb.db/products_sequenceformat 目录。您将找到一个000000_0文件。如果单击此文件,数据将显示在右手查看窗格中。
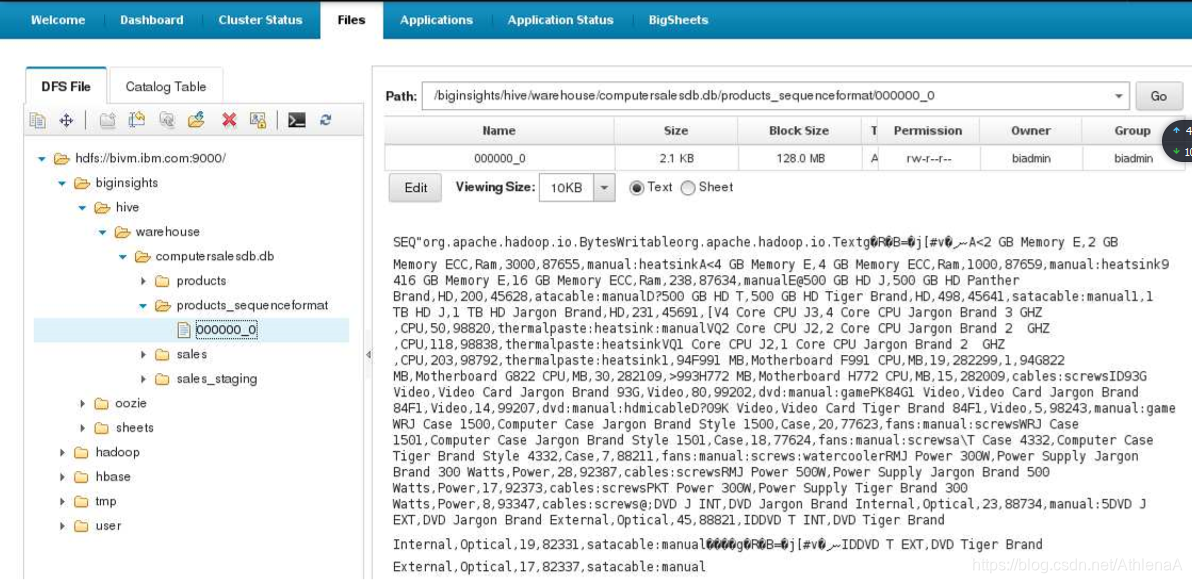
这看起来不像一个普通的文本文件,是吗?有些字符显示得很奇怪。这是一件好事——我们正在查看一个SEQUENCEFILE !
__6。让我们尝试一些不同的东西。打开一个新的Linux终端。我们可以使用HDFS fs命令中的-text选项以人类可读的格式查看数据。
~> hadoop fs –text /biginsights/hive/warehouse/computersalesdb.db/products_sequenceformat/ 000000_0;
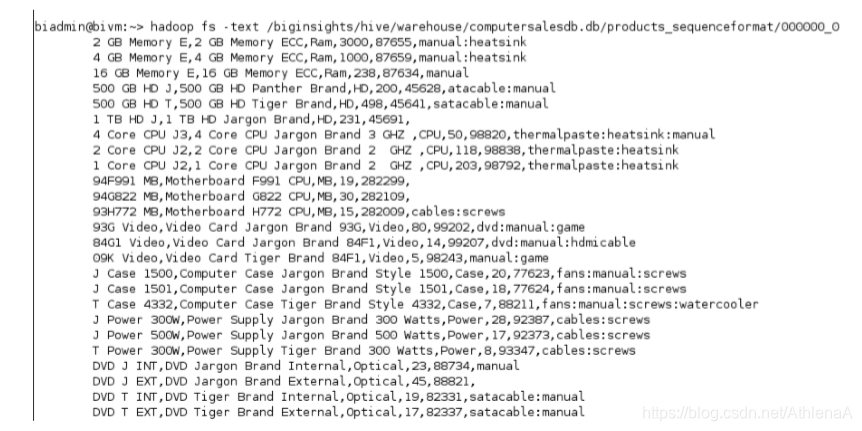
输出看起来好多了!
1.2.2 RCFile
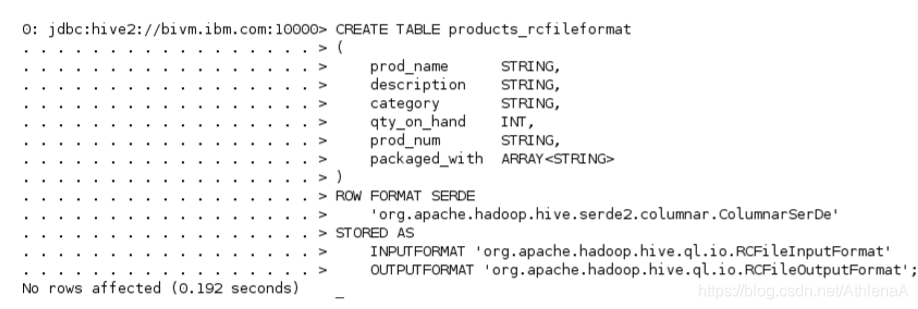
__1。在Hive中创建一个名为products_rcfileformat的新表。我们将使用与创建原始products表类似的DDL,但在本例中,我们将显式地告诉Hive使用哪种SerDe和输入/输出格式。
hive> CREATE TABLE products_rcfileformat
(
prod_name STRING,
description STRING,
category STRING,
qty_on_hand INT,
prod_num STRING,
packaged_with ARRAY
)
ROW FORMAT SERDE
‘org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe’
STORED AS
INPUTFORMAT ‘org.apache.hadoop.hive.ql.io.RCFileInputFormat’
OUTPUTFORMAT ‘org.apache.hadoop.hive.ql.io.RCFileOutputFormat’;
__2。请Hive向我们提供新products_rcfileformat表的扩展细节。
hive> DESCRIBE EXTENDED products_rcfileformat;
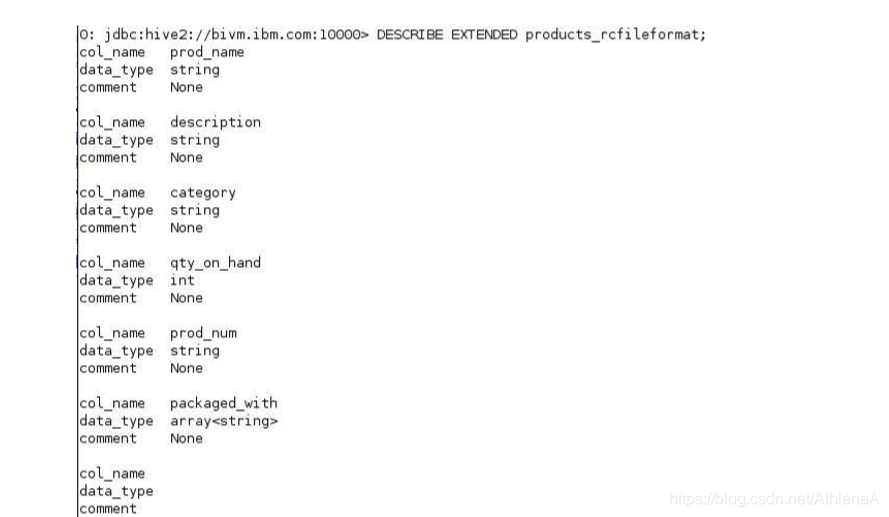

