一、SQL Server调优系列
这是关于SQL Server调优系列文章,以下内容基本涵盖我们日常中所写的查询运算的分解以及调优内容项........
第一个基础模块注重基础内容的掌握,共分7篇文章完成,内容涵盖一系列基础运算算法,详细分析了如何查看执行计划、掌握执行计划优化点,并一一列举了日常我们平常所写的T-SQL语句所会应用的运算符:第二个进阶模块注重SQL Server执行T-SQL语句的时候一些内幕解析,共分为5篇文章完成,其中包括:查询优化器的运行方式、运行时几个优化指标值检测,统计信息、利用索引等一系列内容。通过这块内容让我们了解SQL Server为我们所写的T-SQL语句如何进行优化及运行的。
第三个玩转模块重点跟进特定的问进行特定的提示(Hints),基于前两个模块进行的分析。
SQL Server调优
前言
关于SQL Server调优系列是一个庞大的内容体系,非一言两语能够分析清楚,本篇先就在SQL 调优中所最常用的查询计划进行解析,力图做好基础的掌握,夯实基本功!而后再谈谈整体的语句调优。
通过本篇了解如何阅读和理解查询计划、并且列举一系列最常用的查询执行运算符。
技术准备
基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
一、区别不同的运算符
在所有T-SQL语句在执行的时候,都会将语句分解为一些基本的结构单元,这些结构单元统称为:运算符。每一个运算符都实现一个单独的基本操作,比如:表扫描、索引查找、索引扫描、过滤等。每个运算符可以循环迭代,也可以延续子运算符,这样就可以组成查询树,即:查询计划。
每个T-SQL语句都会通过多种运算符进行组合形成不同的查询计划,并且这些查询计划对于结果的筛选都是有效的,但在执行的时候,SQL Server的查询优化器会自动为我们找到一个最优的。
每一个运算符都会有源数据的传入和结果数据的输出,源数据的输入可以来源于其它的运算符或者直接从数据源表中读取,经过本身的运算进行结果的输出。所以每一个运算符是独立的。互不关心的。
如下例子
SELECT COUNT(*) FROM Orders
此语句会生成两个简单的运算符
当然,在SQL Server中上述的两个运算符有它自己的表达方式,Count(*)是流聚合运算符进行的。
每一个运算符会有三个属性影响其执行的效率
1、内存消耗
所有的运算符都需要一定量的固定内存用以完成执行。当一个T-SQL语句经过编译后生成查询计划后,SQL Server会为认为最优的查询计划尝试去固定内存,目的是为了再次执行的时候不需要再重新申请内存而浪费时间,加快执行速度。
然后,有一些运算符需要额外的内存空间来存储行数据,这样的运算符所需要的内存量通常就和处理的数据行数成正比。如果出现如下几种情况则会导致内存不能申请到,而影响执行性能
a、如果服务器上正在执行其它的类似的内存消耗巨大的查询,导致系统内存剩余不足的时候,当前的查询就得延迟进行,直接影响性能。
b、当并发量过大的的情况下,多个查询竞争有限的内存资源,服务器会适当的控制并发和减少吞吐量来维护机器性能,这时候同样也会影响性能
c、如果当前申请的到可用内存很少的情况下,SQL Server会在执行过程中和磁盘进行交换数据,通常是使用Tempdb临时库进行操作,而这个过程会很慢。更有甚者,会耗尽Tempdb上的磁盘空间以失败结束
通常比较消耗内存的运算符主要有分类、哈希连接以及哈希聚合等连接操作。
2、阻断运算和非阻断运算
所谓阻断和非阻断的区别就是:运算符是否在输入数据的时候能够直接输出结果数据。
a、当一个运算符在消耗输入行的同时生成输出行,这种运算符就是非阻断式的。
比如我们经常使用的 Select Top ...操作,此操作就是输入行的同时进行输出行操作,所以此操作就是非阻断式的。
b、当一个运算符所产生的输出结果需要等待所有的数据输入的时候,这个操作运算就是阻断运算的。
比如上面我们举的例子Count(*)操作,此操作就需要等待所有的数据行输入才能计算出,所以为阻断式运算,另外还有分组计算。
提示:并不是所有的阻断式操作就需要消耗内存,比如Count(*)就为阻断式,但它不消耗内存,但大部分阻断式操作都会消耗内存。
在大部分的OLTP系统中,我们要尽量的使用非阻断式操作来代替阻断式操作,这样才能更好的提高相应时间,比如有时候我们用EXISTS子查询来判断,比用SELECT count(*)>0的速度要理想的多。
二、查看查询计划
在SQL Server2005版本以上,系统提供了三种展示方式:图像方式、文本方式和XML方式。
1、图像方式
图像方式这种方式是最为常见的一种方式,清晰、简洁、易懂。非常适合入门级,当然也有它自身的缺点比如复杂的T-SQL语句会产生较大的图像,查看必须收缩操作,比较麻烦。
SSMS默认给我们提供了查看该查询计划的便捷按钮,需要查看某一条语句的时候,只需要点击上就可以
我们来看一个图像方式展示的查询计划图
DECLARE @Country NVARCHAR(15)
set @Country=N'USA'
SELECT O.CustomerID,MAX(O.Freight) AS MAXFreight
FROM Customers C JOIN Orders O
ON C.CustomerID=O.CustomerID
WHERE C.Country=@Country
GROUP BY O.CustomerID
OPTION(OPTIMIZE FOR (@Country=N'UK'))
以上查询语句所产生的实际执行计划,将其分成了各个不同的运算符进行组合,从最右侧的聚集索引扫描(index scan)然后经过一系列的运算符加工形成最左侧的结果输出(select)。
需要注意的是图中箭头的方向指向的是数据的流向,箭头线的粗细表示了数据量的多少。
在图形化执行计划中,每一个不同的运算符都有它自身的属性值,我们可以把鼠标移至运算符图标上查看
当然也可以直接在图标上右键,查看属性,进入到属性面板,查看更详细的属性值
关于这里面各个运算符的详细指标值,我们在后面介绍,不过这里面有几个关键的值这里可以说是先稍微提一下,关于影响此语句的整体的性能参数,我们可以选择最开始的Select运算符,右键查看属性值
此运算符包含了整条语句的编译时间、所需内存、缓存计划大小、并行度、内存授权、编译执行所需要的参数以及变量值等信息。
此方式作为一种相对直观的方式展示给用户,所以在我们语句调优中占据很大的指导地位,我们知道一条T-SQL语句可能会生成很多不同的执行计划,而SQL Server会帮助我们选择最优的执行计划,当然我们也可以利用它选择的执行计划去调整自己的语句达到优化的目的。
鉴于以上目标,SSMS为我们提供了“评估执行计划”选项,此选项只为评估指导使用,并未实际执行,所以它不包含实际行等具体信息
2、文本方式
此方式在SSMS中默认没有提供快捷键,我们需要自己用语句开启,开启的方式有两种
a、只开启执行计划,不包括详细的评估值
SET SHOWPLAN_TEXT ON
b、开启所有的执行计划明细,包括各个属性的评估值
SET SHOWPLAN_ALL ON
文本方式展现的方式,没有了明确的箭头指示,改用竖线(|)标示子运算符和当前运算的子父关系。并且数据流方向都是从子运算符流向父运算符的,虽然文本展现方式不够直观,但是如果掌握了文本的阅读方式,此方式会更易阅读,尤其在涉及很大的大型计划的时候,此方式更容易保存、处理、搜索和比较。
我们来看一个列子
SET SHOWPLAN_TEXT ON
GO
DECLARE @Country NVARCHAR(15)
SET @Country=N'USA'
SELECT O.CustomerID,MAX(O.Freight) AS MAXFreight
FROM Customers C JOIN Orders O
ON C.CustomerID=O.CustomerID
WHERE C.Country=@Country
GROUP BY O.CustomerID
此种方式输出的形式为文本方式,我们可以拷贝至文本编辑器中分析,方便于查找分析等操作
以上是文本查询计划的分析方式,简单点的就是从最里面的运算符开始执行,数据流方向也是依次从子运算符流向父运算符。
上面的方式看起来有点图像方式,分析起来简单更易用。但是或许缺少的是每个运算符的属性运算信息,我们通过b方法里来查看明细
SET SHOWPLAN_ALL ON
GO
DECLARE @Country NVARCHAR(15)
SET @Country=N'USA'
SELECT O.CustomerID,MAX(O.Freight) AS MAXFreight
FROM Customers C JOIN Orders O
ON C.CustomerID=O.CustomerID
WHERE C.Country=@Country
GROUP BY O.CustomerID
利用此方式可以直观的分析出每个运算符操作的属性评估值。
3、XML方式
XML展现查询计划的方式是SQL Server2005中新加入的功能,此方式结合了文本方式和图形计划方式的优点。利用XML元素的方式展现查询计划。
更主要的特点是利用XML方式是一种规范的方式,可以利用编程的方式进行标准XML操作,利于查询。并且在SQL Server2005中还加入的XML的数据类型,并且内置了XQuery功能进行查询。此方式尤其对与超大型的查询计划查看非常的方便。
通过以下语句开启
SET STATISTICS XML ON
GO
DECLARE @Country NVARCHAR(15)
SET @Country=N'USA'
SELECT O.CustomerID,MAX(O.Freight) AS MAXFreight
FROM Customers C JOIN Orders O
ON C.CustomerID=O.CustomerID
WHERE C.Country=@Country
GROUP BY O.CustomerID
我们可以点击输出的XML进行查看
XML方式展现了非常详细的查询计划信息,我们可以简单的分析下
StmtSimple:描述了T-SQL的执行文本,并且详细分析了该语句的类型,以及各个属性的评估值。
StatementSetOptions:描述该语句的各种属性值的Set值
QueryPlan:是详细的执行计划,包括执行计划的并行的线程数、编译时间、内存占有量等
OutputList:输出参数列表
在中间这部分就是具体的不同的执行运算符的信息了,并且包括详细的预估值等
ParameterList:输出参数列表
XML方式提供的信息是最为全面的,并且在SQL Server内部存储的查询计划类型也为XML数据类型。
三、分析查询计划
当我们拿到一个语句的查询计划,我们应该会分析里面的执行计划的含义,以及各个运算符的属性值,学会如何调整各个运算符的属性值来整体的提高该语句的运行效率。
1、扫描以及查找
对于扫描(scan)和查找(seek)这两种方式是数据库里面从基础数据表里获取的数据的基本方式。
- 当一张表为堆表(没有任何索引)的时候或者获取的数据列不存在任何索引来供查找,此种数据的获取只能通过全表扫描过滤获取,如果存在索引项会通过索引项的扫描来获取数据,提高获取数据的速度。
SELECT OrderID
FROM Orders
WHERE RequiredDate='1998-03-26'
SET SHOWPLAN_ALL ON
GO
SELECT OrderID
FROM Orders
WHERE RequiredDate='1998-03-26'
该方法是最为简单的获取数据的方式
b、如果当前搜寻的数据行存在索引项,那么会采取索引查找(seek)进行数据检索。
SELECT OrderID
FROM Orders
WHERE OrderDate='1998-02-26'
该条语句就是执行的索引查找,因为在Orders表中的OrderDate列存在非聚集索引项。这里顺便提一下如果引入静态变量,SQL Server会自动参数化该值,目的是为了减少编译次数,重复利用执行计划。
由于查找只是搜寻符合条件的这些页进行输出操作,所以查找效率只和符合条件的行数、页数成正比,和整个表中的总行数没有关系。
c、当所选的索引列不包含输出列的时候,也就是说要筛选出的列项不为索引所覆盖,对于这种情况又引出了另外一种查找方式
书签查找(Bookmark Lookup)
其实该方式是扫描和查找之间的一个折中方式,我们知道,如果通过聚集索引扫描,则会获取所有的列,但是这涉及表中的每一行数据,影响性能,相反如果只是通过聚集索引方式进行查找,则有一些列不能获取得到,如果这些列正是我们需要的,这就是不准确的,所以,鉴于此,引入了折中的方式:书签查找(Bookmark Lookup)
简单点讲:书签查找就是通过索引页节点数据查找相关的列数据。
我们来看一个具体的查询列子
SELECT OrderID,CustomerID
FROM Orders
WHERE OrderDate='1998-02-26'
这里需要解释一下,在SQL Server2005 SP2版本以上,书签查找也被称为键查找,其实是一个概念。
这种方式有一些弊端,就是在进行书签查找的时候,如果通过非聚集索引的叶节点查找到聚集索引数据,这种情况通过聚集索引能够快速的获取到数据,如果非聚集索引关键字和聚集索引关键字不存在任何关联,这种情况下,书签查找就会执行随机的I/O操作到聚集索引或者堆表中,而这种情况是非常耗时的,相比而言顺序I/O扫描都要比随机I/O扫描性能好很多。
为了解决上面所述的问题,在SQL Server2005以后的版本中,在创建index的时候引入了INCLUDE关键字。通过创建索引的时候,直接将书签要查找的项直接包含进去,这样就不会发生随机I/O操作。此种方式的缺点会造成索引存储增大一部分,但相比带来的好处,基本可以忽略不计。
结语
此篇文章先到此吧,本篇主要介绍了关于T-SQL语句调优从执行计划该如下下手,并介绍了几个常见的简单运算符,下一篇将着重介绍我们最常用的一些运算符和调优技巧,包括:连接运算符、聚合运算符、联合运算符、并行运算等吧,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。
SQL Server调优(常用运算符总结——三种物理连接方式剖析)
前言
上一篇我们介绍了如何查看查询计划,本篇将介绍在我们查看的查询计划时的分析技巧,以及几种我们常用的运算符优化技巧,同样侧重基础知识的掌握。
通过本篇可以了解我们平常所写的T-SQL语句,在SQL Server数据库系统中是如何分解执行的,数据结果如何通过各个运算符组织形成的。
技术准备
基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
一、数据连接
数据连接是我们在写T-SQL语句的时候最常用的,通过两个表之间关联获取想要的数据。
SQL Server默认支持三种物理连接运算符:嵌套循环连接、合并连接以及哈希连接。三种连接各有用途,各有特点,不同的场景会数据库会为我们选择最优的连接方式。
a、嵌套循环连接(nested loops join)
嵌套循环连接是最简单也是最基础的连接方式。两张表通过关键字进行关联,然后通过双层循环依次进行两张表的行进行关联,然后通过关键字进行筛选。
可以参照下图进行理解分析
其实嵌套扫描是很简单的获取数据的方式,简单点就是两层循环过滤出结果值。
我们可以通过如下代码加深理解
for each row R1 in the outer table
for each row R2 int the inner table
if R1 join with R2
return (R1,R2)
举个列子
SELECT o.OrderID
FROM Customers C JOIN Orders O
ON C.CustomerID=O.CustomerID
WHERE C.City=N'London'
以上这个图标就是嵌套循环连接的图标了。而且解释的很明确。
这种方法的消耗就是外表和内表的乘积,其实就是我们所称呼的笛卡尔积。所以消耗的大小是随着两张表的数据量增大而增加的,尤其是内部表,因为它是多次重复扫描的,所以我们在实践中的采取的措施就是减少每个外表或者内表的行数来减少消耗。
对于这种算法还有一种提高性能的方式,因为两张表是通过关键字进行关联的,所以在查询的时候对于底层的数据获取速度直接关乎着此算法的性能,这里优化的方式尽量使用两个表关键字为索引查询,提高查询速度。
还有一点就是在嵌套循环连接中,在两张表关联的时候,对外表都是有筛选条件的,比如上面例子中【WHERE C.City=N'London'】就是对外表(Customers)的筛选,并且这里的City列在该表中存在索引,所以该语句的两个子查询都为索引查找(Index Seek)。
但是,有些情况我们的查询条件不是索引所覆盖的,这时候,在嵌套循环连接下的子运算符就变成了索引扫描(Index scan)或者RID查找。
举个例子
SELECT E1.EmployeeID,COUNT(*)
FROM Employees E1 JOIN Employees E2
ON E1.HireDate>E2.HireDate
GROUP BY E1.EmployeeID
以上代码是从职工表中获取出每位职工入职前的人员数。我们看一下该查询的执行计划
这里很显然两个表的关联通过的是HireDate列进行,而此列又不为索引项所覆盖,所以两张表的获取只能通过全表的聚集索引扫描进行,如果这两张表数据量特别大的话,无疑又是一个非常耗性能的查询。
通过文本可以看出,该T-SQL的查询结果的获取是通过在嵌套循环运算符中,对两个表经过全表扫描之后形成的笛卡儿积进行过滤筛选的。这种方式其实不是一个最优的方式,因为我们获取的结果其实是可以先通过两个表过滤之后,再通过嵌套循环运算符获取结果,这样的话性能会好很多。
我们尝试改一下这个语句
SELECT E1.EmployeeID,ECNT.CNT
FROM Employees E1 CROSS APPLY
(
SELECT COUNT(*) CNT
FROM Employees E2
WHERE E1.HireDate<E2.HireDate
)ECNT
通过上述代码查询的结果项,和上面的是一样的,只是我们根据外部表的结果对内部表进行了过滤,这样执行的时候就不需要获取全部数据项了。
我们查看下文本执行计划
我们比较一下,前后两条语句的执行消耗,对比一下执行效率
执行时间从1秒179毫秒减少至93毫秒。效果明显。
对比CPU消耗、内存、编译时间等总体消耗都有所降低,参考上图。
所以对嵌套循环连接连接的优化方式就是集中在这几点:对两张表数据量的减少、连接关键字上建立索引、谓词查询条件上覆盖索引最好能减少符合谓词条件的记录数。
b、合并连接(merge join)
上面提到的嵌套循环连接方式存在着诸多的问题,尤其不适合两张表都是大表的情况下,因为它会产生N多次的全表扫描,很显然这种方式会严重的消耗资源。
鉴于上述原因,在数据库里又提供了另外一种连接方式:合并连接。记住这里没有说SQL Server所提供的,是因为此连接算法是市面所有的RDBMS所共同使用的一种连接算法。
合并连接是依次读取两张表的一行进行对比。如果两个行是相同的,则输出一个连接后的行并继续下一行的读取。如果行是不相同的,则舍弃两个输入中较少的那个并继续读取,一直到两个表中某一个表的行扫描结束,则执行完毕,所以该算法执行只会产生每张表一次扫描,并且不需要整张表扫描完就可以停止。
该算法要求按照两张表进行依次扫描对比,但是有两个前提条件:1、必须预先将两张表的对应列进行排序;2、对两张表进行合并连接的条件必须存在等值连接。
我们可以通过以下代码进行理解
get first row R1 from input1get first row R2 from input2while not at the end of either input
begin
if R1 joins with R2
begin
output(R1,R2)
get next row R2 from input2
end
else if R1<R2
get next row R1 from input1
else
get next row R2 from input2
end
合并连接运算符总的消耗是和输入表中的行数成正比的,而且对表最多读取一次,这个和嵌套循环连接不一样。因此,合并连接对于大表的连接操作是一个比较好的选择项。
对于合并连接可以从如下几点提高性能:
两张表间的连接值内容列类型,如果两张表中的关联列都为唯一列,也就说都不存在重复值,这种关联性能是最好的,或者有一张表存在唯一列也可以,这种方式关联为一对多关联方式,这种方式也是我们最常用的,比我们经常使用的主从表关联查询;如果两张表中的关联列存在重复值,这样在两表进行关联的时候还需要借助第三张表来暂存重复的值,这第三张表叫做”worktable “是存放在Tempdb或者内存中,而这样性能就会有所影响。所以鉴于此,我们常做的优化方式有:关联连尽量采用聚集索引(唯一性)
我们知道采用该种算法的前提是,两张表都经过排序,所以我们在应用的时候,最好优先使用排序后的表关联。如果没有排序,也要选择的关联项为索引覆盖项,因为大表的排序是一个很耗资源的过程,我们选择索引覆盖列进行排序性能要远远好于普通列的排序。
我们来举个例子
SELECT O.CustomerID,C.CustomerID,C.ContactName
FROM Orders O JOIN Customers C
ON O.CustomerID=C.CustomerID
我们知道这段T-SQL语句中关联项用的是CustomerID,而此列为主键聚集索引,都是唯一的并且经过排序的,所以这里面没有显示的排序操作。
而且凡是采用合并连接的所有输出结果项,都是已经经过排序的。
我们找一个稍复杂的情况,没有提前排序的利用合并查询的T-SQL
SELECT O.OrderID,C.CustomerID,C.ContactName
FROM Orders O JOIN Customers C
ON O.CustomerID=C.CustomerID AND O.ShipCity<>C.City
ORDER BY C.CustomerID
上述代码返回那些客户的发货订单不在客户本地的。
上面的查询计划可以看出,排序的消耗总是巨大的,其实我们上面的语句按照逻辑应该是在合并连接获取数据后,才采用显示的按照CustomerID进行排序。
但是因为合并连接运算符之前本身就需要排序,所以此处SQL Server采取了优先排序的策略,把排序操作提前到了合并连接之前进行,并且在合并连接之后,就不需要在做额外的排序了。
这其实这里我们要求对查询结果排序,正好也利用了合并连接的特点。
c、哈希连接(hash join)
我们分析了上面的两种连接算法,两种算法各有特点,也各有自己的应用场景:嵌套循环连接适合于相对小的数据集连接,合并连接则应对与中型的数据集,但是又有它自己的缺点,比如要求必须有等值连接,并且需要预先排序等。
那对于大型的数据集合的连接数据库是怎么应对的呢?那就是哈希连接算法的应用场景了。
哈希连接对于大型数据集合的并行操作上都比其它方式要好很多,尤其适用于OLAP数据仓库的应用场景中。
哈希连接很多地方和合并连接类似,比如都需要至少一个等值连接,同样支持所有的外连接操作。但不同于合并连接的是,哈希连接不需要预先对输入数据集合排序,我们知道对于大表的排序操作是一个很大的消耗,所以去除排序操作,哈希操作性能无疑会提升很多。
哈希连接在执行的时候分为两个阶段:
构建阶段
在构建阶段,哈希连接从一个表中读入所有的行,将等值连接键的行机型哈希话处理,然后创建形成一个内存哈希表,而将原来列中行数据依次放入不同的哈希桶中。
探索阶段
在第一个阶段完成之后,开始进入第二个阶段探索阶段,该阶段哈希连接从第二个数据表中读入所有的行,同样也是在相同的等值连接键上进行哈希。哈希过程桶上一阶段,然后再从哈希表中探索匹配的行。
上述的过程中,在第一个阶段的构建阶段是阻塞的,也就是说在,哈希连接必须读入和处理所有的构建输入,之后才能返回行。而且这一过程是需要一块内存存储提供支持,并且利用的是哈希函数,所以相应的也会消耗CPU等。
并且上述流程过程中一般采用的是并发处理,充分利用资源,当然系统会对哈希的数量有所限制,如果数据量超大,也会发生内存溢出等问题,而对于这些问题的解决,SQL Server有它自身的处理方式。
我们可通过以下代码进行理解
--构建阶段for each row R1 in the build table
begin
calculate hash value on R1 join key(s)
insert R1 into the appropriate hash bucket
end--探索阶段for each row R2 in the probe table
begin
calculate hash value on R2 join key(s)
for each row R1 in the corresponding hash bucket
if R1 joins with R2
output(R1,R2)
end
在哈希连接执行之前,SQL Server会估算需要多少内存来构建哈希表。基本估算的方式就是通过表的统计信息来估算,所以有时候统计信息不准确,会直接影响其运算性能。
SQL Server默认会尽力预留足够的内存来保证哈希连接成功的构建,但是有时候内存不足的情况下,就必须采取将一小部分的哈希表分配到硬盘中,这里就存入到了tempdb库中,而这一过程会反复多次循环执行。
举个列子来看看
SELECT O.OrderID,O.OrderDate,C.CustomerID,C.ContactName
FROM Orders O JOIN Customers C
ON O.CustomerID=C.CustomerID
我们来分析上面的执行语句,上面的执行结果通过CustomerID列进行关联,理论将最合适的应该是采用合并连接操作,但是合并连接需要排序,但是我们在语句中没有指定Order by 选项,所以经过评估,此语句采用了哈希连接的方式进行了连接。
我们给它加上一个显示的排序,它就选用合并连接作为最优的连接方式
SELECT O.OrderID,O.OrderDate,C.CustomerID,C.ContactName
FROM Orders O JOIN Customers C
ON O.CustomerID=C.CustomerID
ORDER BY O.CustomerID
我们来总结一下这个算法的特点
和合并连接一样算法复杂度基本就是分别遍历两边的数据集各一遍
它不需要对数据集事先排序,也不要求上面有什么索引,通过的是哈希算法进行处理
基本采取并行的执行计划的方式
但是,该算法也有它自身的缺点,因为其利用的是哈希函数,所以运行时对CPU消耗高,同样对内存也比较大,但是它可以采用并行处理的方式,所以该算法用于超大数据表的连接查询上显示出自己独有的优势。
关于哈希算法在哈希处理过程的时候对内存的占用和分配方式,是有它自己独有哈希方法,比如:左深度树、右深度树、浓密哈希连接树等,这里不做详细介绍了,只需要知道其使用方式就可以了。
Hash Join并不是一种最优的连接算法,只是它对输入不优化,因为输入数据集特别大,并且对连接符上有没有索引也没要求。其实这也是一种不得已的选择,但是该算法又有它适应的场景,尤其在OLAP的数据仓库中,在一个系统资源相对充足的环境下,该算法就得到了它发挥的场景。
当然前面所介绍的两种算法也并不是一无是处,在业务的OLTP系统库中,这两种轻量级的连接算法,以其自身的优越性也获得了认可。
所以这三种算法,没有谁好谁坏,只有合适的场景应用合适的连接算法,这样才能发挥它自身的长处,而恰巧这些就是我们要掌握的技能。
这三种连接算法我们也可以显示的指定,但是一般不建议这么做,因为默认SQL Server会为我们评估最优的连接方式进行操作,当然有时候它评估不对的时候就需要我们自己指定了,方法如下:
SELECT O.OrderID,O.OrderDate,C.CustomerID,C.ContactName
FROM Orders O inner loop JOIN Customers C
ON O.CustomerID=C.CustomerID
二、聚合操作
聚合也是我们在写T-SQL语句的时候经常遇到的,我们来分析一下一些常用的聚合操作运算符的特性和可优化项。
a、标量聚合
标量聚合是一种常用的数据聚合方式,比如我们写的语句中利用的以下聚合函数:MAX()、MIN()、AVG()、COUNT()、SUM()
以上的这些数据结果项的输出基本都是通过流聚合的方式产生,并且这个运算符也被称为:标量聚合
先来看一个列子
SELECT COUNT(*) FROM Orders
上面的图表就是流聚合的运算符了。
上图还有一个计算标量的运算符,这是因为在流聚合产生的结果项数据类型为Bigint类型,而默认输出为int类型,所以增加了一个类型转换的运算符。
我们来看一个不需要转换的
SELECT MIN(OrderDate),MAX(OrderDate) FROM Orders
看一下求平均数的运算符
SELECT AVG(Freight) FROM Orders
求平均数的时候,在SQL Server执行的时候也给我们添加了一个case when分类,防止分母为0的情况发生。
我们来看DISTINCT下的情况下,执行计划
SELECT COUNT(DISTINCT ShipCity) FROM Orders
SELECT COUNT(DISTINCT OrderID) FROM Orders
上面相同的语句,但是产生了不同的执行计划,只是因为发生在不同列的数量汇总上,因为OrderID不存在重复列,所以SQL Server不需要排序直接流聚合就可以产生汇总值,而ShipCity不同它会有重复的值,所以只能经过排序后再流聚合依次获取汇总值。
其实,流聚合这种算法最常用的方式是分组(GROUP BY)计算,上面的标量计算也是利用这个特性,只不过把整体形成了一个大组进行聚合。
我么通过如下代码理解
clear the current aggredate results
clear the current group by columnsfor each input row
begin
if the input row does not match the current group by columns
begin
output the current aggreagate results(if any)
clear the current aggreagate results
set the current group by columns to the input row
end
update the aggregate results with the input row
end
流聚合运算符其实过程很简单,维护一个聚合组和聚合值,依次扫描表中的数据,如果能匹配聚合组则忽略,如果不匹配,则加入到聚合组中并且更新聚合值结果项。
举个例子
SELECT ShipAddress,ShipCity,COUNT(*)
FROM Orders
GROUP BY ShipAddress,ShipCity
这里使用了流聚合,并且之前先对两列进行排序,排序的消耗总是很大。
如下代码就不会产生排序
SELECT CustomerID,COUNT(*)
FROM Orders
GROUP BY CustomerID
所以这里我们已经总结出对于流聚合的一种优化方式:尽量避免排序产生,而要避免排序就需要将分组(Group by)字段在索引覆盖范围内。
b、哈希聚合
上述的流聚合的方式需要提前排序,我们知道排序是一个非常大的消耗过程,所以不适合大表的分组聚合操作,为了解决这个问题,又引入了另外一种聚合运算:哈希聚合
所谓的哈希聚合内部的方法和本篇前面提到的哈希连接机制一样。
哈希聚合不需要排序和过大的内存消耗,并且很容易并行执行计划,利用多CPU同步进行,但是有一个缺点就是:这一过程是阻塞的,也就说哈希聚合不会产生任何结果直到完整的输入。
所以在大数据表中采用哈希聚合是一个很好的应用场景。
通过如下代码加深理解
for each input row
begin
calculate hash value on group by columns
check for a matching row in the hash table
if maching row not found
insert a new row into the hash table
else
update the matching row with the input row
end--最后输出结果
ouput all rows in the hash table
简单点将就是在进行运算匹配前,先将分组列进行哈希处理,分配至不同的哈希桶中,然后再依次匹配,最后才输出结果。
举个例子
SELECT ShipCountry,COUNT(*)
FROM Orders
GROUP BY ShipCountry
这个语句很有意思,我们利用了ShipCountry进行了分组,我们知道该列没有被索引覆盖,按照道理,其实选择流聚合应该也是不错的方式,跟上面我们列举的列子一样,先对这个字段进行排序,然后利用流聚合形成结果项输出。
但是,为什么这个语句SQL Server为我们选择了哈希匹配作为了最优的算法呢!!!
我么来比较两个分组字段:ShipCountry和前面的ShipAddress
前面是国家,后面是地址,国家是很多重复的,并且只有少数的唯一值。而地址就不一样了,离散型的分布,我们知道排序是很耗资源的一件事情,但是利用哈希匹配只需要将不同的列值进行提取就可以,所以相比性能而言,无疑哈希匹配算法在这里是略胜一筹的算法。
而上面关于这两列内容分布类型SQL Server是怎样知道的?这就是SQL Server的强大的统计信息在支撑了。
在SQL Server中并不是固定的语句就会形成特定的计划,并且生成的特定计划也不是总是最优的,这和数据库现有数据表中的内容分布、数据量、数据类型等诸多因素有关,而记录这些详细信息的就是统计信息。
所有的最优计划的选择都是基于现有统计信息来评估,如果我们的统计信息未及时更新,那么所评估出来最优的执行计划将不是最好的,有时候反而是最烂的。
参考文献
微软联机丛书逻辑运算符和物理运算符引用
参照书籍《SQL.Server.2005.技术内幕》系列
结语
此篇文章先到此吧,本篇主要介绍了关于T-SQL语句调优从执行计划下手,并介绍了三个常见的连接运算符和聚合操作符,下一篇将着重介绍我们其它最常用的一些运算符和调优技巧,包括:CURD等运算符、联合运算符、索引运算、并行运算等吧,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。
SQL Server调优(联合运算符总结)
前言
上两篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符的优化技巧,本篇我们总结联合运算符的使用方式和优化技巧。
废话少说,直接进入本篇的主题。
技术准备
基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
一、联合运算符
所谓的联合运算符,其实应用最多的就两种:UNION ALL和UNION。
这两个运算符用法很简单,前者是将两个数据集结果合并,后者则是合并后进行去重操作,如果有过写T-SQL语句的码农都不会陌生。
我们来分析下这两个运算符在执行计划中的显示,举个例子
SELECT FirstName+N''+LastName,City,Country FROM Employees
UNION ALL
SELECT ContactName,City,Country FROM Customers
就是上面这个图标了,这就是UNION ALL联合运算符的图标。
这个联合运算符很简单的操作,将两个数据集合扫描完通过联合将结果汇总。
我们来看一下UNION 这个运算符,例子如下
select City,Country from Employees
UNION
SELECT City,Country FROM Customers
我们可以看到,UNION 运算符是在串联运算符之后发生了一个Distinct Sort排序操作,经过这个操作会将结果集合中的重复值去掉。
我们一直强调:大数据表的排序是一个非常耗资源的动作!
