Python简介
Python是由Guido van Rossum在1989编写一种解释性语言,名字取自作者最喜爱的马戏团Monty Python’s Flying Circus(蒙提.派森干的飞行马戏团)。
特点
- 易读、易学、易维护
- 开源、免费,Python是FLOSS(Free/Libre and Open Source Software:自由/开源软件)之一,可以自由的阅读、拷贝,甚至修改源码。
- 可移植性,Python是解释性语言,由Python虚拟机解释执行字节码,这就意味着只要机器上安装虚拟机,Python应用程序就可以在未做任何修改的情况下,在不同操作系统间移植,类似于Java。
- 可扩展性,考虑到性能或者机密等原因,可以使用C/C++扩展实现部分功能。
- 既支持面向过程编程,又支持面向对象编程。
- 严格缩进,不同于大部分编程语言,Python不使用分号区分语句,而是使用缩进,这也使得Python程序写起来需要更加严谨,看起来更加整齐和优雅。
附上Tim Peters总结的"Python之禅",让我们更好的理解Python:
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren’t special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you’re Dutch.
Now is better than never.
Although never is often better than right now.
If the implementation is hard to explain, it’s a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea – let’s do more of those"
下载
可以到Python 官网去下载并安装符合自身操作系统的Python版本。建议下载Python 3.x,相对于2.x由许多新特性和改进,而且终究会取代2.x。
还可以选择组合包下载Anaconda,它不只包含Python,还包含许多优秀的工具和三方库,对于大型项目开发而言是十分方便的。
开发工具选择
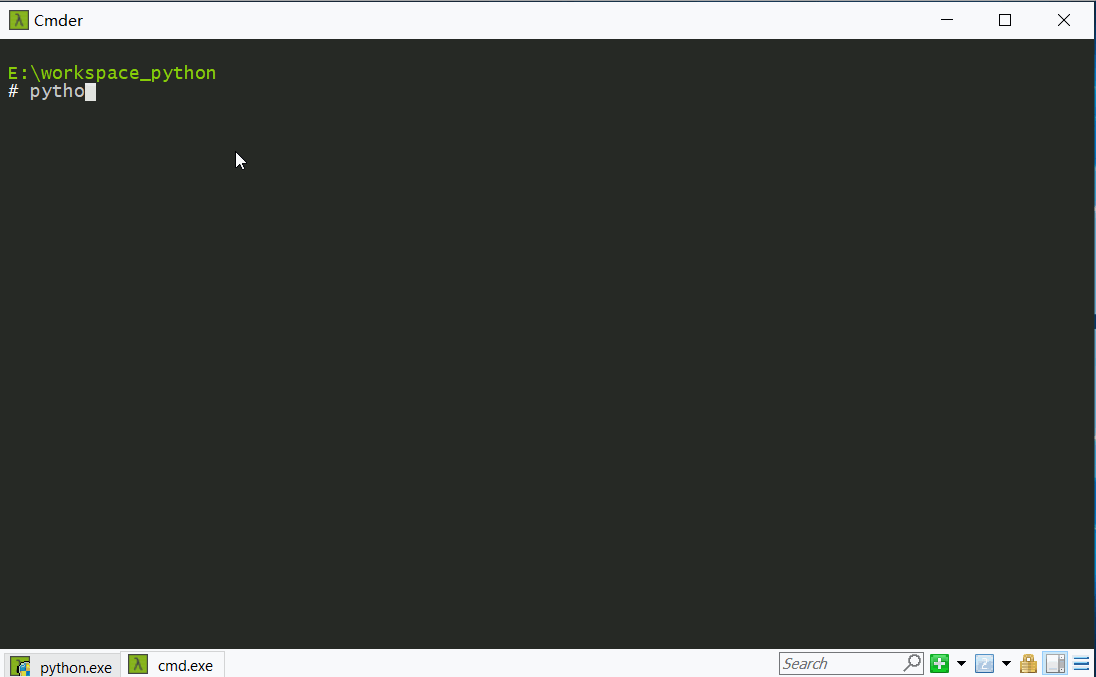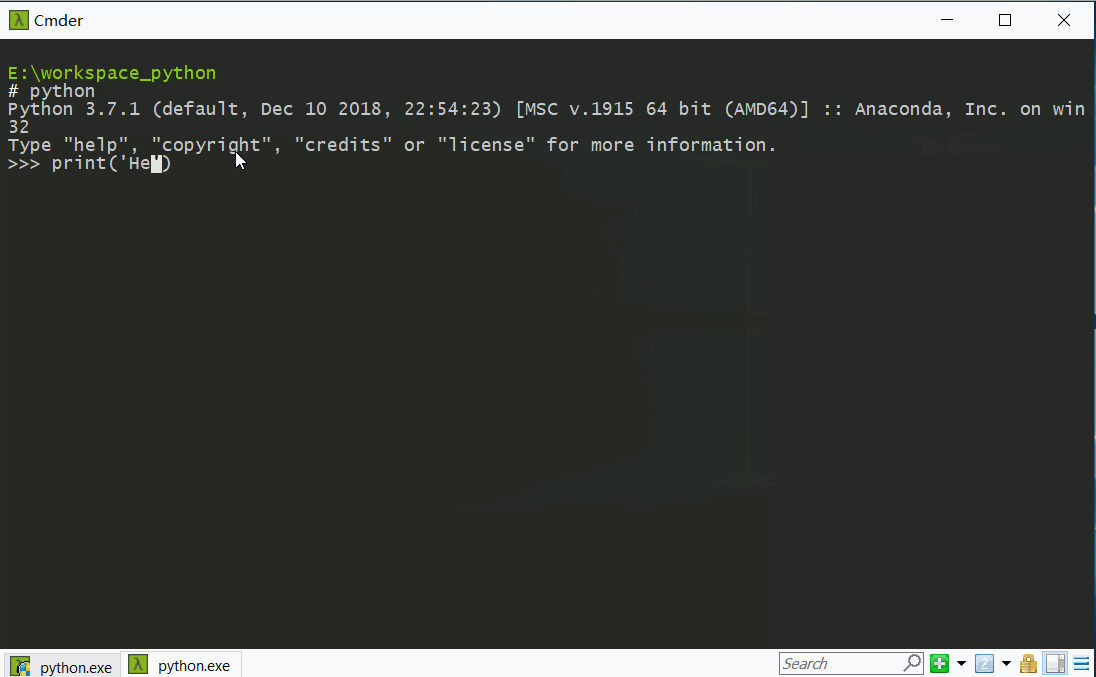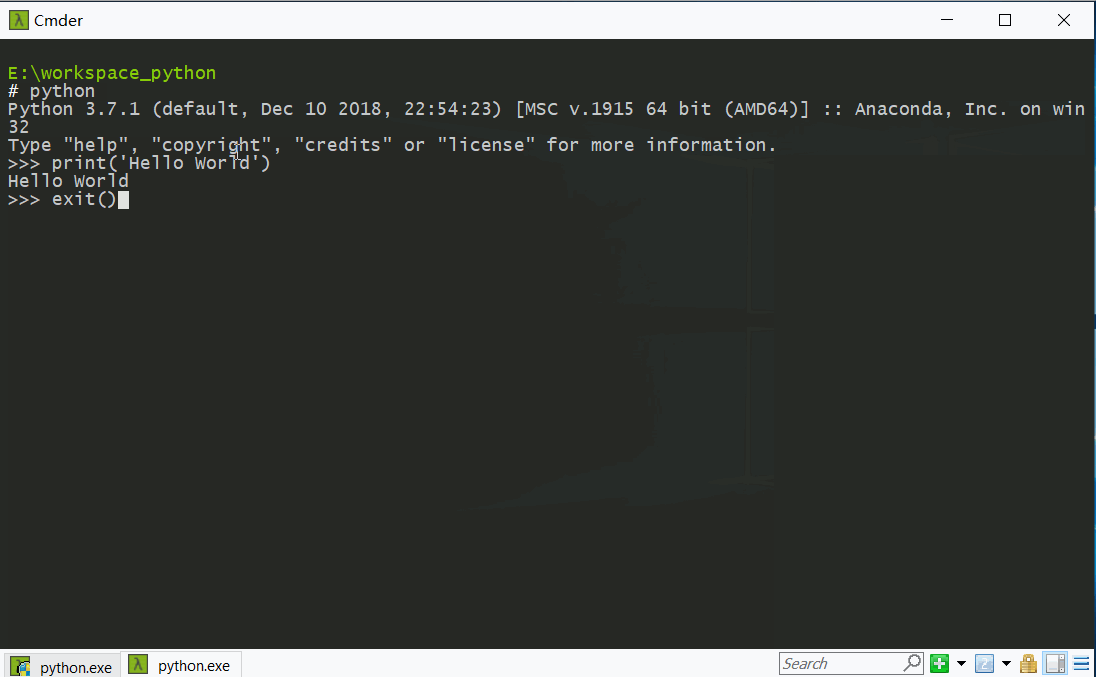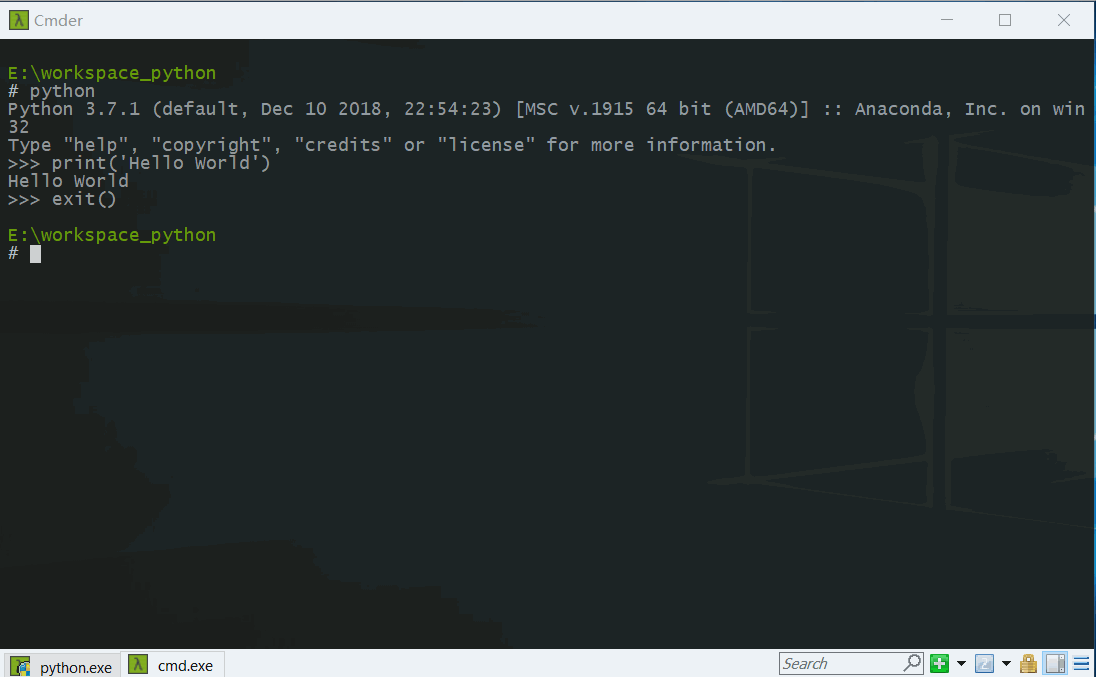
- 可以直接在cmd中输入
python(这里是在cmder中演示的),进入python交互式命令行界面(注意有三个向右的箭头),然后进行简单的编程验证工作。执行exit()退出。
- PyCharm,专业且优秀的Python IDE。
- Jupyter Notebook,是一款基于浏览器的交互式笔记本工具(本质上是一款Web应用),支持Python。轻量,界面简洁美观,非常适合示例测试。Anaconda自带了jupyter-notebook。