InputFormat is: org.apache.hadoop.hive.ql.io.RCFileInputFormat
OutputFormat is: org.apache.hadoop.hive.ql.io.RCFileOutputFormat
SerDe serializationLib is: org.apache.hadoop.hive.serde2.columnar.ColumnarSerde
The HDFS location of the data for this table is: /biginsights/hive/warehouse/computersalesdb.db/products_rcfileformat
看到我们如何显式地指定输入/输出格式和SerDe,这些值就不足为奇了。
__3。现在让我们用数据加载products_rcfileformat表。我们将通过运行INSERT查询来实现这一点。
hive> FROM products INSERT OVERWRITE TABLE products_rcfileformat SELECT ;

__4。将Beeline outputformat设置为table。然后从products_rcfileformat表中选择,以确保装载了产品数据。
hive> !set outputformat table
hive> SELECT * FROM products_rcfileformat;
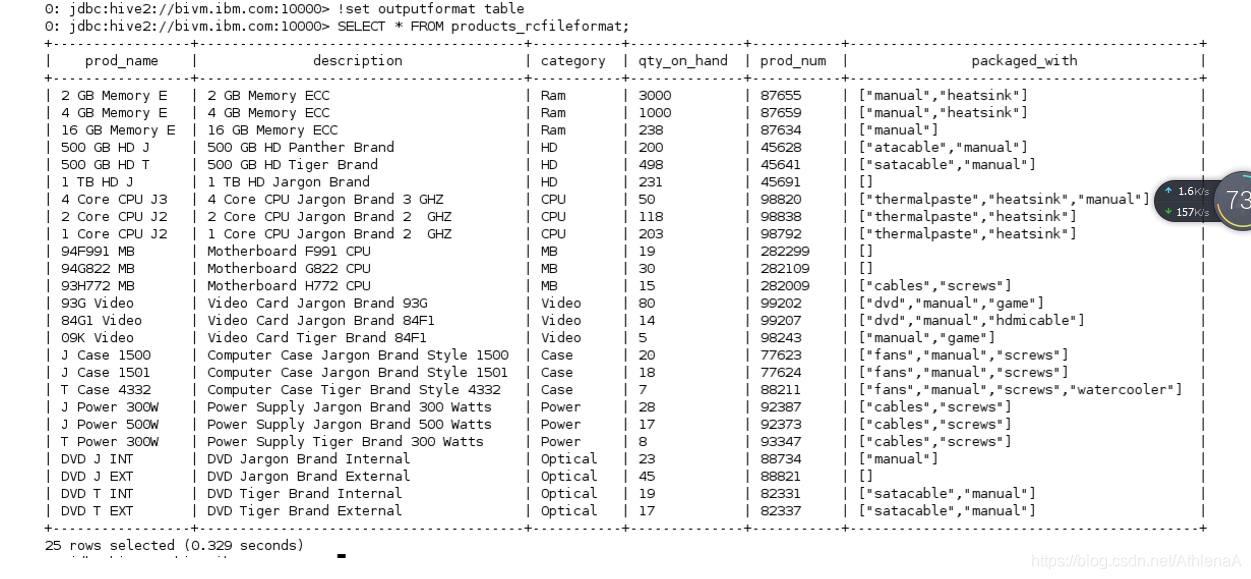 所有的数据都应该在那里。
所有的数据都应该在那里。
__5。我们可以假设Hive在HDFS上的products_rcfileformat目录中创建了一个000000_0文件。让我们在HDFS上检查这个文件,看看Hive到底为我们做了什么。打开Linux终端并运行hadoop fs -cat命令。
~> hadoop fs -cat /biginsights/hive/warehouse/computersalesdb.db/products_rcfileformat/00 0000_0;