所以,到这里我们已经找到了可优化的选项,去掉排序,或者更改排序方式。
替换掉Distinct Sort排序操作的方式就是哈序聚合。Distinct Sort排序操作需要的内存和去除重复之前数据集合的数据量成正比,而哈希聚合需要的内存则是和去除重复之后的结果集成正比!
所以如果数据行中重复值很多,那么相比而言通过哈希聚合所消耗的内存会少。
我们来举个例子
select ShipCountry from Orders
UNION
SELECT ShipCountry FROM Orders
这个例子其实没啥用处,这里就是为了演示,我们来看一下结果
我们知道,这张表里这个ShipCountry是存在大面积重复值的,所以采用了哈希匹配来去重操作是最优的方式。
其实,相比哈希匹配连接还有一种更轻量级的去重的连接方式:合并连接
上一篇我已经分析了这个连接方法,用于两个数据集的连接方式,这里其实类似,应用前都必须先将原结果集合排序!
我们知道优化的方式可以采用建立索引来提高排序速度。
我们来重现这种去重方式,我们新建一个表,然后建立索引,代码如下
--新建表
SELECT EmployeeID,FirstName+N' '+LastName AS ContactName,City,Country
INTO NewEmployees
FROM Employees
GO--添加索引
ALTER TABLE NewEmployees ADD CONSTRAINT PK_NewEmployees PRIMARY KEY(EmployeeID)
CREATE INDEX ContactName ON NewEmployees(ContactName)
CREATE INDEX ContactName ON CUSTOMERS(ContactName)
GO--新建查询,这里一定要加上一个显示的Order by才能出现合并连接去重
SELECT ContactName FROM NewEmployees
UNION ALL
SELECT ContactName FROM Customers
ORDER BY ContactName
我们采用索引扫描的方式可以避免显式的排序操作。
我们将UNION ALL改成UNION,该操作将会对两个数据集进行去重操作。
--新建查询,这里一定要加上一个显示的Order by才能出现合并连接去重
SELECT ContactName FROM NewEmployees
UNION
SELECT ContactName FROM Customers
ORDER BY ContactName
这里我们知道UNION操作会对结果进行去重操作,上面应用了流聚合操作,流聚合一般应用于分组操作中,当然这里用它进行了分组去重。
在我们实际的应用环境中,最常用的方式还是合并连接,但是有一种情况最适合哈希连接,那就是一个小表和大表进行联合操作,尤其适合哪种大表中存在大量重复值的情况下。
哈希算法真是个好东西!
参考文献
微软联机丛书逻辑运算符和物理运算符引用
参照书籍《SQL.Server.2005.技术内幕》系列
结语
此篇文章先到此吧,简短一点,便于理解掌握,本篇主要介绍了查询计划中的联合操作运算符,下一篇我们分析SQL Server中的并行运算,在多核超线程云集的今天,来看SQL Server如何利用并行运算来最大化的利用现有硬件资源提升性能,有兴趣可提前关注,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。
SQL Server调优(并行运算总结)
前言
上三篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符、联合运算符的优化技巧。
本篇我们分析SQL Server的并行运算,作为多核计算机盛行的今天,SQL Server也会适时调整自己的查询计划,来适应硬件资源的扩展,充分利用硬件资源,最大限度的提高性能。
闲言少叙,直接进入本篇的正题。
技术准备
同前几篇一样,基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
一、并行运算符
在我们日常所写的T-SQL语句,并不是所有的最优执行计划都是一样的,其最优的执行计划的形成需要多方面的评估才可以,大部分根据SQL Server本身所形成的统计信息,然后对形成的多个执行计划进行评估,进而选出最优的执行方式。
在SQL Server根据库内容形成的统计信息进行评估的同时,还要参照当前运行的硬件资源,有时候它认为最优的方案可能当前硬件资源不支持,比如:内存限制、CPU限制、IO瓶颈等,所以执行计划的优劣还要依赖于底层硬件。
当SQL Server发现某个处理的数据集比较大,耗费资源比较多时,但此时硬件存在多颗CPU时,SQL Server会尝试使用并行的方法,把数据集拆分成若干个,若干个线程同时处理,来提高整体效率。
在SQL Server中可以通过如下方法,设置SQL Server可用的CPU个数
默认SQL Server会自动选择CPU个数,当然不排除某些情况下,比如高并发的生产环境中,防止SQL Server独占所有CPU,所以提供了该配置的界面。
还有一个系统参数,就是我们熟知的MAXDOP参数,也可以更改此系统参数配置,该配置也可以控制每个运算符的并行数(记住:这里是每个运算符的,而非全部的),我们来查看该参数
这个并行运算符的设置数,指定的是每个运算符的最大并行数,所以有时候我们利用查看系统任务数的DMV视图sys.dm_os_tasks来查看,很可能看到大于并行度的线程数据量,也就是说线程数据可能超过并行度,原因就是两个运算符重新划分了数据,分配到不同的线程中。
这里如没特殊情况的话,建议采用默认设置最佳。
我们举一个分组的例子,来理解并行运算
采用并行运算出了提升性能还有如下几个优点:
不依赖于线程的数量,在运行时自动的添加或移除线程,在保证系统正常吞吐率的前提下达到一个性能最优值
能够适应倾斜和负载均衡,比如一个线程运行速度比其它线程慢,这个线程要扫描或者运行的数量会自动减少,而其它跑的快的线程会相应提高任务数,所以总的执行时间就会平稳的减少,而非一个线程阻塞整体性能。
下面我们来举个例子,详细的说明一下
并行计划一般应用于数据量比较大的表,小表采用串行的效率是最高的,所以这里我们新建一个测试的大表,然后插入部分测试数据,我们插入250000行,整体表超过6500页,脚本如下
--新建表,建立主键,形成聚集索引
CREATE TABLE BigTable
(
[KEY] INT,
DATA INT,
PAD CHAR(200),
CONSTRAINT [PK1] PRIMARY KEY ([KEY])
)
GO--批量插入测试数据250000行
SET NOCOUNT ON
DECLARE @i INT
BEGIN TRAN
SET @i=0
WHILE @i<250000
BEGIN
INSERT BigTable VALUES(@i,@i,NULL)
SET @i=@i+1
IF @i%1000=0
BEGIN
COMMIT TRAN
BEGIN TRAN
END
END
COMMIT TRAN
GO
我们来执行一个简单查询的脚本
SELECT [KEY],[DATA]
FROM BigTable
这里对于这种查询脚本,没有任何筛选条件的情况下,没必要采用并行扫描,因为采用串行扫描的方式得到数据的速度反而比并行扫描获取的快,所以这里采用了clustered scan的方式,我们来加一个筛选条件看看
SELECT [KEY],[DATA]
FROM BigTable
WHERE DATA<1000
对于这个有筛选条件的T-SQL语句,这里SQL Server果断的采用的并行运算的方式,聚集索引也是并行扫描,因为我电脑为4个逻辑CPU(其实是2颗物理CPU,4线程),所以这里使用的是4线程并行扫描四次表,每个线程扫描一部分数据,然后汇总。
这里总共用了4个线程,其中线程0为调度线程,负责调度所有的其它线程,所以它不执行扫描,而线程1到线程4执行了这1000行的扫描!当然这里数据量比较少,有的线程分配了0个任务,但是总得扫描次数为4次,所以这4个线程是并行的扫描了这个表。
可能上面获取的结果比较简单,有的线程任务还没有给分配满,我们来找一个相对稍复杂的语句
SELECT MIN([DATA])
FROM BigTable
这个执行计划挺简单的,我们依次从右边向左分析,依次执行为:
4个并行聚集索引扫描——>4个线程并行获取出前当前线程的最小数——>执行4个最小数汇总——>执行流聚合获取出4个数中的最小值——>输出结果项。
然后4个线程,每个线程一个流聚合获取当前线程的最小数
然后,将这个四个最小值经过下一个“并行度”的运算符汇聚成一个表
然后下一个就是流聚合,从这个4行数据中获取出最小值,进行输出,关于流聚合我们上一篇文章中已经介绍
以上就一个一个标准的多线程并行运算的过程。
上面的过程中,因为我们使用的并行聚集索引扫描数据,4个线程基本上是平均分摊了任务量,也就是说每个线程扫描的数据量基本相等,下面我们将一个线程使其处于忙碌状态,看看SQL Server会不会将任务动态的平摊到其它几个不忙碌的线程上。
我们在来添加一个大数据量表,脚本如下
SELECT [KEY],[DATA],[PAD]
INTO BigTable2
FROM BigTable
我们来写一个大量语句的查询,使其占用一个线程,并且我们这里强制指定只用一个线程运行
SELECT MIN(B1.[KEY]+B2.[KEY])
FROM BigTable B1 CROSS JOIN BigTable2 B2
OPTION(MAXDOP 1)
以上代码想跑出结果,就我这个电脑配置估计少说五分钟以上,并且我们还强行串行运算,速度可想而知,
我们接着执行上面的获取最小值的语句,查看执行计划
SELECT MIN([DATA])
FROM BigTable
我们在执行计划中,查看到了聚集索引扫描的线程数量
可以看到,线程1已经数量减少了近四分之的数据,并且从线程1到线程4,所扫描的数据量是依次增加的。
我们上面的语句很明确的指定了MAXDOP为1,理论上讲只可能会影响一个线程,为什么这几个线程都影响呢?其实这个原因很简单,我的电脑是物理CPU只有两核,所谓的线程数只是超线程,所以非传统意义上的真正的4核数,所以线程之间是互相影响的。
我们来看一个并行连接操作的例子,我们查看并行嵌套循环是怎样利用资源的
SELECT B1.[KEY],B1.DATA,B2.DATA
FROM BigTable B1 JOIN BigTable2 B2
ON B1.[KEY]=B2.[KEY]
WHERE B1.DATA<100
上面的语句中,我们在BigTable中Key列存在聚集索引,而查询条件中DATA列不存在,所以这里肯定为聚集索引扫描,对数据进行查找
来看执行计划
我们依次来分析这个流程,结合文本的执行计划分析更为准确,从右边依次向左分析
第一步,就是利用全表通过聚集索引扫描获取出数据,因为这里采用的并行的聚集索引扫描,我们来看并行的线程数和扫描数
四个线程扫描,这里线程3获取出数据100行数据。
然后将这100行数据,重新分配线程,这里每个线程平均分配到25行数据
到此,我们要获取的结果已经均分成4个线程共同执行,每个线程分配了25行数据,下一步就是交给嵌套循环连接了,因为我们上面的语句中需要从BigTable2中获取数据行,所以这里选择了嵌套循环,依次扫描BigTable2获取数据。
关于嵌套循环连接运算符,可以参照我的第二篇文章。
我们知道这是外表的循环数,也就是说这里会有4个线程并行执行嵌套循环。如果每个线程均分25行,数据那么内部表就要执行
4*25=100次。
然后,执行完,嵌套扫描获取结果后,下一步就是,将各个线程执行的结果通过并行运算符汇总,然后输出
上述过程就是一个并行嵌套循环的执行流程。充分利用了四核的硬件资源。
参考文献
微软联机丛书逻辑运算符和物理运算符引用
参照书籍《SQL.Server.2005.技术内幕》系列
结语
此篇文章先到此吧,文章短一点,便于理解掌握,后续关于并行操作还有一部分内容,后续文章补充吧,本篇主要介绍了查询计划中的并行运算符,下一篇我们接着补充一部分SQL Server中的并行运算,然后分析下我们日常所写的增删改这些操作符的优化项,有兴趣可提前关注,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。
有问题可以留言或者私信,随时恭候有兴趣的童鞋加入SQL SERVER的深入研究。共同学习,一起进步。
SQL Server调优(并行运算总结篇二)
前言
上一篇文章我们介绍了查看查询计划的并行运行方式。
本篇我们接着分析SQL Server的并行运算。
闲言少叙,直接进入本篇的正题。
技术准备
同前几篇一样,基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
内容
文章开始前,我们先来回顾上一篇中介绍的并行运算,来看文章最后介绍的并行运算语句:
SELECT B1.[KEY],B1.DATA,B2.DATA
FROM BigTable B1 JOIN BigTable2 B2
ON B1.[KEY]=B2.[KEY]
WHERE B1.DATA<100
上面是详细的执行计划,从右边依次向左执行,上图中有一个地方很有意思,就是在聚集索引扫描后获取的数据,又重新了使用了一次重新分配任务的过程
(Repartition Streams),就是上图的将获取的100行数据重新分配到并行的各个线程中。
其实这里本可以直接将索引扫描出来的100行数据直接扔到嵌套循环中执行。它这里又重新分配任务的目的就是为了后面嵌套循环的并行执行,最大限度的利用硬件资源!
但这样做又带了另一个弊端就是执行完嵌套循环之后,需要将结果重新汇总,就是下面的(Gather Sreams)运算符。
我们来看看该语句如果不并行的执行计划
SELECT B1.[KEY],B1.DATA,B2.DATA
FROM BigTable B1 JOIN BigTable2 B2
ON B1.[KEY]=B2.[KEY]
WHERE B1.DATA<100
option(maxdop 1)
这才是正宗的串行执行计划。
和上面的并行执行计划相比较,你会发现SQL Server充分利用硬件资源而形成的并行计划,是不是很帅!
如果还没感觉到SQL Server并行执行计划的魅力,我们再来举个例子,看如下语句
SELECT BIG_TOP.[KEY],BIG_TOP.DATA,B2.DATA
FROM
(
SELECT TOP 100 B.[KEY],B.DATA
FROM BigTable B
ORDER BY DATA
) BIG_TOP,
BigTable2 B2
WHERE BIG_TOP.[KEY]=B2.[KEY]
先来分析下上面的语句,这个语句我们在外表中加入了TOP 100.....ORDER BY DATA关键字,这个关键字是很有意思....
因为我们知道这个语句是获取根据DATA关键字排序,然后获取出前100行的意思...
1、根据DATA排序.....丫的多线程我看你怎么排序?每个线程排列自己的?那你排列完了在汇聚在一起...那岂不是还得重新排序!!
2、获取前100行数据,丫多线程怎么获取?假如我4个线程扫描每个线程获取25条数据?这样出来的结果对嘛?
3、我们的目标是让外表和上面的100行数据还要并行嵌套循环连接,因为这样才能充分利用资源,这个怎么实现呢?
上面的这些问题,我们来看强大的SQL Server将为我们怎样生成强悍的执行计划
上面的执行计划已经解决了我们以上所述的三个问题,我们依次来分析下,这几个问题的解决方法
第一个问题,关于并列排序问题
首选根据聚集索引扫描的方式采用并列的方式从表中获取出数据
然后,在并行的根据各个线程中的数据进行排序,获取前几列值,我们知道,我们的目标获取的是前100行,它这里获取的方式是冗余获取,也就是说每个线程各自排序自己的数据
然后获取出前面的数据,通过循环赛的方式进行交换,获取出一部分数据
第二个问题,关于并列获取前100行数据问题
我们知道要想获取前100行数据,就必须将各个线程的数据汇总到一起,然后通过比较获取前100行数据,这是必须的,于是在这一步里SQL Server又的重新将数据汇总到一起
第三个问题,下一步需要将这100行数据和外表进行连接,获取出结果,这里面采用的嵌套循环连接的方式,为了充分利用资源,提升性能,SQL Server又不得不将这100行数据均分到各个线程中去执行,所以这里又采用了一个拆分任务的运算符分发流(Distribute Sreams)任务
所以经过此步骤又将系统的硬件资源充分利用起来了,然后下一步同样就是讲过嵌套循环进行关联获取结果,然后再重新将结果汇总,然后输出
我们可以看到上面的一个流程,SQLServer经过了:先拆分(并行扫描)——》再并行(获取TOP 100....)——》再拆分(为了并行嵌套循环)——》再并行(为了合并结果)
总之,SQL Server在运行语句的时候,经过各种评估之后,利用各种拆分、各种汇总,目的就是充分的利用硬件资源,达到一个性能最优化的方式!这就是SQL Server并行运算的精髓。
当然凡事有利就有弊,我们通过这条语句来对比一下串行和并行在SQL Server中的优劣项
一下是串行执行计划:
SELECT BIG_TOP.[KEY],BIG_TOP.DATA,B2.DATA
FROM
(
SELECT TOP 100 B.[KEY],B.DATA
FROM BigTable B
ORDER BY DATA
) BIG_TOP,
BigTable2 B2
WHERE BIG_TOP.[KEY]=B2.[KEY]
option(maxdop 1)
串行执行的执行计划:简单、大气、没有复杂的各种拆分、各种汇总及并行。
我们来比较下两者的不同项,先比较一个T-SQL语句的各个参数值:
前者是串行、后者是并行
串行编译耗费CPU:2、并行编译耗费CPU:10
串行编译耗费内存:184、并行编译耗费内存:208
串行编译耗时:2、并行编译耗时:81
上面是采取并行的缺点:1、更消耗CPU、2、编译更消耗内存、3、编译时间更久
我们来看一下并行的优点:
上图中串行内存使用(1024),并行内存(448)
优点就是:并行执行消耗内存更小
当然还有一个更重要的优点:执行速度更快!
采用并行的执行方式,执行时间从218毫秒提升到187毫秒!数据量少,我机器性能差所以提升不明显!
在并行运算执行过程中,还有一种运算符经常遇到:位图运算符,这里我们顺带也介绍一下
举个例子:
SELECT B1.[KEY],B1.DATA,B2.[KEY]
FROM BigTable B1 JOIN BigTable2 B2
ON B1.DATA=B2.DATA
WHERE B1.[KEY]<10000
这里我们获取大表中Key列小于10000行的数据。
上述的执行语句,就引入了位图计算。
其实位图计算的目标很简单:提前过滤,因为我们的语句中要求获取的结果项比较多10000行数据,在我们后面的线程中采用的并行扫描的方式获取出数据。由于数据量比较多的原因,各个线程在执行的过程中获取完数据的时间不同,为了避免因某个线程执行速度缓慢,导致整体堵塞,索引引入了位图运算,先将获取出来的部分结果过滤输出到前面的哈希匹配,完整执行。
关于位图运算符更多详细可参照:http://msdn.microsoft.com/zh-cn/library/bb510541
结语
此篇文章先到此吧,本篇主要是上一篇并行运算的一个延续,两篇文章介绍了SQL Server中关于并行运算的原理和使用方式,关于并行运算这块就到这吧,下一篇我们补充SQL Server中关于索引的利用方式和动态索引的内容,关于索引我相信很多了解数据库产品的人都熟悉,但是SQL Server中一些语句利用索引的方式可能还不清楚,我们下一篇分析这块,借此了解索引的建立方式和优化技巧,有兴趣可提前关注,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。
SQL Server调优(索引运算总结)
前言
上几篇文章我们介绍了如何查看查询计划、常用运算符的介绍、并行运算的方式,有兴趣的可以点击查看。
本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方式可以指导我们如何建立索引、调整我们的查询语句,达到性能优化的目的。
闲言少叙,进入本篇的正题。
技术准备
基于SQL Server2008R2版本,利用微软的一个更简洁的案例库(Northwind)进行解析。
简介
所谓的索引应用就是在我们日常写的T-SQL语句中,如何利用现有的索引项,再分析的话就是我们所写的查询条件,其实大部分情况也无非以下几种:
1、等于谓词:select ...where...column=@parameter
2、比较谓词:select ...where...column> or < or <> or <= or >= @parameter
3、范围谓词:select ...where...column in or not in or between and @parameter
4、逻辑谓词:select ...where...一个谓词 or、and 其它谓词 or、and 更多谓词....
我们就依次分析上面几种情况下,如何利用索引进行查询优化的
一、动态索引查找
所谓的动态索引查找就是SQL Server在执行语句的时候,才格式化查询条件,然后根据查询条件的不同自动的去匹配索引项,达到性能提升的目的。
来举个例子
SET SHOWPLAN_TEXT ON
GO
SELECT OrderID
FROM Orders
WHERE ShipPostalCode IN (N'05022',N'99362')
因为我们在表Orders的列ShipPostalCode列中建立了非聚集索引列,所以这里查询的计划利用了索引查找的方式。这也是需要建立索引的地方。
我们来利用文本的方式来查看该语句的详细的执行计划脚本,语句比较长,我用记事本换行,格式化查看
我们知道这张表的该列里存在一个非聚集索引,所以在查询的时候要尽量使用,如果通过索引扫描的方式消耗就比价大了,所以SQL Server尽量想采取索引查找的方式,其实IN关键字和OR关键字逻辑是一样的。
于是上面的查询条件就转换成了:
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'05022'
OR
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'99362'
这样就可以采用索引查找了,先查找第一个结果,然后再查找第二个,而这个过程在SQL Server中就被称为:动态索引查找。
是不是有点智能的感觉了....
所以有时候我们写语句的时候,尽量要使用SQL Server的这点智能了,让其能自动的查找到索引,提升性能。
有时候偏偏我们写的语句让SQL Server的智能消失,举个例子:
--参数化查询条件
DECLARE @Parameter1 NVARCHAR(20),@Parameter2 NVARCHAR(20)
SELECT @Parameter1=N'05022',@Parameter2=N'99362'
SELECT OrderID
FROM Orders
WHERE ShipPostalCode IN (@Parameter1,@Parameter2)
我们将这两个静态的筛序值改成参数,有时候我们写的存储过程灰常喜欢这么做!我们来看这种方式的生成的查询计划
本来很简单的一个非聚集索引查找搞定的执行计划,我们只是将这两个数值没有直接写入IN关键字中,而是利用了两个变量来代替。
看看上面SQL Server生成的查询计划!尼玛...这都是些啥???还用起来嵌套循环,我就查询了一个Orders表...你嵌套循环个啥....上面动态索引查找的能力去哪了???
好吧,我们用文本查询计划来查看下,这个简单的语句到底在干些啥...
|--Nested Loops(Inner Join, OUTER REFERENCES:([Expr1009], [Expr1010], [Expr1011]))
|--Merge Interval
| |--Sort(TOP 2, ORDER BY:([Expr1012] DESC, [Expr1013] ASC, [Expr1009] ASC, [Expr1014] DESC))
| |--Compute Scalar(DEFINE:([Expr1012]=((4)&[Expr1011]) = (4) AND NULL = [Expr1009], [Expr1013]=(4)&[Expr1011], [Expr1014]=(16)&[Expr1011]))
| |--Concatenation
| |--Compute Scalar(DEFINE:([Expr1004]=[@Parameter2], [Expr1005]=[@Parameter2], [Expr1003]=(62)))
| | |--Constant Scan
| |--Compute Scalar(DEFINE:([Expr1007]=[@Parameter1], [Expr1008]=[@Parameter1], [Expr1006]=(62)))
| |--Constant Scan
|--Index Seek(OBJECT:([Northwind].[dbo].[Orders].[ShipPostalCode]), SEEK:([Northwind].[dbo].[Orders].[ShipPostalCode] > [Expr1009] AND [Northwind].[dbo].[Orders].[ShipPostalCode] < [Expr1010]) ORDERED FORWARD)
挺复杂的是吧,其实我分析了一下脚本,关于为什么会生成这个计划脚本的原因,是为了解决如下几个问题:
1、前面我们写的脚本在IN里面写的是两个常量值,并且是不同的值,所以形成了两个索引值的查找通过OR关键字组合,
这种方式貌似没问题,但是我们将这两个数值变成了参数,这就引来了新的问题,假如这两个参数我们输入的是相等的,那么利用前面的执行计划就会生成如下
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'05022'
OR
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'05022'
这样执行产生的输出结果就是2条一样的输出值!...但是表里面确实只有1条数据...所以这样输出结果不正确!
所以变成参数后首先解决的问题就是去重问题,2个一样的变成1个。
2、上面变成参数,还引入了另外一个问题,加入我们两个值有一个传入的为Null值,或者两个都为Null值,同样输出结果面临着这样的问题。所以这里还要解决的去Null值的问题。
为了解决上面的问题,我们来粗略的分析一下执行计划,看SQL Server如何解决这个问题的
简单点将就是通过扫描变量中的值,然后将内容进行汇总值,然后在进行排序,再将参数中的重复值去掉,这样获取的值就是一个正确的值,最后拿这些去重后的参数值参与到嵌套循环中,和表Orders进行索引查找。
但是分析的过程中,有一个问题我也没看明白,就是最好的经过去重之后的常量汇总值,用来嵌套循环连接的时候,在下面的索引查找的时候的过滤条件变成了 and 查找
我将上面的最后的索引查找条件,整理如下:
|--Index Seek(OBJECT:([Northwind].[dbo].[Orders].[ShipPostalCode]), SEEK:
(
[Northwind].[dbo].[Orders].[ShipPostalCode] > [Expr1009]
AND
[Northwind].[dbo].[Orders].[ShipPostalCode] < [Expr1010]
) ORDERED FORWARD)
这个地方怎么搞的?我也没弄清楚,还望有看明白童鞋的稍加指导下....
好了,我们继续
上面的执行计划中,提到了一个新的运算符:合并间隔(merge interval operator)
我们来分析下这个运算符的作用,其实在上面我们已经在执行计划的图中标示出该运算符的作用了,去掉重复值。
其实关于去重的操作有很多的,比如前面文章中我们提到的各种去重操作。
这里怎么又冒出个合并间隔去重?其实原因很简单,因为我们在使用这个运算符之前已经对结果进行了排序操作,排序后的结果项重复值是紧紧靠在一起的,所以就引入了合并间隔的方式去处理,这样性能是最好的。
更重要的是合并间隔这种运算符应用场景不仅仅局限于重复值的去除,更重要的是还应用于重复区间的去除。
来看下面的例子
--参数化查询条件
DECLARE @Parameter1 DATETIME,@Parameter2 DATETIME
SELECT @Parameter1='1998-01-01',@Parameter2='1998-01-04'
SELECT OrderID
FROM ORDERS
WHERE OrderDate BETWEEN @Parameter1 AND DATEADD(DAY,6,@Parameter1)
OR OrderDate BETWEEN @Parameter2 AND DATEADD(DAY,6,@Parameter2)
我们看看这个生成的查询计划项
可以看到,SQL Server为我们生成的查询计划,和前面我们写的语句是一模一样的,当然我们的语句也没做多少改动,改动的地方就是查询条件上。
我们来分析下这个查询条件:
WHERE OrderDate BETWEEN @Parameter1 AND DATEADD(DAY,6,@Parameter1)
OR OrderDate BETWEEN @Parameter2 AND DATEADD(DAY,6,@Parameter2)
很简单的筛选条件,要获取订单日期在1998-01-01开始到1998-01-07内的值或者1998-01-04开始到1998-01-10内的值(不包含开始日期)
这里用的逻辑谓词为:OR...其实也就等同于我们前面写的IN
但是我们这里再分析一下,你会发现这两个时间段是重叠的
这个重复的区间值,如果用到前面的直接索引查找,在这段区间之内的搜索出来的范围值就是重复的,所以为了避免这种问题,SQL Server又引入了“合并间隔”这个运算符。
其实,经过上面的分析,我们已经分析出这种动态索引查找的优缺点了,有时候我们为了避免这种复杂的执行计划生成,使用最简单的方式就是直接传值进入语句中(当然这里需要重编译),当然大部分的情况我们写的程序都是只定义的参数,然后进行的运算。可能带来的麻烦就是上面的问题,当然有时候参数多了,为了合并间隔所应用的排序就消耗的内存就会增长。怎么使用,根据场景自己酌情分析。
二、索引联合
所谓的索引联合,就是根据就是根据筛选条件的不同,拆分成不同的条件,去匹配不同的索引项。
举个例子
SELECT OrderID
FROM ORDERS
WHERE OrderDate BETWEEN '1998-01-01' AND '1998-01-07'
OR ShippedDate BETWEEN '1998-01-01' AND '1998-01-07'
这段代码是查询出订单中的订单日期在1998年1月1日到1998年1月7日的或者发货日期同样在1998年1月1日到1998年1月7日的。
逻辑很简单,我们知道在这种表里面这两个字段都有索引项。所以这个查询在SQL Server中就有了两个选择:
1、一次性的来个索引扫描根据匹配结果项输出,这样简单有效,但是如果订单表数据量比较大的话,性能就会很差,因为大部分数据就根本不是我们想要的,还要浪费时间去扫描。
2、就是通过两列的索引字段直接查找获取这部分数据,这样可以直接减少数据表的扫描量,但是带来的问题就是,如果分开扫描,有一部分数据就是重复的:那些同时在1998年1月1日到1998年1月7日的订单,发货日期也在这段时间内,因为两个扫描项都包含,所以再输出的时候需要将这部分重复数据去掉。
我们来看SQL Server如何选择
看来SQL Server经过评估选择了第2中方法。但是上面的方法也不尽完美,采用去重操作耗费了64%的资源。
其实,上面的方法,我们根据生成的查询计划可以变通的使用以下逻辑,其效果和上面的语句是一样的,并且生成的查询计划也一样
SELECT OrderID
FROM ORDERS
WHERE OrderDate BETWEEN '1998-01-01' AND '1998-01-07'
UNION
SELECT OrderID
FROM ORDERS
WHERE ShippedDate BETWEEN '1998-01-01' AND '1998-01-07'
我们再来看一个索引联合的例子
SELECT OrderID
FROM ORDERS
WHERE OrderDate = '1998-01-01'
OR ShippedDate = '1998-01-01'
我们将上面的Between and不等式筛选条件改成等式筛选条件,我们来看一下这样形成的执行计划
基本相同的语句,只是我们改变了不同的查询条件,但是生成的查询计划还是变化蛮大的,有几点不同之处:
1、前面的用between...and 的筛选条件,通过索引查找返回的值进行组合是用的串联的方式,所谓的串联就是两个数据集拼凑在一起就行,无所谓顺序连接什么的。
2、前面的用between...and 的筛选条件,通过串联拼凑的结果集去重的方式,是排序去重(Sort Distinct)...并且耗费了大量的资源。这里采用了流聚合来干这个事,基本不消耗
我们来分析以下产生着两点不同的原因有哪些:
首先、这里改变了筛选条件为等式连接,所通过索引查找所产生的结果项是排序的,并且按照我们所要查询的OrderID列排序,因此在两个数据集进行汇总的时候,正适合合并连接的条件!需要提前排序。所以这里最优的方式就是采用合并连接!
那么前面我们用between...and 的筛选条件通过索引查找获取的结果项也是排序的,但是这里它没有按照OrderID排序,它是按照OrderDate或者ShippedDate列排序的,而我们的结果是要OrderID列,所以这里的排序是没用的......所以SQL Server只能选择一个串联操作,将结果汇聚到一起,然后在排序了......我希望这里我已经讲明白了...
其次、关于去重操作,毫无疑问采用流聚合(Aggregate)这种方式最好,消耗内存少,速度又快...但是前提是要提前排序...前面选用的排序去重(Sort Distinct)纯属无奈之举...
