==========================================PHP===================================================
1:请用最简单的语言告诉我PHP是什么?
PHP全称:Hypertext Preprocessor,是一种用来开发动态网站的服务器脚本语言。
2:什么是MVC?
MVC由Model(模型), View(视图)和Controller(控制器)组成,PHP MVC可以更高效地管理好3个不同层的PHP代码。
Model:数据信息存取层。
View:view层负责将应用的数据以特定的方式展现在界面上。
Controller:通常控制器负责从视图读取数据,控制用户输入,并向模型发送数据。
3:PHP支持多继承吗?
不可以。PHP类只能继承一个父类,并用关键字“extends”标识。
被继承的方法和属性可以通过用同样的名字重新声明被覆盖。但是如果父类定义方法时使用了 final,则该方法不可被覆盖。可以通过 parent:: 来访问父类中的方法或属性。
当覆盖方法时,参数必须保持一致否则 PHP 将发出 E_STRICT 级别的错误信息。但构造函数例外,构造函数可在被覆盖时使用不同的参数。
Final 关键字
PHP 5新增的一个关键字,如果父类中的方法被声明为 final,则子类无法覆盖该方法。同样如果一个类被声明为 final,则不能被继承。(需要注意的是: 属性不能被定义为 final,只有类和方法才能被定义为 final。)
4:php中对数组序列化和反序列化的函数分别是 serialize 和 unserialize ;
urlencode和rawurlencode两个方法在处理字母数字,特殊符号,中文的时候结果都是一样的,唯一的不同是对空格的处理,urlencode处理成“+”,rawurlencode处理成“%20”。
6:php中过滤HTML的函数是strip_tags,转义的函数是htmlspecialchars ;
7:写出用正则把HTML中的js脚本过滤掉
preg_replace(‘/<script.*?//script>/is’,”,$htmlcode);
8:写出三个调用系统命令的函数:exec、system、passthru

9:php中判断变量是否被设置是函数是_isset_;判断是否为空的是empty;
empty、 isset、is_null的区别:
empty: 如果 变量 是非空或非零的值,则 empty() 返回 FALSE。换句话说,”"、0、”0″、NULL、FALSE、array()、var $var、未定义;以及没有任何属性的对象都将被认为是空的,如果 var 为空,则返回 TRUE。
isset: 如果 变量 存在(非NULL)则返回 TRUE,否则返回 FALSE(包括未定义)。变量值设置为:null,返回也是false;unset一个变量后,变量被取消了。注意,isset对于NULL值变量,特殊处理。is_null: 检测传入值【值,变量,表达式】是否是null,只有一个变量定义了,且它的值是null,它才返回TRUE . 其它都返回 FALSE 【未定义变量传入后会出错!】
10:error_reporting(“E_ALL”)和ini_set(“display_errors”, “on”)的区别_________;
前者是设置错误显示等级,E_ALL代表提示全部错误(包括notice,warnning和error)。后者是设置让php显示错误,在关于错误显示控制中,后者的优先级最高。
11:PHP写出显示客户端IP的预定义变量$_SERVER['REMOTE_ADDR'];
提供来路url的是$_SERVER['HTTP_REFERER'];
$_SERVER['REMOTE_HOST'] //当前用户主机名;
$_SERVER['PHP_SELF']//正在执行脚本的文件名
$_SERVER['REQUEST_METHOD']//访问页面时的请求方法
$_SERVER['SCRIPT_FILENAME'] #当前执行脚本的绝对路径名。
$_SERVER['SERVER_PORT'] #服务器所使用的端口
12:php把utf-8转换成gbk的函数是iconv(‘UTF-8′,’GBK’,$str);
13:php中类的静态方法怎么使用?
在类外部,使用:类名后面跟双冒号,再后面是方法名,类似classname::staticFucntion(),由于静态方法不属于某个对象,而是隶属于整个类,所以要用类名来调用它。
14:$a = 1; $b = & $a;
unset($a),$b是否还是1,为什么?
unset($b),$a是否还是1,为什么?
都等于1。
在php中,引用赋值不同于指针的感念,他只是将另一个变量名指向了某个内存地址。此题中:$b = &$a;只是将$b这个名字也指向了$a变量所指向的内存地址。unset时只是释放了这个名字的指向,并没有释放内存中的值。另一方面讲unset($a),其实也并未真正立刻释放内存中的值,也只是释放了这个名字的指向而已,该函数只有在变量值所占空间超过256字节长的时候才会释放内存,并且只有当指向该值的所有变量(比如有引用变量指向该值)都被销毁后,地址才会被释放。
15:写一个判断手机号码(号段为130-139,150-159,170-179,180-189)是否正确的正则表达式。
/^(((13[0-9]{1})|(15[0-9]{1})|(17[0-9]{1})|(18[0-9]{1}))+\d{8})&/
16:请问PHP中echo和print有什么区别?
echo和print的本质区别在于:echo用来输出字符串,显示多个值的时候可以用逗号隔开。只支持基本类型,print不仅可以打印字符串值,而且可以打印函数的返回值。
17:请问GET和POST方法有什么区别?
我们在网页上填写的表单信息都可以通过这两个方法将数据传递到服务器上,当我们使用GET方法是,所有的信息都会出现在URL地址中,并且使用GET方法最多只能传递1024个字符,所以如果在传输量小或者安全性不那么重要的情况下可以使用GET方法。说到POST方法,最多可以传输2MB字节的数据,而且可以根据需要调节。
18:PHP中获取图像尺寸大小的方法是什么?
getimagesize () 获取图片的尺寸
Imagesx () 获取图片的宽度
Imagesy () 获取图片的高度
19:PHP中的PEAR是什么?
PEAR也就是为PHP扩展与应用库(PHP Extension and Application Repository),它是一个PHP扩展及应用的一个代码仓库。
20:如何用PHP和MySQL上传视频?
我们可以在数据库中存放视频的地址,而不需要将真正的视频数据存在数据库中。可以将视频数据存放在服务器的指定文件夹下,上传的默认大小是2MB,但是我们也可以在php.ini文件中修改max_file size选项来改变。
21:PHP中的错误类型有哪些?
PHP中遇到的错误类型大致有3类。
提示(notice):这都是一些非常正常的信息,而非重大的错误,有些甚至不会展示给用户。比如访问不存在的变量。
警告(warning):这是有点严重的错误,将会把警告信息展示给用户,但不会影响代码的输出,比如包含一些不存在的文件。
错误(error):这是真正的严重错误,比如访问不存在的PHP类。
22:如何在PHP中定义常量?