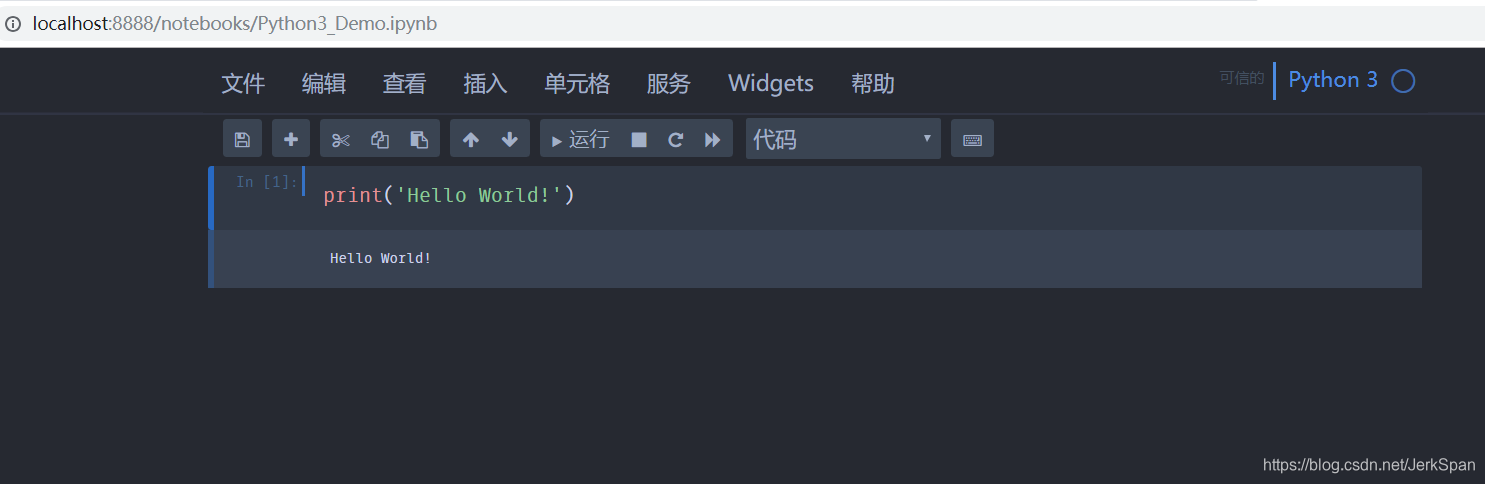
- 更多工具请参考,在实践中根据个人喜好选择工具。本文的例子一部分是在交互式命令行下测试完成的,代码较多的话使用Visual Studio Code完成。
Python 基础知识
模块和包
一个模块就是一个.py文件,文件中可以定义变量、函数、类等。
可以使用import 模块名将其它模块引入到当前模块中,或者使用from 模块名 import 函数等 导入其它模块中的函数、类等。
一个包就是一个文件夹,与普通文件夹的区别是:包中必须包含一个__init__.py文件(可以是空文件)。
包中还可以有子包和模块,如果想引入包中的模块,同样可以使用import。比如import a.b,引入a 包下的b模块。如果还有子包,同样用点号连接。
标识符和关键字
标识符指变量名称、函数名称等。只能使用字符、数字和下划线定义,且首字母不能是数字。
关键字指系统保留字,顾名思义指系统已经为其指定了特殊含义的"单词",开发者只能使用,而不能改变其原本含义,即不能再被用作自定义的标识符。
查看当前python版本的关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
注释
单行注释使用#
多行注释使用'''或者"""
基本数据类型
Python中变量定义时无需声明类型,类型由值推导,即动态类型。Python3有七种基本数据类型:
- 数值: int、float和complex
- 字符串: str,使用
'或"括起来 - 布尔: bool,值只使用
True或者False表示 - 列表: list,使用
[]表示 - 元组: tuple,使用
()表示 - 字典: dict,使用
{key:value,...}表示 - 集合: set,使用
{value,...}表示,注意和字典区分
注:bool是int的子类型,所以在很多文档中都把bool当做数值类的一员,没有单独列出,如Python的官网文档Objects, values and types中的说明:
Booleans (bool)
These represent the truth values False and True. The two objects representing the values False and True are the only Boolean objects. The Boolean type is a subtype of the integer type, and Boolean values behave like the values 0 and 1, respectively, in almost all contexts, the exception being that when converted to a string, the strings “False” or “True” are returned, respectively.