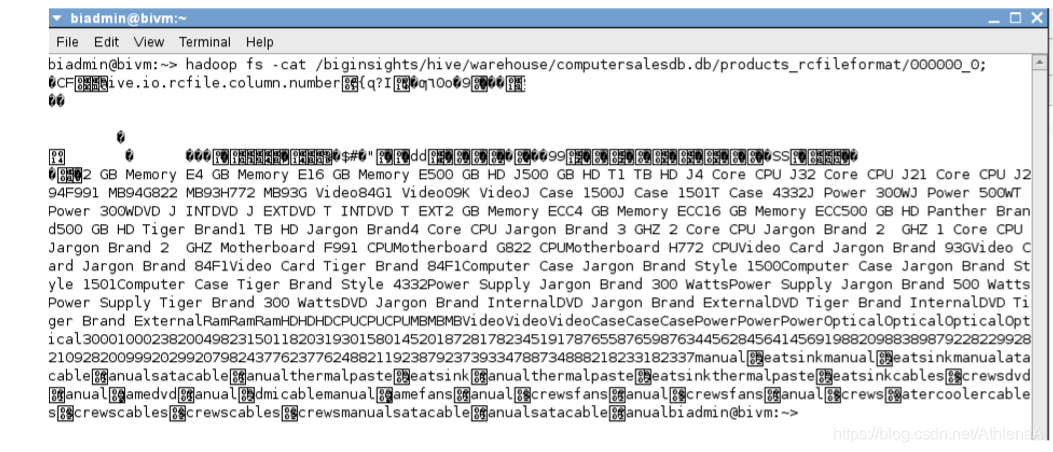
RCFile格式的文件看起来有点古怪。我们需要使用一种工具来查看它,该工具以更人性化的格式显示内容。hadoop fs -text工具也执行相同的操作,因此我们需要使用不同的工具。
__6。在Linux终端中切换到Hive home bin目录。从bin目录中,我们将向hive传递一条语句,该语句允许我们查看RCFile。
~> cd $HIVE_HOME/bin
./hive –-service rcfilecat /biginsights/hive/warehouse/computersalesdb.db/products_rcfileformat/00 0000_0
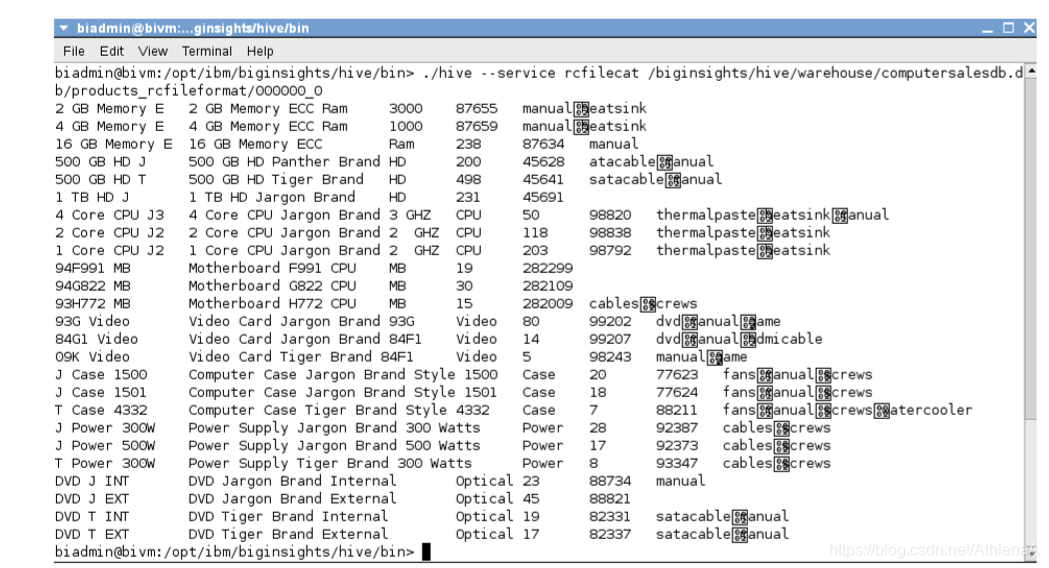 输出看起来好多了!
输出看起来好多了!
1.2.3ORC文件
__1。在Hive中创建一个名为products_orcformat的新表。除了将STORED AS子句改为ORC而不是TEXTFILE之外,我们将使用与创建原始products表完全相同的DDL。
hive> CREATE TABLE products_orcformat
(
prod_name STRING,
description STRING,
category STRING,
qty_on_hand INT,
prod_num STRING,
packaged_with ARRAY
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
COLLECTION ITEMS TERMINATED BY ‘:’
STORED AS ORC;
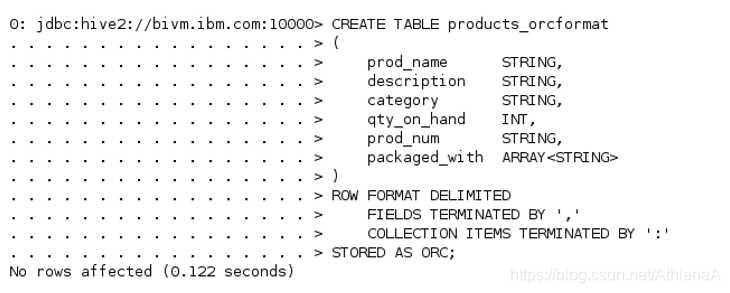
__2。将数据加载到新的ORC表中。
hive> FROM products INSERT OVERWRITE TABLE products_orcformat SELECT ;