PHP中使用Define () 来定义常量。
define (“Newconstant”, 30); echo constant("Newconstant"); //constant返回一个常量的值
23:在网站开发中需要传递变量值时,不能使用session、cookie、application,你有几种方法
Session id的传递主要有四个方法:
1、 通过cookie。
2、 设置php.ini中的session.use_trans_sid = 1或者编译时打开打开了--enable-trans-sid选项,让PHP自动跨页传递session id。
3、 手动通过url或隐藏表单传值。
4、 用文件或数据库方式传递,在通过其他key对应取值。
以上的2和3其实使用的是同样的方法,只是途径不一样。
通过以上的分析我们不难看出,通过cookie传递sessionid,将session存储于memcache服务器中是为一个比较合理的选择。当出现跨域的情况是,可以使用p3p跨域设置cookie。而当客户端禁用cookie的情况下,可以设置php.ini,通过url自动传递session id。
24:概述反射和序列化
序列化:
serialize() 把变量和它们的值编码成文本形式
unserialize() 恢复原先变量
25:session喜欢丢值且占用内存,Cookie不安全,请问用什么办法代替这两种原始的方法
redis 或者 memcache。
26:反射
反射是在PHP运行状态中,扩展分析PHP程序,导出或提取出关于类、方法、属性、参数等的详细信息,包括注释。这种动态获取的信息以及动态调用对象的方法的功能称为反射API。反射是操纵面向对象范型中元模型的API,其功能十分强大,可帮助我们构建复杂,可扩展的应用。
其用途如:自动加载插件,自动生成文档,甚至可用来扩充PHP语言。
php反射api由若干类组成,可帮助我们用来访问程序的元数据或者同相关的注释交互。借助反射我们可以获取诸如类实现了那些方法,创建一个类的实例(不同于用new创建),调用一个方法(也不同于常规调用),传递参数,动态调用类的静态方法。
反射api是php内建的oop技术扩展,包括一些类,异常和接口,综合使用他们可用来帮助我们分析其它类,接口,方法,属性,方法和扩展。这些oop扩展被称为反射。
通过ReflectionClass,我们可以得到Person类的以下信息:
1)常量 Contants
2)属性 Property Names
3)方法 Method Names静态
4)属性 Static Properties
5)命名空间 Namespace
6)Person类是否为final或者abstract
27:请使用正则写一个函数验证电子邮件的格式是否正确?
preg_match('/^[\w\-\.]+@[\w\-]+(\.\w+)+$/',$email);
28:面向对象
三大特性:封装、继承、多态(方法重写)。
抽象类:abstract,至少有一个方法是抽象方法,不能被实例化,为子类定义公共接口。
接口:interface,解决php的单继承问题,所有方法都是public访问权限的抽象方法,不能声明变量只能声明常量。
继承一个类的同时实现多个接口
-
class A extends B implements 接口1,接口2...,接口n(){ -
//实现所有接口中的方法 -
}
29:进程和线程定义,区别和联系。
进程的状态:运行run、就绪ready、等待wait
30:Include require include_once require_once 的区别.
处理失败方式不同:
require 失败时会产生一个致命级别错误,并停止程序运行。
include 失败时只产生一个警告级别错误,程序继续运行。
include_once/require_once和include/require 处理错误方式一样,
唯一区别在于当所包含的文件代码已经存在时候,不在包含。
31:HEREDOC介绍
一种定义字符串的方法。
结构:
<<<。在该提示符后面,要定义个标识符(单独一行),
然后是一个新行。接下来是字符串 本身,
最后要用前面定义的标识符作为结束标志(单独一行)
注意:
标识符的命名也要像其它标签一样遵守PHP的规则:
只能包含字母、数字和下划线,并且必须以字母和下划线作为开头
32:写出一些php魔幻(术)方法
__construct() 实例化类实自动调用
——destruct() 类对象使用结束时自动调用
__set() 在给未定义的属性赋值时调用
__get() 调用未定义的属性时调用哦
__isset() 使用isset()或empty()函数的时候调用
__unset() 使用unset()函数的时候调用
__sleep() 使用serialize序列化的时候调用
__wakeup() 使用unserialize()反序列化的时候调用
__call() 调用一个不存在的方法时调用
__callStatic() 调用一个不存在的静态方法时调用
__toString() 把对象转换Wie字符串的是调用,比如echo
__clone() 当使用clone复制一个对象时候调用。
__invoke() 当尝试把对象当方法调用时调用。
__set_state() 当使用var_export()函数时候调用。接受一个数组参数。
33:一些编译php时的configure 参数
–prefix=/usr/local/php php安装目录
–with-config-file-path=/usr/local/php/etc 指定php.ini位置
–with-mysql=/usr/local/mysql mysql安装目录,对mysql的支持
–with-mysqli=/usr/local/mysql/bin/mysql_config mysqli文件目录,优化支持
–enable-safe-mode 打开安全模式
–enable-ftp 打开ftp的支持
–enable-zip 打开对zip的支持
–with-bz2 打开对bz2文件的支持
–with-jpeg-dir 打开对jpeg图片的支持
–with-png-dir 打开对png图片的支持
–with-freetype-dir 打开对freetype字体库的支持
–without-iconv关闭iconv函数,种字符集间的转换
–with-libxml-dir 打开libxml2库的支持
–with-xmlrpc 打开xml-rpc的c语言
–with-zlib-dir 打开zlib库的支持
–with-gd 打开gd库的支持
34:向php传入参数的三种方法。
方法一 使用$argc $argv
方法二 使用getopt函数()
方法三 提示用户输入,然后获取输入的参数。有点像C语言
35:error_reporting 等调试函数使用
error_reporting() 函数能够在运行时设置php.ini中 error_reporting 指令。
所以可以再程序中随时调节显示的错误级别。
使用此函数时 display_errors必须是打开状态。
36:写一段上传文件的代码。
upload.html
-
<span style="white-space:pre"> </span><form enctype="multipart/form-data" method="POST" action="upload.php"> -
Send this file: <input name="name" type="file" /> -
<input type="submit" value="Send File" /> -
</form>
upload.php
-
<span style="white-space:pre"> </span>$uploads_dir = '/uploads'; -
foreach ($_FILES["error"] as $key => $error) { -
if ($error == UPLOAD_ERR_OK) { -
$tmp_name = $_FILES["tmp_name"][$key]; -
$name = $_FILES["name"][$key]; -
move_uploaded_file($tmp_name, "$uploads_dir/$name"); -