总结下:我们在写语句的时候能确定为等式连接,最好采用等式连接。还有就是如果能确定输出条件的最好能写入,避免多余的书签查找,还有万恶的SELEECT *....
如果写了万恶的SELECT *...那么你所写的语句基本上就可以和非聚集索引查找告别了....顶多就是聚集索引扫描或者RID查找...
瞅瞅以下语句
SELECT *
FROM ORDERS
WHERE OrderDate = '1998-01-01'
OR ShippedDate = '1998-01-01'
最后,奉上一个AND的一个连接谓词的操作方式,这个方式被称为:索引交叉,意思就是说如果两个或多个筛选条件如果采用的索引是交叉进行的,那么使用一个就可以进行查询。
来看个语句就明白了
SELECT OrderID
FROM ORDERS
WHERE OrderDate = '1998-01-01'
AND ShippedDate = '1998-03-05'
这里我们采用了的谓词连接方式为AND,所以在实际执行的时候,虽然两列都存在非聚集索引,理论都可以使用,但是我们只要选一个最优的索引进行查找,另外一个直接使用书签查找出来就可以。省去了前面介绍的各种神马排序去重....流聚合去重....等等不人性的操作。
看来AND连接符是一个很帅的运算符...所以很多时候我们在尝试写OR的情况下,不如换个思路改用AND更高效。
参考文献
微软联机丛书逻辑运算符和物理运算符引用
参照书籍《SQL.Server.2005.技术内幕》系列
结语
此篇文章主要介绍了索引运算的一些方式,主要是描述了我们平常在写语句的时候所应用的方式,并且举了几个例子,算作抛砖引玉吧,其实我们平常所写的语句中无非也就本篇文章中介绍的各种方式的更改,拼凑。而且根据此,我们该怎样建立索引也作为一个指导项。
下一篇我们介绍子查询一系列的内容,有兴趣可提前关注,关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。
SQL Server调优(子查询运算总结)
前言
前面我们的几篇文章介绍了一系列关于运算符的介绍,以及各个运算符的优化方式和技巧。其中涵盖:查看执行计划的方式、几种数据集常用的连接方式、联合运算符方式、并行运算符等一系列的我们常见的运算符。有兴趣的童鞋可以点击查看。
本篇我们介绍关于子查询语句的一系列内容,子查询一般是我们形成复杂查询的一些基础性操作,所以关于子查询的应用方式就非常重要。
废话少说,开始本篇的正题。
技术准备
数据库版本为SQL Server2008R2,利用微软的一个更简洁的案例库(Northwind)进行分析。
一、独立的子查询方式
所谓的独立的子查询方式,就是说子查询和主查询没有相关性,这样带来的好处就是子查询不依赖于外部查询,所以可以独立外部查询而被评估,形成自己的执行计划执行。
举个例子
SELECT O1.OrderID,O1.Freight
FROM Orders O1
WHERE O1.Freight>
(
SELECT AVG(O2.Freight)
FROM Orders O2
)
这句SQL执行的目标是查询订单中运费大于平均运费数的订单。
这里提取平均运费的子句就是一个完全独立的子查询,完全不依赖主查询而独立执行。同时这里我们这里利用利用一个标量计算(AVG),因此正好返回一行。
查看一下该语句的查询计划:
这个查询计划没啥好介绍的,关于子查询的执行计划形成可以参照我的第二篇:SQL Server调优系列基础篇(常用运算符总结)
不过这里需要提示一下就是,关于流聚合和计算标量形成的结果值(AVG)只包含一个结果值,所以该语句能正常的执行。
我们再来看另外一种情况
SELECT O.OrderID
FROM Orders O
WHERE O.CustomerID=
(
SELECT C.CustomerID
FROM Customers C
WHERE C.ContactName=N'Maria Anders'
)
该语句的也是获取名字为'Maria Anders'的顾客有多少订单。这句T-SQL语句能否执行的前提是在顾客表里存不存在同名的“'Maria Anders'”顾客,如果存在同名情况,该语句就不能正确执行,而如果恰巧只有一名顾客为'Maria Anders',则能正常执行。
我们来分析一下对于这种执行的时候才能判断能否正确执行的SQL Server如何判断的
在这里出现了一个新的运算符,名字是:断言。我们用文本执行计划来查看一下,这个运算符的主要功能是什么
经过上面的分析,我们已经分析出了上面的“断言”运算符的作用,因为我们的子查询语句不能保证返回的结果为一行,所以,这里引入了一个断言运算符来做判断。
所以,断言的作用就是根据下文的条件,判断子查询句的查询结果是否满足主语句的查询要求。
如果,断言发现子语句不满足,就会直接报错,比如上面的Expr1005>1
并且,断言运算符还经常用来检测其它条件是否满足,比如:约束条件、参数类型、值长度等。
其实,这里断言要解决的问题就是判断我们的筛选条件中ContactName中的值是否存在重复值的,对于这种判断相对性能消耗还是比较小的,有时候对于别的复杂的断言操作需要消耗大量资源,所以我们就可以根据适当情况情况避免断言操作。
比如,上面的语句我们可以明确的告诉SQL Server在表Customers中ContactName列就不存在重复值,它就不需要断言了。我们在上面建立一个:唯一、非聚集索引实现
CREATE UNIQUE INDEX ContactNameIndex ON Customers(ContactName)
GO
SELECT O.OrderID
FROM Orders O
WHERE O.CustomerID=
(
SELECT C.CustomerID
FROM Customers C
WHERE C.ContactName=N'Maria Anders'
)
drop index Customers.ContactNameIndex
GO
经过我们唯一非聚集索引的提示,SQL Server已经明确的知道我们的子查询语句不会返回多行的情况,所以就去掉了断言操作。
二、相关的子查询方式
相比上面的独立子查询方式,这里的相关的子查询方式相对复杂点,就是我们的子查询依赖于主查询的的结果,对于这种子查询就不能单独执行。
我们来看个这样的子查询例子
SELECT O1.OrderID
FROM Orders O1
WHERE O1.Freight>
(
SELECT AVG(O2.Freight)
FROM Orders O2
WHERE O2.OrderDate<O1.OrderDate
)
这个语句就是返回之前订单中运费量大于平均值的顶点编号。
语句很简单的逻辑,但是这里面的子查询就依赖于主查询的结果项,筛选条件中 WHERE O2.OrderDate<O1.OrderDate,所以这个子查询就不能独立运行。
我们来看一下这个语句的执行计划
这里的查询计划有出现了一个新的运算符:索引假脱机。
其实,关于索引假脱机的作用主要是用于子查询的独立运行,因为我们知道这里的子查询的查询条件是依赖于主查询的,所以,这里想运行的话就的先提前获取出主查询的结果项,而这里获取的主查询的结果项需要一个中间表来暂存,这里暂存的工具就是:(索引池)Index Spool,而对这个索引池的操作,比如:新建、增加等操作就是上面我们所标示的“索引假脱机”了。
索引假脱机分为两种:Eager Spool和Lazy Spool,其实简单点讲就是需不需要立刻将结果存入Index Spool里面,还是通过延迟操作。
而这里形成的索引池(Index Spool)是存放于系统的临时库Tempdb中。
我们通过文本查询计划,来分析下两个索引假脱机里面的值是什么
经过上面的分析,我们已经看到了,里面的Eager Spool是和主查询比较形成的结果值,因为这个必须要及时的形成,以便于子查询的进行,所以它的类型为Eager Spool,
而子查询外面的那个Index Spool为Lazy Spool,这个结果项的保存不需要那么及时了,这个保存的就是子查询的形成的结果项了,就是相对每个订单运费的平均值。
我上面的分析,希望各位看官能看懂了。
其实,关于这个Index Spool的设计的目的,完全为了就是提升性能,因为我们知道上面的查询语句每个子查询的进行,都必须回调主查询的结果,所以为了避免每次都回调,就采用了Index Spool进行暂存,而这个Index Spool存储的位置就是Tempdb,所以Tempdb运行的快慢直接关乎这种查询语句的性能。
这也是我们为什么强调大并发的数据库搭建,建议将Tempdb库单独存放于高性能的硬件环境中。
晒晒联机丛书中关于假脱机数据运算符官方介绍:
Index Spool 物理运算符在 Argument 列中包含 SEEK:() 谓词。Index Spool 运算符扫描其输入行,将每行的副本放置在隐藏的假脱机文件(存储在 tempdb 数据库中且只在查询的生存期内存在)中,并为这些行创建非聚集索引。这样可以使用索引的查找功能来仅输出那些满足 SEEK:() 谓词的行。
如果重绕该运算符(例如通过 Nested Loops 运算符重绕),但不需要任何重新绑定,则将使用假脱机数据,而不用重新扫描输入。
跟索引脱机类似的还有一个相似的运算符:表脱机,其功能类似,表脱机存储的应该是键值列,而表脱机则是存储的是多列数据了。
来看例子
SELECT O1.OrderID,O1.Freight
FROM Orders O1
WHERE O1.Freight>
(
SELECT AVG(O2.Freight)
FROM Orders O2
WHERE O2.CustomerID=O1.CustomerID
)
这个查询和上面的类似,只不过是查询的同一个客户加入的超过所有订单运费平均值的订单。
此语句同样不是独立的子查询语句,每个子查询的结果的形成都需要依赖主查询的结果项,为了加快速度,提升性能,SQL Server会将主表查询的的结果项暂存到一张临时表中,这个表就被称为表脱机
我们来看这句话的执行计划:
这里就用到了一个表脱机的运算符,这个运算符的作用就是用来暂存后面扫描获取的结果集合,用于下面的子查询的应用
这个表脱机形成的结果项也是存储到临时库Tempdb中,所以它的应用和前面提到的索引脱机类似。
上面的执行计划中,还提到了一个新的运算符:段(Segment)
这个运算符的解释是:
Segment 既是一个物理运算符,也是一个逻辑运算符。它基于一个或多个列的值将输入集划分成多个段。这些列显示为 Segment 运算符中的参数。然后运算符每次输出一个段。
其实作用就是将结果进行汇总整理,将相同值汇聚到一起,跟排序一样,只不过这里可以对多列值进行汇聚。
我们再来看一个例子,加深 一下关于段运算的作用
SELECT CustomerID,O1.OrderID,O1.Freight
FROM Orders O1
WHERE O1.Freight=
(
SELECT MAX(O2.Freight)
FROM Orders O2
WHERE O2.CustomerID=O1.CustomerID
)
这个语句查询的是:每个顾客所产生的最大运费的订单数据。
以上语句,如果理解起来有难度,我们可以变通以下的相同逻辑的T-SQL语句,相同的逻辑
SELECT O1.CustomerID,O1.OrderID,O1.Freight
FROM Orders O1
INNER JOIN
(
SELECT CustomerID,max(Freight) Freight
FROM Orders
GROUP BY CustomerID
) AS O2
ON O1.CustomerID=O2.CustomerID
AND O1.Freight=O2.Freight
先根据客户编号分组,然后获取出最大的运费项,再关联主表获取订单信息。
以上两种语句生成的相同的查询计划:
这里我们来解释一下,SQL Server的强大之处,也是段运算符使用的最佳方式。
本来这句话要实现,按照逻辑需要有一个嵌套循环连接,参照上面的方式,使用表脱机的方式进行数据的获取。
但是,我们这句话获取的结果项是每个顾客的最大运费的订单明细项,而且CustomerID列作为输出项,所以这里采用了,先按照运费列(Freight)排序,
然后采用段运算符进行将每个顾客相同的数据汇聚到一起,然后再输出每个顾客的前一列(TOP 1)获取的就是最每个顾客的运费最大的订单项。
省去了任何的表假脱机、索引假脱机、关联连接等一系列复杂的操作。
SQL Server看来这种智能化的操作还是挺强的。
我们再来分析SQL Server关于子查询这块的智能特性,因为经过上面的分析通过对比,相关的子查询语句在运行时需要更多的消耗:
1、有时候需要通过索引假脱机(Index Spool)、表脱机(Table Spool)进行中间结果项的暂存,而这一过程的中间项需要创建、增加、删除、销毁等操作都需要消耗大量的内存和CPU
2、关于相关子查询中以上提到的中间项的形成都是位于Tempdb临时库中,有时候会增大Tempdb的空间,增加Tempdb库的消耗、页争用等问题。
所以,要避免上面的问题,最好的方式是避免使用相关子查询,尽量使用独立子查询进行操作。
当然,SQL Server同样提供了自动转换的功能,智能的去分析语句,避免相关的子查询操作进行:
来看一个稍差的写法:
SELECT o.OrderID
FROM Orders O
WHERE EXISTS
(
SELECT c.CustomerID
FROM Customers C
WHERE C.City=N'Londom' AND C.CustomerID=O.CustomerID
)
上面的语句,我们写的是相关的子查询操作,但是在执行计划中形成的确实独立的子查询,这样从而避免相关的子查询所带来的性能消耗。
其实上面语句,相对好的写法是如下
SELECT o.OrderID
FROM Orders O
WHERE O.CustomerID IN
(
SELECT c.CustomerID
FROM Customers C
WHERE C.City=N'Londom'
)
这样所形成的就是完全独立的子查询,这也是SQL Server要执行的意图。所以这个语句形成的查询计划是和上面的查询计划一样。
这里的优化全部得益于SQL Server的智能化。
但是我们在写语句的时候,需要自己了解,掌握好,这样才能写出高效的T-SQL语句。
参考文献
微软联机丛书逻辑运算符和物理运算符引用
参照书籍《SQL.Server.2005.技术内幕》系列
结语
本篇篇幅有点长,但是介绍的子查询内容也还不是很全,后续慢慢的补充上,我们写的SQL语句中很多都涉及到子查询,所以这块应用还是挺普遍的。到本篇文章关于日常调优的T-SQL中的查询语句经常用到的一些运算符基本介绍全了,当然,还有一些别的增删改一系列的运算符,这些日常生活中我们一般不采用查询计划调优,后续我们的文章会将这些运算符也添加上,以供参考之用。
在完成本系列关于查询计划相关的调优之后,我打算将数据库有关统计信息这块也做一个详细的分析介绍。因为统计信息是支撑SQL Server评估最优执行计划的最重要的决策点,
所以统计信息的重要性不言而喻。有兴趣的童鞋可以提前关注。
关于SQL Server性能调优的内容涉及面很广,后续文章中依次展开分析。
SQL Server调优(查询优化器的运行方式)
前言
前面我们的几篇文章介绍了一系列关于运算符的基础介绍,以及各个运算符的优化方式和技巧。其中涵盖:查看执行计划的方式、几种数据集常用的连接方式、联合运算符方式、并行运算符等一系列的我们常见的运算符。有兴趣的童鞋可以点击查看。
本篇介绍在SQL Server中查询优化器的工作方式,也就是一个好的执行计划的形成,是如何评估出来的,作为该系列的进阶篇。
废话少说,开始本篇的正题。
技术准备
数据库版本为SQL Server2008R2,利用微软的一个更简洁的案例库(Northwind)进行分析。
正文内容
在我们将写好的一个T-SQL语句抛给SQL Server准备执行的时候,首选要经历的过程就是编译过程,当然如果此语句以前在SQL Server中执行过,那么将检测是否存在已经缓存的编译过的执行计划,用以重用。
但是,执行编译的过程需要执行一系列的优化过程,关于优化过程大致分为两个阶段:
1、首先,SQL Server对我们写的T-SQL语句先执行一些简化,通常由查询本身来寻找交互性及重新安排操作的顺序。
在此过程中,SQL Server侧重于语句写法调整,而不过多的考虑成本或者分析索引可用性的等,最重要的目标就是产生一个有效的查询。
然后,SQL Server才会加载元数据,包括索引的统计信息,进入第二个阶段。
2、在这个阶段才是SQL Server一个复杂的优化过程,这个阶段SQL Server会根据上一阶段形成的执行计划运算符进行评估和尝试,甚至于重组执行计划,所以相对这个优化过程是一个耗时的过程。
通过如下流程图,来理解该过程:
这个图看上去有点复杂,我们来详细分析下,其实就是将这个优化阶段分为3个子阶段
<1>这个阶段仅考虑串行计划,也就说单处理器运行,如果这个阶段找到了一个好的串行计划,优化器就不会进入下一阶段。所以对于数据量少的情况,或者执行语句简单的情况下,基本采用的都是串行计划。
当然,如果这个阶段开销比较大,那么会进入到第2个阶段,再进行优化。
<2>这个阶段首先对第1阶段的串行计划进行优化,然后如果环境支持并行化操作,则进行并行化操作,通过进行比较,然后进行优化后的成本如果比较低则输出执行计划,如果成本还是比较高,则进入第2阶段,再继续优化。
<3>其实到达这个阶段就是优化的最后一个阶段了,这个阶段会对第2个阶段中采用串行和并行的比较结果进行最后一步优化,如果串行执行好那就进一步优化,当然如果并行执行好的话,则再继续并行优化。
其实第3阶段是查询优化器的无奈之举,当到达第3阶段了就是一个补救阶段,只能最后做优化了,优化完好不好的就只能按照这个执行计划执行了。
那么上述过程中,各个阶段的优化的原则有哪些:
关于这些优化器的最重要原则的就是:尽可能的减少扫描范围,不管是表或者索引,当然走索引比表好,索引的量也是越少越好,最理想的情况是只有一条或者几条。
所以,SQL Server也尊重上述原则,一直围绕着这个原则去优化。
一、筛选条件分析
所谓的筛选条件,其实就是我们所写的T-SQL语句中的WHERE语句后面的条件,我们会通过这里面的语句进行尽量缩小数据扫描范围,SQL Server通过这些语句来优化。
一般格式如下:
column operator <constant or variable>
或者
<constant or variable> operator column
而这上面格式中operator包括:=、>、<、=>、<=、BETWEEN、LIKE
比如:name='liudehua'、price>4000、4000<price、name like 'liu%'、name='liudehua' AND price >1000
上面这些语句是我们写的语句中最常用的方式,并且这种方式也将被SQL Server用来减少扫描,并且这些列被索引覆盖,那将尽量采取索引进行获取值,但是SQL Server也不是万能的,有些写法它也是不能识别的,也是我们写语句要避免的:
a、where name like '%liu'这货就不能被SQL Server优化器识别,所以它只能通过全表扫描或者索引扫描执行。
b、name='liudehua' OR price >1000,这个同样也是失效的,因为它不能利用两个的筛选条件进行逐步减少扫描。
c、price+4>100这个同样不被识别
d、name not in ('liudehua'、‘zhourunfa’),当然还有类似的:NOT 、NOT LIKE
举个列子:
SELECT CustomerID FROM Orders
WHERE CustomerID='Vinet'
SELECT CustomerID FROM Orders
WHERE UPPER(CustomerID)='VINET'
所以上述的方式写语句的时候需要尽量避免,或者采取变通的方式实现。
二、索引优化
经过上面的筛选范围的确定之后,SQL Server紧接着开始索引的选择,首先要确定的第一件事就是筛选字段是否存在索引项,也就是说是否被索引覆盖。
当然,如果查询项为索引覆盖最好,如果不被索引覆盖,那么为了充分利用索引的特性,就引入了书签查找(bookmark)部分。
所以,鉴于此,我们在创建索引的时候,所参考的属性值就为筛选条件的列了。
关于利用索引优化的选择:
CREATE INDEX EmployeesName ON Employees(FirstName,LastName)
INCLUDE(HIREDATE) WITH(ONLINE=ON)
GO
SELECT FirstName,LastName,HireDate,EmployeeID
FROM Employees
WHERE FirstName='Anne'
当然也不尽然只要查询列存在索引覆盖就执行索引查找,这取决于扫描的内容的多少,所以对于索引的利用程度还取决获取内容的多少
来举个例子:
CREATE INDEX NameIndex ON person.contact(FirstName,LastName)
GO
SELECT * FROM Person.Contact
WHERE FirstName LIKE 'K%'
SELECT * FROM Person.Contact
WHERE FirstName LIKE 'Y%'
GO
完全相同的查询语句,来看执行计划:
完全相同的查询语句,产生的查询计划完全不同,一个是索引扫描,一个则是高效的索引查找。
这里我只告诉你:FirstName like 'K%'的有1255行;而FirstName like 'Y%'只有37行,其中
其实,关于这里的原因就是统计信息在作怪了。
所以,特定的T-SQL语句不一定生成特定的查询计划,同样特定的查询计划不一定是最优的方式,影响的它的因素很多:关于索引、关于硬件、关于表内容、关于统计信息等诸多因素影响。
关于统计信息这块是大篇幅内容,我们放在以后的篇幅中介绍,有兴趣的可以提前关注。
SQL Server调优(查询语句运行几个指标值监测)
前言
上一篇我们分析了查询优化器的工作方式,其中包括:查询优化器的详细运行步骤、筛选条件分析、索引项优化等信息。
本篇我们分析在我们运行的过程中几个关键指标值的检测。
通过这些指标值来分析语句的运行问题,并且分析其优化方式。
通过本篇我们可以学习到调优中经常利用的几个利器!
废话少说,开始本篇的正题。
技术准备
数据库版本为SQL Server2008R2,利用微软的一个更简洁的案例库(Northwind)进行分析。
利器一、IO统计
通过这个IO统计能为我们分析出当前查询语句所要扫描的数据页的数量。这里面有几个重要的概念,我们依次分析。
方法很简单,一行代码搞定:
SET STATISTICS IO ON
来看个例子
SET STATISTICS IO ON
GO
SELECT * FROM Person.Contact
这里可以看到这个语句对于数据表的操作次数,基于数据页的扫描项。
所谓的数据页就是数据库的底层数据存储方式,SQL Server以数据页的形式存储表行数据。每个数据页为8K,
8K=8192字节-96字节(页头)-36字节(行偏移)=8060字节
也就说一个数据页存储的纯数据内容为8060字节。
我们依次来解释上面出现几个读取的概念:
逻辑读
表示处理查询所需要访问页的总数。也就是说要完成一个查询语句需要读取的数据页的总数。
这里的数据页有可能来自内存,也有可能来自硬盘读取。
物理读
这个就是说来自硬盘读取的数据页数。我们知道SQL Server每次都会将读取的数据页尽可能存在于内存中,以方便下一次直接读取,提升读取速度。
所以在这里关于存储于内存中的数据页下次访问的概率,提出了一个指标:缓存命中率
缓存命中率=(逻辑读—物理读)/逻辑读
提出这个指标的提出其实就是为了衡量内存中缓存的数据页的有效性。比如:假如缓存与内存中的数据页就使用一次就不使用了,对于这种就应该及时从内存中清除掉,毕竟对于内存资源来说是非常昂贵的。应该用它来缓存命中率高的数据页。
预读
预读其实就是SQL语句在优化的时候预先读取到内存中的数据页数。这个预先读取的数据页是提前评估出来的,也就是上一篇我们文章中介绍的查询优化器要做的事情。
当然,这些预读的数据页有时候不是所有的都要用到,但是它基本能涵盖到查询用到的数据页。
这里要提示一下,预读数据是通过另外一个线程进行读取的和语句优化线程非用同一线程,并行运行,目的是快速获取数据,提升查询获取的速度。
从这个指标我们可以分析出很多问题,来举个例子:
我们新添加一张测试表,脚本如下
--执行下面脚本新生成一张表
SELECT *
INTO NewOrders
FROM Orders
GO--新增加一列
ALTER TABLE NewOrders
ADD Full_Details CHAR(2000) NOT NULL DEFAULT 'full details'
GO
然后利用如下脚本来看下这张表的大小
EXEC sp_spaceused NewOrders,TRUE
GO
我们可以看到这张表数据页的总大小为2216KB,我们知道一页为8KB,可以推断出这个表的数据页有:
2216(数据页总大小)/8(一个数据页大小)=277页
也就是说这个数据表有277个数据页。
当然,我们也可以通过如下DMV视图来查看该页的数据页数
SELECT *
FROM SYS.dm_db_index_physical_stats
(DB_ID('Northwind'),object_id('NewOrders'),NULL,NULL,'detailed')
经过上面的分析,
我们可以推测,在查询这张表做全表扫描的时候,理论的数据页的逻辑读数就应该为277次
通过如下语句验证下
--先清空缓存数据,生产机慎用
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
SELECT * FROM NewOrders
我去...
这里的逻辑读取为1047页,和我们上面的推断277页不相符...擦...神马原因!!!
这里就是我们要分析的数据页Forwarded record现象造成的。因为我们在新建立的表,在后面新添加的一列数据:Full_Details,类型为CHAR(2000)的数据列,当数据行中的变长列增长使得原有页无法容纳下数据行时,数据将会移动到新的页中,并在原位置留下一个指向新页的指针,这就是所谓的: Forwarded record
我们可以通过如下DMV视图,查看该表的Forwarded Record形成的页有多少
SELECT *
FROM SYS.dm_db_index_physical_stats
(DB_ID(N'Northwind'),object_id('NewOrders'),NULL,NULL,'detailed')
纠正一下:上图的770数据页为Forwarded Record页,非拆分页的概念(感谢院友 wy123 指出)。
看到了,这里的Forwarded Record页为770页,那么我们就可以推测出我们的逻辑读数量来了
277(原数据页)+770(Forwarded Record页)=1047页
所以上面的我们的问题就分析出原因了。
我们通过此表也展示了一个Forwarded Record页的问题:会影响查询性能。
解决的方式很多种,最简单的方式就是重建聚集索引。
CREATE CLUSTERED INDEX orderID_C ON NewOrders(OrderID)
GO
DROP INDEX NewOrders.orderID_C
GO
SET STATISTICS IO ON
SELECT * FROM NewOrders
GO
通过IO统计项,除了可以分析出上面的Forwarded Record页造成的碎片外,更重要的地方使用来对比不同查询语句之间的读取次数,通过降低读取的次数来优化语句。
关于预读的情况,我们在前面已经分析了,其数据时通过另外一个线程在T-SQL查询语句优化的时候进行数据的预加载。
所以这个线程在预读数据的时候其实是有一个参考值的,根据这个参考值读取出来的数据才能保证大部分数据是有用的,也就是提高上面提到的缓存命中率。
关于这个参考值,我分析了下,其实是分为两中情况分析的。
首先、如果是数据表为堆表,SQL Server获取的方式只能通过全表扫描了。而此方式为了避免重复读取,增加消耗,所以一次的预读并非读取一个数据页,
而是一段物理上的连续64个页
来看联机丛书的官方解释:
预读机制允许数据库引擎从一个文件中读取最多 64 个连续页 (512KB)。该读取作为缓冲区高速缓存中相应数量(可能是非相邻的)缓冲区的一次散播-聚集读取来执行。如果此范围内的任何页在缓冲区高速缓存中已存在,当读取完成时,所读取的相应页将被放弃。如果相应页在缓存中已存在,也可以从任何一端“裁剪”页的范围。
所以,如果我们的表在物理上不是连续页,那么读取次数就不好怎么确定了。
我们来看个堆表的例子
SET STATISTICS IO ON--新建个测试表
SELECT * INTO NewOrders_TEST FROM NewOrders
SELECT * FROM NewOrders_TEST
这里预读的次数为8次,所以我估计底层的数据页肯定不是连续的。所以造成了多出了3次。
我们可以DBCC IND()进行查询下,来验证下我的推断。
DBCC IND('Northwind','NewOrders_TEST',1)
数据信息比较多,我将其粘贴到Excel中,然后做了一个折线图,其中涂掉的部分其实是没有数据页的,所以不会产生一次读取。
关于读取顺序标示的也有点问题,不过确定的总数肯定是8次.....
希望这种方式,各位看官能看懂了...希望我也表述明白了。
其次、如果表非堆表,也就是说存在聚集索引项,那么好了,SQL Server很轻松的找到了它预读的参考依据:统计信息。
并且,我们知道数据以B-Tree数存储,读取的数据页都存在与叶子节点。所以基本没有了什么连续读取的感念。
一个叶子节点就是一个数据页,一个数据页就是一次预读。
来看个例子:
我们将上面的表添加上聚集索引项,再一次清空缓存,执行查询,脚本如下
CREATE CLUSTERED INDEX NewOrders_TESTIndex ON NewOrders_TEST(OrderID)
GO
SELECT * FROM NewOrders_TEST
这里添加了聚集索引,SQL Server仿佛一下看到了救星,根据统计信息,预读数据就可以。
所以如果统计信息有错误,就造成了预读的乱读取....然后严重降低了缓存命中率.....然后严重增加了内存中换出换入的速度....增加了CPU....
好了,咱们继续文章,上面我们提到的这个预读数据行,可以在如下DMV中查到。
SELECT *
FROM SYS.dm_db_index_physical_stats
(DB_ID(N'Northwind'),object_id('NewOrders_TEST'),NULL,NULL,'detailed')
从这个DMV视图中可以看到这种表统计信息为277个数据页,所以形成了277次预读。
但是,事实这个数据表是279页,也就是说统计的信息有问题,造成了少读读取了2个数据页,而为了弥补这个统计过失就出现了2次物理读,重新从硬盘中获取。
利器二、时间统计
关于时间统计这个很简单,就是统计T-SQL执行语句执行时间项,包括CPU占用时间、语句编译时间、语句执行总时间等项。
使用方法也很简单,一行代码
SET STATISTICS TIME ON
通过这个参数,可以分析出以上信息,其作用主要是用来对比查询语句调优中的执行时间,我们的目标就是降低执行时间。
举例:我们通过开启时间统计,来对比下,上面的查询语句,在第一次运行和以后运行(数据已经缓存)的时间对比,了解下缓存的重要性
再次执行的时间
缓存追踪(补充于2014年12月25日)
当然我们也可以再深入一点,如果想查看该部分数据在内存中缓存的明细,可以通过如下DMV脚本查看
SELECT * FROM sys.dm_os_buffer_descriptors
WHERE DB_NAME(database_id)='Northwind'
AND page_type='DATA_PAGE'
ORDER BY page_id
也可以通过该DMV分析出各个库在内存中占据的大小比例,脚本如下:
--清除缓存
dbcc dropcleanbuffers--查看缓存内容中在内存大小
SELECT COUNT(*)*8/1024 as 'Cached Size(MB)'
,CASE database_id
WHEN 32767 THEN 'ResourceDB'
ELSE DB_NAME(database_id)
END AS 'Database'
FROM sys.dm_os_buffer_descriptors
GROUP BY DB_NAME(database_id),database_id
ORDER BY 'Cached Size(MB)' DESC
经过这次查询,这张表已经全部缓存到内存里了,因为整张表总共就2MB的大小
文章已经有点长度了...先到此吧。
关于调优内容太广泛,我们放在以后的篇幅中介绍,有兴趣的可以提前关注。
参考文献
微软联机丛书读取页
参照书籍《SQL.Server.2005.技术内幕》系列
SQL Server调优(深入剖析统计信息)
前言
经过前几篇的分析,其实大体已经初窥到SQL Server统计信息的重要性了,所以本篇就要祭出这个神器了。
该篇内容会很长,坐好板凳,瓜子零食之类...