__3。从products_orcformat表中选择,以确保装载了产品数据。
hive> SELECT * FROM products_orcformat;
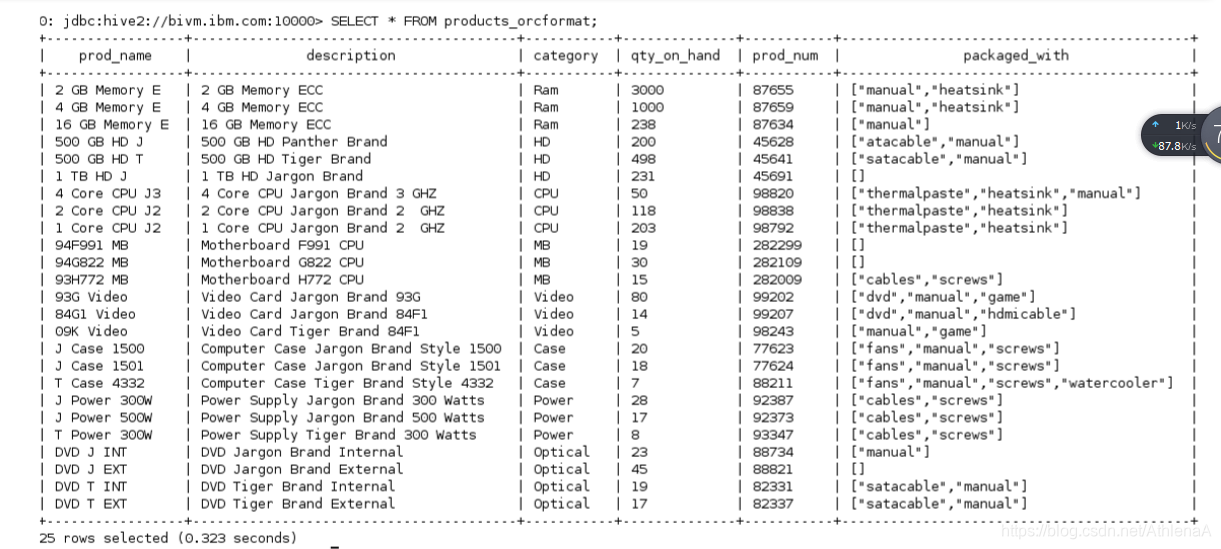
__4。让我们检查一下HDFS上的products_orcformat表,看看Hive为我们做了什么。打开BigInsights Web控制台并导航到/biginsights/hive/warehouse/computersalesdb.db/products_orcformat 目录。您将找到一个000000_0文件。如果单击此文件,数据将显示在右手查看窗格中。
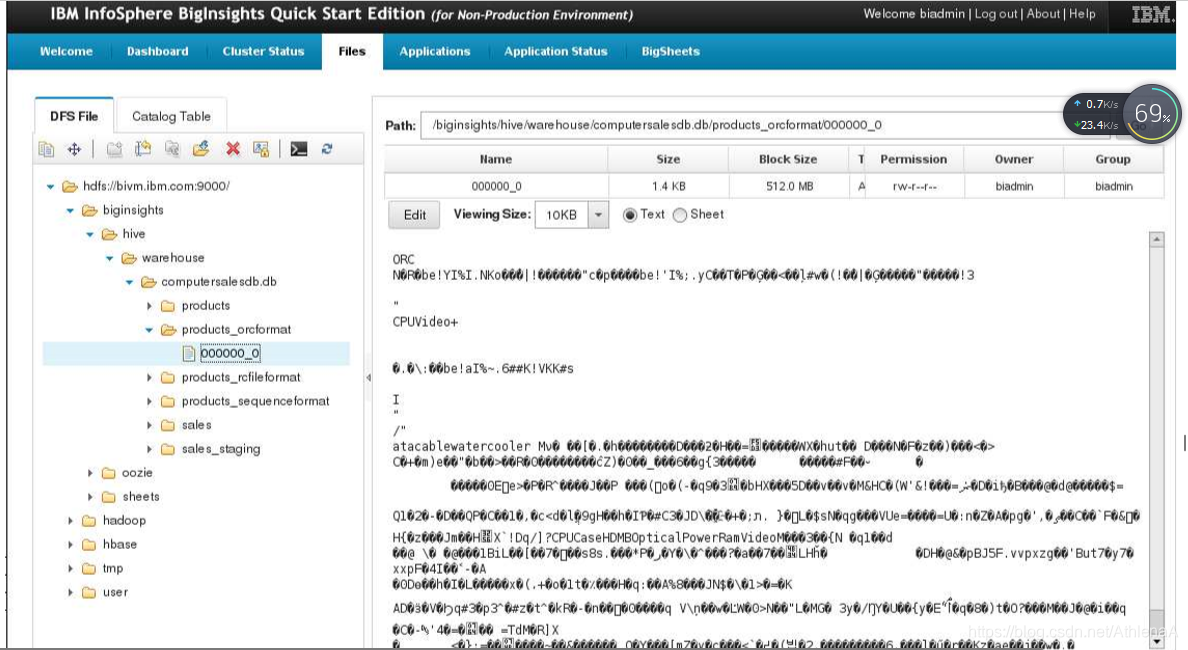
分析文件的细节,包括文件大小。
1.3压缩
在本节中,我们将使用Hive进行压缩。
__1。在Hive CLI中,输入以下set命令。这些更改只会持续这个会话。
hive> set hive.exec.compress.output=true;
hive> set mapred.output.compression.code=org.apache.hadoop.io.compress.GzipCodec;
我们告诉Hive将输出(而不是中间压缩)压缩成Gzip格式。