} -
}
37:写代码来解决多进程/线程同时读写一个文件的问题。
PHP是不支持多线程的,可以使用php的flock加锁函数实现。
-
<span style="white-space:pre"> </span>$fp = fopen("/tmp/lock.txt", "w+"); -
if (flock($fp, LOCK_EX)) { // 进行排它型锁定 -
fwrite($fp, "Write something here\n"); -
flock($fp, LOCK_UN); // 释放锁定 -
} else { -
echo "Couldn't lock the file !"; -
} -
fclose($fp);
38:$_POST/$HTTP_RAW_POST_DATA和php://input的区别
$_POST是获取表单提交的数据,media type是"applicaiton/x-www-form-urlencoded"。字段名和值都进行了编码,每个key-value队使用‘$’分隔,key和value使用‘=’分开,其他特殊字符都会被urlencode进行编码
$HTTP_RAW_POST_DATA:可以获取原始的POST数据,但需要在php.ini中设置开启,并且不支持enctype='multipart/form-data'方式传递的数据
php://input:可以获取POST数据,但是比$HTTP_RAW_POST_DATA跟少的消耗内存,也不支持‘multipart/form-data’
39:PHP常用的设计模式:
1.简单工厂模式
##工厂模式是一种类,具有为民创建对象的某些方法。可以用工厂类创建对象而不直接使用new方法
特点:
1.抽象基类:类中定义抽象一些方法,用以在子类中实现
2.继承自抽象基类的子类:实现基类中的抽象方法
3.工厂类:用以实例化所有相对应的子类
代码实例;
-
<span style="white-space:pre"> </span>/** -
* 定义个抽象的类,让子类去继承实现它 -
*/ -
abstract class Operation{ -
//抽象方法不能包含函数体 -
abstract public function getValue($num1,$num2);//强烈要求子类必须实现该功能函数 -
} -
/** -
* 加法类 -
*/ -
class OperationAdd extends Operation { -
public function getValue($num1,$num2){ -
return $num1+$num2; -
} -
} -
/** -
* 减法类 -
*/ -
class OperationSub extends Operation { -
public function getValue($num1,$num2){ -
return $num1-$num2; -
} -
} -
/** -
* 工程类,主要用来创建对象 -
* 功能:根据输入的运算符号,工厂就能实例化出合适的对象 -
*/ -
class Factory{ -
public static function createObj($operate){ -
switch ($operate){ -
case '+': -
return new OperationAdd(); -
break; -
case '-': -
return new OperationSub(); -
break; -
case '*': -
return new OperationSub(); -
break; -
case '/': -
return new OperationDiv(); -
break; -
} -
} -
} -
$test=Factory::createObj('/'); -
$result=$test->getValue(23,0); -
echo $result;
2.单例模式--数据库应用
特点:
a是某个类只能有一个实例;
b是它必须自行创建这个实例;
c是它必须自行向整个系统提供这个实例
为什么要使用PHP单例模式:
1. php的应用主要在于数据库应用, 一个应用中会存在大量的数据库操作, 在使用面向对象的方式开发时, 如果使用单例模式, 则可以避免大量的new 操作消耗的资源,还可以减少数据库连接这样就不容易出现 too many connections情况。
2. 如果系统中需要有一个类来全局控制某些配置信息, 那么使用单例模式可以很方便的实现. 这个可以参看zend Framework的FrontController部分。
3. 在一次页面请求中, 便于进行调试, 因为所有的代码(例如数据库操作类db)都集中在一个类中, 我们可以在类中设置钩子, 输出日志,从而避免到处var_dump, echo。
3.观察者模式
观察者模式属于行为模式,是定义对象间的一种一对多的依赖关系,以便当一个对象的状态发生改变时,所有依 赖于它的对象都得到通知并自动刷新。
4.策略模式
在此模式中,算法是从复杂类提取的,因而可以方便地替换.例如,如果要更改搜索引擎中排列页的方法,则策略模式是一个不错的选择。思考一下搜索引擎的几个部分 —— 一部分遍历页面,一部分对每页排列,另一部分基于排列的结果排序。在复杂的示例中,这些部分都在同一个类中。通过使用策略模式,您可将排列部分放入另一个类中,以便更改页排列的方式,而不影响搜索引擎的其余代码。
此模式非常适合复杂数据管理系统或数据处理系统,二者在数据筛选、搜索或处理的方式方面需要较高的灵活性
5.命令链模式
40:抽象类和接口:
一、 抽象类abstract class
1 .抽象类是指在 class 前加了 abstract 关键字且存在抽象方法的类(在类方法 function 关键字前加了 abstract 关键字)
2.抽象类不能被直接实例化。抽象类中只定义(或部分实现)子类需要的方法。子类可以通过继承抽象类并通过实现抽象类中的所有抽象方法,使抽象类具体化。
3.如果子类需要实例化,前提是它实现了抽象类中的所有抽象方法。如果子类没有全部实现抽象类中的所有抽象方法,那么该子类也是一个抽象类,必须在 class 前面加上 abstract 关键字,并且不能被实例化。
-
<span style="white-space:pre"> </span>abstract class A{ -
/** 抽象类中可以定义变量 */ -
protected $value1 = 0; -
private $value2 = 1; -
public $value3 = 2; -
/** 也可以定义非抽象方法 */ -
public function my_print(){ -
echo "hello,world/n"; -
} -
/** -
* 大多数情况下,抽象类至少含有一个抽象方法。抽象方法用abstract关键字声明,其中不能有具体内容。 -
* 可以像声明普通类方法那样声明抽象方法,但是要以分号而不是方法体结束。也就是说抽象方法在抽象类中不能被实现,也就是没有函数体“{some codes}”。 -
*/ -
abstract protected function abstract_func1(); -
abstract protected function abstract_func2(); -
} -
abstract class B extends A{ -
public function abstract_func1(){ -
echo "implement the abstract_func1 in class A/n"; -
} -
/** 这么写在zend studio 8中会报错*/ -
//abstract protected function abstract_func2(); -
} -
class C extends B{ -
public function abstract_func2(){ -
echo "implement the abstract_func2 in class A/n"; -
} -
}
41:以下输出结果为7,因为=是赋值的意思
-
$z=2; -
$x=$z+$z+$z=3; -
echo $x;
42:请介绍Session的原理,大型网站中Session方面应注意什么?