不废话,进正题
技术准备
数据库版本为SQL Server2008R2,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks
相信了解SQL Server的朋友,对这两个库都不会太陌生。
概念理解
关于SQL Server中的统计信息,在联机丛书中是这样解释的
查询优化的统计信息是一些对象,这些对象包含与值在表或索引视图的一列或多列中的分布有关的统计信息。查询优化器使用这些统计信息来估计查询结果中的基数或行数。通过这些基数估计,查询优化器可以创建高质量的查询计划。例如,查询优化器可以使用基数估计选择索引查找运算符而不是耗费更多资源的索引扫描运算符,从而提高查询性能。
其实关于统计信息的作用通俗点将就是:SQL Server通过统计信息理解库中每张表的数据内容项分布,知道里面数据“长得啥德行,做到心中有数”,这样每次查询语句的时候就可以根据表中的数据分布,基本能定位到要查找数据的内容位置。
比如,我记得我以前有篇文章写过一个相同的查询语句,但是产生了完全不同的查询计划,这里回顾下,基本如下:
SELECT * FROM Person.Contact
WHERE FirstName LIKE 'K%'
SELECT * FROM Person.Contact
WHERE FirstName LIKE 'Y%'
完全相同的查询语句,只是查询条件不同,一个查找以K开头的顾客,一个查找以Y开头的顾客,却产生了完全不同的查询计划。
其实,这里的原因就是统计信息在作祟。
我们知道,在这张表的FirstName字段存在一个非聚集索引,目标就是为了提升如上面的查询语句的性能。
但是这张表里面FirstName字段中的数据内容以K开头的顾客存在1255行,也就是如果利用非聚集索引查找的方式,需要产生1225次IO操作,这可能不是最糟的,糟的还在后面,因为我们获取的数据字段并不全部在FirstName字段中,而需要额外的书签查找来获取,而这个书签查找会产生的大量的随机IO操作。记住:这里是随机IO。关于这里的查找方式在我们第一篇文章中就有介绍。
所以相比利用非聚集索引所带来的消耗相比,全部的所以索引扫描来的更划算,因为它依次扫描就可以获取想要的数据。
而以Y开头的就只有37行,37行数据完全通过非聚集索引获取,再加一部分的书签查找很显然是一个很划算的方式。因为它数据量少,产生的随机IO量相对也会少。
所以,这里的问题来了:
SQL Server是如何知道这张表里FirstName字段中以K开头的顾客会比较多,而以Y开头反而少呢?。
这里就是统计信息在作祟了,它不但知道FirstName字段中各行数据的内容“长啥样”,并且还是知道每行数据的分布情况。
其实,这就好比在图书库中,每个书架就是一张表,而每本书就是一行数据,索引就好像图书馆书籍列表,比如按类区分,而统计信息就好像是每类书籍的多少以及存放书架位置。所以你借一本书的时候,需要借助索引来查看,然后利用统计信息指导位置,这样才能获取书本。
希望这样解释,看官已经明白了统计信息的作用了。
这里多谈点,有很多童鞋没有深入了解索引和统计信息的作用前提下,在看过很多调优的文章之后,只深谙了一句话:调优嘛,创建索引就行了。
我不否认创建索引这种方式调优方式的作用性,但是很多时候关于建索引的技巧却不了解。更巧的是大部分情况下属于误打误撞创建完索引后,性能果真提升了,而有时候创建的索引却毫无用处,只会影响表的其它操作的性能(尤其是Insert),更有甚者会产生死锁情况。
而且,关于索引项的作用,其实很多的情况下,并不想你想象的那么美好,后续文章我们会分析那些索引失效的原因。
所以遇到问题,其实还要通过表象理解其本质,这样才能做到真正的有的放矢,有把握的解决问题。
解析统计信息
我们来详细分析一下统计信息中的内容项,我们知道在上面的语句中,在表Customers中ContactName列中存在一个非聚集索引项,所以在该列存在统计信息,我们可以通过如下脚本查看该表的统计信息列表
sp_helpstats Customers
然后通过以下命令来查看该统计信息的详细内容,代码如下
DBCC SHOW_STATISTICS(Customers,ContactName)
每一个统计信息的内容都包含以上三部分的内容。
我们依次来分析下,通过这三部分内容SQL Server如何了解该列数据的内容分布的。
a、统计信息的总体属性项
该部分包含以下几列:
Name:统计信息的名称。
Updated:统计信息的最近一次更新时间,这个时间信息很重要,根据它我们能知道该统计信息什么时候更新的,是不是最新的,是不是存在统计信息更新不及时造成统计的当前数据分布不准确等问题。
Rows:描述当前表中的总行数。
Rows Sampled:统计信息的抽样数据。当数据量比较多的时候,统计信息的获取是采用的抽样的方式统计的,如果数据量比较就会通过扫描全部获取比较精确的统计值。比如,上面的例子中抽样数据就为91行。
Steps:步长值。也就是SQL Server统计信息的根据数据行的分组的个数。这个步长值也是有SQL Server自己确定的,因为步长越小,描述的数据越详细,但是消耗也越多,所以SQL Server会自己平衡这个值。
Density:密度值,也就是列值前缀的大小。
Average Key length:所有列的平均长度。
String Index:表示统计值是否为字符串的统计信息。这里字符串的评估目的是为了支持LIKE关键字的搜索。
Filter Expression:过滤表达式,这个是SQL Server2008以后版本的新特性,支持添加过滤表达式,更加细粒度进行统计分析。
Unfiltered Rows:没有经过表达式过滤的行,也是新特性。
经过上面部分的数据,统计信息已经分析出该列数据的最近更新时间、数据量、数据长度、数据类型等信息值。
b、统计信息的覆盖索引项
All density:反映索引列的稠密度值。这是一个非常重要的值,SQL Server会根据这个评分项来决定该索引的有效程度。
该分值的计算公式为:density=1/表中非重复的行数。所以该稠密度值取值范围为:0-1。
该值越小说明该列的索引项选择性更强,也就说该索引更有效。理想的情况是全部为非重复值,也就是说都是唯一值,这样它的数最小。
举个例子:比如上面的例子该列存在91行,假如顾客不存在重名的情况下,那么该密度值就为1/91=0.010989,该列为性别列,那么它只存在两个值:男、女,那么该列的密度值就为0.5,所以相比而言SQL Server在索引选择的时候很显然就会选择ContactName(顾客名字)列。
简单点讲:就是当前索引的选择性高,它的稠密度值就小,那么它就重复值少,这样筛选的时候更容易找到结果值。相反,重复值多选择性就差,比如性别,一次过滤只能过滤掉一半的记录。
Average Length:索引的平均长度。
Columns:索引列的名称。这里因为我们是非聚集索引,所以会存在两行,一行为ContactName索引列,一行为ContactName索引列和聚集索引的列值CustomerID组合列。希望能明白这里,索引基础知识。
通过以上部分信息,SQL Server会知道该部分的数据获取方式那个更快,更有效。
c、统计信息的直方图信息
我们接着分析第三部分,该列直方图信息,通过这块SQL Server能直观“掌控”该列的数据分布内容,我们来看
RANGE_HI_KEY:直方图中每一组数据的最大值。这个好理解,如果数据量大的话,经过分组,这个值就是当前组的最大值。上面例子的统计信息总共分了90组,总共才91行,也就是说,SQL Server为了准确的描述该列的值,大部分每个组只取了一个值,只有一个组取了俩值。
RANGE_ROWS:直方图的没组数据的区间行数(不包括最大值)。这里我们说了总共就91行,它分了90组,所以有一组会存在两个值,我们找到它:
EQ_ROWS:这里表示和上面最大值相等的行数目。因为我们不包含一样的,所以这里值都为 1
DISTINCT_RANGE_ROWS:直方图每组数据区间的非重复值的数目。上限值除外。
AVG_RANGE_ROWS:每个直方图平均的行数。
经过最后一部分的描述,SQL Server已经完全掌控了该表中该字段的数据内容分布了。想获取那些数据根据它就可以从容获取到,并且统计信息是排序了的。
所以当我们每次写的T-SQL语句,它都能根据统计信息评估出要获取的数据量多少,并且找到最合适的执行计划来执行。
我也相信经过上面三部分的分析,关于文章开篇我们提到的那个关于‘K’和‘Y’的问题会找到答案了,这里不解释了。
当然,如果数据量特别大,统计信息的维护也会有小小的失误,而这时候就需要我们来站出来及时的弥补。
创建统计信息
通过上面的介绍,其实我们已经看到了统计信息的强大作用了,所以对于数据库来说它的重要性就不言而喻了,因此,SQL Server会自动的创建统计信息,适时的更新统计信息,当然我们可以关闭掉,但是我非常不建议这么做,原因很简单:No Do No Die...
这两项功能默认是开启的,也就是说SQL Server会自己维护统计信息的准确性。
在日常维护中,我们大可不必要去更改这两项,当然也有比较极端的情况,因为我们知道更新统计信息也是一个消耗,在非常的大的并发的系统中需要关掉自动更新功能,这种情况非常的少之又少,所以基本采用默认值就可以。
在以下情况下,SQL Server会自动的创建统计信息:
1、在索引创建时,SQL Server会自动的在索引列上创建统计信息。
2、当SQL Server想要使用某些列上的统计信息,发现没有的时候,这时候会自动创建统计信息。
3、当然,我们也可以手动创建。
比如,自动创建的例子
select * into CustomersStats from Customers
sp_helpstats CustomersStats
来添加一个查询语句,然后再查看统计信息
select * from CustomersStatswhere ContactName='Hanna Moos'
go
sp_helpstats CustomersStats
go
当然,我们也可以根据自己的情况来手动创建,创建脚本如下
USE [Northwind]
GO
CREATE STATISTICS [CoustomersOne] ON [dbo].[CustomersStats]([CompanyName])
GO
SQL Server也提供了GUI的图像化操作窗口,方便操作
在以下情况下,SQL Server会自动的更新统计信息:
1、如果统计信息是定义在普通的表格上,那么当发生以下任一种的变化后,统计信息就会被触发更新动作。
表格从没有数据变成大于等于1条数据。
对于数据量小于500行的表格,当统计信息的第一个字段数据累计变化大于500以后。
对于数据量大于500行的表格,当统计信息的第一个字段数据累计变化大于500+(20%*表格总的数据量)以后。所以对于较大的表,只有1/5以上的数据发生变化后,SQL Server才会重新计算统计信息。
2、临时表上也可以有统计信息。这也是很多情况下采用临时表优化的原因之一。其维护策略基本和普通表格一样,但是表变量不能创建统计信息。
当然,我们也可以手动的更新统计信息,更新脚本如下:
UPDATE STATISTICS Customers WITH FULLSCAN
文章写的有点糙....但篇幅已经稍长了....先到此吧...后续我再补充一部分关于统计信息的内容。
关于调优内容太广泛,我们放在以后的篇幅中介绍,有兴趣的可以提前关注。
参考文献
参照书籍《Microsoft SQL Server企业级平台管理实践》
参照书籍《SQL.Server.2005.技术内幕》系列
SQL Server调优(如何索引调优)
前言
上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布。不清楚的童鞋可以点击参考。
作为调优系列的文章,数据库的索引肯定是不能少的了,所以本篇我们就开始分析这块内容,关于索引的基础知识就不打算深入分析了,网上一搜一片片的,本篇更侧重的是一些实战项内容展示,希望通过本篇文章各位看官能在真正的场景中找到合适的解决方法足以。
对于索引的使用,我希望的是遇到问题找到合适的解决方法就可以,切勿乱用!!!
本篇在分析出索引的优越性的同时也将负面影响展现出来。
技术准备
数据库版本为SQL Server2012,前几篇文章用的是SQL Server2008RT,内容区别不大,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks
相信了解SQL Server的朋友,对这两个库都不会太陌生。
概念理解
所谓的索引同SQL Server中的其它类型的数据页一样,也是固定的8KB(8192字节),存储方式同为B-Tree结构,索引B树中的每一页称为一个索引节点。B树顶端节点为根节点。索引中的底层节点称为叶节点。根节点与叶节点之间的任何索引统称为中间级。
算了,描述起来太麻烦,联机丛书上截个图直观的展示结构:
上面的图直观的展示出B-Tree结构的方式,基本和数据页的结构类似,这里有一点需要提醒下,就是聚集索引的最底层的叶子节点存储的为实际的数据页。就这一点为数据的快速获取可谓提供了一个超快方式,也是我们调优中必须要使用的,后续文章中分析。
再来看一下非聚集索引。
非聚集索引和聚集索引相比,同样以B-Tree的结构存储,但是在存储的内容上有着显著的区别:
基础表的数据行不按非聚集索引键的顺序排序和存储
非聚集索引的叶层是由索引页而不是由数据组成
由于上面的几种特性中,很明显的获取数据最快的方式是通过聚集索引,因为它叶子节点就是数据页,同样叶子节点的数据页物理顺序也是按照聚集索引的结构顺序进行存储,这也就造成了一个数据表只能存在一个聚集索引,并且聚集索引所占据的磁盘空间要远远小于非聚集索引。
而对于非聚集索引的叶子节点存储的是索引行,获取数据的话必须通过索引行所记录的数据页的地址(聚集索引键或者堆表的RID),这一特性也就是造就了,一张数据表可以有多个非聚集聚集索引,并且需要自己独立的存储空间。
两种索引设计的初衷都是为了便于快速的获取到数据页,提高查询性能。这就好比一本书需要加上目录一个道理。
关于索引的知识很多,基础的内容不作太多介绍,不了解的可以自行查阅资料,网上N多。
下面主要介绍一下使用技巧和注意事项,我相信这也是朋友们最关注的。
一、聚集索引的选择
所有的利用索引提升查询性能方式中,首当其中的就是聚集索引,它速度快是因为B-Tree这种优越的存储算法,B-Tree作为一个平衡分叉树的数据结构,是市面上所有的关系型数据库所采用的方式,有兴趣的同学可以深入研究一下此种算法。
来看一下聚集索引,因为在一张表中只能存在一个,并且主要经过聚集索引查找在叶节点就可以获取到数据内容,所以SQL Server数据库系统也在尽力的为聚集索引的存在提供便利。
举个例子:
USE [TestDB]
GO
CREATE TABLE [dbo].[TestTable](
[A] [int] PRIMARY KEY NOT NULL,
[B] [varchar](20) NULL
)
GO
我们创建一张测试表,一般采取的最佳设计是在这张表上添加一个主键。
主键的概念,我相信几乎了解点数据库的童鞋就不陌生,两大基本特性:不重复、非空。
好了,仅仅这两点就被利用,不重复所带来的含义就是选择性高,非空更能带来数据的稠密度高,因此,SQL Server就痛快的将聚集索引选在了主键列上,并且这种方式在数据库中起了一个高雅的名字:主键索引。
所以当我们创建完这张表的时候,SQL Server默认就将该表的聚集索引建立好了。
为了避免名称的重复,SQL Server默认给名称加了一个GUID的字段。真可谓用心了。
当然,正规的方式使我们自己指定这个名称,脚本如下:
CREATE TABLE [TestTable3]
(
[A] [int] NOT NULL,
[B] [varchar](20) NULL
CONSTRAINT PK_Index PRIMARY KEY([A])
);
GO
看上去优雅多了。
其实,SQL Server这种默认的方式最主要的目的就是为了最大限度的利用好聚集索引,因为我们知道聚集索引所带来的好处,并且它还为非聚集索引的形成创造了基础条件:非聚集索引的叶子节点就是聚集索引的键值码。
所以基于此,我们以后设计表的时候,也不要辜负了SQL Server的用心,将每张表都应该有一个聚集索引。
我见过很多人设计出来的表就是赤裸裸的堆表。而这不是严重的,严重的是很多不明所以的在堆表上加上了非聚集索引,这在大并发的场景中就是一个典型的死锁环境,文章后面会复现该场景。
当然,这种方式不是一个最优的一种方式,因为我们知道我们在设计表的时候,主键大部分情况下为无意义的键,也就说很多的情况在查询的时候是不会作为筛选条件的,并且它所覆盖的范围也仅限于主键列。所以最优的设计是采用联合主键或者自定义聚集索引列。当然了,SQL Server上面这种设计的初衷大部分是考虑了小白的建表方式,权衡了利弊选出的一种折中方式,如无特别需求,默认的这种建立聚集索引的方式基本能满足业务场景。
接着我们分析下非聚集索引
二、非聚集索引的选择
经过文章前面的分析,我们可以了解到聚集索引所带来的好处,但是它也有着最大的自身限制性:一张表只能存在一个聚集索引。
为了更多的使用索引,SQL Server又引入了非聚集索引,并且单张表的非聚集索引项可以存在好多个,因此足以让我们领略索引带来的性能提升。
上面,我们知道在一张表指定主键的时候,SQL Server默认就将聚集索引给创建好了,但是对于非聚集索引的创建,SQL Server默认是不会帮助建立的,需要我们手动建立,因为它也不知道你的非聚集索引创建到那一列上更合适。
但是,通常有一个最佳实践就是,作为关系性数据为了应当复杂的业务实体,采用的设计结构一般都是采用一对一、一对多、多对多的设计思路,而这种设计结构就形成了主外键的关系,我们知道主键SQL Server会自动的创建聚集索引,索引在外键中推荐的方式是手动创建非聚集索引,目的是为了加快表之间的映射关系。
但是,非聚集索引因为其存储结构的特别性(叶节点存储的非数据页),影响了它读取数据的效率,并且更多时候我们要获取的是一部分数据而非一条数据。
在获取的一部分数据为非聚集索引所覆盖那么利用非聚集索引是高效的,如果获取的数据非索引所覆盖,也就是通过聚集索引查找的时候还需要引入额外的书签查找,这种状态效率是非常低的,因为我们知道对于B-Tree结构下的书签查找是:随机IO,随机IO所带来的性能消耗是非常大的,为此SQL Server会放弃这种方式,直接通过表扫描(Table seek)或者聚集索引扫描(Index Seek)获取的数据更直接。
上面的这部分内容,我在前面的第一篇文章就有介绍,可以点击查看。
描述起来太麻烦,来个例子解释下:
SELECT OrderID,CustomerID,OrderDate
FROM Orders
ORDER BY OrderDate
很简单的查询,来看一下执行计划
因为该表上存在一个主键,所以这里采用了聚集索引扫描(Index Scan),如果没有聚集索引,这里肯定就是表扫描了。
下面我们利用一个Hint提示来查看一下SQL Server利用非聚集索引的过程。
这里我们用Fast N Hint提示,这个提示很简单就是告诉SQL Server快速的先获取出前N行数据,别的数据都靠后...把前N行的数据获取效率提至最高(记住:这个提示最佳的应用场景就是分页查询,很多业务系统都有分页显示,加上此Hint会让数据库最快的获取出前多少条数据)
我们后续的文章会详细分析各种Hint的用处。
继续分析,我想快速获取到前1行数据,脚本如下:
SELECT OrderID,CustomerID,OrderDate
FROM Orders
ORDER BY OrderDate
OPTION(FAST 1)
为了快速获取到一行数据,SQL Server更改了执行计划,采用了非聚集索引来扫描,并且为了获取出其它列的数据不得不引进一个书签查找(Key Lookup),从上面我们可以看到书签查找的消耗高达66%。
我们接着分析,我想获取前十行的数据,脚本如下:
SELECT OrderID,CustomerID,OrderDate
FROM Orders
ORDER BY OrderDate
OPTION(FAST 10)
当我们要获取十行的时候,书签查找的消耗已经开始飙升,上面已经飙升到了90%....原因很简单,就是我文章前面分析的这里是随机IO...
虽然书签查找影响效率,但是我们查找的数据只是很少的一部分,所以这里SQL Server认为利用非聚集索引+书签查找获取数据还是一种最优方式。
我们接着分析,我想快速获取二十行数据,脚本如下
SELECT OrderID,CustomerID,OrderDate
FROM Orders
ORDER BY OrderDate
OPTION(FAST 20)
到此,SQL Server已经果断的放弃了非聚集索引+书签查找这种方式。采用了聚集索引扫描这种更低廉的方式。
经过我的测试,我找到了SQL Server认为这个聚集索引有效的数值范围:
SELECT OrderID,CustomerID,OrderDate
FROM Orders
ORDER BY OrderDate
OPTION(FAST 15)
SELECT OrderID,CustomerID,OrderDate
FROM Orders
ORDER BY OrderDate
OPTION(FAST 16)
这个判别的阀值是15行,一旦超过了15行数据,SQL Server就会放弃非聚集索引了。
我们从这个过程中可以分析出非聚集索引的有效范围:15(有效行数)/1660(总行数)=0.009638,也就是9%的这么一个量,当然,这个值非固定值,取决于多种因素,比如行类型、内容分布、硬件环境等吧。
但是,通过这个值我想告诉你的是:非聚集索引的有效性其实范围很窄,因为其覆盖范围小,这就导致了很多童鞋建立好了非聚集索引了,但是在真正执行的时候基本是没有用。
这里再多谈点,还有很多人误认为神马非聚集索引选INT类型比选Varchar类型好,更有甚者上次看到群里有人为了把电话号码也存储成INT....目的就是为了查找快云云...
关于这些观点,其实都是很浅层的理解...索引列的选择最好是整型不错,但是也好区分好列内容分布,选择的标准只有一个:最大限度的提升SQL Server的可选择性。
举个极端点的例子:将性别列加上非聚集索引:选择性只有50%.......本来非聚集索引覆盖范围就小,这种索引基本上就是无用...
另外,还要注意索引的顺序问题,比如:两列值:姓、名字,设计索引的时候请将姓放在前面,然后是名字...这就好比你查找通讯录一般最先区分姓,然后在找名字一样....
好吧...一谈就谈多了,回归咱们的内容。
上面的非聚集索引带来的随机IO问题,SQL Server从2005版本也给出了解决方法:包含性的列索引
其实很简单,就是在存储非聚集索引的时候将要获取的数据页包含进叶子节点。
就是为了模仿聚集索引的方式,将非聚集索引的叶子节点也存放进数据页信息,当然,因为物理数据页只有一份,所以非聚集索引只能再拷贝一份自己存储了,这样在查找非聚集索引的时候就可以直接获取数据了。
代码如下:
USE [Northwind]
GO
CREATE NONCLUSTERED INDEX [OrderDateINDEX] ON [dbo].[Orders]
(
[OrderDate] ASC
)
INCLUDE
(
[OrderID],
[CustomerID]
) WITH (ONLINE = ON)
GO
这样的话,在查找这列的时候就都会采用此非聚集索引了。并且避免了随机IO(书签查找)的存在,降低了IO值,提升了性能。
当然,在大部分的业务系统中,利用非聚集索引获取的数据量还是比较少的,大部分是一条展示明细页面,这样的话非聚集索引的有利面就充分显现了。
所以针对OLTP业务系统而言,要学会利用好非聚集索引。
当然,凡事有利有弊,也不能过多的创建非聚集索引,如果利用过多的索引这就好比将一张表的各个列数据拷贝了N份重新存储,占用空间不说,最主要的是SQL Server在新添加数据的时候需要维护各个非聚集索引,这会导致数据的插入速度减慢,还会造成更多的索引碎片,增加读取IO。
下面,我们来重现下文章前面提到的死锁现象,这些问题纯粹是设计不到位导致。
关于此问题高兄在以前的文章中就有介绍,这里我借用以下它的脚本来重现下,点击此可以连接到高兄的那篇文章。
脚本如下:
create table testklup
(
clskey int not null,
nlskey int not null,
cont1 int not null,
cont2 char(3000)
)
create unique clustered index inx_cls on testklup(clskey)
create unique nonclustered index inx_nlcs on testklup(nlskey) include(cont1)
insert into testklup select 1,1,100,'aaa'
insert into testklup select 2,2,200,'bbb'
insert into testklup select 3,3,300,'ccc'
开启一个线程进项查询修改
----模拟高频update操作
declare @i intset @i=100while 1=1
begin
update testklup set cont1=@i
where clskey=1
set @i=@i+1
end
另外同样一个线程进行查询操作
----模拟高频select操作
declare @cont2 char(3000)while 1=1
begin
select @cont2=cont2 from testklup where nlskey=1
end
本来两个操作,一个要修改,一个要查询,SQL Server会自动很好的维护好两者秩序,不会发生死锁的情况,但是...但是我们在上面创建了一个包含性的非聚集索引,将Cont1列拷贝进入了非聚集索引,这样修改操作就需要维护非聚集索引列,而这时候我们有利用非聚集索引进行查询,两者恰巧发生在同一张表的两个不同的键值上,这就造成了一次死锁的发生。
我们开启Profile来捕捉此死锁的发生。
其实,对于这种问题好几种解决方式,因为我们这知道这个问题的罪魁祸首就是我们创建的非聚集索引不恰当,使得查询和修改发生在两个同一张表的不同键值上。
所以一种解决方式就是,直接将这个聚集索引去掉。这样就不会产生额外的键锁的存在。
另一种方式就是讲我们的非聚集索引把cont2列也包含进去,脚本如下
CREATE NONCLUSTERED INDEX [inx_nlskey_incont2] ON [dbo].[testklup]
([nlskey] ASC) INCLUDE ( [cont2])
当然,也可以提高隔离级别或者降低隔离级别,但这不是推荐的方法,原因很简单:降低隔离级别会脏读,提高隔离级别会影响并发量。
希望各位看官在设计数据库的时候不要发生此类悲剧。尤其高并发的情况下,一定要谨慎,再谨慎的进行。
当然,这里也要捎带提醒一下:不要手里拿着锤子,眼里看什么都是钉子!!切勿过度设计。
还是那句话,合适的场景采取合适的方案,一切不能武断,更不能轻易听信于别人,要以实践方能出真理。
索引的知识实在是太广泛....稍写点东西就够篇幅了....先到此吧...后续我再补充一部分关于索引的内容。
我们要及时的维护好索引,及时的重建、碎片整理、删除无用索引等操作,包括创建索引的一系列注意项等。
关于此块内容下一篇文章介绍吧。
关于调优内容太广泛,我们放在以后的篇幅中介绍,有兴趣的可以提前关注
三、考察问题
在文章的最后,晒一个前几天在书中看到的一个比较有意思的逻辑,这里共享下供院友们玩味,也考察下对T-SQL语句的逻辑能力,这道题可以作为一道面试题,不算太难,但是完全能测试出对T-SQL编程能力的高低。
问题内容如下:
--创建一个回话信息记录表
CREATE TABLE dbo.Sessions
(
keycol INT NOT NULL IDENTITY,
app VARCHAR(10) NOT NULL,
usr VARCHAR(10) NOT NULL,
host VARCHAR(10) not null,
starttime DATETIME not null,
endtime DATETIME not null,
CONSTRAINT PK_Sessions PRIMARY KEY(keycol),
CHECK(endtime>starttime)
);
GO--插入部分测试数据
INSERT INTO DBO.Sessions
VALUES('app1','user1','host1','20030212 08:30','20030212 10:30');
INSERT INTO DBO.Sessions
VALUES('app1','user2','host1','20030212 09:30','20030212 11:30');
INSERT INTO DBO.Sessions
VALUES('app1','user3','host2','20030212 09:31','20030212 11:20');
INSERT INTO DBO.Sessions
VALUES('app1','user4','host2','20030212 11:30','20030212 12:30');
INSERT INTO DBO.Sessions
VALUES('app1','user5','host3','20030212 11:35','20030212 12:35');
INSERT INTO DBO.Sessions
VALUES('app2','user6','host3','20030212 08:30','20030212 10:30');
INSERT INTO DBO.Sessions
VALUES('app2','user7','host3','20030212 08:30','20030212 10:30');
INSERT INTO DBO.Sessions
VALUES('app2','user8','host3','20030212 08:30','20030212 10:30');
就一张表,要求获取出:查询出每个应用程序的最大并发数....