__2。打开BigInsights Web控制台并导航到/biginsights/hive/warehouse/computersalesdb.db/products_rcfileformat/00 0000_0 文件
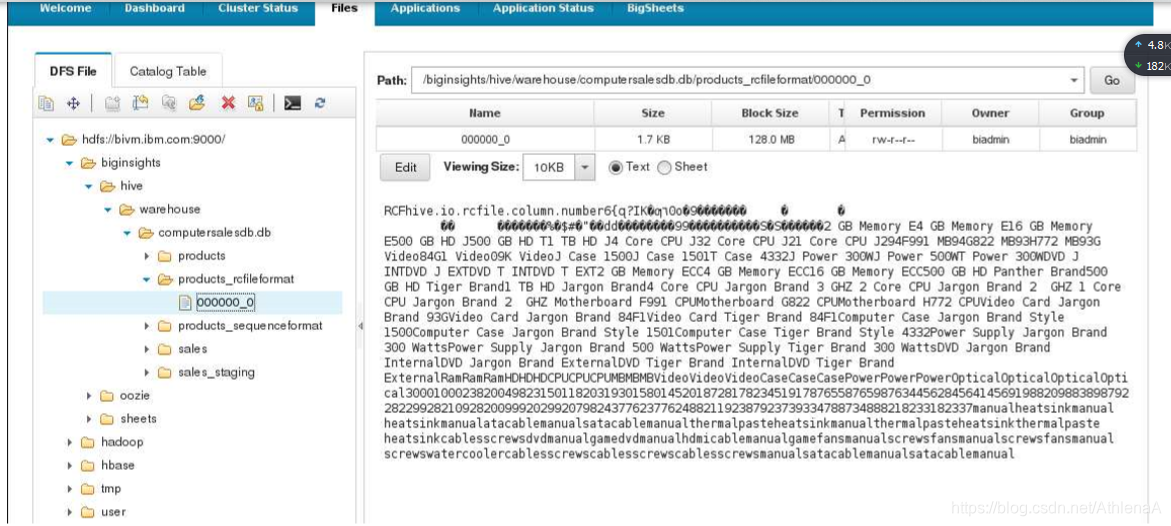
在右边,您可以看到文件大小为1.7KB。
__3。现在,让我们用products表中的数据重新加载products_rcfileformat表。
hive> FROM products INSERT OVERWRITE TABLE products_rcfileformat SELECT *;