PHP SESSION原理:
session是在服务器端保持用户会话数据的一种方法,对应的cookie是 在客户端保持用户数据。
首先要将客户端和服务器端建立一一联系,每个客户 端都得有一个唯一标识,这样服务器才能识别出来。建议唯一标识的方法有两种:cookie或者通过GET方式指定。默认配置的PHP使用session的 时会建立一个名叫”PHPSESSID”的cookie(可以通过php.ini修改session.name值指定),如果客户端禁用cookie,你 也可以指定通过GET方式把session id传到服务器(修改php.ini中session.use_trans_sid等参数)。
session是保存的服务端的,在服务器端session.save_path目录会发现很多类似sess_vv9lpgf0nmkurgvkba1vbvj915这样的文件,这个就是session id "vv9lpgf0nmkurgvkba1vbvj915"对应的数据。客户端将session id传递到服务器,服务器根据session id找到对应的文件,读取的时候对文件内容进行反序列化就得到session的值,保存的时候先序列化再写入。
session影响系统性能:
session 在大访问量网站上确实影响系统性能,影响性能的原因之一由文件系统设计造成,在同一个目录下超过10000个文件时,文件的定位将非常耗时,PHP支持 session目录hash,我们可以通过修改php.ini中session.save_path = “2;/path/to/session/dir”,那么session将存储在两级子目录中,每个目录有16个子目录[0~f],不过好像PHP session不支持创建目录,你需要事先把那么些目录创建好 。
session数据都不会太大(1~2K),如果有大量这样1~2K的文件在磁盘上,IO效率肯定会很差
存储session的方式有很多种,可以通过php -i|grep “Registered save handlers”查看。比如memcached,mysql等
session的同步
1.如果存储在memcached或者MySQL中比较容易,
2.如果是文件形式的,你可以用NFS统一存储。
3.通过加密的cookie来实现
4.在负载均衡那一层保持会话,把访问者绑定在某个服务器上,他的所有访问都在那个服务器上就不需要session同步了,这些都是运维层面的东西。
43:禁用cookie的session使用方案
1.url传值,
2.通过隐藏表单提交,
3.配置php.ini将session.use_trans_sid设为1,
4.用文件或数据库等形式保存session_id,在跨页过程中手动调用
44:PHP缓存技术有哪些?
1、全页面静态化缓存。也就是将页面全部生成html静态页面,用户访问时直接访问的静态页面,而不会去走php服务器解析的流程。此种方式,在CMS系统中比较常见,比如dedecms;
Ob_start()
******要运行的代码*******
$content = Ob_get_contents();
****将缓存内容写入html文件*****
Ob_end_clean();
2、页面部分缓存
该种方式,是将一个页面中不经常变的部分进行静态缓存,而经常变化的块不缓存,最后组装在一起显示;可以使用类似于ob_get_contents的方式实现,也可以利用类似ESI之类的页面片段缓存策略,使其用来做动态页面中相对静态的片段部分的缓存(ESI技术,请baidu,此处不详讲)。
该种方式可以用于如商城中的商品页;
3、数据缓存
顾名思义,就是缓存数据的一种方式;比如,商城中的某个商品信息,当用商品id去请求时,就会得出包括店铺信息、商品信息等数据,此时就可以将这些数据缓存到一个php文件中,文件名包含商品id来建一个唯一标示;下一次有人想查看这个商品时,首先就直接调这个文件里面的信息,而不用再去数据库查询;其实缓存文件中缓存的就是一个php数组之类;
Ecmall商城系统里面就用了这种方式;
4、查询缓存
其实这跟数据缓存是一个思路,就是根据查询语句来缓存;将查询得到的数据缓存在一个文件中,下次遇到相同的查询时,就直接先从这个文件里面调数据,不会再去查数据库;但此处的缓存文件名可能就需要以查询语句为基点来建立唯一标示;
按时间变更进行缓存
其实,这一条不是真正的缓存方式;上面的2、3、4的缓存技术一般都用到了时间变更判断;就是对于缓存文件您需要设一个有效时间,在这个有效时间内,相同的访问才会先取缓存文件的内容,但是超过设定的缓存时间,就需要重新从数据库中获取数据,并生产最新的缓存文件;比如,我将我们商城的首页就是设置2个小时更新一次;
5、按内容变更进行缓存
这个也并非独立的缓存技术,需结合着用;就是当数据库内容被修改时,即刻更新缓存文件;
比如,一个人流量很大的商城,商品很多,商品表必然比较大,这表的压力也比较重;我们就可以对商品显示页进行页面缓存;
当商家在后台修改这个商品的信息时,点击保存,我们同时就更新缓存文件;那么,买家访问这个商品信息时,实际上访问的是一个静态页面,而不需要再去访问数据库;
试想,如果对商品页不缓存,那么每次访问一个商品就要去数据库查一次,如果有10万人在线浏览商品,那服务器压力就大了;
6、内存式缓存
提到这个,可能大家想到的首先就是Memcached;memcached是高性能的分布式内存缓存服务器。 一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、 提高可扩展性。
它就是将需要缓存的信息,缓存到系统内存中,需要获取信息时,直接到内存中取;比较常用的方式就是 key–>value方式;
-
<?php -
$memcachehost = '192.168.6.191'; -
$memcacheport = 11211; -
$memcachelife = 60; -
$memcache = new Memcache; -
$memcache->connect($memcachehost,$memcacheport) or die ("Could not connect"); -
$memcache->set('key','缓存的内容'); -
$get = $memcache->get($key); //获取信息 -
?>
7、apache缓存模块
apache安装完以后,是不允许被cache的。如果外接了cache或squid服务器要求进行web加速的话,就需要在htttpd.conf里进行设置,当然前提是在安装apache的时候要激活mod_cache的模块。
安装apache时:./configure –enable-cache –enable-disk-cache –enable-mem-cache
8、php APC缓存扩展
Php有一个APC缓存扩展,windows下面为php_apc.dll,需要先加载这个模块,然后是在php.ini里面进行配置:
[apc]
extension=php_apc.dll
apc.rfc1867 = on
upload_max_filesize = 100M
post_max_size = 100M
apc.max_file_size = 200M
upload_max_filesize = 1000M
post_max_size = 1000M