问题不是很难,想测试下能力的可以试试.....再重申下,一定好审好题再做,可以将答案给我留言。
SQL Server调优(如何维护数据库索引)
前言
上一篇我们研究了如何利用索引在数据库里面调优,简要的介绍了索引的原理,更重要的分析了如何选择索引以及索引的利弊项,有兴趣的可以点击查看。
本篇延续上一篇的内容,继续分析索引这块,侧重索引项的日常维护以及一些注意事项等。
闲言少叙,进入本篇的主题。
技术准备
数据库版本为SQL Server2012,前几篇文章用的是SQL Server2008RT,内容区别不大,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks。
相信了解SQL Server的朋友,对这两个库都不会太陌生。
一、创建索引
当我们要开始对表进行索引的创建的时候,首先明确的是,一张表内只能创建一个聚集索引,最多可以创建最多249个非聚集索引(SQL Server2005),在SQL Server2008以后聚集索引数提升至999个,上一篇文章我们知道对于聚集索引项一般要创建上,而非聚集索引项要根据日常的T-SQL语句进行选择。
关于索引的选择是一个很考验调优能力的事情,大部分的情况下优质的索引新建全靠经验而论,有兴趣的可以点击查阅我前面的一系列关于分析查询计划的文章,掌握住里面的精髓才能有的放矢。
当然,小白级别的也可以参照如下方法尝试进行创建:
由于SQL Server有着自己的一套调优技巧,所以在我们每次运行的T-SQL语句应该怎样优化,SQL Server是了如指掌的,所以它会将缺失的索引项进行记录,用于提示使用者,尝试去建立这些索引。
主要记录在以下几个DMV中
sys.dm_db_missing_index_details
sys.dm_db_missing_index_groups
sys.dm_db_missing_index_group_stats
sys.dm_db_missing_index_columns(index_handle)
sys.dm_db_missing_index_details
关于这些个DMV的使用,来举一个例子:
--新建表,建立主键,形成聚集索引
CREATE TABLE BigTable
(
[KEY] INT,
DATA INT,
PAD CHAR(200),
CONSTRAINT [PK1] PRIMARY KEY ([KEY])
)
GO--批量插入测试数据250000行
SET NOCOUNT ON
DECLARE @i INT
BEGIN TRAN
SET @i=0
WHILE @i<250000
BEGIN
INSERT BigTable VALUES(@i,@i,NULL)
SET @i=@i+1
IF @i%1000=0
BEGIN
COMMIT TRAN
BEGIN TRAN
END
END
COMMIT TRAN
GO
利用这个测试脚本,我们新建了一张测试表,并且插入了一些测试数据,运行一个查询
SELECT [KEY],[DATA]
FROM BigTable
WHERE DATA<1000
GO
在这个简单的查询脚本中,SQL Server已经提示了我们需要创建的索引项。我们可以右键,直接生成创建脚本
SQL Server已经提示我们要创建的索引项内容了,穿件一个非聚集索引在列DATA上,并且INCLUDE列KEY,并且经创建完这个索引后的提升值都给计算出来了。
以上这种方式,在我们调优的时候是经常使用的,在我们拿到需要优化的语句后,直接执行就可以看到一部分需要调整的信息了。
但是,大部分的T-SQL语句不允许我们进行这样的优化流程,甚至有时候是已经存在的系统。所以,我们下手的方式只能绕道了,幸好SQL Server为我们记录下了这些缺失索引项的信息,就存在我上面提到的几个DMV中。我们来查看下:
SELECT migs.group_handle, mid.*
FROM sys.dm_db_missing_index_group_stats AS migs
INNER JOIN sys.dm_db_missing_index_groups AS mig
ON (migs.group_handle = mig.index_group_handle)
INNER JOIN sys.dm_db_missing_index_details AS mid
ON (mig.index_handle = mid.index_handle)
WHERE migs.group_handle = 2
所以,大部分情况下,通过查看以上语句基本能确认到需要创建的索引项有哪些。
提示:但是,这里的DMV信息只是记录自上次SQL Server启动以后的信息项,也就是说每次重启之后这部分信息就丢失了,所以对于生产系统,建议确保运行了一段周期之后再进行查看。
知道了应该创建什么样的索引,下一步就是创建索引了,来看创建索引的脚本
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON <object> ( column [ ASC | DESC ] [ ,...n ] )
[ INCLUDE ( column_name [ ,...n ] ) ]
[ WHERE <filter_predicate> ]
[ WITH ( <relational_index_option> [ ,...n ] ) ]
[ ON { partition_scheme_name ( column_name )
| filegroup_name
| default
}
]
[ FILESTREAM_ON { filestream_filegroup_name | partition_scheme_name | "NULL" } ]
创建脚本很简单,指定索引类型、索引名称、所属表、包含列、筛选项、所属文件组以及操作项就可以创建了。
我相信基本搞过SQL Server数据的这块脚本一般不会陌生。
当然,如果不熟悉脚本的方式,SQL Server也默认给提供了图形化操作界面,傻瓜式操作
这里我们重点分析几点注意事项。
UNIQUE:
该关键字指定索引项为唯一值,也就是非重复值,在实际应用中非常的有用,应为唯一就意味着这个索引的高选择性,也就意味着当前索引的可用性高低。
前面文章已经分析了SQL Server会默认的在主键列上创建聚集索引,也是利用了主键的非空和唯一性特点。
当然,这里也提示下聚集索引要求的就是唯一性,如果当前列确实存在重复值,那在创建聚集索引的时候SQL Server会默认的在当前列上加上一个唯一标识符(uniqueifiter)在内部来保证索引的唯一性。但这个时候就不需要显式的指定UNIQUE了,否则会报如下错误:
CLUSTERED|NONCLUSTERED:
这个就是指定创建的索引为聚集还是非聚集索引。
关于它,这里有几点需要注意,因为非聚集索引的叶子节点存储的就是聚集索引键值,所以在创建顺序上要保证优先创建聚集索引,而后再创建非聚集索引,保证有足够的存储空间来存放非聚集索引。
在我们重新创建聚集索引的时候,SQL Server会默认的重新生成全部非聚集索引,如果表数据量特别大,这个过程会很漫长,如果不指定ONLINE的话,这个过程会是锁定索引B-Teee的,这就意味着是阻塞的,业务就要停下来等待完成操作,切记不要将此事发生在生产机上。
当然,以上问题是可以避免的。
index_name:索引的名字。
column :
创建索引所选的列了,提示下:不能将大型对象 (LOB) 数据类型 ntext、text、varchar(max)、 nvarchar(max)、varbinary(max)、xml 或 image 的列指定为索引的键列。 另外,即使 CREATE INDEX 语句中并未引用 ntext、text 或 image 列。如果想用这些类型的列可以存放于INCLUDE里面。
INCLUDE:
索引包含列,这个关键字非常有用,尤其在应对T-SQL的随机IO问题上,具体内容可参照我前面的一系列的文章介绍。
还有前面提到的那些大型对象(LOB)数据类型,也可以包含进去,不过这里有一点需要提示下,如果包含了大型对象,则创建索引不支持在线(ONLINE)操作,这就意味着必须选择非业务器进行操作。
PAD_INDEX = { ON | OFF }|FILLFACTOR =fillfactor
这个两个选项是为了设置填充因子使用的,也是我们在创建索引的时候最常用的。
关于填充因子的作用简单点讲就是为了减少分页而在索引空间中提前先预留空间。我们知道对于聚集索引在叶级别就包含了数据,所以用户在这里可以指定每个叶子保留的空间的大小,通过预留空间,就可以避免用户新的数据填充而产生分页现象,产生索引碎片影响性能。
当然,关于填充因子的内容支撑,是需要一部分基础知识的,有兴趣的可以点击此参照联机丛书的官方介绍。
索引默认的的选项是OFF,也就是说基本不会预留太多空间。
关于这里填充因子设置的数值大小问题,其实没有一个固定的值,纯粹是一个经验值,来自于系统的场景和长期运行的总结。当然,如果非要给出的话,可以参照如下进行设置:
1.当读写比例大于100:1时,不要设置填充因子,100%填充
2.当写的次数大于读的次数时,设置50%-70%填充
3.当读写比例位于两者之间时80%-90%填充
但是,这个值并不是被SQL Server所维护的,也就是说在这部分预留空间填满之后,后者改数据页删除部分数据之后,还是会产生索引碎片,所以在系统运行过一段周期之后,我们需要手动的去重新整理索引,来维护好索引的秩序,维护方式也就是:重新创建,重新组织等。文章后面的会介绍。
SORT_IN_TEMPDB = { ON | OFF }
这个就是指定当前索引排序是否要借助TempDB库,默认值为OFF。如果想快速的生成索引请将此选项指定为ON,当然弊端就是会扩大TempDB的大小,如果原表数据量特别多的话,这可能会是一个很大的空间值。
STATISTICS_NORECOMPUTE = { ON | OFF}
这个指定是否同时更新统计信息。默认是开启的。我知道统计信息的重要性,所以在创建的时候不要更改此值。
DROP_EXISTING = { ON | OFF }
删除或重建的时候是否重新生成已经命名先前存在的聚集或非聚集索引。默认是OFF。
这个选项非常的有用。删除或者重建索引的时候整个流程是作为一个事务来处理的。所以,通常情况下,如果打算重建一个聚集索引的时候,需要先删除聚集索引,而后再新建立一个,但是这个流程中,在删除的时候SQL Server必须重建每一个非聚集索引将每一个非聚集索引的叶子节点有聚集索引键改成RID,然后新建过程,在重复的将所有的每一个非聚集索引的叶子节点由RID键更改成新的聚集索引键值。
这就是需要重建非聚集索引两次,如果表数据量特别大的话,这个时间消耗就会很长很长...而且是阻塞的....
但是如果指定DROP_EXISTING选项为ON的话,就可以在创建或者删除的时候只需要一次更改所有非聚集索引就可以。当然此方式也可以通过ALTER INDEX做到,后面分析。
ONLINE = { ON | OFF }
是否在线提供索引创建,此方式也是数据库的在05版本以后新添加的一大亮点,提供了在线状态下索引的创建,但是仅限于Enterprise版本。
如果在生产系统中,业务并发时期可以采用这个选项进行索引的创建及维护,但相对离线创建的时间周期要明显长很多,但是不会造成业务停机。
如果深入研究此方式的底层原理,其实就是数据的快照隔离机制,简单点将就是在创建索引的时候,将相应的数据行提供了版本控制,避免了和正常业务系统的锁争用从而避免了阻塞,属于乐观锁机制原理。
MAXDOP = max_degree_of_parallelism
设置并行计划的数量值。这个选项也很有用,如果是非业务高发期,可以适当调高此值来并行进行索引的创建,加快索引的创建速度。
当然,也受限于物理的CPU核数。还有就是此功能也只有Enterprise版提供。
ALLOW_ROW_LOCKS = { ON | OFF }|ALLOW_PAGE_LOCKS = { ON | OFF }
此方式指定是否行锁或者页锁,当然,只所以索引的创建和修改大部分情况下需要离线操作,就是因为在索引创建的时候加锁了。为了加快索引的生成就必须添加相应的锁。
如果 ALLOW_ROW_LOCKS = ON 且 ALLOW_PAGE_LOCK = ON,则访问索引时允许行级、页级和表级锁。数据库引擎将选择相应的锁,并且可以将锁从行锁或页锁升级到表锁。
如果 ALLOW_ROW_LOCKS = OFF 且 ALLOW_PAGE_LOCK = OFF,则访问索引时仅允许使用表级锁。
一个有用的索引的创建需要耐心的创建出来,切勿草率的鲁莽进行,如果操作不当有可能还会产生更多意外的情况。所以要充分把握好数据的特性,合理的创建好每一个有用的索引。
二、索引管理
经过上面一步的索引的创建,其实在日常的大部分时间就需要维护好索引。关于索引的维护基本就集中在以下几个方面
a、索引的重建
当我们发现索引索引覆盖范围不够或者存在大量索引锁片,影响性能的时候,我们就需要对索引进行重建。
索引范围的问题其实大部分来源于对于T-SQL语句性能的把握,也就是我们前面几篇文章中分析的需要调优的内容项。
而关于索引碎片的形成,也是源于数据库长时间的运行,大量的增删该查造成了B-Tree结构的不准确,确切的说是不能正确的提供平衡查询的性能,或者大量的数据分页造成索引碎片,进而增大了IO,影响了性能。
关于索引碎片的查看,可以通过以下DMV语句进行
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatbaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, ROUND(s.avg_fragmentation_in_percent,2) AS [Fragmentation %]
INTO #TempFragmentation
FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?]; INSERT INTO #TempFragmentation
SELECT TOP 20
DB_NAME() AS DatbaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, ROUND(s.avg_fragmentation_in_percent,2) AS [Fragmentation %]
FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE s.database_id = DB_ID()
AND i.name IS NOT NULL
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
ORDER BY [Fragmentation %] DESC'
SELECT top 20 * FROM #TempFragmentation ORDER BY [Fragmentation %] DESC
DROP TABLE #TempFragmentation
看到了,这部分索引的碎片到大了99%...这就需要我们重建进行维护了,否则将严重拖垮数据的性能。
维护的方式也就主要集中在以下几种:
1、重建索引
这种方式简单高效也就是我们上面分析的CREATE INDEX 命令后面加上DROP_EXISTING方式。当然可以联机操作,操作方式参考文章前面
2、修改索引
这种方式是05版本以后才提供的,简单点将就是ALTER INDEX命令进行。其实底层的运行方式同索引重建,只不过这种方式更改的选项多一些。
3、索引重组
这种方式就是重新填充索引里面的数据,对于解决索引碎片的方式不如前面两种来的直接。不过也是一种推荐的方式,因为此方式在运行的时候,也是随时停止。
不像前面两种方式为原子性操作,并且业务阻塞。
b、索引的禁用
关于索引的禁用,这个功能也是SQL Server2005版本以后才出现的新功能,这个功能一般应用的不多。
因为大部分情况下将索引禁用了,还倒不如直接将索引删除掉来的直接。
但是,记住了既然SQL Server设计了它就是有它的用武之地的。
很多情况下,数据库在运行很长一段时间之后,会发生坏页的情况。而如果通过命令查找,发现损坏也处于索引项上,那么你所做的操作就是禁用这个索引(记住只能是禁用)
然后重新建立一个新索引就可以了。
在这种情况下我们可选的最快处理方式就是禁用该索引,因为一旦发生坏页的情况,该索引项是不允许删除的。
很多朋友就好奇了,索引来了个禁用,那我什么时候启用呢?.......
.嘿嘿...一旦问出了此问题,就说明了你对数据库的理解还很浅...基本上还算没有入门了......一旦索引禁用就意味着这个所以不再维护更新了....不再维护更新了那它里面的数据就是过时的或者说不准确的...那还启用它干嘛...与其启用还不如重新维护一个呢...
关于数据库坏页的情况,可以参照我前面写的一篇文章,点击此。
c、索引的删除
关于索引的删除,就不需要太多的介绍了,原因很简单,索引的存在会影响数据插入数据的速度,并且在查询的时候需要维护等多的锁,进而影响并发。
所以,一旦索引存在着一点优化的作用没有,我们就要及时的删除掉,因为百害而无一利嘛。
查看未使用的索引DMV脚本如下:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatbaseName
, SCHEMA_NAME(O.Schema_ID) AS SchemaName
, OBJECT_NAME(I.object_id) AS TableName
, I.name AS IndexName
INTO #TempNeverUsedIndexes
FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?]; INSERT INTO #TempNeverUsedIndexes
SELECT
DB_NAME() AS DatbaseName
, SCHEMA_NAME(O.Schema_ID) AS SchemaName
, OBJECT_NAME(I.object_id) AS TableName
, I.NAME AS IndexName
FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id
LEFT OUTER JOIN sys.dm_db_index_usage_stats S ON S.object_id = I.object_id
AND I.index_id = S.index_id
AND DATABASE_ID = DB_ID()
WHERE OBJECTPROPERTY(O.object_id,''IsMsShipped'') = 0
AND I.name IS NOT NULL
AND S.object_id IS NULL'
SELECT * FROM #TempNeverUsedIndexes
ORDER BY DatbaseName, SchemaName, TableName, IndexName
DROP TABLE #TempNeverUsedIndexes
当然,这些记录都是自动SQL Server启动以来未曾使用的索引,所以在生产系统中,一定要确保已经运行了一段周期了。
索引脚本的删除,很简单和表删除类似,直接drop掉就可以了。
当然,最后再赠送一个DMV,查看那些经常被大量更新,但是却基本不适用的索引项
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, s.user_updates
, s.system_seeks + s.system_scans + s.system_lookups
AS [System usage]
INTO #TempUnusedIndexes
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?]; INSERT INTO #TempUnusedIndexes
SELECT TOP 20
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, s.user_updates
, s.system_seeks + s.system_scans + s.system_lookups
AS [System usage]
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE s.database_id = DB_ID()
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
AND s.user_seeks = 0
AND s.user_scans = 0
AND s.user_lookups = 0
AND i.name IS NOT NULL
ORDER BY s.user_updates DESC'
SELECT TOP 20 * FROM #TempUnusedIndexes ORDER BY [user_updates] DESC
DROP TABLE #TempUnusedIndexes
关于这些脚本,就要自己酌情考虑是否删除了,不能一概而论。
SQL Server调优(如何利用查询提示(Hint)引导语句运行)
前言
前面几篇我们分析了关于SQL Server关于性能调优的一系列内容,我把它分为两个模块。
第一个模块注重基础内容的掌握,共分7篇文章完成,内容涵盖一系列基础运算算法,详细分析了如何查看执行计划、掌握执行计划优化点,并一一列举了日常我们平常所写的T-SQL语句所会应用的运算符。我相信你平常所写的T-SQL语句在这几篇文章中都能找到相应的分解运算符。
第二个模块注重SQL Server执行T-SQL语句的时候一些内幕解析,共分为5篇文章完成,其中包括:查询优化器的运行方式、运行时几个优化指标值检测,统计信息、利用索引等一系列内容。通过这块内容让我们了解SQL Server为我们所写的T-SQL语句如何进行优化及运行的。
从本篇进入第三个模块的内容,该篇为第一篇,该模块主要让我们来指导SQL Server进行定向调整,达到优化的目的。本模块的内容是以前面一系列内容为前提的,希望充分掌握了前面基础内容,方能进入本模块内容。
技术准备
数据库版本为SQL Server2012,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks。
相信了解SQL Server的朋友,对这两个库都不会太陌生。
概念理解
谈到hint,其实概念很简单,正如词义理解:提示,也就是说让我们通过给予SQL Server提示(hint)让数据库运行时按照我们的思路进行,我估计很多不怎么了解SQL Server的童鞋都不怎么知道,因为一般应用的不多。
其实,SQL Server本身的查询优化器已经做到很好了,所以大部分情况下不需要我们人工干预,自己就能运行的很好,并且最大限度的优化运行项。但是,俗话说:老虎也有打盹的时候,所以,在有些场景下,就需要我们来给数据库指导一个方向,让其运行的更流畅。
但是,记住了:你所应用的hint是在现在的场景中基于现有的环境下,相对是一个好的方式,不能确保你所给予的提示(Hint)永久有效,并且随着时间推移,数据量的变更,你所发出的提示(Hint)有可能会成为数据库优化的绊脚石。所以没有充分的把握不要轻易使用Hint,并且最好采用目标导向Hint。
Hint主要分为三类应用:查询Hint、表Hint、连接Hint。查询Hint影响整个查询,主要应用于查询语句优化,本篇主要分析查询Hint。
表Hint影响查询引用的单个表,而连接Hint影响一个单独的连接。
Hint应用方式分为两类:目标导向Hint和物理运算符Hint。
目标导向Hint传递逻辑的目标给优化器,而不会具体指定优化器应该如何达到这个目标,应该使用什么物理运算符,或者如何排列这些运算符。所以这种运算符使我们所推荐的,原因很简单:我告诉丫按照这个思路执行就可以,至于怎么达到,自己想办法!这种方式从长期看对于数据库的影响会小很多。
另外一个就是物理运算符,此方式就更直接了:直接告诉丫的步骤,你按照这个去做就行。这种方式不推荐,原因很简单:你的思路暂时会是好的,但是过段时间就不好了。
一、查询提示(Hint)
首先,查询提示(Hint)是我们在调优中应用最广泛的,因为大部分时间我们是在调整查询的性能。
关于查询中的优化选项就是在指导SQL Server的连接类型、聚合类型、联合类型等物理连接运算符。关于此块的详细解析,可以参照我调优系列中前几篇文章,分析的相当的详细。
a、FAST N Hint提示
关于此方式的提示,我在前面的文章中已经有使用到,在介绍索引那篇文章中,可以点击这里查看。
首先,这个Hint是一个目标导向hint。提示目标很简单:告诉数据库给我速度出前N行数据就可以,而其它的数据你爱咋地咋地。
这个提示最优的应用环境就是:应用系统中的分页查询,当然其它环境可以用。有点类似于SELECT TOP N....
其次,在我们的应用环境中,尤其数据量多的情况下,如果这时候我们的场景是:我想速度的看到前面的部分数据,其它的数据你可以稍后再显示,但是在执行T-SQL的时候,SQL Server会多方面的考虑耗费(cost),然后再平衡各种利弊选择出它认为相对好的执行计划去执行,显然这种方式获取数据的方式是很浪费的,并且速度就会相对慢很多。
所以,我们利用FAST N Hint提示,这样,SQL Server会阻止优化器使用哈希连接、哈希聚合、排序、甚至是并行这些大消耗的动作,而转变成为这N条数据做快速的优化并输出。这在大数据量的情况下,是一种非常高明的方式。
来个例子:
SELECT OrderID,CustomerID,OrderDate
FROM Orders
ORDER BY OrderDate
简单的查询,并且按照OrderDate排序,不看执行计划,我们就已经推测出这个执行计划中最耗损的就是这个OrderDate了,排序永远是高耗损,这也是为什么各种类型的索引都要提前排序的原因。
然后,我们再来看一下加上这个FAST N Hint提示的执行
SELECT OrderID,CustomerID,OrderDate
FROM Orders
ORDER BY OrderDateOPTION(FAST 1)
为了快速获取这一行数据,利用HINT后,改为了索引扫描+书签查找,因为这是获取一条数据的最优的一种方式。
因为数据量的关系,所以我上述演示没能很好的表现出FAST 提示的优越性来,其实在实际生产中,在面临庞大的数据量的时候,一般利用FAST N提示获取出部分数据之后,就不再继续运行了,因为我们关注的就是这一部分数据。
当然,此HINT也有弊端:在快速获取前N行结果之后,可能会延迟整个查询的总体相应时间。也就是说,尽管FAST N HINT可能会使优化器快速产生前N个输出计划。但是它会使优化器产生一个在结束最后一行前花费更多时间,消耗更多CPU,甚至于更多IO。
b、OPTIMIZE FOR Hint提示
此HINT是一种非常有用的提示,也是我们在日常中经常使用的。
这个HINT目标很简单:告诉优化器目标以Hint值进行分配或者执行。此Hint提示是从SQL Server2005版本以上开始支持,能够根据指定的参数值产生一个计划,尤其适用于非对称数据集中,因为这种数据集中数据分布不均匀,不同的参数值可能导致不同的基数评估和不同的查询计划,我们可以从不同的参数中选择一个最优的执行计划,作为后续不同参数的执行计划,避免了SQL Server的重新评估和重编译的耗费的动作。
来个例子:
SELECT OrderID,OrderDate
FROM Orders
WHERE ShipPostalCode=N'51100'
此语句很简单,就是通过查询邮政编码(ShipPostalCode),获取出订单ID和订单日期。
来看这个查询语句,最理想的情况就是直接通过索引查找(index seek)动作获取出数据。其实最好的方式也是通过INCLUDE将两列值包含进去。
我们来看一下实际的执行计划:
SQL Server通过了索引查找+书签查找方式获取,这种方式也凑合吧,其实我们还可以继续优化。
但是,这不是问题重点,问题重点是该段T-SQL一般我们会利用参数进行查询或者包装成存储过程通过传参调用。是吧??不会你永远只查询一个固定值吧....来看语句
DECLARE @ShipPostalCode NVARCHAR(50)
SET @ShipPostalCode=N'51100'
SELECT OrderID,OrderDate
FROM Orders
WHERE ShipPostalCode=@ShipPostalCode
是吧,这种方式才能做到重用嘛,不过包装成一个存储过程或者一个函数等,估计核心代码肯定就这样子了。
来看看生成的执行计划:
本来很爽的非聚集索引查找(Seek),通过我加了一个参数之后变成了聚集索引扫描(Scan)了,聚集索引扫描的性能跟表扫描基本一样,没有啥质的提高!
如果该表数据量特别大的话,我们为该语句设计的非聚集索引就失效了。只能通过依次扫描获取数据了。有意思吗???没意思!!!
怎么解决呢?这就是我们此处提到Hint出场的时候了,告诉数据库:丫就按照执行 “51100” 的查询一样去执行我传过来的参数。
DECLARE @ShipPostalCode NVARCHAR(50)
SET @ShipPostalCode=N'51100'
SELECT OrderID,OrderDate
FROM Orders
WHERE ShipPostalCode=@ShipPostalCodeOPTION(OPTIMIZE FOR( @ShipPostalCode=N'51100'))
看到了,这里又回归了快速的非聚集索引查找(Seek)状态,并且不受限制于传过来的参数是啥。
这个提示只是告诉SQL Server查询按照这个目标值进行操作,并不会实际影响结果值。
当然上面的问题,如果封装成存储过程的时候,可以采用重编译的方式解决,但是相比利用Hint的方式,重编译带来的消耗远大的多。尤其高并发的环境下重编译所带来CPU消耗是非常高的。
c、物理连接提示(Hint)
关于物理连接我们在前面的文章中已经详细的分析了,在SQL Server中共分为三种物理连接方式:嵌套循环、合并、哈希连接。
详细的内容可以参照我的基础篇中的链接:SQL Server调优系列基础篇(常用运算符总结——三种物理连接方式剖析)
文章中对三种连接的利弊进行了详细的对比,并且对三种连接的使用环境进行了详细的介绍。但是,有时候SQL Server为我们评估的连接并不是最优的,或者说并不是符合我们的要求,这时候,就要利用我们的物理连接提示进行指导。
总共分为三种查询级别的连接Hint,正好对应三种物理连接运算符,依次是:LOOP JOIN、MERGE JOIN 和 HASH JOIN
在应用时候,可以指定一个或者多个,如果指定一个,那么查询计划中的全部连接使用指定的连接类型,如果指定两个,SQL Server会在这两个连接类型中选择最好的一个,也就是毙掉了第三个。
应用场景蛮多的,根据三种连接的特性,我们可以有选择的进行提示,比如我们想一个查询不消耗内存,那么就可以指定OPTION(LOOP JOIN,MERGER JOIN),这样就去掉消耗内存的哈希连接,当然这是减小内存消耗但会增加执行时间。如果采用了合并连接(MERGER JOIN)方式不会消耗内存,但是合并连接需要提前排序(sort),排序会消耗大量的内存。
当然,有时候嵌套循环连接执行的时间不理想,就可以指定为哈希连接(hash join)进行连接。
来看个例子:
SELECT o.OrderID
FROM Customers C JOIN Orders O
ON C.CustomerID=O.CustomerID
WHERE C.City=N'London'
上面的查询计划采用了嵌套循环的连接方式,两张表依次进行循环嵌套执行。
如果,经过测试这里发现采用合并连接的方式更好一点,我们可以采用如下Hint进行提示操作
SELECT o.OrderID
FROM Customers C JOIN Orders O
ON C.CustomerID=O.CustomerID
WHERE C.City=N'London'
OPTION(MERGE JOIN)
经过调整之后,这时候该语句就利用到了我们设计的非聚集索引,并且由原来的索引SCAN变成了索引Seek运算。
通过如下方式,可以指导SQL Server在哈希连接和合并连接之间做出选择,但是一定要放弃嵌套循环连接。
SELECT o.OrderID
FROM Customers C JOIN Orders O
ON C.CustomerID=O.CustomerID
WHERE C.City=N'London'
OPTION(HASH JOIN,MERGE JOIN)
看以看到,经过评估SQL Server还是依然的选择了合并连接
其实,这个很正常,首先数据量不大,其次是在City列上存在非聚集索引,所以要充分利用,并且在两张表的CustomerID是都为索引所覆盖,这就保证了两张表在这列上都是预先排序(sort)了,这完全满足了合并连接的条件。当然,默认选择嵌套循环连接的原因,我估计的原因就一个:两张表数据量不大。
当然,出来上面的HINT方式可以指定连接的物理连接方式,还有另外更为粗暴的一种方式,强制执行。如下:
SELECT o.OrderID
FROM Customers C INNER MERGE JOIN Orders O
ON C.CustomerID=O.CustomerID
WHERE C.City=N'London'
当然,这种方式也手动的达到了指定采用合并连接的方式。
但是,此种方式有严重的弊端:
1、通过采用这种方式貌似暂时解决问题了,但是经过一段时间,此连接方式可能会严重阻碍数据库的优化,而要解决此问题就不得不更改代码。
2、只能粗暴的指定一种物理连接方式,不能顺应SQL Server本身自己的优化策略。
上述的方式是非常不推荐的一种,大部分新手会选择这种方式。
当然,利用Hint的方式是并非一种万全之策,但在当前基本能解决问题,当运行到一段周期之后,如果当前的HINT干预了SQL Server数据库的正常运行,我们也可以采用适当的方式予以停用Hint。使数据库得到完美的平稳的正常运行。后续文章我们依次介绍。
关于Hint这块的使用,内容还是挺多的,其中一部分还包含锁提示等,后续文章我们依次介绍,有兴趣的童鞋提前关注。
其实Hint是平常我们调优时候一种重要的工具。但是,这个工具的正确的使用则要依靠牢靠的基础知识掌握和经验累积。正所谓:厚积薄发! 不要轻易的看到了使用场景就妄自的进行盲目的使用。如果使用不当,还会扰乱SQL Server数据库本身正常的生态环境,得不偿失,越调越乱。
所以:施主,三思而行呀......
参考文献
微软联机丛书逻辑运算符和物理运算符引用
参照书籍《SQL.Server.2005.技术内幕》系列
结语
此篇文章先到此吧,关于SQL Server调优工具Hint的使用还有很多内容,后续依次介绍,有兴趣的童鞋可以提前关注。
SQL Server调优(如何利用汇聚联合提示(Hint)引导语句运行)
前言
上一篇我们分析了查询Hint的用法,作为调优系列的最后一个玩转模块的第一篇。有兴趣的可以点击查看:SQL Server调优系列玩转篇(如何利用查询提示(Hint)引导语句运行)
本篇继续玩转模块的内容,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析。
闲言少叙,进入本篇的内容。
技术准备
数据库版本为SQL Server2012,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks。
相信了解SQL Server的朋友,对这两个库都不会太陌生。
误区纠正
在开始本篇文章主题内容之前,先纠正一些关于新手对于数据库调优的误区。也希望在日常应用解决问题的时候,切记道听途说,人云亦云,毛爷爷说过的:实践是检验真理的唯一标准。
两个误区:
1、当在查询计划中发现了表扫描(Table Scan),就仿佛找到了病根一样,就想搞掉它,因为很多过来人都说过这种方式是性能很烂,而搞掉它的方式就是上索引,而且认为有了索引的就会快很多。
2、SQL Server语句优化就是创建索引,而创建索引就更简单了,找找查询语句,看看Where条件后...有几个筛选条件,创建几个非聚集索引就可以。
来看第一个问题:关于表扫描(Table Scan)是否真像传说的性能那么差劲!
首先,我们知道比较查询语句性能的优越性,无非就几个关键指标:运行IO、运行时间、消耗:CPU、Memory、编译时间等。
来看,以下语句,完全相同的表结构、表数据,不同的是一张表是堆表,一张是加了聚集索引的表,我们来开启两个回话进行测试比较。
堆表查询:
SET STATISTICS IO ON--新建个测试表
SELECT * INTO NewOrders FROM Orders--先清空缓存数据
DBCC DROPCLEANBUFFERS
GO
SELECT * FROM NewOrders
SET STATISTICS IO OFF
存在聚集索引的测试表查询:
SET STATISTICS IO ON--新建个测试表
SELECT * INTO NewCLOrders FROM Orders--添加聚集索引
CREATE CLUSTERED INDEX CL_OrderID ON NewCLOrders (OrderID desc)
GO--先清空缓存数据
DBCC DROPCLEANBUFFERS
GO
SELECT * FROM NewCLOrders
SET STATISTICS IO OFF
这样对比的原因是:很多人认为数据库优化的方式就是加上索引,并且认为查找(Seek)就比扫描好(Scan)。
这样可以肯定的堆表采用的为表扫描(Table Scan),而后者则就是通过聚集索引扫描(Index Scan)
先来看IO的两者对比:
先来看看堆表的IO信息
堆表的表现:逻辑读取20次,预读2次,这里预读次数的多少其实是影响性能的重要指标,因为它是直接从磁盘中读取,所以性能最差,当然SQL Server此处采用并行处理,而且第一次读取数之后就缓存到内存中,防止再次的磁盘交互。
再来看聚集索引表的IO信息
采用聚集索引的表,逻辑IO为23次,预读飙升至22次。
相比而言:
相同的查询语句,堆表的查询逻辑读取次数为20次、预读2次,没有物理读...,而用聚集索引的表逻辑读为23次、预读22次!还有统计信息的不准确导致的物理读取1次!....所以相比堆表的SCAN是不是性能好很多。
当然,要再深入点分析,其实这两者不同的原因很简单:采用了聚集索引的表因为其存储的结构(B-Tree)的方式,所以逻辑IO肯定要多3,因为从索引根节点至叶子节点,也就是需要经过三个索引页,才能获取到数据页。
而预读的差距这么大的原因也是同样的原因:从堆表中获取数据是一段连续的数据页(确切的说是一次连续读取64个数据页<512KB>),而这时所有加上索引的表做不到的!通过索引只能依次读取一个数据页(8KB),这也是索引的局限性。
关于查询计划的逻辑读、预读、物理读等IO详细逻辑信息,可以参照我前面的文章,分析的很详细:SQL Server调优系列进阶篇(查询语句运行几个指标值监测)
接着我们再对比下执行时间,相信这个也是更为关注的:
看明白了吧,获取完全相同的数据量,堆表执行的时候耗时157毫秒,并且分析和编译没有占用时间,这个很简单,因为它是堆表,根本不需要根据统计信息进行优化和选择;而加上聚集索引的表就不一样了,需要根据索引的统计信息对T-SQL语句进行优化和编译,而这足足耗费了79毫秒,然后执行的时候还需要更多的预读IO,还有如果优化器没有优化到位的时候,还要造成额外的物理IO,所以它总耗费了298毫秒...
在我的测试表中只有八百多行的数据中就产生了如此的差距值..如果数据量多的话...性能就堪忧了....
关于CPU和内存值我就不截图了......上面我们分析了加了聚集索引了,就产生了查询优化器一系列的过程...而编译就是需要CPU资源的.....
通过上面的结果,我要表达的是:
首先,在我们所看到的查询计划中,不要一看到表扫描,就感觉这个运算符是很慢的,或者是很耗时的。更有甚者看到了就感觉问题出现在这上面,并且为很多人所唾弃为“万恶的表扫描”....
其次,请记住,在SQL Server中你所看到的任何一个运算符,都是在目前你所设定的环境中基本是最好的....更没有那个运算符好与那个运算符烂一说...诸如偏执的认为哈希连接就比嵌套循环要快...索引查找就比索引扫描要好等问题.....我们要做的就是合适的场景运用合适的处理方式,最优的顺应SQL Server性能。
再次,经过上述了问题的分析,也不要陷入另外一个极端的误区:表扫描就要比聚集索引扫描好!后续的文章中我会给你展示聚集索引比表扫描好的用处...在SQL Server的世界中,只有你真正的触摸的本质,才不会迷茫...才会看清一切所谓的教条调优都非绝对!