__4。回到BigInsights Web控制台,刷新文件视图并导航到/biginsights/hive/warehouse/computersalesdb.db/products_rcfileformat/00 0000_0 文件。
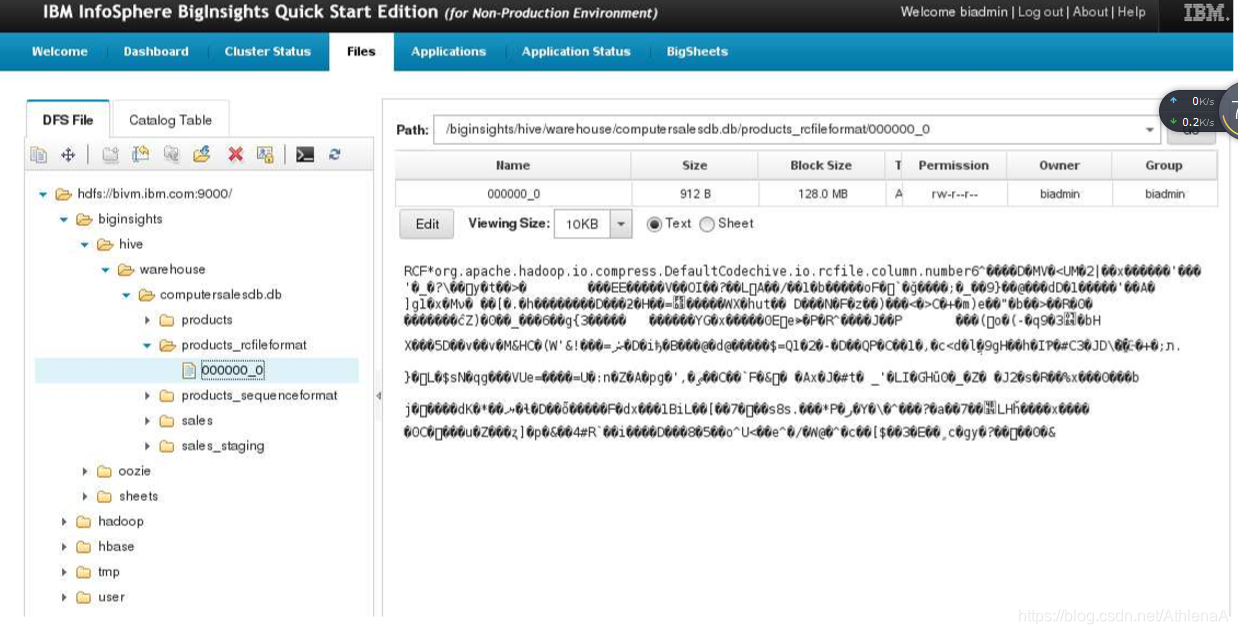
您可以看到该文件现在已经被压缩,并且肯定比以前小了!
__5。为了更好地度量,从products_rcfileformat表中运行SELECT查询,以确保仍然能够查询此压缩数据。
hive> SELECT prod_name FROM products_rcfileformat LIMIT 5;

__6。在Hive CLI中,输入以下set命令来关闭此会话的压缩。
hive> set hive.exec.compress.output=false;
1.4总结
恭喜你!现在您已经知道如何使用不同的文件格式,包括SequenceFiles、RCFiles和ORC文件。您在CREATE TABLE语句中显式地声明了输入和输出格式以及SerDe。您还在Hive中打开了输出压缩,并亲眼看到了尺寸的缩小。你可以换到下一个单位。
HiveLab6_HiveConfiguration_3_0
Accesing Hadoop Data Using Hive
Unit 6: Hive Configuration
蜂巢配置
1.1调查蜂巢配置
1.1.1配置预排
1.1.2蜂巢配置文件模板
1.2日志配置
1.3 TEMP目录
1.4 BIGINSIGHTS配置注意事项
1.5总结
实验室6蜂房配置
在这个实验室中,我们将探索Hive的一些配置文件。我们还将研究Hive使用的日志记录和临时文件空间。
完成这个动手实验后,你将能够:
•查找并更新Hive的主配置文件。
•查找Hive的日志并编辑Log4j配置。
•导航并清理Hive的临时空间。
给30分钟来完成这部分实验。
这个版本的实验室是使用InfoSphere BigInsights 3.0快速启动版设计的。在整个实验过程中,我们假定您将使用以下帐户登录信息:

如果您在使用Hive Unit 5: Hive存储格式完成对Hadoop数据的访问之后,还在继续这个系列的实验,那么您可以继续学习这个实验的1.1部分。(所有Hadoop组件应该都在运行,您应该已经创建了这个单元中使用的数据库、表和分区。)
1.1研究蜂箱配置
我们在这个实验室使用的BigInsights虚拟机对默认的Hive配置进行了一些更改。让我们研究一下hive-site.xml文件,看看是如何为我们配置的。
1.1.1配置预排
让我们看一看hive-site.xml并分析所有配置变量。
__1。打开一个新的Linux终端。然后输入gedit命令打开Linux gedit文本编辑器程序。
~> gedit
__2。单击文本编辑器屏幕顶部的Open图标。将弹出一个打开的文件框。
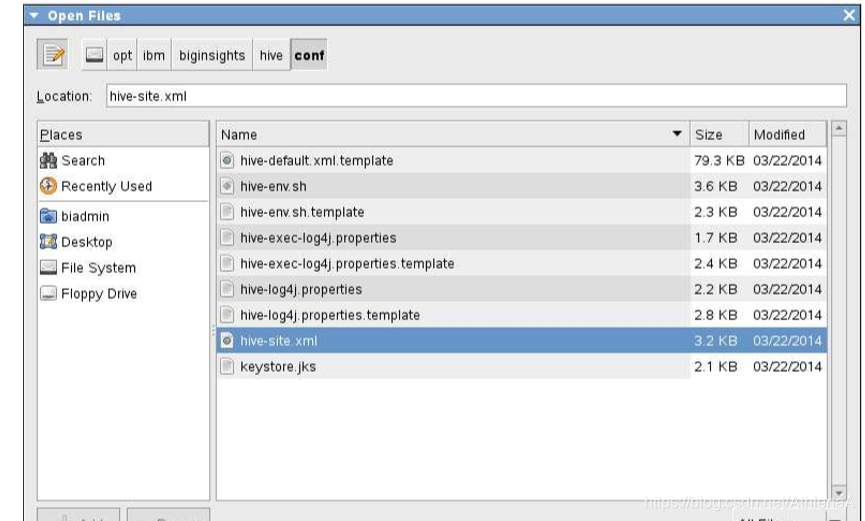
__3。在/opt/ibm/biginsights/hive/conf目录中导航并打开hive-site.xml文件。
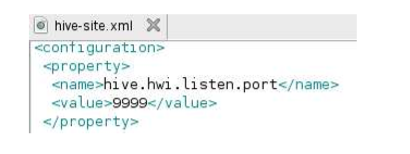
__4。hive-site.xml 文件中遇到的第一个属性是hive.hwi.listen.port 变量。它被设置为9999。此变量保存Hive Web接口将侦听的端口号。
__5。向下移动,下一个变量是hive.querylog.location。它存储创建结构化hive查询日志的目录。