max_execution_time = 600 ; 每个PHP页面运行的最大时间值(秒),默认30秒
max_input_time = 600 ; 每个PHP页面接收数据所需的最大时间,默认60
memory_limit = 128M ; 每个PHP页面所吃掉的最大内存,默认8M 9、Opcode缓存
首先php代码被解析为Tokens,然后再编译为Opcode码,最后执行Opcode码,返回结果;所以,对于相同的php文件,第一次运行时可以缓存其Opcode码,下次再执行这个页面时,直接会去找到缓存下的opcode码,直接执行最后一步,而不再需要中间的步骤了。
比较知名的是XCache、Turck MM Cache、PHP Accelerator等。
45:返回由对象属性组成的关联数组:get_object_vars
class object1 {
private $a = NULL;
public $b = 123;
public $c = 'public';
private $d = 'private';
static $e = 'static';
public function test(){
echo "<pre>";
print_r(get_object_vars($this));
echo "<pre>";
}
}
$test = new object1();
//print_r(get_object_vars($test));
$test->test();
?>
输出:
Array (
[a] =>
[b] => 123
[c] => public
[d] => private
)
如果把//print_r(get_object_vars($test));的注释打开的话,则输出:
Array (
[b] => 123
[c] => public
)
也就是说在外面只会弹出public的非静态的属性;46.php函数:从数组中取出一段的函数是 array_slice();
dirname() 函数返回路径中的目录部分。
realpath()返回绝对路径名。
file_exists()检查文件或目录是否存在。
file_get_contents()将文件读入字符串。
flock()锁定或释放文件。
fopen()打开一个文件或 URL。
is_dir()判断指定的文件名是否是一个目录。
is_file()判断指定文件是否为常规的文件。
mkdir()创建目录。
pathinfo()返回关于文件路径的信息。
func_get_args() 返回包含所有参数的数组
变量的类型转换和判断类型方法。
3:php运算符优先级,一般是写出运算符的运算结果。
4:PHP中函数传参,闭包,判断输出的echo,print是不是函数等。
5:PHP数组,数组函数,数组遍历,预定义数组(面试必出)。
6:PHP面向对象,魔术方法,封装、继承、多态。设计模式,包括(单利、工厂、迭代器、装饰、命令、策略)。
7:正则表达式,每个标号含义,邮箱、网址、标签匹配,正则函数。
8:PHP异常处理(级别,错误日志,控制错误输出)。
9:PHP时间函数,日期计算函数。
10:文件系统,记录日志、目录、文件的遍历、上传、多方法得到文件扩展名、文件引用方式、引用函数区别。(面试必出)。
11:会话控制,主要说原理。session与cookie在分布式应用中出现问题的解决方案。
12:PHP模板引擎,常用模板引擎特点,MVC好与不好的地方。
13:PHP安全处理,过滤函数。
14:XML的使用。
15:PHP字符串的处理,包括转义(安全)、编码、截取、定位、与数组间的转换、处理函数等。(面试必出)。
16:Socket编程,各种协议,head头,curl参数含义。
17:网络状态码含义,常用(204,304, 404, 504,502)。
18:Apache配置文件,PHP配置文件,各个含义字段的含义。
=================================================PHP写函数===========================
1.请实现一个函数,输入1-1亿之间的任意整数,返回其中文。
<?php
function num2Chinese($num){
$char= array('零','一','二','三','四','五','六','七','八','九');
$unit = array('','十','百','千','','万','亿','兆');
$str = strrev($num);
for($i = 0,$c = strlen($str);$i < $c;$i++) {
$out[$i] = $char[$str[$i]];
$out[$i] .= $str[$i] != '0'? $unit[$i%4] : '';
if($i>1 and $str[$i]+$str[$i-1] == 0){
$out[$i] = '';
}
if($i%4 == 0){
$out[$i] .= $unit[4+floor($i/4)];
}
}
$retval = join('',array_reverse($out)) ;
return $retval;
}
echo num2Chinese(20160348);
?><?php
//3.写5个不同的自己的函数,来截取一个全路径的文件的扩展名,允许封装php库中已有的函数。
url dir/upload.image.jpg找出jpg或者.jpg
1.return strrchr($filename,"."));
strrchr() 函数查找字符串在另一个字符串中最后一次出现的位置,并返回从该位置到字符串结尾的所有字符。
2.return substr($filename,strrpos($filname,"."));
strrpos() 函数查找字符串在另一字符串中最后一次出现的位置。
substr(string,start,length) 函数返回字符串的一部分。
3.return array_pop(explode(".",$filename));
4.$p=pathinfo($filename); return $p['extension'];
5. return strrev(substr(strrev($filanme),o,strpos(strrev($filename),".")));
?>========================HTML============================
1.如下HTML:<img title=’aaaa’ sina_title=’bbbb’ id=’img1′>,
用js取得 document.getElementById(‘img1′); 方法取得该对象;
用 document.getElementById(‘img1′).getAttribute(‘title’); 属性取得属性title的属性值;
用 document.getElementById(‘img1′).getAttribute(‘sina_title’); 方法取得属性sina_title的属性值;
2.
===========================MySQL=============================
1:mysql has gone away的原因是什么?