关于第二个问题的误区,其实是很多人的误区,误认为了非聚集索引的强大性,误以为在列中加上了索引就可以充分应用。本篇就不纠正了,可以参照我前面的文章,相信看完了基本也就懂了非聚集索引的利弊项,连接:SQL Server调优系列进阶篇(如何索引调优)
一、GROUP 提示 (Hints)
继续咱们本篇文章的内容,上一篇我们分析了查询的几个重要的Hints,本篇文章我们来看分组提示,分组查询也是我们在写T-SQL语句经常用到的,关于分组的运算符也有两个:Order Group和Hash Group。其实关于排序一直也是数据库中最为头疼的运算。这个运算符也是消耗比较大的,相当的耗内存,如果数据量较大的话,SQL Server处理的方式也是通过哈希算法进行优化。
当然,关于分组查询运算符分解,看以参照基础篇中的文章:SQL Server调优系列基础篇(常用运算符总结)
来看个例子:
SELECT CustomerID,MAX(OrderDate)
FROM Orders
GROUP BY CustomerID
上面的查询语句,我们想获取出每个订单的最大订单日期。
通过查询计划我们可以推测出肯定在CustomerID列存在索引,这样SQL Serer能直接利用这个进行排序,但是即便如此消耗还是飙升到56%....然后通过再加上一个流聚合计算出最大订单日期。
当然,此方式也是SQL Server认为的一种最优方式,但是如果数据量多的话,此种方式将会造成内存严重的消耗。
所以,我们可以采用GROUP Hint进行提示,将其更改为Hash 分组..代码如下:
SELECT CustomerID,MAX(OrderDate)
FROM Orders
GROUP BY CustomerIDOPTION(HASH GROUP)
当然,此处可能并不是一个最优的方式,只是为了演示,但是如果基础数据量增大的话,我也相信SQL Server会自动的更改为哈希匹配的方式进行。
二、组合提示 (Hints)
大部分情况下,我们所写的T-SQL语句并不是简单的,有很多的各种嵌套查询进行,如果这种查询语句,我们的提示(Hints)就可能不是单一的。
我们来看如此方式该如何进行指导。先来看个简单的例子:
SELECT O.OrderID
FROM Customers C JOIN Orders O
JOIN Employees E
ON O.EmployeeID=E.EmployeeID
ON C.CustomerID=O.CustomerID
WHERE C.City=N'London' AND E.City=N'London'
OPTION(FORCE ORDER,HASH JOIN)
不仅仅如此,我们还可以手动给查询语句写查询计划。
也就是我们自己写的XML查询计划,让T-SQL语句就按照我们自定义的查询计划去进行,当然,这是大招了,我们留在最后使用。
参考文献
微软联机丛书逻辑运算符和物理运算符引用
参照书籍《SQL.Server.2005.技术内幕》系列
结语
此篇文章先到此吧,关于SQL Server调优工具Hint的使用还有很多内容,后续依次介绍,有兴趣的童鞋可以提前关注。
SQL Server调优(利用索引提示(Hint)引导语句最大优化运行)
前言
本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析。
闲言少叙,进入本篇的内容。
技术准备
数据库版本为SQL Server2012,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks。
相信了解SQL Server的朋友,对这两个库都不会太陌生。
一、并行Hint提示 (MAXDOP N Hint)
在当前多核超线程的今天,并行运算已经不算什么稀罕了,所以在SQL Server中也有它自己的并行运算符,来充分的利用现有硬件资源,最大限度的提升运行效率。
在本系列中有两篇文章专门介绍关于SQL Server的并行运算,可以点击查看:SQL Server并行运算总结、SQL Server并行运算总结篇二
所以,在Hint中也给出了关于并行运算的提示:MAXDOP N Hint,这个Hint还是经常用的,尤其索引操作的时候,为了缩短操作时间,我们常常会最大限度的利用并行运算。
另外,此Hint会优先于数据库级别的配置选项。也就说尽管在数据库中设置了MAXDOP 1(强制顺序运行),如果使用了此Hint也会忽略数据库设置的。
当然,并行运算虽然大部分情况能提升运行效率,但是也非绝对,我们知道多线程的操作是需要维护线程之间的数据交换和执行顺序等,所有有时候多线程的执行并不一定会单线程效率高。
来看个例子:
SELECT [KEY],[DATA]
FROM TestMaxDopTable
WHERE DATA<1000
OPTION(MAXDOP 1)
SELECT [KEY],[DATA]
FROM TestMaxDopTable
WHERE DATA<1000
OPTION(MAXDOP 4)
上面为串行运算,下面为4线程的并行运算。
当然,此处几线程运算可以自己设定,最大值推荐为当前系统配置的逻辑核数,当然设置大了也可以只不过没用罢了。
二、索引Hint提示 (INDEX Hint)
所谓的索引Hint提示,就是强制查询优化器为一个查询语句执行扫描或者使用一个指定的索引。
此方式,是我们在调优中经常用到的一种方式,很多时候我们创建的索引是失效的,当然,大部分情况下失效的原因是创建索引不妥当导致的,但是有一些情况下,需要我们来指导下T-SQL的运行方式,这时候就是索引Hint的使用场景了。
当然,这里能利用索引提示的前提就是当前表存在索引了,如果是堆表的情况,根本就谈不上了索引提示了,只能通过表扫描获取数据了。
来看看这个提示的用法:WITH(INDEX(N))
这里的N就是索引的在该表中索引顺序排序号了,来看一张表中的索引序列号:
SELECT * FROM SYS.indexes
WHERE OBJECT_NAME(object_id)='Orders'
可以看到,该表中存在十个索引,依次排序之后,就是从1至10,第一个就是聚集索引(主键)了,然后是非聚集索引。
所以,我们上面的N的值就是这个数字了,指定几就是要求用哪个索引了。
来看个脚本:
SELECT OrderID,CustomerID
FROM Orders WITH(INDEX(1))WHERE ShipPostalCode=N'99362'
SELECT OrderID,CustomerID
FROM Orders WITH(INDEX(9))WHERE ShipPostalCode=N'99362'
看到了,上面的例子中我们选了两个索引:一个编号1的聚集索引PK_Orders,一个编号为9的非聚集索引了ShipPostalCode。当然,有兴趣也可以玩玩其它几个索引。
我们顺便来分析下这个语句的索引用法:
首先从查询条件来看,我们是根据ShipPostalCode进行查询,所以最好在该列中被索引所覆盖,这样在数据量大的情况下,查询优化器就可以采用索引查找(Index Seek)了,所以,这里我们选择了第9个非聚集索引,恰巧覆盖该列值,从上面的查询计划也可以看出,采用该索引Hint提示后查询开销从69%提升至3%...但是由于这个非聚集索引没有包含CustomerID列,所以不得不又引入书签查找(key Lookup)来获取该列值,并且这个书签查找消耗还比较大:60%,所以最佳的方式就是将该索引Include进CustomerID列。
当然,此方式用起来可能很不爽,因为我们在使用的时候需要查找当前表中的各个索引的排序号。
所以,我们最推荐也是最常用的方式是这样:
WITH(INDEX('IndexName'))
就是我们直接指定索引名称既可以,来看个例子:
SELECT OrderID,CustomerID
FROM Orders WITH(INDEX(CustomersOrders))WHERE ShipPostalCode=N'99362'
看起来,简单的多了,因为索引的名字我们直接能看到,来看看我们将这个查询语句指定到这个非聚集索引CustomersOrders上的执行计划。
来看看这个查询计划:丫的!.....查询开销直接飙升到100%......原因很简单:这个非聚集索引和这个查询一毛钱关系....但是我们却强制的指定该语句利用索引执行....
首先非聚集索引包含的列为:[OrderID],[CustomerID]
我们要获取的值为按照ShipPostalCode进行筛选,所以要获取结果就必须按照这个非聚集索引进行一次扫描(Index Scan),这个还可以,毕竟非聚集索引都是有序进行的,但是为了进行过滤,就必须引入书签查找(Key Lookup)进行过滤,我们知道书签查找为随机IO,消耗巨大,所以这次过滤就好比在整张表中随机的去查找数据一样,其实效率还不如来一次表扫描(Table Scan)的好,所以此开销飙升到95%!
上面的例子,也是很多新手容易犯的错误。
我记得在玩转模块的第一篇中,我们提到过一个利用OPTIMIZE FOR Hint提示 解决一个引入参数而导致的执行计划评估不准的问题。
文章可以点击此处看到:SQL Server调优(如何利用查询提示(Hint)引导语句运行)
我们来回顾下:
--普通的查询语句
SELECT OrderID,OrderDate
FROM Orders
WHERE ShipPostalCode=N'51100'
--参数化后的查询语句
DECLARE @ShipPostalCode NVARCHAR(50)
SET @ShipPostalCode=N'51100'
SELECT OrderID,OrderDate
FROM Orders
WHERE ShipPostalCode=@ShipPostalCode
完全相同逻辑的查询语句,只是下面那个我们通过参数进行了传值操作。
我们只是加了一个参数,SQL Server将相同的查询语句,有以前的索引查找变成了索引扫描了!
消耗一下子从46%提升到54%.....这也是我们写的语句经常遇到的问题,因为很多情况下,我们都是通过传参来实现该语句的重用性。
但是,为什么加了参数使得查询性能变差,显然不是一个好的方式,在第一篇的玩转篇中,我们的解决方式是通过OPTIMIZE FOR Hint提示解决。
这里,我们再来看一个解决方式,也可以通过索引Hint来强制该语句指定按照给定的索引进行查找。
方法如下:
--参数化后的查询语句
DECLARE @ShipPostalCode NVARCHAR(50)
SET @ShipPostalCode=N'51100'
SELECT OrderID,OrderDate
FROM Orders WITH(INDEX(ShipPostalCode))WHERE ShipPostalCode=@ShipPostalCode
是不是一个很帅的方式。
希望你能理解这些个方式的好处,算作抛砖引玉了。
结语
此篇文章先到此吧,到此玩转篇已经三篇了,关于SQL Server调优工具Hint的使用还有很多内容,后续依次介绍,有兴趣的童鞋可以提前关注。
二、T-SQL
数据库范式那些事
简介
数据库范式在数据库设计中的地位一直很暧昧,教科书中对于数据库范式倒是都给出了学术性的定义,但实际应用中范式的应用却不甚乐观,这篇文章会用简单的语言和一个简单的数据库DEMO将一个不符合范式的数据库一步步从第一范式实现到第四范式。
范式的目标
应用数据库范式可以带来许多好处,但是最重要的好处归结为三点:
1.减少数据冗余(这是最主要的好处,其他好处都是由此而附带的)
2.消除异常(插入异常,更新异常,删除异常)
3.让数据组织的更加和谐…
但剑是双刃的,应用数据库范式同样也会带来弊端,这会在文章后面说到。
什么是范式
简单的说,范式是为了消除重复数据减少冗余数据,从而让数据库内的数据更好的组织,让磁盘空间得到更有效利用的一种标准化标准,满足高等级的范式的先决条件是满足低等级范式。(比如满足2nf一定满足1nf)
DEMO
让我们先从一个未经范式化的表看起,表如下:
{kind=link}
先对表做一个简单说明,employeeId是员工id,departmentName是部门名称,job代表岗位,jobDescription是岗位说明,skill是员工技能,departmentDescription是部门说明,address是员工住址
对表进行第一范式(1NF)
如果一个关系模式R的所有属性都是不可分的基本数据项,则R∈1NF。
简单的说,第一范式就是每一个属性都不可再分。不符合第一范式则不能称为关系数据库。对于上表,不难看出Address是可以再分的,比如”北京市XX路XX小区XX号”,着显然不符合第一范式,对其应用第一范式则需要将此属性分解到另一个表,如下:
{kind=link}
对表进行第二范式(2NF)
若关系模式R∈1NF,并且每一个非主属性都完全函数依赖于R的码,则R∈2NF
简单的说,是表中的属性必须完全依赖于全部主键,而不是部分主键.所以只有一个主键的表如果符合第一范式,那一定是第二范式。这样做的目的是进一步减少插入异常和更新异常。在上表中,departmentDescription是由主键DepartmentName所决定,但却不是由主键EmployeeID决定,所以departmentDescription只依赖于两个主键中的一个,故要departmentDescription对主键是部分依赖,对其应用第二范式如下表:
{kind=link}
对表进行第三范式(3NF)
关系模式R<U,F> 中若不存在这样的码X、属性组Y及非主属性Z(Z Y), 使得X→Y,Y→Z,成立,则称R<U,F> ∈ 3NF。
简单的说,第三范式是为了消除数据库中关键字之间的依赖关系,在上面经过第二范式化的表中,可以看出jobDescription(岗位职责)是由job(岗位)所决定,则jobDescription依赖于job,可以看出这不符合第三范式,对表进行第三范式后的关系图为:
{kind=link}
上表中,已经不存在数据库属性互相依赖的问题,所以符合第三范式
对表进行BC范式(BCNF)
设关系模式R<U,F>∈1NF,如果对于R的每个函数依赖X→Y,若Y不属于X,则X必含有候选码,那么R∈BCNF。
简单的说,bc范式是在第三范式的基础上的一种特殊情况,既每个表中只有一个候选键(在一个数据库中每行的值都不相同,则可称为候选键),在上面第三范式的noNf表中可以看出,每一个员工的email都是唯一的(难道两个人用同一个email??)则,此表不符合bc范式,对其进行bc范式化后的关系图为:
{kind=link}
对表进行第四范式(4NF)
关系模式R<U,F>∈1NF,如果对于R的每个非平凡多值依赖X→→Y(Y X),X都含有候选码,则R∈4NF。
简单的说,第四范式是消除表中的多值依赖,也就是说可以减少维护数据一致性的工作。对于上面bc范式化的表中,对于员工的skill,两个可能的值是”C#,sql,javascript”和“C#,UML,Ruby”,可以看出,这个数据库属性存在多个值,这就可能造成数据库内容不一致的问题,比如第一个值写的是”C#”,而第二个值写的是”C#.net”,解决办法是将多值属性放入一个新表,则第四范式化后的关系图如下:
{kind=link}
而对于skill表则可能的值为:
{kind=link}
总结
上面对于数据库范式进行分解的过程中不难看出,应用的范式等级越高,则表越多。表多会带来很多问题:
1 查询时要连接多个表,增加了查询的复杂度
2 查询时需要连接多个表,降低了数据库查询性能
而现在的情况,磁盘空间成本基本可以忽略不计,所以数据冗余所造成的问题也并不是应用数据库范式的理由。
因此,并不是应用的范式越高越好,要看实际情况而定。第三范式已经很大程度上减少了数据冗余,并且减少了造成插入异常,更新异常,和删除异常了。我个人观点认为,大多数情况应用到第三范式已经足够,在一定情况下第二范式也是可以的。
SQL查询入门(上篇)
引言
SQL语言是一门简单易学却又功能强大的语言,它能让你快速上手并写出比较复杂的查询语句。但对于大多数开发者来说,使用SQL查询数据库并没有一个抽象的过程和一个合理的步骤,这很可能会使在写一些特定的SQL查询语句来解决特定问题时被”卡”住,本系列文章主要讲述SQL查询时一些基本的理论,以及写查询语句的抽象思路。
SQL查询简介
SQL语言起源于1970年E.J.Codd发表的关系数据库理论,所以SQL是为关系数据库服务的。而对于SQL查询,是指从数据库中取得数据的子集,这句话貌似听着有些晦涩是吧,下面通过几张图片简单说明一下:
假如一个数据库中只有一个表,再假如所有数据如下图(取自AdventureWork示例数据库):
{kind=link}
而对于子集的概念,look下图:
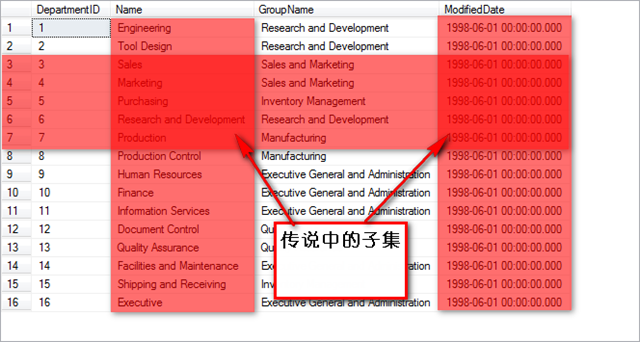{kind=link}
最后,子集如下:
{kind=link}
其实,SQL中无论多复杂的查询,都可以抽象成如上面的过程.
精确查询的前置条件
对于正确取得所需要的数据子集.除了需要思路正确并将思路正确转变为对应SQL查询语句之外。还有很重要的一点是需要数据库有着良好的设计.这里的良好设计我所指的是数据库的设计符合业务逻辑并至少实现第三范式,对于实现第三范式,这只是我个人观点.如果数据库设计很糟糕,存在很多冗余,数据库中信息存在大量异常,则即使SQL写的正确,也无法取得精确的结果。
两种方式,同一种结果
在SQL中,取得相同的数据子集可以用不同的思路或不同的SQL语句,因为SQL源于关系数据库理论,而关系数据库理论又源于数学,思考如何构建查询语句时,都可以抽象为两种方法:
1.关系代数法
关系代数法的思路是对数据库进行分步操作,最后取得想要的结果.
比如如下语句:
Select Name,Department,Age
From Employee
where Age>20
关系代数的思路描述上面语句为:对表Employee表进行投影(选择列)操作,然后对结果进行筛选,只取得年龄大于20的结果.
2.关系演算法
相比较关系代数法而言,关系演算法更多关注的是取得数据所满足的条件.上面SQL可以用关系演算法被描述为:我想得到所有年龄大于20的员工的姓名,部门和年龄。
为什么需要两种方法
对于简单的查询语句来说,上面两种方法都不需要.用脚就可以想出来了。问题在于很多查询语句都会非常复杂。对于关系演算法来说更多的是关注的是所取出信息所满足的条件,而对于关系代数法来说,更多关注的是如何取出特定的信息.简单的说,关系演算法表示的是”what”,而关系代数法表达的是”how”.SQL语句中所透漏的思路,有些时候是关系代数法,有些时候是关系演算法,还有些是两种思路的混合.
对于某些查询情况,关系代数法可能会更简单,而对于另外一些情况,关系演算法则会显得更直接.还有一些情况.我们需要混合两种思路。所以这两种思维方式在写SQL查询时都是必须的.
单表查询
单表查询是所有查询的中间状态,既是多个表的复杂查询在最终进行这种连接后都能够被抽象成单表查询。所以先从单表查询开始。
选择列的子集
根据上面数据子集的说法,选择列是通过在select语句后面添加所要选择的列名实现的:
比如下面数据库中通过在select后面选择相应的列名实现选择列的子集.
{kind=link}
相应sql语句如下:
SELECT [Name]
,[GroupName]
FROM [AdventureWorks].[HumanResources].[Department]
选择行的子集
选择行的子集是在Sql语句的where子句后面加上相应的限制条件,当where子句后面的表达式为“真”时,也就是满足所谓的“条件”时,相应的行的子集被返回。
where子句后面的运算符分为两类,分别是比较运算符和逻辑运算符.
比较运算符是将两个相同类型的数据进行比较,进而返回布尔类型(bool)的运算符,在SQL中,比较运算符一共有六种,分别为等于(=),小于(<),大于(>),小于或等于(<=),大于或等于(>=)以及不等于(<>),其中小于或等于和大于或等于可以看成是比较运算符和逻辑运算符的结合体。
而逻辑运算符是将两个布尔类型进行连接,并返回一个新的布尔类型的运算符,在SQL中,逻辑运算符通常是将比较运算符返回的布尔类型相连接以最终确定where子句后面满足条件的真假。逻辑运算符一种有三种,与(AND),或(OR),非(NOT).
{kind=link}
比如上面,我想选择第二条和第六条,为了说明比较运算符和逻辑运算符,可以使用如下Sql语句:
SELECT [Name]
,[GroupName]
FROM [AdventureWorks].[HumanResources].[Department]
WHERE DepartmentID>1 and DepartmentID<3 or DepartmentID>5 and DepartmentID<7
由此我们可以看出,这几种运算符是有优先级的,优先级由大到小排列是比较运算符>于(And)>非(Or)
当然,运算符也可以通过小括号来改变优先级,对于上面那个表
{kind=link}
对于不加括号时:
SELECT *
FROM [AdventureWorks].[HumanResources].[Department]
WHERE DepartmentID>=1 and DepartmentID<=3 and DepartmentID>=5 or DepartmentID<=7
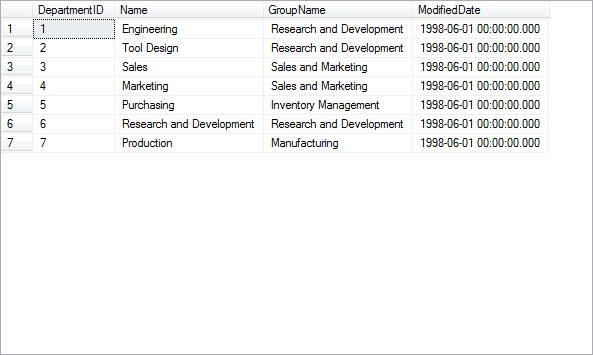{kind=link}
加了括号改变运算顺序后:
SELECT *
FROM [AdventureWorks].[HumanResources].[Department]
WHERE DepartmentID>=1 and DepartmentID<=3 and (DepartmentID>=5 or DepartmentID<=7)
{kind=link}
很特别的NULL
假如在一个用户注册的表中,一些选填信息并不需要用户必须填写,则在数据库中保存为null,这些null值在利用上面where子句后的运算符时,有可能造成数据丢失,比如一个选填信息是性别(Gender),假设下面两条条件子句:
where Gender="M"
由于null值的存在,这两条语句返回的数据行加起来并不是整个表中的所有数据。所以,当将null值考虑在内时,where后面的条件子句拥有可能的值从真和假,增加为真,假,以及未知(null)。这些是我们在现实世界中想一些问题的时候可能的答案--真的,假的,我不知道。
所以我们如何在这种情况下不丢失数据呢,对于上面的例子来说,如何才能让整个表的数据不被丢失呢,这里必须将除了“真”,“假”以外的“未知”这个选项包含在内,SQL提供了IS NULL来表明未知这个选项:
将上面语句加入进去,则不会再丢失数据。
排序结果
上面的那些方法都是关于取出数据,而下面是关于将取出的子集进行排序。SQL通过Order by子句来进行排序,Order by子句是Sql查询语句的最后一个子句,也就是说Order by子句之后不能再加任何的子句了。
Order By子句分为升序(ASC)和降序(DESC),如果不指定升序或者降序,则默认为升序(由小到大),而Order by是根据排序依据的数据类型决定,分别为3种数据类型可以进行排序:
字符
数字
时间日期
字符按照字母表进行排序,数字根据数字大小排序,时间日期根据时间的先后进行排序。
其它一些有关的
视图
视图可以看作是一个保存的虚拟表,也可以简单看做是保存的一个查询语句。视图的好处是视图可以根据视图所查询表的内容的改变而改变,打个比方来理解这句话是:
{kind=link}
使用视图的优点是可以对查询进行加密以及便于管理,据说还可以优化性能(我不认可这点).
防止重复
有时候我们对于取出的数据子集不想重复,比如你想知道一些特定的员工一共属于几个部门
SELECT [EmployeeID]
,[DepartmentID]
FROM [AdventureWorks].[HumanResources].[EmployeeDepartmentHistory]
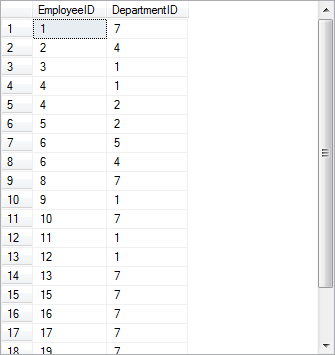{kind=link}
这样的结果是没有意义的,SQL提供了Distinct关键字来实现这点:
FROM [AdventureWorks].[HumanResources].[EmployeeDepartmentHistory]
{kind=link}
聚合函数
所谓聚合函数,是为了一些特定目的,将同一列多个值聚合为一个,比如我想知道一群人中最大年龄是多少可以利用MAX(Age),比如我想知道一个班级平均测验成绩是多少可以用AVG(Result)……
总结
文章简单概述了SQL查询的原理以及简单的单表查询,这些都是数据库查询的基础概念,对于进行复杂查询来说,弄明白这些概念是必不可少的。
SQL查询入门(中篇)
引言
在前篇文章中(SQL查询入门(上篇),我对数据库查询的基本概念以及单表查询做了详细的解释,本篇文章中,主要说明SQL中的各种连接以及使用范围,以及更进一步的解释关系代数法和关系演算法对在同一条查询的不同思路。
多表连接简介
在关系数据库中,一个查询往往会涉及多个表,因为很少有数据库只有一个表,而如果大多查询只涉及到一个表的,那么那个表也往往低于第三范式,存在大量冗余和异常。
因此,连接(Join)就是一种把多个表连接成一个表的重要手段.
比如简单两个表连接学生表(Student)和班级(Class)表,如图:
{kind=link}
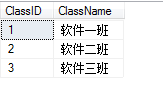{kind=link}
进行连接后如图:
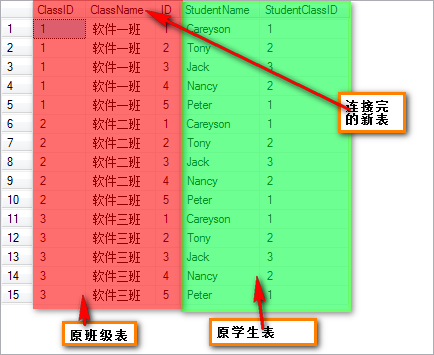{kind=link}
笛卡尔积
笛卡尔积在SQL中的实现方式既是交叉连接(Cross Join)。所有连接方式都会先生成临时笛卡尔积表,笛卡尔积是关系代数里的一个概念,表示两个表中的每一行数据任意组合,上图中两个表连接即为笛卡尔积(交叉连接)
在实际应用中,笛卡尔积本身大多没有什么实际用处,只有在两个表连接时加上限制条件,才会有实际意义,下面看内连接
内连接
如果分步骤理解的话,内连接可以看做先对两个表进行了交叉连接后,再通过加上限制条件(SQL中通过关键字on)剔除不符合条件的行的子集,得到的结果就是内连接了.上面的图中,如果我加上限制条件
对于开篇中的两个表,假使查询语句如下:
SELECT *
FROM [Class] c
[Student] s
on c.ClassID=s.StudentClassID
可以将上面查询语句进行分部理解,首先先将Class表和Student表进行交叉连接,生成如下表:
{kind=link}
然后通过on后面的限制条件,只选择那些StudentClassID和ClassID相等的列(上图中划了绿色的部分),最终,得到选择后的表的子集
{kind=link}
当然,内连接on后面的限制条件不仅仅是等号,还可以使用比较运算符,包括了>(大于)、>=(大于或等于)、<=(小于或等于)、<(小于)、!>(不大于)、!<(不小于)和<>(不等于)。当然,限制条件所涉及的两个列的数据类型必须匹配.
对于上面的查询语句,如果将on后面限制条件由等于改为大于:
SELECT *
FROM [Class] c
[Student] s
on c.ClassID>s.StudentClassID
则结果从第一步的笛卡尔积中筛选出那些ClassID大于StudentClassID的子集:
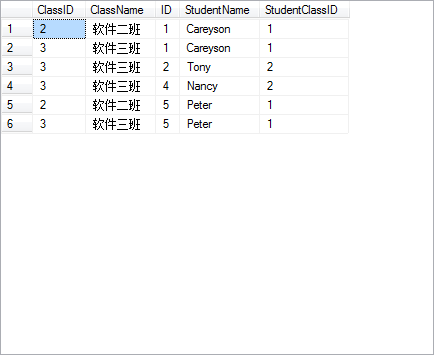{kind=link}
虽然上面连接后的表并没有什么实际意义,但这里仅仅作为DEMO使用:-)
关系演算
上面笛卡尔积的概念是关系代数中的概念,而我在前一篇文章中提到还有关系演算的查询方法.上面的关系代数是分布理解的,上面的语句推导过程是这样的:“对表Student和Class进行内连接,匹配所有ClassID和StudentClassID相等行,选择所有的列”
而关系演算法,更多关注的是我想要什么,比如说上面同样查询,用关系演算法思考的方式是“给我找到所有学生的信息,包括他们的班级信息,班级ID,学生ID,学生姓名”
用关系演算法的SQL查询语句如下:
SELECT *
FROM [Class] c
,
[Student] s
where c.ClassID=s.StudentClassID
当然,查询后返回的结果是不会变的:
外连接
假设还是上面两个表,学生和班级.我在学生中添加一个名为Eric的学生,但出于某种原因忘了填写它的班级ID:
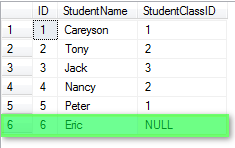{kind=link}
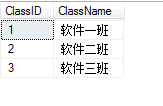{kind=link}
当我想执行这样一条查询:给我取得所有学生的姓名和他们所属的班级:
SELECT s.StudentName,c.ClassName
FROM [fordemo].[dbo].[Student] s
[fordemo].[dbo].[Class] c
s.StudentClassID=c.ClassID
结果如下图:
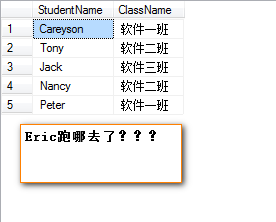{kind=link}
可以看到,这个查询“丢失”了Eric..
这时就需要用到外连接,外连接可以使连接表的一方,或者双方不必遵守on后面的连接限制条件.这里把上面的查询语句中的inner join改为left outer join:
SELECT s.StudentName,c.ClassName
FROM [fordemo].[dbo].[Student] s
[fordemo].[dbo].[Class] c
s.StudentClassID=c.ClassID
结果如下:
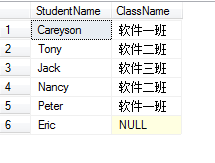{kind=link}
Eric又重新出现.
右外连接
右外连接和左外连接的概念是相同的,只是顺序不同,对于上面查询语句,也可以改成:
SELECT s.StudentName,c.ClassName
FROM [fordemo].[dbo].[Class] c
[fordemo].[dbo].[Student] s
s.StudentClassID=c.ClassID
效果和上面使用了左外连接的效果是一样的.
全外连接
全外连接是将左边和右边表每行都至少输出一次,用关键字”full outer join”进行连接,可以看作是左外连接和右外连接的结合.
自连接
谈到自连接,让我们首先从一个表和一个问题开始:
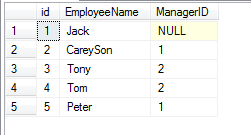{kind=link}
上面员工表(Employee),因为经理也是员工的一种,所以将两种人放入一个表中,MangerID字段表示的是当前员工的直系经理的员工id.
现在,我的问题是,如何查找CareySon的经理的姓名?
可以看出,虽然数据存储在单张表中,但除了嵌套查询(这个会在后续文章中讲到),只有自连接可以做到.正确自连接语句如下:
SELECT m.EmployeeName
FROM [fordemo].[dbo].[Employee] e
inner join [fordemo].[dbo].[Employee] m
on e.ManagerID=m.id and e.EmployeeName='Careyson'
在详细解释自连接的概念之前,请再看一个更能说明自连接应用之处的例子:
{kind=link}
这个表是一个出席会议记录的表,每一行表示出席会议的记录(这里,由于表简单,我就不用EmployeeID和MeetingID来表示了,用名称对于理解表更容易些)
好了,现在我的问题是:找出既参加“谈论项目进度”会议,又参加”讨论职业发展”会议的员工
乍一看上去很让人迷惑是吧,也许你看到这一句脑中第一印象会是:
SELECT EmployeeName
FROM [fordemo].[dbo].[MeettingRecord] m
where MeetingName='¨¬??????????¨¨' and meetingName='¨¬????¡ã¨°¦Ì¡¤¡é?1'
(我用的代码高亮插件不支持中文,所以上面where子句后面第一个字符串是’谈论项目进度’,第二个是’讨论职业发展’)
恩,恭喜你,答错了…如果这样写将会什么数据也得不到.正确的写法是使用自连接!