__6。下一个变量是hive.metastore.warehouse.dir。这是本机Hive表的默认位置的URI。

__7。接下来列出的三个变量是hive.hwi.war.file, hive.warehouse.subdir.inherit.perms and hive.metastore.metrics.enabled.
第一个保存带有Hive Web接口jsp内容的WAR文件。第二个涉及表目录权限。第三个与亚转移性指标有关。

__8。接下来是metastore配置设置。我们正在使用一个通过JDBC访问的DB2数据库。

__9。下一个属性是org.jpox.autoCreateSchema。该属性控制您是希望JPOX创建数据库模式来持久化JDO对象,还是希望它使用现有的模式。
__10。让我们看看下面四个属性。hive.server2.thrift.min.worker.threads 属性控制HiveServer2的最小工作线程数。hive.server2.thrift.max.worker.threads 属性控制工作线程的最大数量。hive.server2.thrift.port属性控制要监听的TCP端口号。hive.server2.thrift.bind.host 属性控制要绑定的TCP接口。

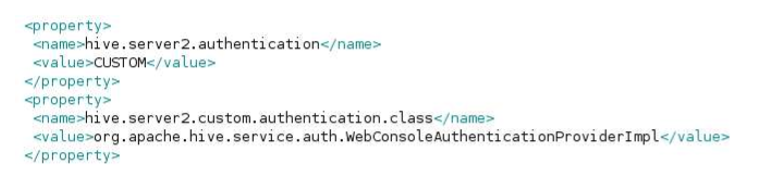
__11。接下来的两个配置属性是hive.server2.authentication and hive.server2.custom.authentication.class.
hive.server2.authentication 属性设置为CUSTOM, hive.server2.custom.authentication.class告诉Hive使用哪个类进行自定义身份验证。
__12。下一个属性是 hive.server2.enable.doAs。这个属性告诉HiveServer2模拟连接的用户(提交查询的用户)。如果设置为false,那么查询将作为HiveServer2进程运行的用户运行。

__13。最后的属性控制更多的安全性和授权设置。

1.1.2 Hive配置文件模板
__1。如果您正在设置自己的Hive安装,那么可以使用Hive安装一个有用的模板文件,该文件包含各种配置变量以及它们的功能信息。在Linux文本编辑器中,打开hive-default.xml。模板文件位于/opt/ibm/biginsights/hive/conf目录中。花点时间分析这个文件。

1.2日志配置
现在我们来看看Hive的Log4j配置。
__1。在文本编辑器应用程序(又名“gedit”)中,打开 hive-log4j.properties 文件(位于/opt/ibm/biginsights/hive/conf目录中)。
__2。该文件的顶部包含一些关键配置细节。

注意hive.log的位置。dir是- /var/ibm/biginsights/hive/logs/${user.name}
__3。让我们打开一个hive日志文件。在文本编辑器中打开/var/ibm/biginsights/hive/logs/hive/hive.log

您的日志看起来可能与屏幕截图有点不同。花点时间浏览日志。
1.3临时目录
Hive在运行作业时使用临时目录。让我们调查。
__1。在前面分析 hive-default.xml.template 文件时,您可能已经注意到hive.exec.scratchdir 的默认设置 是/tmp/hive-${user.name}。因为我们的hive-site.xml文件没有指定 hive.exec.scratchdir 变量,我们可以假设Hive使用默认值。