一般情况下是由于max_allowed_packet设置的值过小导致的,max_allowed_packet用来控制缓冲区的包大小,有时在导入数据的时候,此值过小就容易造成缓冲区容量不够。将my.ini或my.cnf中的此值设置大一些即可解决。
还有一种可能是连接数据库时使用了单例模式,多次操作数据库但都使用的是同一个连接,由于mysql处理每个线程也是队列模式,当前一个操作还没执行完毕并且间隔小于wait_timeout所设置的值时就容易出现此问题,解决办法是将wait_timeout的值设置大一些。
2:mysql优化方式
MYSQL 优化常用方法:
1、选取最适用的字段属性。
MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。在可能的情况下,应该尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。对于某些文本字段,例如“省份”或者“性别”,我们可以将它们定义为ENUM类型。因为在MySQL中,ENUM类型被当作数值型数据来处理,而数值型数据被处理起来的速度要比文本类型快得多。
2、使用连接(JOIN)来代替子查询(Sub-Queries)。
MySQL从4.1开始支持SQL的子查询。子查询可以把一个结果作为过滤条件用在另一个查询中,如:DELETE FROM customerinfo WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo ) ,使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的SQL操作,同时也可以避免事务或者表锁死,并且写起来也很容易。但是,有些情况下,子查询可以被更有效率的连接(JOIN).. 替代,例如SELECT * FROM customerinfo WHERE CustomerID NOT in (SELECT CustomerID FROM salesinfo ) ,如果使用连接(JOIN)来完成这个查询工作,速度将会快很多。尤其是当salesinfo表中对CustomerID建有索引的话,性能将会更好,查询如下:SELECT * FROM customerinfo LEFT JOIN salesinfoON customerinfo.CustomerID=salesinfo. CustomerID WHERE salesinfo.CustomerID IS NULL。 连接(JOIN).. 之所以更有效率一些,是因为 MySQL不需要在内存中创建临时表来完成这个逻辑上的需要两个步骤的查询工作。
3、使用联合(UNION)来代替手动创建的临时表
MySQL从4.0的版本开始支持UNION查询,它可以把需要使用临时表的两条或更多的SELECT查询合并的一个查询中。在客户端的查询会话结束的时候,临时表会被自动删除,从而保证数据库整齐、高效。使用UNION来创建查询的时候,我们只需要用UNION作为关键字把多个SELECT语句连接起来就可以了,要注意的是所有SELECT语句中的字段数目要想同。示例:
SELECT Name, Phone FROM client UNION SELECT Name, BirthDate FROM author UNION SELECT Name, Supplier FROM product
4、事务
事务可以保持数据库中数据的一致性和完整性。事物以BEGIN关键字开始,COMMIT关键字结束。在这之间的一条SQL操作失败,那么,ROLLBACK命令就可以把数据库恢复到BEGIN开始之前的状态。 示例:
-
<span style="white-space:pre"> </span>BEGIN; -
INSERT INTO salesinfo SET CustomerID=14; -
UPDATE inventory SET Quantity=11 -
WHERE item='book'; -
COMMIT;
事务的另一个重要作用是当多个用户同时使用相同的数据源时,它可以利用锁定数据库的方法来为用户提供一种安全的访问方式,这样可以保证用户的操作不被其它的用户所干扰。
5、锁定表
尽管事务是维护数据库完整性的一个非常好的方法,但却因为它的独占性,有时会影响数据库的性能,尤其是在很大的应用系统中。由于在事务执行的过程中,数据库将会被锁定,因此其它的用户请求只能暂时等待直到该事务结束。其实,有些情况下我们可以通过锁定表的方法来获得更好的性能。示例:
-
<span style="white-space:pre"> </span>LOCK TABLE inventory WRITE -
SELECT Quantity FROM inventory -
WHEREItem='book'; -
... -
UPDATE inventory SET Quantity=11 -
WHEREItem='book'; -
UNLOCK TABLES
6、使用外键 (FOREIGN KEY)
锁定表的方法可以维护数据的完整性,但是它却不能保证数据的关联性。这个时候我们就可以使用外键。如果要在MySQL中使用外键,一定要记住在创建表的时候将表的类型定义为事务安全表 InnoDB类型。
7、使用索引
索引是提高数据库性能的常用方法,尤其是在查询语句当中包含有MAX()、MIN()和ORDERBY这些命令的时候,性能提高更为明显。一般说来,索引应建立在那些将用于JOIN、WHERE判断和ORDER BY排序的字段上。
8、优化的查询语句
首先,最好是在相同类型的字段间进行比较的操作。如不能将一个建有索引的INT字段和BIGINT字段进行比较;但是作为特殊的情况,在CHAR类型的字段和 VARCHAR类型字段的字段大小相同的时候,可以将它们进行比较。
其次,在建有索引的字段上尽量不要使用函数进行操作。 例如,在一个DATE类型的字段上使用YEAE()函数时,将会使索引不能发挥应有的作用。所以,下面的两个查询虽然返回的结果一样,但后者要比前者快得多。
-
<span style="white-space:pre"> </span>SELECT * FROM order WHERE YEAR(OrderDate)<2001; -
SELECT * FROM order WHERE OrderDate<"2001-01-01";
第三,在搜索字符型字段时,我们有时会使用 LIKE 关键字和通配符,这种做法虽然简单,但却也是以牺牲系统性能为代价的。例如:
SELECT * FROM books
WHERE name like "MySQL%"
但是如果换用下面的查询,返回的结果一样,但速度就要快上很多:
SELECT * FROM books
WHERE name>="MySQL"and name<"MySQM"
最后,应该注意避免在查询中让MySQL进行自动类型转换,因为转换过程也会使索引变得不起作用。
3:MYSQL数据表类型有哪些?
MyISAM、InnoDB、HEAP、BOB,ARCHIVE,CSV等
MyISAM:成熟、稳定、易于管理,快速读取。一些功能不支持(事务等),表级锁。
InnoDB:支持事务、外键等特性、数据行锁定。空间占用大,不支持全文索引等。
存储引擎MyISAM和InnoDB的区别:
一、InnoDB支持事务,MyISAM不支持,这一点是非常之重要。事务是一种高级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而MyISAM就不可以了。
二、MyISAM适合查询以及插入为主的应用,InnoDB适合频繁修改以及设计到安全性就高的应用
三、InnoDB支持外键,MyISAM不支持
四、MyISAM是默认引擎,InnoDB需要指定
五、InnoDB不支持FULLTEXT类型的索引
六、InnoDB中不保存表的行数,如select count(*) from table时,InnoDB需要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count(*)语句包含where条件时MyISAM也需要扫描整个表
七、对于自增长的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中可以和其他字段一起建立联合索引
八、清空整个表时,InnoDB是一行一行的删除,效率非常慢。MyISAM则会重建表
九、InnoDB支持行锁(某些情况下还是锁整表,如 update table set a=1 where user like '%lee%'
4:PHP中防sql注入方法
mysql_escape_string(strip_tags($arr["$val"]));
5:mysql数据库,一天五万条以上的增量,预计运维三年怎么优化
a. 设计良好的数据库结构,允许部分数据冗余,尽量避免join查询,提高效率。
b. 选择合适的表字段数据类型和存储引擎,适当的添加索引。
c. mysql库主从读写分离。
d. 找规律分表,减少单表中的数据量提高查询速度。
e。添加缓存机制,比如memcached,apc等。
f. 不经常改动的页面,生成静态页面。
g. 书写高效率的SQL。比如 SELECT * FROM TABEL 改为 SELECT field_1, field_2, field_3 FROM TABLE.