Python也确实可以使用数字来表示"真"和"假", 但是Python3 定义了True和False,专门用于表示布尔值,所以这里把bool单独列出,方便与其他数值类型区分。但是当True和False与数字一起参与算术运算时,其值分别代表1和0.
bool与int对比:
# 打印数字1的数据类型
print(type(1))
# 打印False的数据类型
print(type(False))
# 使用数字作为bool值,以及True和False与数字的运算
if (1):
print('数字可以表示bool')
print(True + 0)
print(False + 0)
输出:
<class 'int'>
<class 'bool'>
数字可以表示bool
1
0
基本数据类型间的相互转换:
每一种数据类型都有一个对应的方法,比如int()、bool()、str()、list()、tuple()、dict()、set(),那么给这些方法传其它类型的参数,可以将其它类型转换为该类型。如将字符串转成列表:
>>> str_to_list = list('Blues')
>>> print(str_to_list)
['B', 'l', 'u', 'e', 's']
运算符
- 算术运算符:
+、-、*、/、%(取模,返回除法的余数)、//(整除,返回除法后的整数部分)、**(幂运算) - 关系运算符:
==、!=、<、>、<=、>= - 赋值运算符:
=、+=、-=、*=、/=、//=、%=、**=。先执行运算符表示的运算后,将结果赋值给左边的变量。
举个例子:a %= 3等价于a = a % 3
>>> a = 5
>>> a %= 3
>>> print(a)
2
- 位运算符:将数字看做二进制位,进行二进制运算。
&:按位与,|:按位或,^:按位异或,~:取反,<<:左移,>>:右移。 - 逻辑运算符:与(
and)、或(or)、非(not) - 成员运算符:检查值是否在某个序列中。
in、not in is和is not,判断两个标识符是否指向同一个对象,即内存地址是否相同(可以使用id(obj)查看obj的内存地址)。与==的区别是:==判断值是否相等。举个例子:
>>> a = [1, 2]
>>> b = [1, 2]
>>> print(a == b)
True
>>> print(a is b)
False
数值
数值运算的常用方法大部分在math和random模块下:
| 函数 | 描述 |
|---|---|
| abs(x) | 返回绝对值 |
| math.ceil(x) | 返回大于等于x的最小整数 |
| math.floor(x) | 返回小于等于x的最大整数 |
| max(x1, x2) | 返回最大值 |
| min(x1, x2) | 返回最小值 |
| round(x) | 四舍五入 |
| random.random() | 返回[0.0, 1.0)之间的一个实数 |
| random.randint(a, b) | 返回[a, b]间的一个整数 |
| random.choice(seq) | 返回序列中一个元素 |
字符串
可以使用'或者"定义字符串,Pyhon中的字符串都是不可变的,但是可以通过拼接、切片、join()等操作生成新的字符串。字符串长度可以使用内建函数len(string)获取。
字符串常用操作
| 操作符 | 描述 | 举例 |
|---|---|---|
| + | 字符串拼接 | >>> a = ‘Hello’ >>> b = ‘World’ >>> a + b ’HelloWorld’ |
| * | 字符串复制 | >>> h = ‘Hello’ >>> print(h * 2) HelloHello |
| [index] | 获取字符串中index处的字符 | |
| [start:stop] | 截取start-stop间的子字符串,不包含stop处字符 | |
| in / not in | 判断是否是子串 | >>> h = ‘Hello’ >>> print(‘H’ in h) True |
| r/R | 输出原始字符串,即不会解析字符串中的转义字符等 | |
| % | 格式化字符串,%后可以跟d、s、x等不同字符,表示不同的格式化规则。不过这是旧式的格式化方法,建议使用str.format()方法进行格式化 |
字符串方法
| 序号 | 方法 | 描述 | 举例 |
|---|---|---|---|
| 1 | capitalize() | 将字符串首字母大写,其他字母小写 | >>> h = ‘heLLo’ >>> h.capitalize() ‘Hello’ |
| 2 | center(width[, fillchar]) | 如果width小于原字符串长度,直接返回原字符串;否则,返回长度为with,两边使用fillchar填充,原字符串居中的新字符串;类似的还有ljust和rjust | |
| 3 | count(sub[, start][, stop]) | 返回字符串sub在原字符串[start, stop]区间内出现的次数 | |
| 4 | endswith(sub[, start][, end]) | 是否以sub结尾 | |
| 5 | find(sub[, start][, end]) | 检查sub是否包含在原字符串中,返回开始索引;若不包含返回-1 | >>> sub = ‘llo’ >>>‘HelloWorld’.find(sub) 2 |
| 6 | isalnum() | 字符串中所有字符都是字母或者数字,返回True;否则,返回False。字母不单单指英文字母,汉字等也都是 | >>> ‘a2啊’.isalnum() True |
| 7 | isalpha() | 所有字符都是字母,返回True | |
| 8 | isdigit() / isnumeric() | 判断是否只包含数字字符。区别是isnumeric遇到汉字数字时也返回True。 | >>> ‘四十五’.isdigit() False >>> ‘四十五’.isnumeric() True |
| 9 | islower()/isupper()/lower()/upper() | 字符大小写判断、转换 | |
| 10 | isspace() | 只包含空白符,返回True | |
| 11 | join(iterable) | 原字符串作为分隔符,将iterable中的元素(元素必须是字符串)拼接成字符串 | >>> ‘seperator’.join(‘ABC’) ‘AseperatorBseperatorC’ |
| 12 | replace(old, new [, count]) | 使用new替换原字符串中的old,如果count指定,最多替换count次,返回替换后的字符串 | |
| 13 | split(sep, maxsplit) | 以seq作为分隔符切割原字符串,如果maxsplit指定,最多分割maxsplit次,返回切割的元素组成的列表 | |
| 14 | strip([chars]) | 删除原字符串左右两边的特定字符,如果chars未指定,则删除空白符,否则就是删除chars中的字符;与其类似的还有lstrip()和rstrip() | |
| 15 | swapcase() | 大小写互转 |
列表
使用[]或者list(iterable)初始化一个列表。
列表元素可以是任意类型:
>>> list1 = ['1', 'a', 4, ['sub',5], None]