自连接的是一种特殊的连接,是对物理上相同但逻辑上不相同的表进行连接的方式。我看到百度百科上说自连接是一种特殊的内连接,但这是错误的,因为两个相同表之间不光可以内连接,还可以外连接,交叉连接…在进行自连接时,必须为其中至少一个表指定别名以对这两个表进行区分!
回到上面的例子,使用自连接,则正确的写法为:
SELECT m.EmployeeName
FROM [fordemo].[dbo].[MeettingRecord] m,
[fordemo].[dbo].[MeettingRecord] m2
where m.MeetingName='¨¬??????????¨¨' and m2.MeetingName='¨¬????¡ã¨°¦Ì¡¤¡é?1'
and m.EmployeeName=m2.EmployeeName
(关于乱码问题,请参考上面)
多表连接
多个表连接实际上可以看成是对N个表进行n-1次双表连接.这样理解会让问题简单很多!
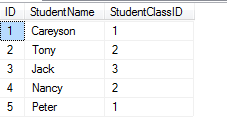{kind=link}
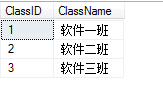{kind=link}
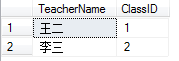{kind=link}
比如上面三个表,前两个表是我们已经在文章开始认识的,假设现在又添加了一个教师表,对这三个表进行笛卡尔积如下:
SELECT *
FROM [fordemo].[dbo].[Class]
[fordemo].[dbo].[Teacher]
[fordemo].[dbo].[Student]
结果可以如图表示:
{kind=link}
总结
文中对SQL中各种连接查询方式都做了简单的介绍,并利用一些Demo实际探讨各种连接的用处,掌握好各种连接的原理是写好SQL查询所必不可少的!
SQL查询入门(下篇)
引言
在前两篇文章中,对于单表查询和多表查询的概念做出了详细的介绍,在本篇文章中会主要介绍聚合函数的使用和数据的分组.
简介
简单的说,聚合函数是按照一定的规则将多行(Row)数据汇总成一行的函数。对数据进行汇总前,还可以按照特定的列(column)将数据进行分组(Group by)再汇总,然后按照再次给定的条件进行筛选(Having).
聚合函数将多行数据进行汇总的概念可以简单用下图解释:
简单聚合函数
简单聚合函数是那些拥有很直观将多行(Row)汇总为一行(Row)计算规则的函数。这些函数往往从函数名本身就可以猜测出函数的作用,而这些函数的参数都是数字类型的。简单聚合函数包括:Avg,Sum,Max,Min.
简单聚合函数的参数只能是数字类型,在SQL中,数字类型具体包括:tinyint,smallint,int,bigint,decimal,money,smallmoney,float,real.
在介绍简单聚合函数之前,先来介绍一下Count()这个聚合函数.
Count()
Count函数用于计算给定条件下所含有的行(Row)数.例如最简单的:
{kind=link}
上表中,我想知道公司员工的个数,可以简单的使用:
SELECT COUNT(*) AS EmployeeNumberFROM HumanResources.Employee
结果如下
{kind=link}
当Count()作用于某一特定列(Column),和以“*”作为参数时的区别是当Count(列名)碰到“Null”值时不会将其计算在内,例如:
我想知道公司中有上级的员工个数:
SELECT COUNT(ManagerID) AS EmployeeWithSuperiorFROM HumanResources.Employee
{kind=link}
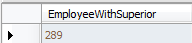{kind=link}
可以看到,除了没有上级的CEO之外,所有其他的员工已经被统计在内.
也可以在Count()内使用Distinct关键字来让,每一列(Column)的每个相同的值只有一个被统计在内,比如:
我想统计公司中经理层级的数量:
SELECT COUNT(DISTINCT ManagerID) AS NumberOfManagerFROM HumanResources.Employee
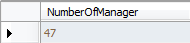{kind=link}
结果如上.
Avg(),Sum(),Max()和Min()
这几个聚合函数除了功能不同以外,参数和用法几乎相同。所以这里只对Avg()这个聚合函数进行解释:
Avg()表示计算在选择范围内的汇总数据的平均值.这个过程中“Null”值不会被统计在内 ,例如:
我想获得平均每位员工休假的时长:
SELECT AVG(VacationHours) AS 'Average vacation hours'FROM HumanResources.Employee
结果如下:
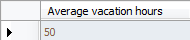{kind=link}
因为默认用聚合函数进行数据汇总时,不包含null,但如果我想要包含null值,并在当前查询中将Null值以其他值替代并参与汇总运算时,使用IsNull(column,value)
例如:
我想获得平均每位员工的休假时长,如果员工没有休假,则按休假10个小时计算
SELECT AVG(ISNULL(VacationHours, 10)) AS 'Average vacation hours'FROM HumanResources.Employee
结果如下:
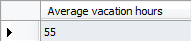{kind=link}
也可以使用DISTINCT关键字在简单聚合函数中让每一个值唯一参与聚合汇总运算.在上面的Count函数中已经解释,这里不做重复。
而关于Sum(),Max(),Min()等这些简单聚合函数,使用方法基本相同,这里就不重复了
将聚合函数得到的值按照列(Column)进行分组
如果聚合函数所得到的结果无法按照特定的值进行分组,那聚合函数的作用就没那么强了。在SQL中,使用Group by对聚合函数汇总的值进行分组。分组的概念可以下面这个简单的例子表示:
例如:
我想根据不同省得到销售人员所销售的总和:
SELECT TerritoryID, SUM(SalesLastYear) AS ToTalSalesFROM Sales.SalesPersonGROUP BY TerritoryID
概念如下图所示:
跟在Group by后面的列名是分组的依据。当然在某些情况下,会有依据多个列(Column)进行分组的情况.下面这个例子有点实际意义:
我想按照不同性别获得不同经理手下的员工的病假时间总和:
SELECT ManagerID, Gender, SUM(SickLeaveHours) AS SickLeaveHours, COUNT(*) AS EmployeeNumberFROM HumanResources.EmployeeGROUP BY Gender, ManagerID
结果如下:
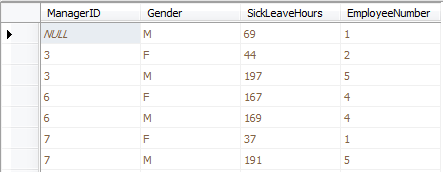{kind=link}
Group By后面多列,我们可以在逻辑思维上这么想,先根据每一列唯一的ManagerId和唯一的Gender进行Cross Join(如果你不懂什么Cross join,请看我前面的文章)得到唯一可以确定其他键(Key)的键,最后过滤掉聚合函数中不能返回值的行(Row)(也就是为Null)的行。再根据这实际上两列,但逻辑上是一列的值作为分组依据。
上图中可以看到,我们首先按照经理ID,进行分组,然后根据不同经理手下的员工的性别,再次进行分总,最终按照这个分组条件得到病假时间总和.
这里要注意,当使用Group By按照多列(Column)进行分组时,一定要注意出现在Group By后面的次序
上面先出现Gender是先遍历Gender的所有可能的值,再根据每个Gender可能的值去计算匹配ManagerID,最后再根据ManagerID来进行聚合函数运算,如果将上面Group By后面得列(Column)顺序改为先ManagerId,再Gender,则意味着先遍历ManagerID所有可能出现的值,再去匹配Gender,则结果如下:
{kind=link}
从Gender(性别)变为M(男性)开始,第二次遍历ManagerId进行匹配:
{kind=link}
从上面我们可以看出,虽然Group by后面出现列(Column)的次序不同,所得到结果的顺序也不同,但所得到的数据集(DataSet)是完全一样,所以,可以通过Order By子句将按照不同列次序进行Group By的查询语句获得相同的结果。这里就不再截图了。
对分组完成后的数据集进行再次筛选(Having)
当对使用聚合函数进行分组后,可以再次使用放在Group By子句后的Having子句对分组后的数据进行再次的过滤.Having子句在某些方面很像Where子句,具体having表达式的使用可以看我前面文章中对where的讲解。Having子句可以理解成在分组后进行二次过滤的语句.
使用having子句非常简单,但需要注意的是,having子句后面不能跟在select语句中出现的别名,而必须将Select语句内的表达式再写一遍,例如还是针对上面的表:
我想按照不同性别获得不同经理手下的员工的病假时间总和,这些经理手下的员工需要大于2个人:
SELECT ManagerID, Gender, SUM(SickLeaveHours) AS SickLeaveHours, COUNT(*) AS EmployeeNumberFROM HumanResources.EmployeeGROUP BY ManagerID, GenderHAVING (EmployeeNumber > 2)
注意,上面这句话是错误的,在Having子句后面不能引用别名或者变量名,如果需要实现上面那个效果,需要将Count(*)这个表达式再Having子句中重写一遍,正确写法如下:
SELECT ManagerID, Gender, SUM(SickLeaveHours) AS SickLeaveHours, COUNT(*) AS EmployeeNumberFROM HumanResources.EmployeeGROUP BY ManagerID, GenderHAVING (COUNT(*) > 2)
结果如下:
{kind=link}
我们看到,只有员工数大于2人的条件被选中。
当然,Having子句最强大的地方莫过于其可以使用聚合函数作为表达式,这是在Where子句中不允许的。下面这个例子很好的演示了Having子句的强大之处:
还是上面那个例子的数据:
我想获得不同经理手下的员工的病假时间总和,并且这个经理手下病假最多的员工的请假小时数大于病假最少员工的两倍:
SELECT ManagerID, SUM(SickLeaveHours) AS TotalSickLeaveHours, COUNT(*) AS EmployeeNumberFROM HumanResources.EmployeeGROUP BY ManagerIDHAVING (MAX(SickLeaveHours) > 2 * MIN(SickLeaveHours))
结果如下:
{kind=link}
这里可以看出,Having子句实现如此简单就能实现的强大功能,如果用where将会非常非常的麻烦。上面那个结果中,having语句聚合函数的作用范围可以用下图很好的演示出来:
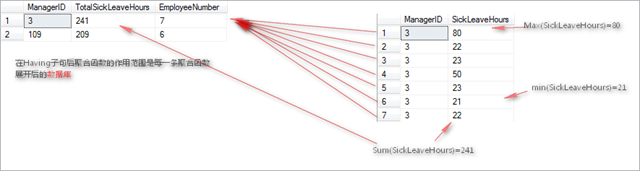{kind=link}
上面可以看出被筛选后的数据满足请假最多员工的小时数明显大于请假最少员工小时数的两倍。
小结
本文以聚合函数概念为开始,讲述了聚合函数使用中经常用到的查询,分组,过滤的概念和使用方式。使用好聚合函数可以将很多放到应用程序业务层的任务转到数据库里来.这会对维护和性能提升很很大的帮助.
T-SQL查询进阶--深入理解子查询
引言
SQL有着非常强大且灵活的查询方式,而多表连接操作往往也可以用子查询进行替代,本篇文章将会讲述子查询的方方面面。
简介
子查询本质上是嵌套进其他SELECT,UPDATE,INSERT,DELETE语句的一个被限制的SELECT语句,在子查询中,只有下面几个子句可以使用
SELECT子句(必须)
FROM子句(必选)
WHERE子句(可选)
GROUP BY(可选)
HAVING(可选)
ORDER BY(只有在TOP关键字被使用时才可用)
子查询也可以嵌套在其他子查询中,这个嵌套最多可达32层。子查询也叫内部查询(Inner query)或者内部选择(Inner Select),而包含子查询的查询语句也叫做外部查询(Outter)或者外部选择(Outer Select),子查询的概念可以简单用下图阐述:
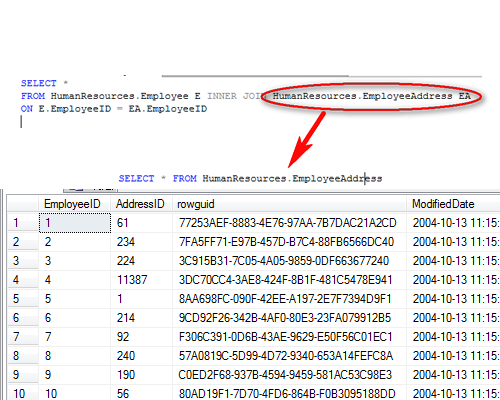{kind=link}
上图是作为数据源使用的一个子查询.
通常来讲,子查询按照子查询所返回数据的类型,可以分为三种,分别为:
返回一张数据表(Table)
返回一列值(Column)
返回单个值(Scalar)
下面,我们按照这三种方式来阐述子查询
子查询作为数据源使用
当子查询在外部查询的FROM子句之后使用时,子查询被当作一个数据源使用,即使这时子查询只返回一个单一值(Scalar)或是一列值(Column),在这里依然可以看作一个特殊的数据源,即一个二维数据表(Table).作为数据源使用的子查询很像一个View(视图),只是这个子查询只是临时存在,并不包含在数据库中。
比如这个语句:
SELECT P.ProductID, P.Name, P.ProductNumber, M.Name AS ProductModelNameFROM Production.Product AS P INNER JOIN
(SELECT Name, ProductModelID
FROM Production.ProductModel) AS M ON P.ProductModelID = M.ProductModelID
上述子查询语句将ProductModel表中的子集M,作为数据源(表)和Product表进行内连接。结果如下:
{kind=link}
作为数据源使用也是子查询最简单的应用。当然,当子查询作为数据源使用时,也分为相关子查询和无关子查询,这会在文章后面介绍到.
子查询作为选择条件使用
作为选择条件的子查询也是子查询相对最复杂的应用.
作为选择条件的子查询是那些只返回一列(Column)的子查询,如果作为选择条件使用,即使只返回单个值,也可以看作是只有一行的一列.比如:
在AdventureWorks中:
我想取得总共请病假天数大于68小时的员工:
SELECT [FirstName]
,[MiddleName]
,[LastName]
FROM [AdventureWorks].[Person].[Contact]
(SELECT EmployeeID
FROM [AdventureWorks].[HumanResources].[Employee]
WHERE SickLeaveHours>68)
结果如下:
上面的查询中,在IN关键字后面的子查询返回一列值作为外部查询的选择条件使用.
同样的,与IN关键字的逻辑取反的NOT IN关键字,这里就不再阐述了
但是要强调的是,不要用IN和NOT IN关键字,这会引起很多潜在的问题,这篇文章对这个问题有着很好的阐述:http://wiki.lessthandot.com/index.php/Subquery_typo_with_using_in。这篇文章的观点是永远不要再用IN和NOT IN关键字,我的观点是存在即合理,我认为只有在IN里面是固定值的时候才可以用IN和NOT IN,比如:
SELECT [FirstName]
,[MiddleName]
,[LastName]
FROM [AdventureWorks].[Person].[Contact]
只有在上面这种情况下,使用IN和NOT IN关键字才是安全的,其他情况下,最好使用EXISTS,NOT EXISTS,JOIN关键字来进行替代. 除了IN之外,用于选择条件的关键字还有ANY和ALL,这两个关键字和其字面意思一样. 和"<",">",”="连接使用,比如上面用IN的那个子查询:
我想取得总共请病假天数大于68小时的员工
用ANY关键字进行等效的查询为:
SELECT [FirstName]
,[MiddleName]
,[LastName]
FROM [AdventureWorks].[Person].[Contact]
(SELECT EmployeeID
FROM [AdventureWorks].[HumanResources].[Employee]
WHERE SickLeaveHours>68)
在作为ANY和ALL关键字在子查询中使用时,所实现的效果如下
| =ANY |
和IN等价 |
| <>ALL |
和NOT IN等价 |
| >ANY |
大于最小的(>MIN) |
| <ANY |
小于最大的(<MAX) |
| >ALL |
大于最大的(>MAX) |
| <ALL |
小于最小的(<MIN) |
| =ALL |
下面说 |
=ALL关键字很少使用,这个的效果在子查询中为如果只有一个返回值,则和“=”相等,而如果有多个返回值,结果为空
这里要注意,SQL是一种很灵活的语言,就像子查询所实现的效果可以使用JOIN来实现一样(效果一样,实现思路不同),ANY和ALL所实现的效果也完全可以使用其他方式来替代,按照上面表格所示,>ANY和>MIN完全等价,比如下面两个查询语句完全等价:
SELECT *FROM AdventureWorks.HumanResources.EmployeeWHERE SickLeaveHours>ANY
(SELECT SickLeaveHours FROM AdventureWorks.HumanResources.Employee WHERE SickLeaveHours>68)
SELECT *FROM AdventureWorks.HumanResources.EmployeeWHERE SickLeaveHours>
(SELECT MIN(SickLeaveHours) FROM AdventureWorks.HumanResources.Employee WHERE SickLeaveHours>68)
相关子查询和EXISTS关键字
前面所说的查询都是无关子查询(Uncorrelated subquery),子查询中还有一类很重要的查询是相关子查询(Correlated subquery),也叫重复子查询比如,还是上面那个查询,用相关子查询来写:
我想取得总共请病假天数大于68天的员工:
SELECT [FirstName]
,[MiddleName]
,[LastName]
FROM [AdventureWorks].[Person].[Contact] c
(SELECT *
FROM [AdventureWorks].[HumanResources].[Employee] e
WHERE c.ContactID=e.ContactID AND e.SickLeaveHours>68)
结果和使用IN关键字的查询结果相同:
如何区别相关子查询和无关子查询呢?最简单的办法就是直接看子查询本身能否执行,比如上面的例子中的子查询:
(SELECT *
FROM [AdventureWorks].[HumanResources].[Employee] e
WHERE c.ContactID=e.ContactID AND e.SickLeaveHours>68)
这一句本身执行本身会报错.因为这句引用到了外部查询的表
对于无关子查询来说,整个查询的过程为子查询只执行一次,然后交给外部查询,比如:
SELECT *FROM AdventureWorks.HumanResources.EmployeeWHERE SickLeaveHours>ANY
SQLRESULT
上面的无关子查询,整个查询过程可以看作是子查询首先返回SQLResult(SQL结果集),然后交给外部查询使用,整个过程子查询只执行一次
而相反,作为相关子查询,子查询的执行的次数依赖于外部查询,外部查询每执行一行,子查询执行一次,比如:
还是上面的例子:我想取得总共请病假天数大于68天的员工
SELECT [FirstName]
,[MiddleName]
,[LastName]
FROM [AdventureWorks].[Person].[Contact] c
(SELECT *
FROM [AdventureWorks].[HumanResources].[Employee] e
WHERE c.ContactID=e.ContactID AND e.SickLeaveHours>68)
----
step 1:SELECT [FirstName]
,[MiddleName]
,[LastName]
FROM [AdventureWorks].[Person].[Contact] c
(SELECT *
FROM [AdventureWorks].[HumanResources].[Employee] e
WHERE 1=e.ContactID AND e.SickLeaveHours>68)----
step 2:SELECT [FirstName]
,[MiddleName]
,[LastName]
FROM [AdventureWorks].[Person].[Contact] c
(SELECT *
FROM [AdventureWorks].[HumanResources].[Employee] e
WHERE 2=e.ContactID AND e.SickLeaveHours>68)----
step n:SELECT [FirstName]
,[MiddleName]
,[LastName]
FROM [AdventureWorks].[Person].[Contact] c
(SELECT *
FROM [AdventureWorks].[HumanResources].[Employee] e
WHERE n=e.ContactID AND e.SickLeaveHours>68)
如上面代码所示。上面的相关子查询实际上会执行N次(N取决与外部查询的行数),外部查询每执行一行,都会将对应行所用的参数传到子查询中,如果子查询有对应值,则返回TRUE(既当前行被选中并在结果中显示),如果没有,则返回FALSE。然后重复执行下一行。
子查询作为计算列使用
当子查询作为计算列使用时,只返回单个值(Scalar) 。用在SELECT语句之后,作为计算列使用。同样分为相关子查询和无关子查询
相关子查询的例子比如:我想取得每件产品的名称和总共的销量
SELECT [Name],
(SELECT COUNT(*) FROM AdventureWorks.Sales.SalesOrderDetail S
WHERE S.ProductID=P.ProductID) AS SalesAmountFROM [AdventureWorks].[Production].[Product] P
部分结果如下:
{kind=link}
当子查询作为计算列使用时,会针对外部查询的每一行,返回唯一的值。
同样的,SQL子查询都可以使用其他语句达到同样的效果,上面的语句和如下语句达到同样的效果:
SELECT P.Name,COUNT(S.ProductID)FROM [AdventureWorks].[Production].[Product] P LEFT JOIN AdventureWorks.Sales.SalesOrderDetail SON S.ProductID=P.ProductIDGROUP BY P.Name
子查询作为计算列且作为无关子查询时使用,只会一次性返回但一值,这里就不再阐述了。
小结
本篇文章通过子查询的三种不同用途来阐述子查询。同时,所有的子查询还可以分为相关子查询和无关子查询,而子查询所实现的功能都可以使用连接或者其他方式实现。但一个好的作家应该是掌握丰富的词汇,而不是仅仅能表达出自己的意思。学会多种SQL查询方式是学习SQL查询必经之路。
T-SQL查询进阶--基于列的逻辑表达式
引言
T-SQL不仅仅是一个用于查询数据库的语言,还是一个可以对数据进行操作的语言。基于列的CASE表达式就是其中一种,不像其他查询语句可以互相替代(比如用子查询实现的查询也可以使用Join实现),CASE表达式在控制基于列的逻辑大部分是无法替代的。下面文中会详细讲解CASE表达式。
简介
基于列的逻辑表达式,其实就是CASE表达式.可以用在SELECT,UPDATE,DELETE,SET以及IN,WHERE,ORDER BY和HAVING子句之后。由于这里讲的是T-SQL查询,所以只说到CASE表达式在SELECT子句和ORDER BY子句中的使用。
CASE表达式实现的功能类似于编程语言中的IF…THEN…ELSE逻辑。只是CASE表达式在T-SQL中并不能控制T-SQL程序的流程,只是作为基于列的逻辑使用.
一个简单的CASE表达式如下:
我已经知道员工ID对应的姓名,我想获得员工ID,并将员工ID以姓名的方式展现出来,我不知道的员工ID则显示UNKNOW:
ELSE 'UNKNOW'
FROM [AdventureWorks].[HumanResources].[Employee]
显示结果如下:
上面代码中,CASE后面跟选择的列名,后面的WHEN所取得值都为EmployeeID这一列,THEN后面的值为对应前面WHEN后面列中,实际在结果中显示的值。
CASE表达式实际情况可以分为两种:
CASE简单表达式(CASE Simple Expression):将某个表达式与一组简单表达式进行比较以确定结果。
CASE 搜索表达式(CASE Searched Expression):计算一组布尔表达式以确定结果。
下面会按照这两种CASE表达式来阐述
CASE简单表达式(CASE Simple Expression)
在CASE简单表达式中,整个表达式只会取一列的值做相应的判断,上面那个查询例子就是一个CASE简单表达式,可以用下图表示:
{kind=link}
CASE表达式也可以用这样的写法:
SELECT TOP 4 NameList=CASE EmployeeID
ELSE 'UNKNOW'
END,EmployeeID
FROM [AdventureWorks].[HumanResources].[Employee]
上面代码和前面代码所达到的效果是一模一样的,从这个代码可以看出,CASE表达式的结果实际上只局限在一列当中,这也是为什么CASE表达式是“基于列的逻辑表达式”
因为CASE表达式的值只局限在一列当中,所以THEN后面的值数据类型必须相同,或者兼容,否则就会报错。
在上面语句中,还有一个可选的“ELSE”语句,这个语句可以省略,但最好的做法是保留ELSE,否则不在匹配值范围内的所有值都会为“NULL”。
CASE搜索表达式(CASE Searched Expression)
与CASE简单表达式不同,CASE搜索表达式提供了更强大的功能,CASE搜索表达式不仅可以使用更复杂的逻辑表达式,并且还能根据多列中的数据确定所显示列的值。与上面CASE简单表达式等效的CASE搜索表达式为:
WHEN EmployeeID=1 THEN 'CareySon'
ELSE 'UNKNOW'
END,EmployeeID
FROM [AdventureWorks].[HumanResources].[Employee]
CASE搜索表达式更复杂的应用比如:
公司规定每个人病假或者休假每年都不应该超过30个小时,现在我想取得所有男性员工的ID,其中员工病假或者是休假任意一项超过了30个小时,标记为“Exceed the time”,两项都不超过30个小时的,标记为“Not Exceed the time”
SELECT EmployeeID,
WHEN VacationHours>30 AND Gender='M' THEN 'Exceed The Time'
WHEN SickLeaveHours>30 AND Gender='M' THEN 'Exceed The Time'
ELSE 'Not Exceed The Time'
FROM [AdventureWorks].[HumanResources].[Employee]
查询结果如下:
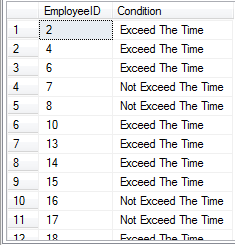{kind=link}
上面可以看到,搜索表达式一列的WHEN表达式可以取自不同列,甚至是不同列之间的运算(比如上面可以取WHEN VacationHours+SickLeaveHours>60),这大大增强了CASE表达式的功能,因为CASE搜索表达式可以完全实现CASE简单表达式所能实现的功能,我个人认为所有的CASE表达式都应该写成CASE搜索表达式的形式。
还有要注意WHEN…THEN是以先后顺序出现,当第一个WHEN后面的表达式为FALSE时,则会去看第二个WHEN后的表达式,依次类推。当第一个WHEN后的表达式为TRUE时,则取第一个THEN后面的值,即使第二个WHEN表达式也为TRUE。
例如还是第一个例子:我已经知道员工ID对应的姓名,我想获得员工ID,并将员工ID以姓名的方式展现出来,我不知道的员工ID则显示UNKNOW:
WHEN EmployeeID=1 THEN 'CareySon'
ELSE 'UNKNOW'
END,EmployeeID
FROM [AdventureWorks].[HumanResources].[Employee]
结果如下:
{kind=link}
CASE表达式在ORDER BY中的使用
CASE表达式在ORDER BY中可以将排序结果分类,使符合某些条件的行(Row)采用一种排序方式,符合另一种条件的行采用另一种排序方式:
比如:我想查看省份ID为8和9的员工的地址,当省份ID为9时,按照AddressID降序排列,当省份ID为8时,按照AddressID升序排列
SELECT [AddressID]
,[AddressLine1]
,[City]
,[StateProvinceID]
FROM [AdventureWorks].[Person].[Address]WHERE StateProvinceID=9 OR StateProvinceID=8ORDER BY
CASE WHEN StateProvinceID=9 THEN AddressID END DESC,
CASE WHEN StateProvinceID=8 THEN AddressID END
结果如下:
{kind=link}
注意这里,每一条排序规则都要写一个单独的CASE表达式,前面文章说了,因为CASE表达式是基于列的,一个CASE表达式只能返回一个值,所以基于多少个值排序,则需要多少个CASE表达式
总结
文章讲述了CASE表达式在SELECT子句中和ORDER BY子句中的使用,CASE表达式又进一步分为CASE简单表达式和CASE搜索表达式。掌握使用CASE表达式可以使程序员将一部分需要在程序中的业务逻辑移到数据库中。掌握CASE表达式是深入学习T-SQL查询必不可少的。
T-SQL查询进阶--流程控制语句
概述
和其他高级语言一样,T-SQL中也有用于控制流程的语句。T-SQL中的流程控制语句进一步扩展了T-SQL的力量……使得大部分业务逻辑可以在数据库层面进行。但很多人对T-SQL中的流程控制语句并没有系统的了解,本篇文章会系统的对T-SQL语句中的流程控制语句进行系统讲解。
基本概念
在没有流程控制语句的情况下,T-SQL语句是按照从上到下的顺序逐个执行:
{kind=link}
使用流程控制语句可以让开发人员可以基于某些逻辑进行选择性的跳转,实现了类似高级语言的跳转结构:
{kind=link}
流程控制语句的使用范围和GO关键字
流程控制语句只能在单个批处理段(Batch),用户自定义函数和存储过程中使用。不能跨多个批处理段或者用户自定义函数和存储过程。
因为这里重点讲到T-SQL查询语句,所以这里只讲批处理段(Batch).
一个批处理段是由一个或者多个语句组成的一个批处理,之所以叫批处理是因为所有语句一次性被提交到一个SQL实例。在这个批处理范围内,局部变量是互相可见的。
而想让多个语句分多次提交到SQL实例,则需要使用GO关键字。GO关键字本身并不是一个SQL语句,GO关键字可以看作是一个批处理结束的标识符,当遇到GO关键字时,当前GO之前的语句会作为一个批处理直接传到SQL实例执行。所以不在同一个批处理内局部变量不可见,也不可对跨批处理的语句使用流程控制语句.
在同一个批处理中局部变量互相可见:
在不同批处理中局部变量不可见:
在不同批处理中,流程控制语句不能跨批处理:
T-SQL中的8个流程控制语句关键字
在T-SQL中,与流程控制语句相关的关键字有8个:
| BEGIN...END |
BREAK |
| GOTO |
CONTINUE |
| IF...ELSE |
WHILE |
| RETURN |
WAITFOR |
下面对上述关键字进行挨个讲解
BEGIN…END关键字
BEGIN…END关键字也是流程控制语句需要用到的最基本关键字,用于将多个语句划分成逻辑上的一部分。其实可以直接理解成类C语言中的花括号(“{}"“)
{kind=link}
WHILE/BREAK/CONTINUE关键字
在T-SQL的流程控制语句中,循环语句只有WHILE循环,并没有传统高级语言的FOR和SWITCH循环。WHILE除了被用于流程控制语句的循环之外,还经常被用于游标之中。
WHILE关键字和高级语言中的WHILE关键字几乎完全一样。WHILE循环中可以利用BREAK和CONTINUE关键字对循环进行控制。
CONTINUE关键字用于结束本次循环,直接开始下一次循环。
BREAK关键字用于直接跳出WHILE循环语句。
这里值得注意的是,当WHILE循环嵌套时,CONTINUE关键字和BREAK关键字只会作用于它们所处的WHILE循环之内,不会对外部WHILE循环产生作用。
一个简单的例子如下:从1循环到10,当循环到7时,结束本次循环并继续,当循环到8时,跳出循环
IF..ELSE关键字
IF..ELSE关键字实现了非此既彼的逻辑。和高级语言中的IF..ELSE具有完全一样的使用方法,这里就不再讲述了,例子参看上图。
还有要注意的是IF经常会和EXISTS关键字相结合来查看数据表中指定的数据是否存在,比如:
我想查询员工中没有上级的人,如果有这个人,则输出“XXX is our boss”,如果没有,则输出"There is no infomation about our boss”
GOTO关键字
GOTO关键字因为能打乱程序的整个流程而在高级语言中臭名卓著。GOTO关键字的使用非常简单,定义一个跳转标签,只要GOTO 标签名就可以。如果说一定要使用GOTO关键字的话,最佳实践是只使用在错误处理上,比如:
RETURN关键字
Return是最简单有效直接无条件告诉服务器跳出某个批处理段(Batch),用户自定义函数和存储过程的方式。在同一个批处理中Return关键字直接截止当前Return所在的批处理(Batch),批处理有关概念请参考前面GO关键字那一节.