6:(mysql)请写出数据类型(int char varchar datetime text)的意思; 请问varchar和char有什么区别;
int : 数值类型
char : 固定长度字符串类型
varchar : 可变长度字符串类型
datetime : 时期时间类型
text : 文本类型
varchar和char有什么区别:
a. char 长度是固定的,不管你存储的数据是多少他都会都固定的长度。
而varchar则处可变长度但他要在总长度上加1字符,这个用来存储位置。
b. char 固定长度,所以在处理速度上要比varchar快速很多,但是浪费存储空间,
所以对存储不大,但在速度上有要求的可以使用char类型,反之可以用varchar类型来实例。
7:Mysql 的存储引擎,myisam和innodb的区别。
a. MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持.
b. MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快.
c. InnoDB不支持FULLTEXT类型的索引.
d. InnoDB 中不保存表的具体行数,也就是说,
执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行,
但是MyISAM只要简单的读出保存好的行数即可.
e. 对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。
f. DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
g. LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,
但是对于使用的额外的InnoDB特性(例如外键)的表不适用.
h. MyISAM支持表锁,InnoDB支持行锁。
8:
=============================LINUX======================
1:Linux服务器上有一个访问日志文件,格式如下:
172.17.0.31--[17/Mar/2016:15:59:40 +0800] "POST /User/get HTTP/1.1" 200 1209 "-" "order" "-" 17
其中,order字段记录了调用方的系统名称,最后的17为本次查询的响应时间,使用SHEEL或者PHP来统计调用方为order的所有接口的平均响应时间。
awk '$9 ~ /order/ {++S[$11]}END{for (a in S) print (sum+=S[a])/a}' file
============================HTTP======================
1:长连接和短连接的使用
长连接,指在一个TCP连接上可以连续发送多个数据包,在TCP连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接,一般需要自己做在线维持。
长连接通常就是:
连接→数据传输→保持连接(心跳)→数据传输→保持连接(心跳)→……→关闭连接;
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况,
例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
短连接是指通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接,
操作步骤是:
连接→数据传输→关闭连接;
例如:一般银行都使用短连接。 WEB网站的http服务一般都用短链接
2:LAMP与LNMP架构的区别及其具体的选择说明
LAMP和LNMP最主要的区别在于:
一个使用的是Apache,一个使用的是Nginx。
Apache是世界是用排名第一的Web服务器软件,其几乎可以在所有广泛使用的计算机平台上运营,由于其跨平台和安全性被广泛使用,是最流行的Web服务端软件之一。相比于nginx,apache有些臃肿,内存和CPU开销较大,性能上有损耗,nginx对于静态文件的响应能力远高apache。
Apache是负载PHP的最佳选择,如果流量很大的话,可以使用nginx来负载非PHP的Web请求。在整个IT界而言,70%的流量访问均来源于Apache。
Nginx是一款高性能额Http和反向代理服务器,也是一个AMAP/POP3/SMTP服务器,Nginx是由Igor Sysoev为俄罗斯访问量第二的Rambler.ru站点开发的。相比于Apache,nginx使用资源更少,支持更多并发连接,效率更高,作为负载均衡服务器。nginx即可对内进行支持,也可对外进行服务。其还是一款非常优秀的邮件代理服务器,安装简单,配置简介。
LNMP是Linux+Nginx+Mysql+PHP的组合方式,其特点是利用Nginx的快速与轻量级,替代以前的LAMP(Linux+Apache+Mysql+PHP)的方式。由于安装方便,并且安装脚本也随时更新。
LNMP方式的优点:占用VPS资源较少,Nginx配置起来也比较简单,利用fast-cgi的方式动态解析PHP脚本。
LNMP方式的缺点:php-fpm组件的负载能力有限,在访问量巨大的时候,php-fpm进程容易僵死,容易发生502 bad gateway错误
综上所述:
基于 LAMP 架构设计具有成本低廉、部署灵活、快速开发、安全稳定等特点,是 Web 网络应用和环境的优秀组合。若是服务器配置比较低的个人网站,当然首选 LNMP 架构。
当然,在大流量的时候。把Apache和Nginx结合起来使用,也不失为一个不错选择,如下:
LNAMP是Linux+Nginx+Apache+Mysql+PHP的组合方式,其特点是利用Nginx来作为静态脚本的解析,而利用 Nginx的转发特性,将动态脚本的解析转交给Apache来处理,这样,能充分利用两种Web服务器的特点,对于访问量需求较大的站点来说,是一个很不错的选择。
LNAMP方式的优点:由于Apache本身处理PHP的能力比起php-fpm要强,所以不容易出现类似502 bad gateway的错误。适合访问量较大的站点使用。
LNAMP方式的缺点:相比LNMP方式会多占用一些资源,另外,配置虚拟主机需要同时修改Nginx和Apache的配置文件,要稍微麻烦一些。
3:memcached、redis、mongodb的区别联系
3个场景完全不同的东西。
1.memcached:单一键值对内存缓存的,做对象缓存无可替代的分布式缓存;
2.redis:是算法和数据结构的集合,快速的数据结构操作是他最大的特点,支持数据持久化;
3.mongodb是bson结构、介于rdb和nosql之间的,更松散更灵活的,但是不支持事务,只用作非重要数据存储。
Redis和Memcached的区别
1.数据支持类型不同:
Memcached仅支持简单的key-value结构的数据,Redis常用的数据类型有5种:String、Hash、List、Set和Sorted Set.Resdis内部使用一个redisObject对象来表示所有的key和value.
redis核心对象(redisObject)
|数据类型(type)-------------------->string/hash/list/set/sorted set
raw/int/ht/zipmap/
linkedlist/ziplist --> |编码方式(encoding)
/intset
|数据指针(ptr)
|虚拟内存(vm)
|其他信息……
说明:type代表一个value对象具体是什么数据类型,encoding是不同数据类型在redis内部的存储方式。比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者int,如果是int则代码实际redis内部是按数值型类型存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示比如“124”,“456”这样的字符串。只有打开了Redis的虚拟内存功能,vm字段才会真正的分配内存,该功能默认关闭。
1)String:
常用命令:set/get/decr/incr/mget等。
应用场景:String是最常用普通的key/value都可以用
实现方式:String在Redis内部存储默认就是一个字符串。当遇到incr、decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
2)Hash
常用命令:hset/hget/hgetall等
应用场景:我们要存储一个用户信息对象数据,其中包括用户ID、用户姓名、年龄和生日,通过用户ID我们希望获取该用户的姓名或者年龄或者生日;
实现方式:Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口。如图所示,Key是用户ID, value是一个Map。这个Map的key是成员的属性名,value是属性值。这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据。当前HashMap的实现有两种方式:当HashMap的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,这时对应的value的redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
3)List
常用命令:lpusht/rpush/lpop/rpop/lrange等
应用场景:比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现;
实现方式:Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构
4)Set
常用命令:sadd/spop/smembers/sunion等;
应用场景:Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的;
实现方式:set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
5)Sorted Set
常用命令:zadd/zrange/zrem/zcard等;
应用场景:Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
实现方式:Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
2.内存管理机制不同
在Redis中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别。
4:HTTP协议中几个状态码的含义:503 500 401 403 404 200 301 302。。。
2XX 成功
200 : 请求成功,请求的数据随之返回。
3XX 重定向
301 : 永久性重定向。
302 : 暂时行重定向。
304 :未修改
305 :使用代理
307 :临时重定向
4XX 请求错误
401 : (未授权)当前请求需要用户验证。
403 : (禁止) 服务器拒绝请求。
404 : (未找到)请求失败,请求的数据在服务器上未发现。
405 :(方法禁用) 禁用请求中指定的方法。
407 :(需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。
5xx 服务器错误
500 : 服务器错误。一般服务器端程序执行错误。
501 :(尚未实施) 服务器不具备完成请求的功能
502 :(错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 : (服务不可用)服务器临时维护或过载。这个状态时临时性的。
504 :(网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 :(HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
5:对于大流量的网站,您采用什么样的方法来解决各页面访问量统计问题
a. 确认服务器是否能支撑当前访问量。
b. 优化数据库访问。参考2.3
c. 禁止外部访问链接(盗链), 比如图片盗链。
d. 控制文件下载。
e. 使用不同主机分流。
f. 使用浏览统计软件,了解访问量,有针对性的进行优化。
6:使用mod_rewrite,在服务器上没有/archivers/567.html这个物理文件时,重定向到index.php?id=567,请先打开mod_rewrite.