>>> list1
['1', 'a', 4, ['sub', 5], None]
还可以使用列表推导式来生成列表,列表推导式的格式为:[ x+1 for x in seq ],它的逻辑是:遍历seq,在一次循环中,取出seq中的一个元素赋值给x,然后对x进行期望的操作(这里是x+1),生成的值作为列表的一个元素。所以每次遍历都会生成一个新的列表元素,直至seq遍历完。
如下使用列表推导式由字符串生成列表:
>>> str1 = 'str to list'
>>> list1 = [c + '@' for c in str1]
>>> list1
['s@', 't@', 'r@', ' @', 't@', 'o@', ' @', 'l@', 'i@', 's@', 't@']
除此之外,还可以使用if子句来进一步过滤需要的元素。如下:
>>> tuple1 = (1, 2, 3, 4, 5, 6)
>>> list1 = [x for x in tuple1 if x >= 3]
>>> list1
[3, 4, 5, 6]
访问元素
使用索引list[index]访问指定位置的元素,索引从0开始:
>>> list1[0]
'1'
但是索引一定不能越界,否则就会报错IndexError: list index out of range。
修改元素
同理,也可以直接修改元素值,如下将’a’改成’b’:
>>> list1 = ['1', 'a', 'blues']
>>> list1[1] = 'b'
>>> list1
['1', 'b', 'blues']
删除元素
使用del删除指定位置的元素,
>>> del list1[1]
>>> list1
['1', 'blues']
如果del后跟的是列表名称,则表示删除列表对象本身,而不只是元素,如下,当列表被删除后,如果再想访问就会报错:
>>> del list1
>>> list1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'list1' is not defined
del是根据索引删除元素,除此之外,list.remove(obj)可以根据名称删除元素,但只会删除第一个匹配的元素。
列表其它常见操作
- 使用
+可以拼接多个列表 - 使用
*重复列表元素 - 使用
in判断元素是否在列表中(用在条件语句时)或者从列表中取元素(用在循环语句时)。 - 使用[start:end]:对列表进行切片,,即截取原列表中start(包含start)到end(不包含end)的元素,生成一个新列表,原列表不变,start和end都可以省略,但是冒号不能省。
如果省略start或者start小于0,则从0开始截取;
如果省略end或者end大于列表长度,则截取到列表末尾;
如果都省略,则返回全部列表元素。
如:
>>> list1=[1,2,3,4]
>>> list1[:]
[1, 2, 3, 4]
>>> list1[1:41]
[2, 3, 4]
>>> list1[-11:41]
[1, 2, 3, 4]
>>> list1[1:2]
[2]
列表方法
| 序号 | 方法 | 描述 | 举例 |
|---|---|---|---|
| 1 | append(obj) | 在末尾添加新元素 | |
| 2 | count(obj) | 统计某个元素在列表中出现的次数 | |
| 3 | extend(iterable) | 使用iterable扩展原列表中的元素 | |
| 4 | index(obj) | 返回obj的索引 | |
| 5 | insert(index, obj) | 在index处插入obj | |
| 6 | pop([index]) | 移除index处的元素并返回,如果index未指定,则移除最后一个元素。 | |
| 7 | remove(obj) | 移除列表中第一个obj元素 | |
| 8 | reverse() | 列表元素反转 | >>> list=[1,2,3] >>> list.reverse() >>> list [3, 2, 1] |
| 9 | sort(key=None,reverse=False) | 对列表元素重新排序(),key和reverse都是可选。key值必须是一个单参函数,它依次接收列表中的元素作为入参,返回值决定了该元素的排序位置;如果reverse是False,则返回值越小,该参数排序越靠前; | |
| 10 | clear() | 清空列表 | |
| 11 | copy() | 复制列表 |
sort(key)举例:
def keyFunc(element):
return 1 / element
list1 = [3, 2, 1, 5, 4]
list1.sort(key=keyFunc)
print(list1)
输出:
[5, 4, 3, 2, 1]
element就是列表元素,element越大,则返回值1/element就越小,那么该元素在排序时就会越靠前,所以最大值5排在了第一位。这和sort(reverse=True)是同样的效果。
列表方法在调用时都要使用.操作符连接对象和方法。除此之外,Python还内置有多个与列表相关的函数,可以直接调用,不需要.操作符,比如:
len(list):返回list的长度,即list中的元素个数max(list)和min(list):返回列表中最大值和最小值list(iterable):从可迭代对象iterable中取元素,生成一个列表
元组
元组与列表十分相似,可以简单认为是元素不可变的列表,所以列表的一些修改和删除元素的操作在元组中是没有的,除此之外,像索引、拼接、切片等操作,元组和列表并无差异。
可以使用()或者tuple(iterable)生成新的数组。
字典
可以使用{}生成一个字典对象,字典中的元素都是key:value形式的键值对。key必须是不可变类型,如字符串、数字、元组等,但不能是列表,否则会报TypeError,如下:
>>> list1 = ['a']
>>> dict1 = {list1:'value1'}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
但是如果是元组作为key,则没有问题:
>>> t1 = ('a')
>>> dict1 = {t1:'value1'}
>>> dict1
{'a': 'value1'}
而且key不能重复,否则最后一个key对应的value值生效。
访问和修改元素值
使用dict[key]获取键为key的元素值,同样也可以直接赋值修改:
>>> dict1 = {'a':1, 'b':2, 3:4}
>>> dict1['a']
1
>>> dict1[3]
4
>>> dict1['b'] = 22
>>> dict1
{'a': 1, 'b': 22, 3: 4}
删除字典元素
可以使用del dict[key]可以删除键为key的元素,也可以使用字典方法pop等删除。
字典方法
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | clear() | 清空字典 |
| 2 | copy() | 拷贝字典元素,浅拷贝,这意味着如果value是类对象,则只会拷贝引用,不会拷贝对象,则当原始对象改变后,copy()生成的字典同样会变。 |
