最近一个项目中,需要在spark中解析protobuf编码过的数据。
针对这个问题,我首先试了一下在scala中解析protobuf编码后数据的功能,下面记录了详细过程
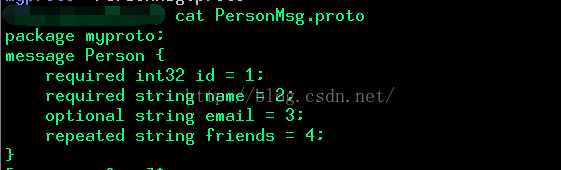
1.书写proto文件
2.编译proto文件,获取java类文件
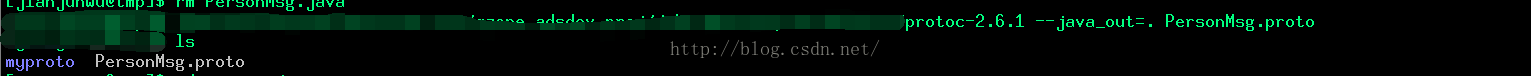
3.把刚刚得到java类文件拷贝maven工程目录下,注意目录结果和package一致
4.修改maven配置文件,加入对protobuf的依赖

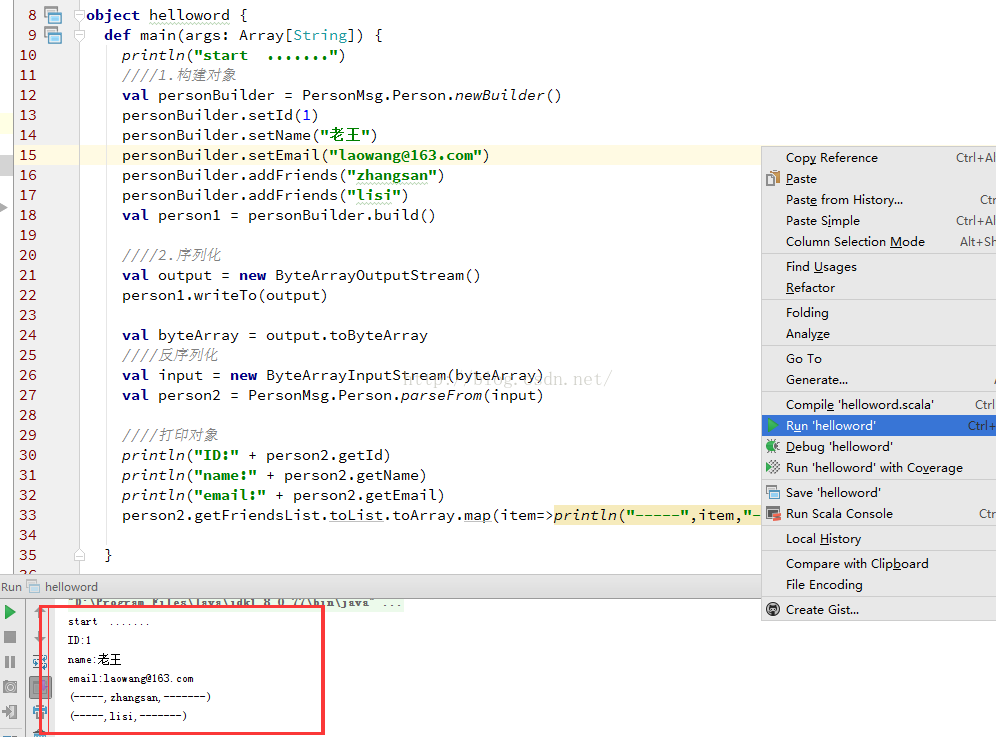
5.编写读写protobuf的scala代码
package hello
import scala.collection.JavaConversions._
import java.io.ByteArrayInputStream
import java.io.ByteArrayOutputStream
import myproto._
object helloword {
def main(args: Array[String]) {
println("start .......")
////1.构建对象
val personBuilder = PersonMsg.Person.newBuilder()
personBuilder.setId(1)
personBuilder.setName("老王")
personBuilder.setEmail("[email protected]")
personBuilder.addFriends("zhangsan")
personBuilder.addFriends("lisi")
val person1 = personBuilder.build()
////2.序列化
val output = new ByteArrayOutputStream()
person1.writeTo(output)
val byteArray = output.toByteArray
////反序列化
val input = new ByteArrayInputStream(byteArray)
val person2 = PersonMsg.Person.parseFrom(input)
////打印对象
println("ID:" + person2.getId)
println("name:" + person2.getName)
println("email:" + person2.getEmail)
person2.getFriendsList.toList.toArray.map(item=>println("-----",item,"-------"))
}
}