首先,打开mod_rewrite模块。
其次,http.conf找到以下代码段:
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
将其中的:AllowOverride None 改为 AllowOverride All ,重启httpd服务即可。
然后,在项目根目录下建立 .htaccess 文件,填写规则。
7:测试php性能和mysql数据库性能的工具,和找出瓶颈的方法
XHProf是一个分析php性能的工具,他报告函数基本的请求次数和各种指标,包括阻塞时间、cpu时间和内存使用情况,有一个简单的HTML用户界面,给予浏览器的性能分析用户界面,也能绘制调用关系
转载自:https://blog.csdn.net/han0207xiao/article/details/52239518
以下为自己补充:
1.多对多的情况下,数据表应该如何设计,如学生选课,一个学生可以选择多门课程,一门课程也可以被多个学生选择,并且一门课程对应一名教师,一个教师却可以教授多门课程,问此时数据表该如何设计
通过学生选课了解多对多问题的处理:

在多对多中在一个表中添加一个字段就行不通了,所以处理多对多表问题时,就要考虑建立关系表了
例:
学生表: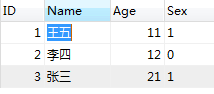

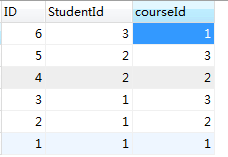
以上三个表只是解决了学生和课程之间的对应关系,并没有解决课程和老师之间的对应关系,可以知道老师与课程是一对多的关系,故而可以设计一个表teacher,字段为主键ID,teacherName,courseId,用来对应老师与课程之间的关系
注:所以对于多对多表,通过关系表就建立起了两张表的联系!多对多表时建立主外键后,要先删除约束表内容再删除主表内容
外键的基本概念
一、基本概念
1、MySQL中“键”和“索引”的定义相同,所以外键和主键一样也是索引的一种。不同的是MySQL会自动为所有表的主键进行索引,但是外键字段必须由用户进行明确的索引。用于外键关系的字段必须在所有的参照表中进行明确地索引,InnoDB不能自动地创建索引。
2、外键可以是一对一的,一个表的记录只能与另一个表的一条记录连接,或者是一对多的,一个表的记录与另一个表的多条记录连接。
3、如果需要更好的性能,并且不需要完整性检查,可以选择使用MyISAM表类型,如果想要在MySQL中根据参照完整性来建立表并且希望在此基础上保持良好的性能,最好选择表结构为innoDB类型。
4、外键的使用条件
① 两个表必须是InnoDB表,MyISAM表暂时不支持外键
② 外键列必须建立了索引,MySQL 4.1.2以后的版本在建立外键时会自动创建索引,但如果在较早的版本则需要显式建立;
③ 外键关系的两个表的列必须是数据类型相似,也就是可以相互转换类型的列,比如int和tinyint可以,而int和char则不可以;
5、外键的好处:可以使得两张表关联,保证数据的一致性和实现一些级联操作。保持数据一致性,完整性,主要目的是控制存储在外键表中的数据。 使两张表形成关联,外键只能引用外表中的列的值!可以使得两张表关联,保证数据的一致性和实现一些级联操作;
2.数据库ER图
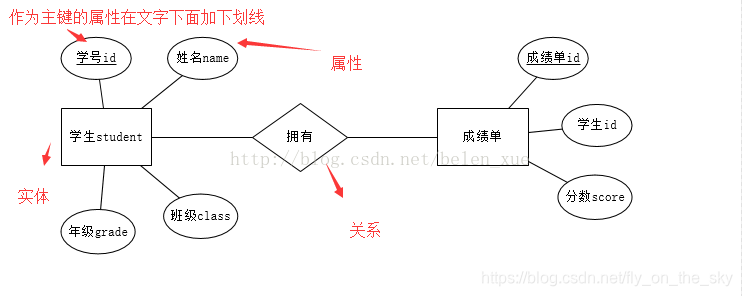
简单画一画,暂时不做过多探讨
3.常用的Linux命令,如运行文件,查看某个文件是否正在运行
https://www.cnblogs.com/gaojun/p/3359355.html
参考链接
4.当服务器访问量特别大时,比如说千万级别,引入redis进行优化,redis存储量为10000
5.服务器502错误
6.PHP的多种设计模式
7.Git和SVN的区别
8.TP和CI的区别和优缺点
9.递归方法
10.从输入百度到出检索结果中间的整个响应流程
11.TP5的新特性
12.小米抢手机,同时有十万的并发量,怎么设计程序(微信抢红包)
13.TP框架的路由原理
14.PHP的自动加载原理
15.PHP的整形和字符型的各种转换($a =1,$b="30$a",那么$b='301'?)
16.一组数据,如1,1,2,3,5,8,13.....这种格式,已有解决办法
function aaa($a) {
if ($a==1 || $a==2) {
return 1;
}
return aaa($a-2)+aaa($a-1);
}
问当$a=100时可能会有性能问题,是什么性能问题,并且写出优化的写法
答:http://www.nowamagic.net/librarys/veda/detail/2321
17.echo,print,print_r,var_dump,printf,s_printf的区别和共同点
18.写一个方法实现var_dump()的功能
19.二维数组排序