| 3 | dict.fromkeys(iterable[, value]) | 从iterable获取键,从value获取值,生成新的字典,value可选,如果未指定,则值默认为None。这里最好就用类dict调用fromkeys,不要用对象调用,突出这是一个类方法,当然用对象调用也完全没有问题,但是生成的新字典和原字典对象没有任何关系。 |
| 4 | get(key[, default]) | 获取指定key的值,如果default指定,则在key不存在时,返回default。 |
| 5 | items() | 返回一个形似列表的dict_items对象,该对象的元素是由原字典中(key,value)组成的元组。 |
| 6 | keys() | 返回一个dict_keys对象,对象中的元素由字典的key组成。 |
| 7 | setdefault(key[, default]) | 类似于get,虽然名字中带有set,但它会返回一个值,规则是: 如果key值存在,则返回key对应的value,无论default有无值; 如果key不存在,则新增key;如果同时指定了了default,则值为default,并返回,否则值为None; |
| 8 | dict1.update(dict2) | 将dict2中的键/值对更新到dict1中,如果dict2中的key在dicy1中不存在,则新增,否则直接修改值。 |
| 9 | values() | 与keys()类似,返回dict_values对象,元素由字典中的元素的值组成。 |
| 10 | pop(key[, default]) | 删除指定key的值,并返回;如果key不存在但是指定了default,则返回default;如果key不存在也未指定default,则报KeyError错误。 |
dict.fromkeys()举例:
>>> list1 = [1.1, 2.2, 3.3]
>>> dict1 = {'a': 1, 'b': 2, 3: 4}
>>> dict2 = dict.fromkeys(list1)
>>> dict2
{1.1: None, 2.2: None, 3.3: None}
如果这里使用dict1.fromkeys,结果仍然是一模一样的,说明和dict1是没有任何关系的,所以最好不要使用dict1调用,以免发生误解。
>>> dict1.fromkeys(list1)
{1.1: None, 2.2: None, 3.3: None}
items()举例:
>>> dict1 = {'a':1, 'b':2, 3:4}
>>> items = dict1.items()
>>> items
dict_items([('a', 1), ('b', 2), (3, 4)])
生成的是dict_items对象,看起来像列表,但不是列表,可以使用isinstance(items, list)来确认,如下:
>>> isinstance(items, list)
False
update(dict)举例:
>>> dict1 = {'a':'A', 'b':'B'}
>>> dict2 = {1:'I', '2':'II','b':'C'}
>>> dict1.update(dict2)
>>> dict1
{'a': 'A', 'b': 'C', 1: 'I', '2': 'II'}
集合
集合(set)是一个无序且元素不重复的序列。
可以使用{}或set(iterable)生成一个新的集合。注意当使用{}创建集合时与字典的区别:字典中的元素必须是key:value形式。如果想创建空集合,只能使用set(),空的{}表示创建空字典。
可以使用type(obj)来查看对象的类型:
>>> set1 = {'a', 1, True}
>>> type(set1)
<class 'set'>
>>> empty_dict = {}
>>> type(empty_dict)
<class 'dict'>
集合方法
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | add(element) | 添加新元素,如果元素已存在,不作任何操作 |
| 2 | clear() | 清空集合元素 |
| 3 | copy() | 拷贝集合 |
| 4 | set1.difference(other1, other2, …) | 返回set1和other1, other2等的差集(集合),其中差集元素包含在set1中,而不在other中; 包含在other中但不在set1中的元素不会返回。other1必须,other2等可选。 |
| 5 | discard(value) | 删除指定元素,若元素不存在,则不做任何操作 |
| 6 | set1.intersection(other1, other2, …) | 与difference类似,只不过返回的是set1与other的交集,与之功能类似的还有intersection_update()。 |
| 7 | set1.isdisjoint(set2) | 判断两个集合是否包含相同的元素,如果有相同元素,返回False;否则返回True |
| 8 | set1.issubset(set2) | 判断set1是否是set2的子集 |
| 9 | set1.isuperset(set2) | 判断set1是否是set2的超集 |
| 10 | pop() | 随机移除元素 |
| 11 | remove(obj) | 移除集合中指定元素,与discard()类似,区别是:当移除的元素不存在时,remove会报KeyError错误,discard不会。 |
| 12 | set1.union(other1, other2, …) | 返回多个集合的并集,other1必须指定,other2等可选。 |
| 13 | set1.update(other1, other2,…) | 使用other来更新set1,和union类似,都是取并集,唯一的区别是:union生成新的集合,而update只是将新元素更新到set1中。 |
difference(other)举例:
>>> set1 = {1, 2, 3}
>>> set2 = {2, 4}
>>> set1.difference(set2)
{1, 3}
other除了可以是集合之外,还可以是列表、元组和字典等,但是字符串无效。当other是字典时,比较的是字典的key:
>>> set1 = {1, 2, 3}
>>> dict1 = {2:'a', 4:'b'}
>>> set1.difference(dict1)
{1, 3}
语句
和其它高级程序设计语言一样,代码都是由最基本的语句组成,如条件语句、循环语句等,要想熟练编程,语句相关知识必不可少。
条件语句
条件语句模板如下:其中elif和else都是可选,根据具体业务逻辑进行选择。condition就是具体的条件,只有满足condition时,才会执行其下的代码。pass是空语句,什么都不做,根据具体业务替换成其它可执行语句。
if condition_1:
pass
elif condition_2:
pass
else:
pass
如下举例:从控制台读取一个数字,根据数字的大小,打印不同的输出:
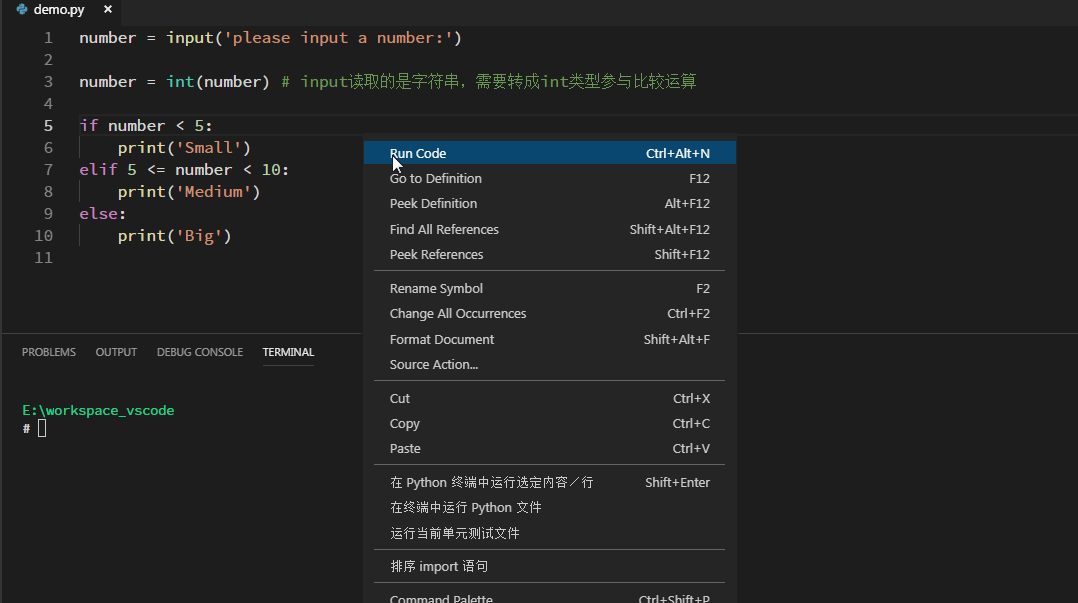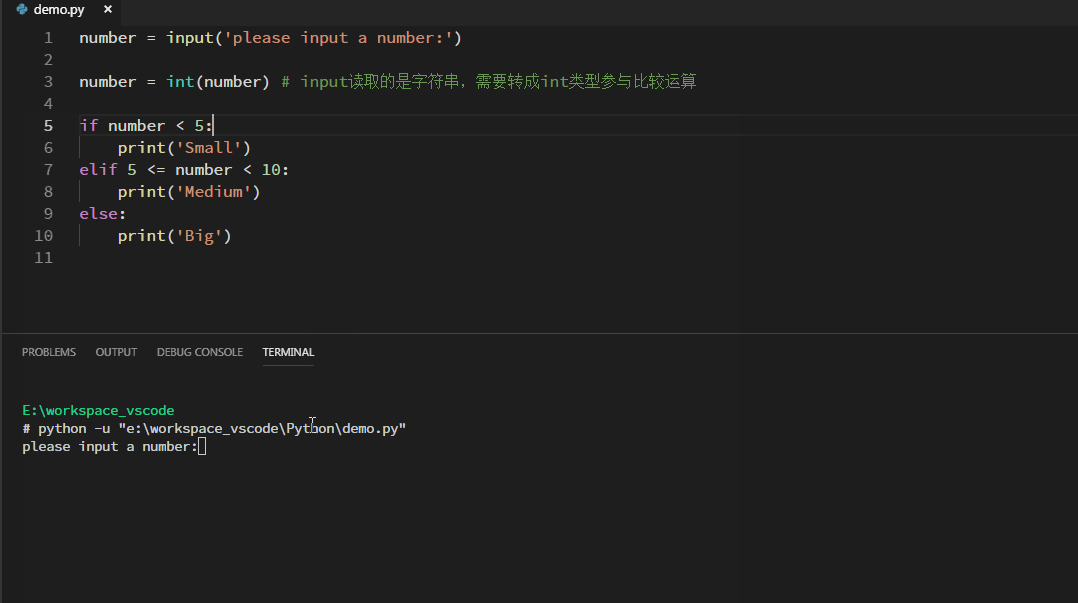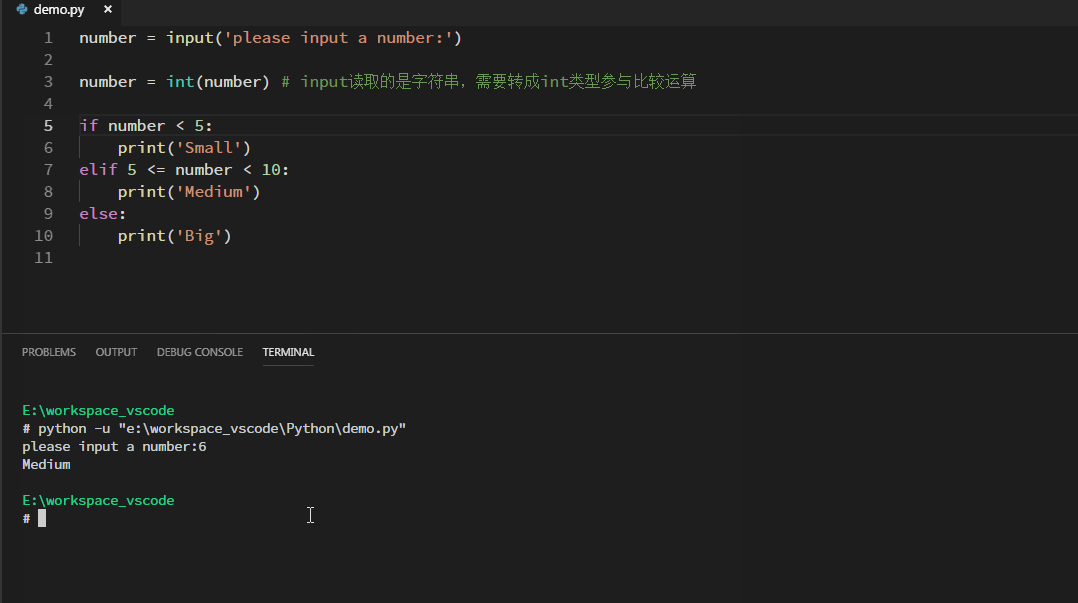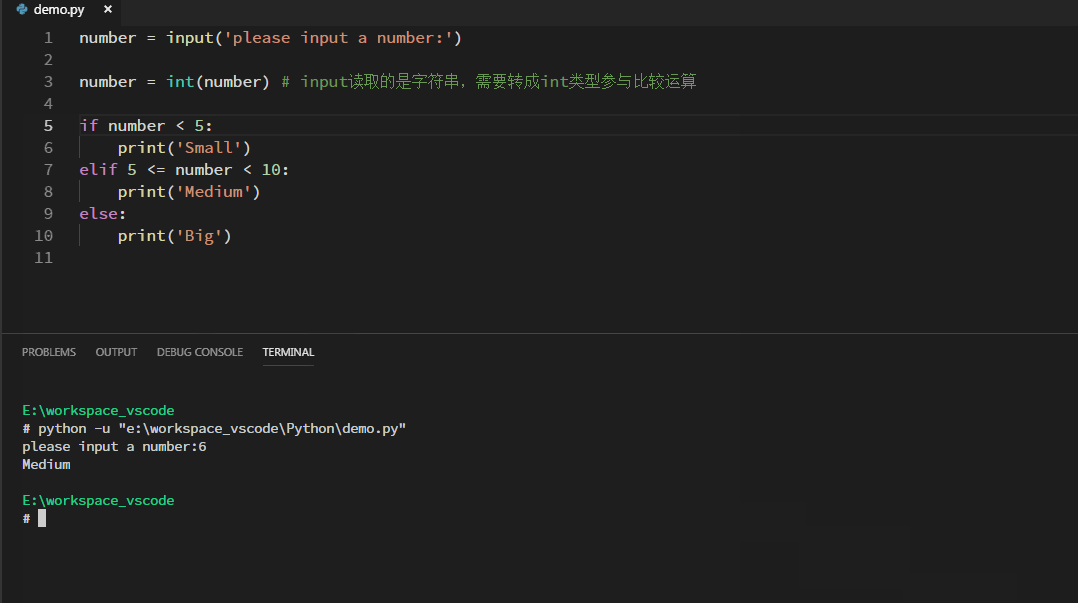