__2。在BigInsights Web控制台中,转到Files选项卡并导航到HDFS上的/tmp/hive-hive。
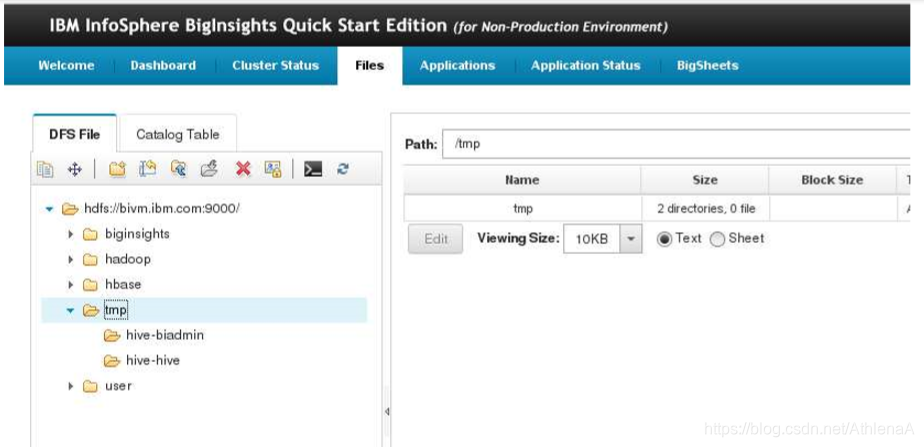
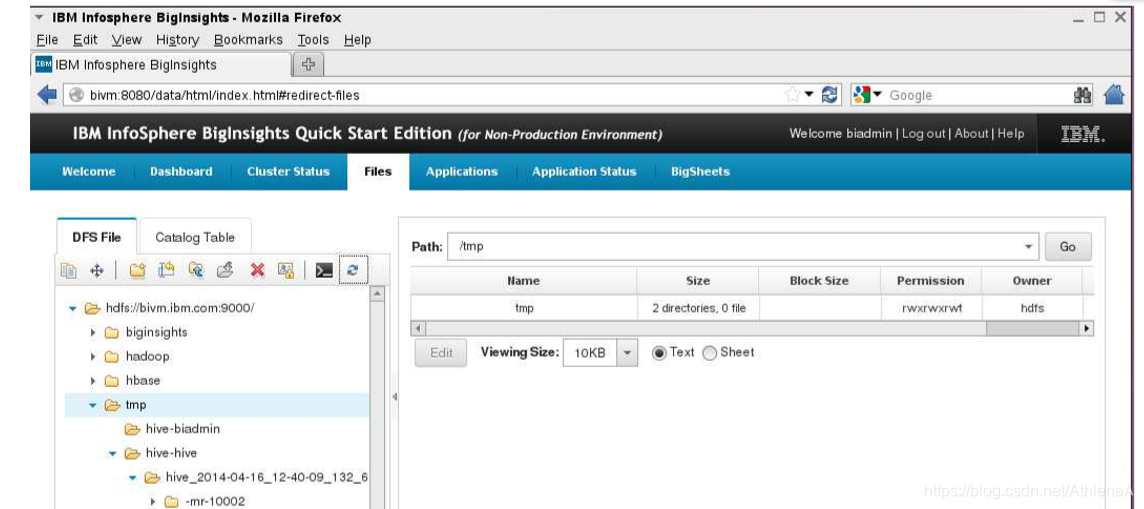
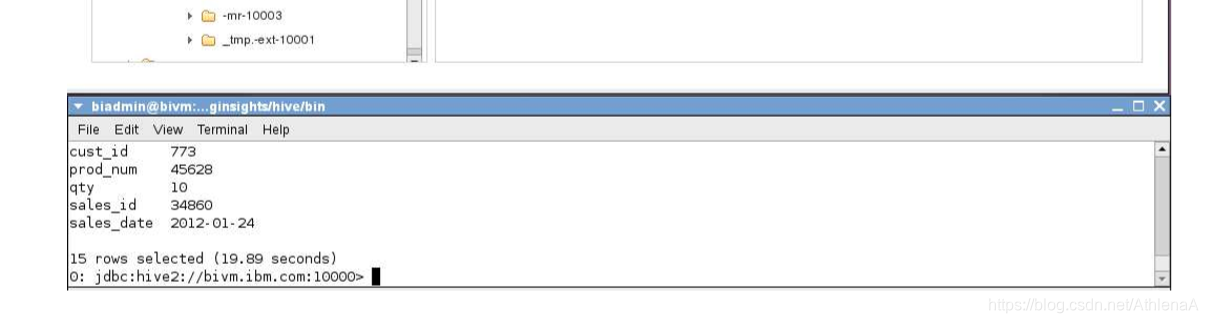
您可能会看到一个空目录。如果您要运行Hive作业并刷新tmp文件空间,您可能会看到临时文件正在运行!下面是在CLI底层shell中运行的一个简单的SELECT查询。BigInsights Web控制台显示了/tmp/hivehive目录中的内容……创建了相当多的新文件夹,然后在作业完成时删除。
1.4 BigInsights配置说明
我们鼓励您在BigInsights虚拟机上试验Hive配置更改。如果您更改了Hive的配置文件,最好是:
1.更改配置文件
2.停止蜂巢
3.运行位于/opt/ibm/biginsights/bin目录中的syncconf.sh脚本
4. 开始蜂巢
sh脚本同步一个或多个BigInsights组件的配置。如果指定了所有组件,它将同步所有组件的配置。此命令仅适用于hadoop、hbase、hive和zookeeper等分布式组件。
1.5总结
恭喜你!现在您知道了如何调查和更新Hive的主配置文件。您还知道如何查找Hive的日志并编辑Log4j配置。最后,您可以在Hive作业提前终止的情况下导航到并清理Hive的临时空间。