循环语句
while循环
while循环结构:当condition为True时会执行其下代码。
while condidtion:
代码块
例子:打印小于5的整数:
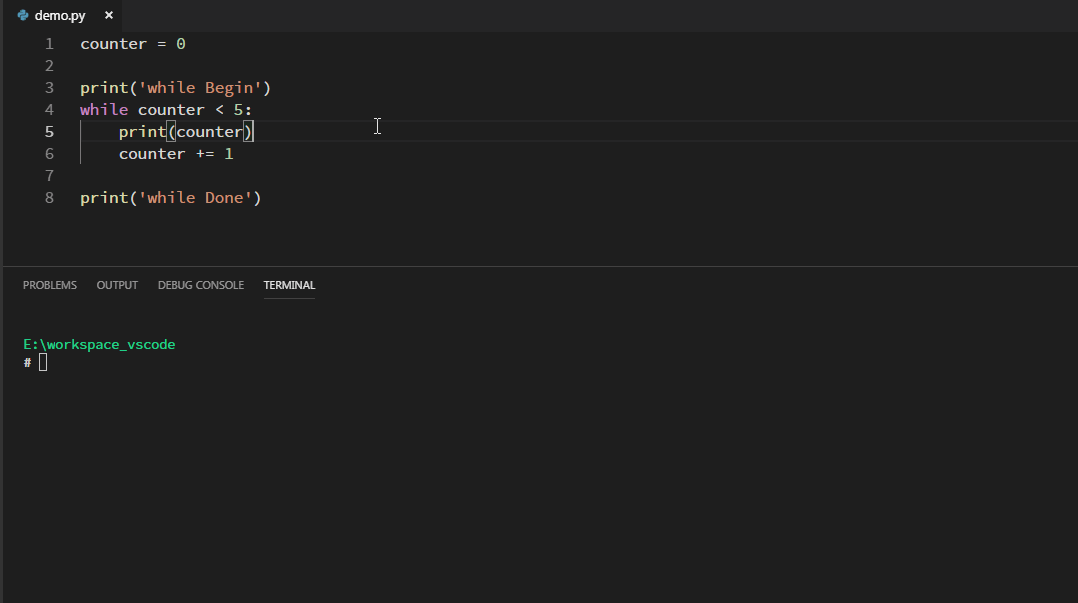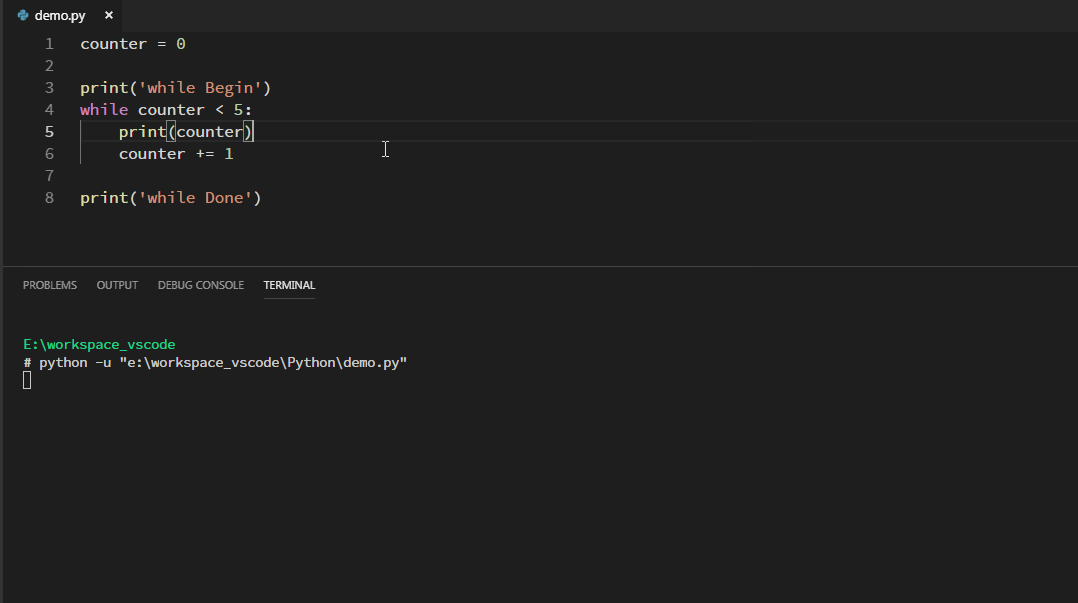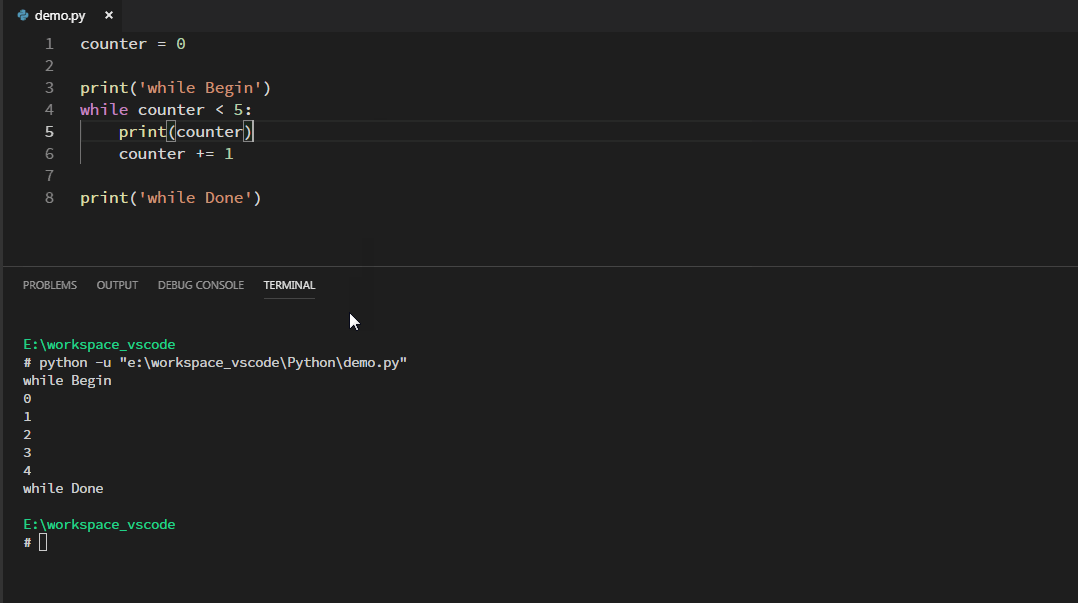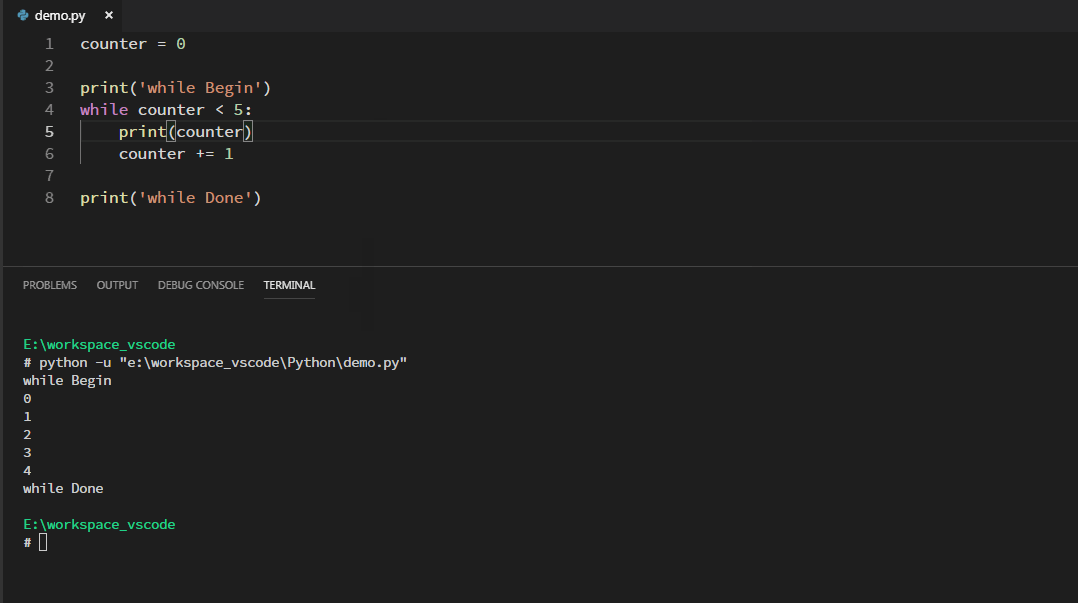
与while同时出现的还可能有else,构成while…else 结构:他表示当condition为False时,执行else下的语句。
while condition:
pass
else:
pass
for循环
for循环结构:表示依次取出expression_list中的元素并赋值给item,直至取完。
for item in expression_list:
pass
同理for循环也可以和else搭配使用,当所有元素遍历完成后执行else中的逻辑。
举例:
list1 = [3, 4, 'a', 'B']
for item in list1:
print(item)
else:
print('for循环执行完毕。')
输出:
3
4
a
B
for循环执行完毕。
但是当for循环中加入break语句,导致元素未遍历完毕而提前跳出循环时,是不会执行else下的语句的:
list1 = [3, 4, 'a', 'B']
for item in list1:
print(item)
if (item == 'a'):
break
else:
print('for循环执行完毕。')
输出:
3
4
a
跳转语句
Python中有两个关键字continue和break用于跳出循环。它们的区别是:continue只能跳出本轮循环,continue后的语句不会执行,但是会继续执行下一轮循环;break直接结束整个循环,不会再执行循环内的任何代码。这和其他编程语言如Java是一致的。
举例:
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
for item in list1:
if (item < 5):
continue
if (item == 8):
break
print(item)
print('跳出for循环')
输出:
5
6
7
跳出for循环
当item小于5的时候,执行了continue,那么本次循环结束,print(item)没有执行,所以1,2,3,4都是没有打印的;当item=8时,执行了break,整个循环结束,尽管还有元素没有遍历到,也不会再循环,所以9也是没有打印的,最终只打印了5,6,7。
with 语句
with语句常常用于优化try except finally语句块,最常用的场景就是打开文件,这样可以省略关闭文件的操作,因为with已经默认做了。但是对于open抛出的异常,with语句并没有捕获。
with open(file_name, 'w', encoding='utf-8') as f:
pass
函数
函数定义:
def funcname(parameter_list):
pass
def :关键字,用于定义函数;
funcname:自定义的函数名称;
paremeter_list:参数列表,可选;
使用return关键字为函数指定返回值,如未指定,默认返回None;
函数调用:
直接使用funcname(value)调用。
函数参数
有四种常见的参数定义和使用方式:
必须参数:
函数定义时,显示指定的参数。当调用时,每一个参数都必须赋值,否则会报TypeError异常。如下当函数定义了两个参数,但是在调用时只传递一个参数,就会报错。
def test(param1, param2):
print('param1 = ' + str(param1), 'param2 = ' + str(param2))
test(1)
输出:
Traceback (most recent call last):
File "e:\workspace_vscode\python\demo.py", line 5, in <module>
test(1)
TypeError: test() missing 1 required positional argument: 'param2'
关键字参数:
默认情况下,函数调用时必须按顺序为参数赋值,但是也可以使用"参数名=参数值"的形式,这样就可以忽略参数顺序。
def print_people(name, age):
print('name = ' + str(name), 'age = ' + str(age))
print_people('Blues', 18) # 普通调用,顺序赋值
print_people(age=18, name='Blues') # 关键字参数调用,可以不用关注参数顺序
可以看到输出是一样的:
name = Blues age = 18
name = Blues age = 18
默认参数 :
函数在定义时可以为参数指定默认值,当函数调用时,如果没有为这个参数赋值,那么将直接使用默认值。
def print_people(name, age=18):
print('name = ' + str(name), 'age = ' + str(age))
print_people('Blues') # 没有指定age
输出:
name = Blues age = 18
不定长参数
也即变长参数,顾名思义实际传递的参数个数是不确定的。像请客吃饭,当不确定有多少人会来时,一般会多留一桌,这样就算还有其他人来,也会有位置坐,不定长参数可以达到类似的效果。使用*或者**定义不定长参数。
使用*定义变长参数:
假设count为原计划宴请的人数,people为实际来的人。
def print_people(count, *people):
print('count = ' + str(count), 'people = ' + str(people))
print_people(1, 'Blues', 'John')
输出:
count = 1 people = ('Blues', 'John')
原计划只有一人,但是现在来了Blues和John两个人,不过people准确的识别出了这两个人(就算更多人也没有问题),同时也可以看出使用*定义的参数使用元组来封装实际传入的值。
使用**定义变长参数:
在上面例子的基础上,再打印出每个人的年龄:
def print_people(count, **people):
print('count = ' + str(count), 'people = ' + str(people))
print_people(1, Blues=18, John=20)
输出:
count = 1 people = {'Blues': 18, 'John': 20}
使用**定义的参数使用字典封装数据,并且使用关键字参数传值,否则会报错。
匿名函数
使用lambba定义匿名函数,顾名思义就是没有函数名的函数,不止如此,与普通函数的定义还是差别挺大的,但是调用并无区别。
定义:
lambda parameter_list: expression
parameter_list:参数列表
expression:函数体,只能是表达式,所以无法处理太过复杂的逻辑。
匿名函数虽然在定义时无法指定函数名,但是可以将整个lambda表达式赋值给一个变量,那么该变量就可以当函数来调用:
sum = lambda x, y: x + y
ret = sum(2, 3)
print(ret)
输出:
5
高阶函数
函数其实就是function类对象(可以使用type(函数名)查看),它可以作为另一个函数的参数,也可以接收其它函数作为参数,甚至作为另一个函数的返回值。
接受其它函数作为参数的函数,称为高阶函数(Higher Order Function),它不是Python的专有名词,在JavaScript等编程语言,甚至其它领域都有这个概念。
Python内置一些常用的高阶函数:
map()
函数原型:
map(func, iterable) --> map object
将iterable中的元素依次传入func参与计算,结果作为map对象的一个元素,最终map()函数返回一个map对象(可迭代对象)。所以,func定义时只能有一个参数。
例子:
L = [1, 2, 3]
def func1(x):
return x + 1
ret = map(func1, L)
print(ret)
for item in ret:
print(item)
输出:
<map object at 0x000000000282CD30>
2
3
4
functools.reduce()
原型:
reduce(function, sequence[, initial]) -> value
和map类似,但是需要import functools才能使用reduce。
它的计算规则是:循环处理sequence中的元素,返回处理后的结果value:
- 第一次循环需要从sequence中取出两个元素传给function(因此function需要接收两个参数,并且有返回值);
- 下次循环时,将上一次的结果作为一个参数,再从sequence取一个参数,把这两个参数传给function;
- 依次类推,相当于叠加处理,直到sequence的所有元素处理完毕。
filter()
函数原型:
filter(function or None, iterable) --> filter object
顾名思义,filter起到过滤的作用,它会将iterable中的元素依次传入function参与计算,如果计算结果是True,则保留该元素,否则,舍弃,最终生成一个filter对象(也是可迭代对象)。若function未指定,也必须写None,那么只保留iterable中值为True的元素。Python大部分对象的值都为True,以下情况除外:
4. None
5. False
6. 所有值为0的数,如0,0.0等
7. 空字符串''
8. 空的列表[]、元组()和字典{}
例子:
L = [0, None, 3, 4]
filter_ret = filter(None, L)
for item in filter_ret:
print(item)
输出:
3
4
变量作用域
作用域限制一个变量的可使用范围。
Python中变量的作用域有四种:
- L(Local):局部作用域,函数内部定义的变量
- E(Enclosing):闭包作用域,闭包函数的外部函数中定义的变量
- G(Global):全局作用域,在函数外部定义的变量。
- B(Built-in):内建作用域,Python解释器在启动时,会加载常用的函数和类到内存中,那么这些函数和类便拥有了内建作用域。
Python解释器对变量的查找规则是:L->E->G->B,所以如果出现同名变量,先找到的变量生效。如下,
a = 1 # 全局作用域
def print_a():
a = 2
print('局部变量a:', a) #局部作用域
print_a()
print('全局变量a:', a)
输出:
局部变量a: 2
全局变量a: 1
从上面的例子可以看出,在函数内部a的值是2,并不受函数外部变量a的影响,并且也无法修改外部a的值。但是如果确实需要在函数内部修改外部变量值,该如何操作? — 使用 global和nolocal关键字。
global允许函数内部修改全局变量,把上面的例子稍加改动:
a = 1 # 全局作用域
def print_a():
global a # 一定要使用global声明,再修改
a = 2
print('局部变量a:', a) #局部作用域
print_a()
print('全局变量a:', a)
输出:可以看到外部变量a的值修改成功。
局部变量a: 2
全局变量a: 2
nolocal与global类似,只不过它允许修改闭包作用域(即外部函数)中的变量:
如下定义一个嵌套函数,内部函数是无法修改外部函数中a的值的,但是加上nolocal之后便可以修改:
def print_a():
a = 1
def print_a_inner():
nonlocal a
a = 2
print('内部函数a:', a) #局部作用域
print_a_inner()
print('外部函数a:', a)
print_a()
输出:
内部函数a: 2
外部函数a: 2
生成器
生成器就是一个generator对象,它可以在循环处理大量数据时节省内存,因为它不需要一次性把所有数据都加载到内存,在使用上类似迭代器。
有两种方式创建生成器对象:
- 使用小括号+推导式
>>> gen = (x for x in range(6))
>>> gen
<generator object <genexpr> at 0x0000000002675ED0>
- 函数+
yield
def gen(max):
i = 0
while i < max:
yield i
i += 1
print(gen)
print(gen(5))
输出:
<function gen at 0x00000000003DC1E0>
<generator object gen at 0x0000000002335ED0>
可以看到gen(5)是一个generator对象。
当遍历生成器时,它会在yield处停止,并返回yield的值,再次遍历时,从yield后继续执行。
可以使用next(gen_obj)从生成器中取得一个值(注意:Python 3中不能使用gen_obj.next()形式,因为该方法已经被移除了),当所有元素遍历完后,再调用next()时会报StopIteration异常,所以最好使用for循环来遍历,不会报异常。并且所有元素只能被遍历一次。
举例:
# 定义生成器
def gen(max):
i = 0
while i < max:
yield i
i += 1
# 创建一个生成器对象
gen_obj = gen(5)
# 使用next获取一个值
print(next(gen_obj))
print('-----------')
# 使用for遍历剩余的所有值
for item in gen_obj:
print(item)
print('-----------')
# 再次使用next获取一个值 --- 会报错,因为已无值可取
print(next(gen_obj))
输出:
0
-----------
1
2
3
4
-----------
Traceback (most recent call last):
File "e:\workspace_vscode\Python\demo.py", line 21, in <module>
print(next(gen_obj))
StopIteration
类
同其它面向对象的高级程序设计语言一样,Python中也有类,同样使用class关键字定义。
class DemoClass:
pass
类属性
属性即类中定义的变量,有些高级语言中叫做成员变量,使用点操作符访问。
class DemoClass:
def __init__(self, name, age):
self.name = name
self.age = age
demo = DemoClass('blues', 28)
print(demo.name, demo.age)
输出:
blues 28
私有属性:
Python中没有指示属性可访问范围的关键字,但是使用双下划线开头的属性具有私有特性,即只能在类内部访问,类外部无法访问到。
构造方法
类的构造方法名称是固定的:__init__,当生成类实例(对象)时,该方法会被自动调用。如下,控制台打印 ‘构造方法…’。
class Demo:
def __init__(self):
print('构造方法..')
# 生成一个Demo实例,此时__init__被调用
demo = Demo()
类方法
类方法就是在类中定义的函数,与普通函数的主要区别是:它的第一个参数必须指定,按照惯例命名为self,表示调用该方法的对象。如果使用其它名称也完全没有问题。
class DemoClass:
def __init__(self):
print('构造方法..')
def run(self):
print('run..')
# 生成一个Demo对象
demo = DemoClass()
# 调用类方法
demo.run()
继承
通过继承,两个原本不相干的类产生了关联,子类可以使用基类的方法、变量等。使用()包含基类,如果有多个,使用逗号分隔。
class Base:
def __init__(self):
print('Base: init')
def run(self):
print('Base: run')
class Sub(Base):
def __init__(self):
Base.__init__(self) # 显示调用父类的构造方法
print('Sub: init')
sub = Sub()
# 调用父类中继承来的run方法
sub.run()
方法重写
当父类方法功能不能完全满足子类要求时,子类可以重写该方法。只能重写方法的实现,不能修改方法名称,参数个数等声明,否则就不是重写,而是定义的新方法。
class Base:
def run(self):
print('Base: run')
class Sub(Base):
# 重写run方法
def run(self):
print('Sub: run')
sub = Sub()
# 调用子类的run方法
sub.run()
文件
使用内置函数open打开文件,返回一个文件流对象,通过该对象操作文件。
函数原型:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
其中file是必须的,指要打开的文件,其它参数可选。
mode:打开模式,常用的模式如下:
| 模式 | 描述 |
|---|---|
| t | 文本文件,默认打开的文件类型 |
| b | 二进制文件,操作二进制文件,如图片等 |
| r | 只读,默认的打开方式,若文件不存在,则报错 |
| w | 只写,若文件不存在,则新建,若存在,则是覆盖写入,即之前的内容会被覆盖掉 |
| a | 打开一个文件,进行追加写入,即从文件指针在文件末尾 |
即mode主要包含两部分内容:要打开的文件类型(t和b)以及打开方式(r、w和a),二者可以任意组合,默认是rt,但是同类型之间不能组合,比如tb或者rw等都是不可以的。那么如果想要打开一个文件,能够同时支持读和写,怎么办?再加一个+就可以了。于是组合就变成了文件类型、打开方式和+三者之间的任意组合,比如:
| 模式 | 描述 |
|---|---|
| r+ | 打开文本文件,进行读写,指针在文件头,若文件不存在,则报错 |
| w+ | 同r+,指针在文件头,区别是,如果文件不存在,会新建 |
| a+ | 打开一个文本文件,进行追加写入,指针在文件末尾,若文件不存在,则新建 |
| wb+ | 打开一个二进制文件进行读写,指针在文件头,若文件不存在,则新建 |
| … |
open()通常与with一起使用:
with open('a.txt', 'a+') as f:
f.write('blues')
文件常用方法
| 方法 | 描述 |
|---|---|
| file.close() | 关闭文件流对象 |
| file.read([size]) | 读取指定字节,若size未指定或越界,则读取整个文件 |
| file.readline() | 读取一行,包括换行符 |
| file.seek(offset[, whence]) | 重新设定文件指针的位置,offset是偏移量。whence可选,表示从哪里偏移,取值0:从文件头,默认;1:从当前位置;2:从文件尾 |
| file.tell() | 返回当前指针位置 |
| file.write(str) | 将字符串写入文件 |
| file.writelines(seq) | 将序列写入文件 |
GUI
使用Python开发图形界面应用,优秀的GUI库有很多,这里列出一部分:
- tkinter(tk): Python自带的标准GUI库,小巧,简单。
- wxPython:开源的Python GUI库,跨平台,功能健全。
- PyQt:大型库,类众多,同样功能强大,界面美观,使用范围广。
- 更多GUI库,请参考GuiProgramming
下面使用tkinter制作的一个简单的demo:
import tkinter as tk
def submit():
pass
# 主界面
root = tk.Tk()
root.title('Tkinter GUI')
root.geometry('300x200') # 主窗口大小
# 标签
label = tk.Label(root, text='请输入姓名:')
label.pack()
# 按钮, command用于设置点击时的操作
button = tk.Button(root, text='提交', command=submit)
button.pack()
# 开启主循环,必须
root.mainloop()
效果:
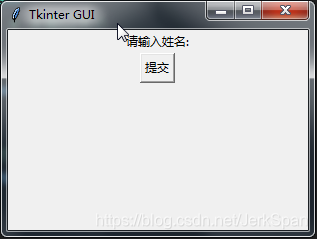
可以看到这里组件不怎么美观,不过也没关系,可以引入ttk下的组件,替换tkinter的默认组件:
import tkinter as tk
from tkinter import ttk
def submit():
pass
# 主界面
root = tk.Tk()
root.title('Tkinter GUI')
root.geometry('300x200') # 主窗口大小
# 标签
label = ttk.Label(root, text='请输入姓名:')
label.pack()
# 按钮, command用于设置点击时的操作
button = ttk.Button(root, text='提交', command=submit)
button.pack()
# 开启主循环,必须
root.mainloop()
效果:
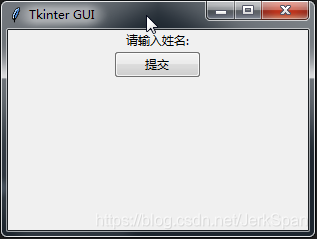
可以看到,按钮确实好看多了,更加贴近系统本地样式。