简单的Return概念如下例子:
在存储过程中,Return语句后面可以返回数字用于返回执行状态或者错误代码。
很多人会把Return语句和RAISERROR函数搞混,区别在于RAISERROR函数会引发错误,并且程序依然会往下执行:
WAITFOR关键字
WAITFOR关键字允许指定语句在特定时间或是推迟特定时间执行。
推迟等待和在特定时间执行的语法分别是WAITFOR DELAY ‘需要等待的执行时间',WAITFOR TIME ‘需要执行程序的精确时间’
简单的语法例子如下:
WAITFOR的功能可以实现更为复杂的业务逻辑,比如:
我想开始一项促销活动,在当前时间10小时后开始,为8折,20小时后结束,变为9折:
总结
本篇文章从T-SQL查询的角度讲解了流程控制语句的8个关键字。利用好这些关键字是掌握复杂T-SQL查询的必要条件。
T-SQL查询进阶--变量
概述
变量对于一种语言是必不可少的一部分,当然,对于T-SQL来讲也是一样。在简单查询中,往往很少用到变量,但无论对于复杂的查询或存储过程中,变量都是必不可少的一部分.
变量的种类
在T-SQL中,变量按生存范围可以分为全局变量(Global Variable)和局部变量(Local Variable).
1.全局变量是由系统定义的,在整个SQL SERVER实例内都能访问到的变量.全局变量以@@作为第一个字符,用户只能访问,不能赋值。
2.局部变量由用户定义,生命周期只在一个批处理内有效。局部变量以@作为第一个字符,由用户自己定义和赋值。
一个简单的例子如下
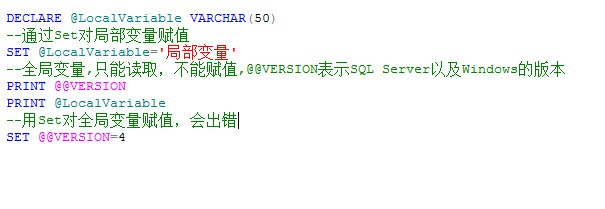{kind=link}
因为全局变量仅仅是用于读取系统的一些参数,具体每个全局变量所代表的含义请Google之…本文主要介绍局部变量(也就是用户自定义变量).
局部变量的用途
在T-SQL中,局部变量是一个存储指定数据类型单个值的对象.T-SQL中对变量的定义实际上和大多数高级语言一样.
局部变量在使用中常常用于以下三种用途:
1.在循环语句中记录循环的次数或者用于控制循环的次数.
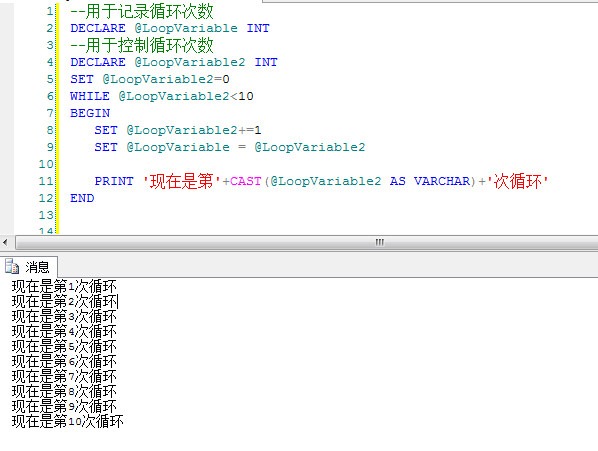{kind=link}
2.用于存储流程语句来控制流程走向
{kind=link}
3.储存存储过程或者函数的返回值
{kind=link}
实际上,存储任何业务数据的局部变量都属于这一类应用.
局部变量的声明
局部变量的声明必须以"DECLARE"作为关键字,变量的命名必须以"@"作为变量名的第一个字符.必须为所声明的变量提供一个数据类型和数据长度.如:
{kind=link}
局部变量的数据类型不能为Text,ntext,和Image类型,当对于字符型变量只提供数据类型没有提供数据长度时,数据长度默认为1.
一切只声明没有赋值的局部变量的初始值都为”NULL”.
局部变量的赋值
在T-SQL中,局部变量的赋值是通过”Set”关键字和”Select”关键字实现的.
实际上,使用Set或者是Select取决于下面几个因素
1.当对多个变量赋值时
SELECT关键字支持多个变量赋值,而SET关键字只支持一次对一个值赋值
{kind=link}
2.当赋值时表达式返回值的个数
使用SET进行赋值时,当表达式返回多个值时,报错.而SELECT关键字在赋值表达式返回多个值时,取最后一个.
比如,假设XXX表只有以下几条数据:
{kind=link}
当使用SELECT关键字进行时,可以取返回值的最后一个。
{kind=link}
3.当表达式未返回值时
使用SET对局部变量赋值时,如果赋值表达式未返回值,则局部变量变为NULL,而SELECT对表达式赋值时,如果表达式未返回值,则局部变量保持原值.
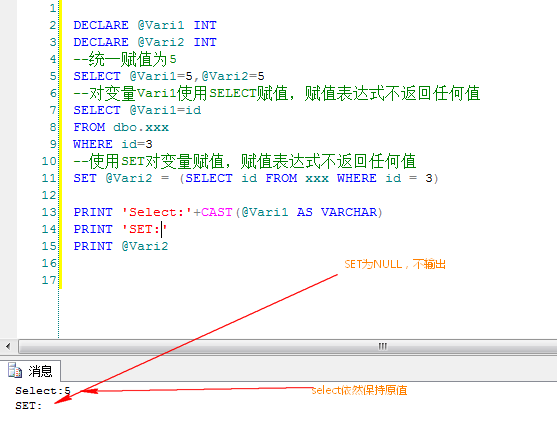{kind=link}
4.当…你是一个标准爱好者时
坚决使用SET关键字对局部变量赋值吧,因为SET是ANSI标准……
5.当…你懒得记上述何时使用SET或是何时使用SELECT时
好吧,我承认我也很懒.那你按照一个简单的方式区别:当你的赋值语句需要引用一个数据源(表)时,使用SELECT.除此之外,使用SET.
局部表变量
局部表变量是一个特殊的局部变量.和临时表不同,局部表变量具有一切局部变量的特点.在查询中,因为局部表变量是存在内存中,而不是硬盘中,所以速度会远远快于临时表或是实际表,局部表变量最多的使用时在查询中充当多个表做连接时的中间表,比如:
{kind=link}
这样会大大提高多表连接的查询速度.
总结
本文介绍了变量种类以及局部变量的使用范围,定义以及赋值方法.还简单介绍了表变量。在复杂查询中,系统的了解T-SQL的变量是写出好的查询语句必不可少的一部分。
T-SQL查询进阶--数据集之间的运算
概述
关系数据库的起源起源于数学中的集合概念.所以集合与集合之间,也同样继承了数学集合之间的运算.而对于在关系数据库中,常常用于两个数据集中并没有直接的关系数据库中的“关系”,比如外键.但两个数据集会有间接的关系,比如两届比赛,参加比赛人员集合之间会有间接关系.
数据集运算的种类
在T-SQL中,关系运算实际上可以分为四类,首先看我们举例子用的表:
这里的例子表分别为两个不同会议参加的人员记录,分别为Meeting1和Meeting2,如下:
{kind=link}
{kind=link}
关系运算的具体可以分为以下四类:
1.A∩B,既是所求数据集既在A中,又在B中
在实例表中,实际的例子为既参加第一个会议,又参加第二个会议人的集合,如下图:
{kind=link}
2.A∪B,既所求数据在数据集A中,或在数据集B中
在实例表中,实际的例子为参加第一个会议,或参加第二个会议人的集合,如下图:
{kind=link}
3.A-B,既所求数据在数据集A中,不在数据集B中
在实例表中,实际的例子为参加了第一个会议,同时没有参加第二个会议的人的集合,如下图:
{kind=link}
4.B-A,既所求数据在数据集B中,不在数据集A中
这个其实和上面第三种情况没有本质区别,只是顺序颠倒了一下,如下图:
{kind=link}
数据集的来源
在T-SQL中,参与数据集运算的两个数据集可以来自任何返回数据集的表达式.比如,一张表,一张表的子集,多张表,临时表变量,虚拟列,甚至是一个scalar值
数据集运算的条件
并不是所有的数据集都可以做运算。就像一个苹果+一个鸭梨不能等于2一样,在T-SQL中,数据集之间的运算需要符合下面3个条件:
1.两个数据集之间必须有相同数量的列(Column)
2.两个数据集之间列出现的次序必须一致
3.两个数据集之间每一个对应的列的数据类型必须匹配
数据集运算在T-SQL中的实现
1.A∪B 使用UNION实现
T-SQL中提供了UNION来实现A∪B的运算,实际上UNION有两个版本,分别为:
UNION
UNION表示了A∪B的关系,当遇到两个数据集中相同的行时,保留唯一一个:
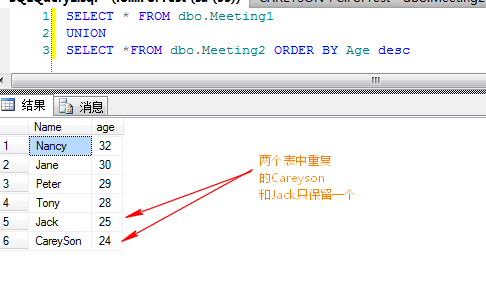{kind=link}
UNION ALL
UNION ALL同样实现了A∪B的逻辑,但与UNION不同的是,当遇到两个数据集中重复的行时,全部保留:
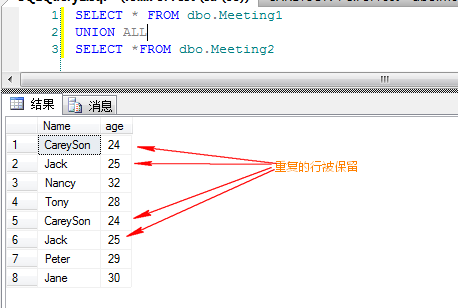{kind=link}
2.A∩B,使用INTERSECT实现
T-SQL提供了INTERSECT关键字来实现A∩B的关系:
{kind=link}
3.A-B,使用EXCEPT实现
T-SQL提供了EXCEPT关键字来实现A-B的关系:
{kind=link}
数据集运算的别名和排序
如果没有为数据列指定别名,则数据列的名称按照出现在第一个集合对应的列名算:
{kind=link}
做UNION后:
{kind=link}
如若我们想自定义列名,则需要为数据集运算中出现在第一位的数据集指定别名:
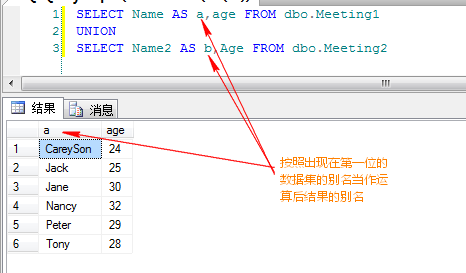{kind=link}
对运算后的结果进行排序
对运算后的结果进行排序是一件非常简单的事情,只需要在运算的最后加上ORDER BY子句,但是这里一定要注意:
1.ORDER BY是对整个运算后的结果排序,并不是对单个数据集
2.ORDER BY后面排序的字段名称是第一个数据集的字段名或者别名
{kind=link}
总结
本文详细介绍了简单的集合运算,并给出了简单集合运算在T-SQL中的实现。在文章最后还介绍了运算的别名规则和排序规则.掌握集合之间的运算对更加清晰的了解T-SQL查询有很大的帮助。
T-SQL查询进阶-10分钟理解游标
概述
游标是邪恶的!
在关系数据库中,我们对于查询的思考是面向集合的。而游标打破了这一规则,游标使得我们思考方式变为逐行进行.对于类C的开发人员来着,这样的思考方式会更加舒服。
正常面向集合的思维方式是:
{kind=link}
而对于游标来说:
{kind=link}
这也是为什么游标是邪恶的,它会使开发人员变懒,懒得去想用面向集合的查询方式实现某些功能.
同样的,在性能上,游标会吃更多的内存,减少可用的并发,占用宽带,锁定资源,当然还有更多的代码量……
从游标对数据库的读取方式来说,不难看出游标为什么占用更多的资源,打个比方:
{kind=link}
当你从ATM取钱的时候,是一次取1000效率更高呢,还是取10次100?
既然游标这么“邪恶”,为什么还要学习游标
我个人认为存在既是合理.归结来说,学习游标原因我归纳为以下2点
1.现存系统有一些游标,我们查询必须通过游标来实现
2.作为一个备用方式,当我们穷尽了while循环,子查询,临时表,表变量,自建函数或其他方式扔来无法实现某些查询的时候,使用游标实现.
T-SQL中游标的生命周期以及实现
在T-SQL中,游标的生命周期由5部分组成
1.定义一个游标
在T-SQL中,定义一个游标可以是非常简单,也可以相对复杂,取决于游标的参数.而游标的参数设置取决于你对游标原理的了解程度.
游标其实可以理解成一个定义在特定数据集上的指针,我们可以控制这个指针遍历数据集,或者仅仅是指向特定的行,所以游标是定义在以Select开始的数据集上的:
{kind=link}
T-SQL中的游标定义在MSDN中如下:
DECLARE cursor_name CURSOR [ LOCAL | GLOBAL ]
[ FORWARD_ONLY | SCROLL ]
[ STATIC | KEYSET | DYNAMIC | FAST_FORWARD ]
[ READ_ONLY | SCROLL_LOCKS | OPTIMISTIC ]
[ TYPE_WARNING ]
FOR select_statement
[ FOR UPDATE [ OF column_name [ ,...n ] ] ]
[;]
看起来很让人头痛是吧.下面仔细讲一下如何定义游标:
游标分为游标类型和游标变量,对于游标变量来说,遵循T-SQL变量的定义方法(啥,不知道T-SQL变量定义的规则?参考我前面的博文).游标变量支持两种方式赋值,定义时赋值和先定义后赋值,定义游标变量像定义其他局部变量一样,在游标前加”@”,注意,如果定义全局的游标,只支持定义时直接赋值,并且不能在游标名称前面加“@”,两种定义方式如下:
{kind=link}
下面我们来看游标定义的参数:
LOCAL和GLOBAL二选一
LOCAL意味着游标的生存周期只在批处理或函数或存储过程中可见,而GLOBAL意味着游标对于特定连接作为上下文,全局内有效,例如:
{kind=link}
如果不指定游标作用域,默认作用域为GLOBAL
FORWARD_ONLY 和 SCROLL 二选一
FORWARD_ONLY意味着游标只能从数据集开始向数据集结束的方向读取,FETCH NEXT是唯一的选项,而SCROLL支持游标在定义的数据集中向任何方向,或任何位置移动,如下图:
{kind=link}
STATIC KEYSET DYNAMIC 和 FAST_FORWARD 四选一
这四个关键字是游标所在数据集所反应的表内数据和游标读取出的数据的关系
STATIC意味着,当游标被建立时,将会创建FOR后面的SELECT语句所包含数据集的副本存入tempdb数据库中,任何对于底层表内数据的更改不会影响到游标的内容.
DYNAMIC是和STATIC完全相反的选项,当底层数据库更改时,游标的内容也随之得到反映,在下一次fetch中,数据内容会随之改变
KEYSET可以理解为介于STATIC和DYNAMIC的折中方案。将游标所在结果集的唯一能确定每一行的主键存入tempdb,当结果集中任何行改变或者删除时,@@FETCH_STATUS会为-2,KEYSET无法探测新加入的数据
FAST_FORWARD可以理解成FORWARD_ONLY的优化版本.FORWARD_ONLY执行的是静态计划,而FAST_FORWARD是根据情况进行选择采用动态计划还是静态计划,大多数情况下FAST_FORWARD要比FORWARD_ONLY性能略好.
READ_ONLY SCROLL_LOCKS OPTIMISTIC 三选一
READ_ONLY意味着声明的游标只能读取数据,游标不能做任何更新操作
SCROLL_LOCKS是另一种极端,将读入游标的所有数据进行锁定,防止其他程序进行更改,以确保更新的绝对成功
OPTIMISTIC是相对比较好的一个选择,OPTIMISTIC不锁定任何数据,当需要在游标中更新数据时,如果底层表数据更新,则游标内数据更新不成功,如果,底层表数据未更新,则游标内表数据可以更新
2.打开游标
当定义完游标后,游标需要打开后使用,只有简单一行代码:
OPEN test_Cursor
注意,当全局游标和局部游标变量重名时,默认会打开局部变量游标
3.使用游标
游标的使用分为两部分,一部分是操作游标在数据集内的指向,另一部分是将游标所指向的行的部分或全部内容进行操作
只有支持6种移动选项,分别为到第一行(FIRST),最后一行(LAST),下一行(NEXT),上一行(PRIOR),直接跳到某行(ABSOLUTE(n)),相对于目前跳几行(RELATIVE(n)),例如:
{kind=link}
对于未指定SCROLL选项的游标来说,只支持NEXT取值.
第一步操作完成后,就通过INTO关键字将这行的值传入局部变量:
比如下面代码:
{kind=link}
{kind=link}
游标经常会和全局变量@@FETCH_STATUS与WHILE循环来共同使用,以达到遍历游标所在数据集的目的,例如:
{kind=link}
4.关闭游标
在游标使用完之后,一定要记得关闭,只需要一行代码:CLOSE+游标名称
CLOSE test_Cursor
5.释放游标
当游标不再需要被使用后,释放游标,只需要一行代码:DEALLOCATE+游标名称
DEALLOCATE test_Cursor
对于游标一些优化建议
如果能不用游标,尽量不要使用游标
用完用完之后一定要关闭和释放
尽量不要在大量数据上定义游标
尽量不要使用游标上更新数据
尽量不要使用insensitive, static和keyset这些参数定义游标
如果可以,尽量使用FAST_FORWARD关键字定义游标
如果只对数据进行读取,当读取时只用到FETCH NEXT选项,则最好使用FORWARD_ONLY参数
总结
本文从游标的基本概念,到生命周期来谈游标。游标是非常邪恶的一种存在,使用游标经常会比使用面向集合的方法慢2-3倍,当游标定义在大数据量时,这个比例还会增加。如果可能,尽量使用while,子查询,临时表,函数,表变量等来替代游标,记住,游标永远只是你最后无奈之下的选择,而不是首选。
游标是邪恶的!
T-SQL查询进阶--深入浅出视图
简介
视图可以看作定义在SQL Server上的虚拟表.视图正如其名字的含义一样,是另一种查看数据的入口.常规视图本身并不存储实际的数据,而仅仅存储一个Select语句和所涉及表的metadata.
视图简单的理解如下:
{kind=link}
通过视图,客户端不再需要知道底层table的表结构及其之间的关系。视图提供了一个统一访问数据的接口。
为什么要使用视图(View)
从而我们不难发现,使用视图将会得到如下好处:
视图隐藏了底层的表结构,简化了数据访问操作
因为隐藏了底层的表结构,所以大大加强了安全性,用户只能看到视图提供的数据
使用视图,方便了权限管理,让用户对视图有权限而不是对底层表有权限进一步加强了安全性
视图提供了一个用户访问的接口,当底层表改变后,改变视图的语句来进行适应,使已经建立在这个视图上客户端程序不受影响
视图(View)的分类
视图在SQL中可以分为三类
普通视图(Regular View)
索引视图(Indexed View)
分割视图(Partitioned View)
下面从这几种视图类型来谈视图
普通视图(Rugular View)
普通视图由一个Select语句所定义,视图仅仅包含其定义和被引用表的metadata.并不实际存储数据。MSDN中创建视图的模版如下:
CREATE VIEW [ schema_name . ] view_name [ (column [ ,...n ] ) ]
[ WITH <view_attribute> [ ,...n ] ] AS select_statement
<view_attribute> ::=
{
[ ENCRYPTION ]
[ SCHEMABINDING ]
[ VIEW_METADATA ] }
参数还是比较少的,现在解释一下上面的参数:
ENCRYPTION:视图是加密的,如果选上这个选项,则无法修改.创建视图的时候需要将脚本保存,否则再也不能修改了
SCHEMABINDING:和底层引用到的表进行定义绑定。这个选项选上的话,则视图所引用到的表不能随便更改构架(比如列的数据类型),如果需要更改底层表构架,则先drop或者alter在底层表之上绑定的视图.
VIEW_METADATA:这个是个很有意思的选项.正如这个选项的名称所指示,如果不选择,返回给客户端的metadata是View所引用表的metadata,如果选择了这个选项,则返回View的metadata.再通俗点解释,VIEW_METADATA可以让视图看起来貌似表一样。View的每一个列的定义等直接告诉客户端,而不是所引用底层表列的定义。
WITH Check Option:这个选项用于更新数据做限制,下面会在通过视图更新数据一节解释.
当然了,创建视图除了需要符合上面的语法规则之外,还有一些规则需要遵守:
在View中,除非有TOP关键字,否则不能用Order By子句(如果你一意孤行要用Order by,这里有个hack是使用Top 100 percent…..)
View在每个Schema中命名必须独一无二
View嵌套不能超过32层(其实实际工作中谁嵌套超过两层就要被打PP了-.-)
Compute,compute by,INTO关键字不允许出现在View中
View不能建立在临时表上
View不能对全文索引进行查询
建立View一个简单的例子:
CREATE VIEW v_Test_View1ASSELECT TOP 100 * FROM HumanResources.Employee
视图建立完成后,就可以像访问表一样访问视图了:
在Management studio中,我创建视图的时候更喜欢用这样一种方法,将会便捷很多:
{kind=link}
{kind=link}
索引视图(Indexed View)
在谈到索引视图之前,我突然想起以前看过的一个漫画.话说咱们高端产品买不起,但是省吃俭用攒点钱买个IPhone装装高端总还是可以的吧:
{kind=link}
其实索引视图也很类似,在普通的视图的基础上,为视图建立唯一聚集索引,这时这个视图就变成了索引视图.套用上面漫画的公式:视图+聚集索引=索引视图
索引视图可以看作是一个和表(Table)等效的对象!
SQL Server中的索引视图和Oracle中的Materialized View是一个概念.想要理解索引视图,必须先理解聚集索引。聚集索引简单来说理解成主键,数据库中中的数据按照主键的顺序物理存储在表中,就像新华字典,默认是按照ABCD….这样的方式进行内容设置。ABCD….就相当于主键.这样就避免了整表扫描从而提高了性能.因此一个表中只能有一个聚集索引。
对于索引视图也是,为一个视图加上了聚集索引后。视图就不仅仅再是select语句和表的metadata了,索引视图会将数据物理存在数据库中,索引视图所存的数据和索引视图中所涉及的底层表保持同步。
理解了索引视图的原理之后,我们可以看出,索引视图对于OLAP这种大量数据分析和查询来说,性能将会得到大幅提升。尤其是索引视图中有聚合函数,涉及大量高成本的JOIN,因为聚合函数计算的结果物理存入索引视图,所以当面对大量数据使用到了索引视图之后,并不必要每次都进行聚合运算,这无疑会大大提升性能.
而同时,每次索引视图所涉及的表进行Update,Insert,Delete操作之后,SQL Server都需要标识出改变的行,让索引视图进行数据同步.所以OLTP这类增删改很多的业务,数据库需要做大量的同步操作,这会降低性能。
谈完了索引视图的基本原理和好处与坏处之后,来看看在SQL Server中的实现:
在SQL Server中实现索引视图是一件非常,简单的事,只需要在现有的视图上加上唯一聚集索引.但SQL Server对于索引视图的限制却使很多DBA对其并不青睐:
比如:
索引视图涉及的基本表必须ANSI_NULLS设置为ON
索引视图必须设置ANSI_NULLS和QUOTED_INDETIFIER为ON
索引视图只能引用基本表
SCHEMABINDING必须设置
定义索引视图时必须使用Schema.ViewName这样的全名
索引视图中不能有子查询
avg,max,min,stdev,stdevp,var,varp这些聚合函数不能用
………………
还有更多…就不一一列举了,有兴趣的请自行Google之.
下面我来通过一个例子来说明索引视图:
假设在adventureWorks数据库中,我们有一个查询:
SELECT p.Name,s.OrderQtyFROM Production.Product p
inner join Sales.SalesOrderDetail sON p.ProductID=s.ProductID
这个查询的执行计划:
{kind=link}
这时,我建立视图并在这个视图上建立唯一聚集索引:
--建立视图CREATE VIEW v_Test_IndexedViewWITH SCHEMABINDINGASSELECT p.Name,s.OrderQty,s.SalesOrderDetailIDFROM Production.Product p
inner join Sales.SalesOrderDetail sON p.ProductID=s.ProductIDGO--在视图上建立索引CREATE UNIQUE CLUSTERED INDEX indexedview_test1ON v_Test_IndexedView(SalesOrderDetailID)
接下来,套用刘谦的台词:见证奇迹的时刻到了,我们再次执行之前的查询:
{kind=link}
从上面这个例子中,可以体会到索引视图的强大威力,即使你的查询语句中不包含这个索引视图,查询分析器会自动选择这个视图,从而大大的提高了性能.当然,这么强力的性能,只有在SQL SERVER企业版和开发版才有哦(虽然我见过很多SQL Server的开发人员让公司掏着Enterprise版的钱,用着Express版的功能……)
分割视图(Partitioned View)
分割视图其实从微观实现方式来说,整个视图所返回的数据由几个平行表(既是几个表有相同的表结构,也就是列和数据类型,但存储的行集合不同)进行UNION连接(对于UNION连接如果不了解,请看我之前的博文)所获得的数据集.
分割视图总体上可以分为两种:
1.本地分割视图(Local Partitioned View)
2.分布式分割视图(Distributed Partitioned View)
因为本地分割视图仅仅是为了和SQL Server 2005之前的版本的一种向后兼容,所以这里仅仅对分布式分割视图进行说明.
分布式分割视图其实是将由几个由不同数据源或是相同数据源获得的平行数据集进行连接所获得的,一个简单的概念图如下:
{kind=link}
上面的视图所获得的数据分别来自三个不同数据源的表,每一个表中只包含四行数据,最终组成了这个分割视图.
使用分布式分割视图最大的好处就是提升性能.比如上面的例子中,我仅仅想取得ContactID为8这位员工的信息,如果通过分布式视图获取的话,SQL Server可以非常智能的仅仅扫描包含ContactID为8的表2,从而避免了整表扫描。这大大减少了IO操作,从而提升了性能.
这里要注意的是,分布式分割视图所涉及的表之间的主键不能重复,比如上面的表A ContactID是1-4,则表B的ContactID不能是2-8这个样子.
还有一点要注意的是,一定要为分布式分割索引的主键加Check约束,从而让SQL Server的查询分析器知道该去扫描哪个表,下面来看个例子.
在微软示例数据库AdventureWorks数据库,我通过ContactID从前100行和100-200行的数据分别存入两个表,Employee100和Employee200,代码如下:
--create Employee100SELECT TOP 100 * INTO Employee100FROM HumanResources.Employee ORDER BY EmployeeID--create Employee200SELECT * INTO Employee200FROM
(SELECT TOP 100 *FROM HumanResources.Employee WHERE EmployeeID NOT IN (SELECT TOP 100 EmployeeID FROM HumanResources.Employee ORDER BY EmployeeID)ORDER BY HumanResources.Employee.EmployeeID)AS e
这时来建立分布式分割视图:
CREATE VIEW v_part_view_testASSELECT * FROM Employee100UNION SELECT * FROM Employee200
这时我们对这个索引进行查询操作:
SELECT * FROM v_part_view_testWHERE EmployeeID=105
下面是执行计划:
{kind=link}
通过上图可以看出,通过这种分割的方式,执行计划仅仅是扫描Employee200,从而避免了扫描所有数据,这无疑提升了性能.
所以,当你将不同的数据表之间放到不同的服务器或是使用RAID5磁盘阵列时,分布式分割视图则进一步会提升查询性能.
使用分布式分割视图能够在所有情况下都提升性能吗?那妥妥的不可能.使用这种方式如果面对的查询包含了聚合函数,尤其是聚合函数中还包含distinct。或是不加where条件进行排序.那绝对是性能的杀手。因为聚合函数需要扫描分布式分割视图中所有的表,然后进行UNION操作后再进行运算.
通过视图(View)更新数据
通过视图更新数据是我所不推荐的.因为视图并不能接受参数.我更推荐使用存储过程来实现.
使用View更新数据和更新Table中数据的方式完全一样(前面说过,View可以看作是一个虚拟表,如果是索引视图则是具体的一张表)
通过视图来更新数据需要注意以下几点
1.视图中From子句之后至少有一个用户表
2.View的查询无论涉及多少张表,一次只能更新其中一个表的数据
3.对于表达式计算出来的列,常量列,聚合函数算出来的列无法更新
4.Group By,Having,Distinct关键字不能影响到的列不能更新
这里说一下创建View有一个WITH Check Option选项,如果选择这个选项,则通过View所更新的数据必须符合View中where子句所限定的条件,比如:
我创建一个View:
{kind=link}
视图(View)中的几个小技巧
1.通过视图名称查到视图的定义
SELECT * FROM sys.sql_modulesWHERE object_id=OBJECT_ID('视图名称')
2.前面说过,普通视图仅仅存储的是select语句和所引用表的metadata,当底层表数据改变时,有时候视图中表的metadata并没有及时同步,可以通过如下代码进行手动同步
EXEC sp_refreshview 视图名称
视图(View)的最佳实践
这是我个人一些经验,欢迎补充
一定要将View中的Select语句性能调到最优(貌似是废话,不过真理都是废话…)
View最好不要嵌套,如果非要嵌套,最多只嵌套一层
能用存储过程和自定义函数替代View的,尽量不要使用View,存储过程会缓存执行计划,性能更优,限制更少
在分割视图上,不要使用聚合函数,尤其是聚合函数还包含了Distinct
在视图内,如果Where子句能加在视图内,不要加在视图外(因为调用视图会返回所有行,然后再筛选,性能杀手,如果你还加上了order by…..)
总结
文中对视图的三种类型进行了详解.每种视图都有各自的使用范围,使用得当会将性能提升一个档次,而使用不当反而会拖累性能.
我想起一句名言:“everything has price,always trade-off”…..
T-SQL查询进阶--详解公用表表达式(CTE)
简介
对于SELECT查询语句来说,通常情况下,为了使T-SQL代码更加简洁和可读,在一个查询中引用另外的结果集都是通过视图而不是子查询来进行分解的.但是,视图是作为系统对象存在数据库中,那对于结果集仅仅需要在存储过程或是用户自定义函数中使用一次的时候,使用视图就显得有些奢侈了.
公用表表达式(Common Table Expression)是SQL SERVER 2005版本之后引入的一个特性.CTE可以看作是一个临时的结果集,可以在接下来的一个SELECT,INSERT,UPDATE,DELETE,MERGE语句中被多次引用。使用公用表达式可以让语句更加清晰简练.
除此之外,根据微软对CTE好处的描述,可以归结为四点:
可以定义递归公用表表达式(CTE)
当不需要将结果集作为视图被多个地方引用时,CTE可以使其更加简洁
GROUP BY语句可以直接作用于子查询所得的标量列
可以在一个语句中多次引用公用表表达式(CTE)
公用表表达式(CTE)的定义
公用表达式的定义非常简单,只包含三部分:
公用表表达式的名字(在WITH之后)
所涉及的列名(可选)
一个SELECT语句(紧跟AS之后)
在MSDN中的原型:
WITH expression_name [ ( column_name [,...n] ) ]
( CTE_query_definition )
按照是否递归,可以将公用表(CTE)表达式分为递归公用表表达式和非递归公用表表达式.
非递归公用表表达式(CTE)
非递归公用表表达式(CTE)是查询结果仅仅一次性返回一个结果集用于外部查询调用。并不在其定义的语句中调用其自身的CTE
比如一个简单的非递归公用表表达式:
{kind=link}
当然,公用表表达式的好处之一是可以在接下来一条语句中多次引用:
{kind=link}
前面我一直强调“在接下来的一条语句中”,意味着只能接下来一条使用:
{kind=link}
由于CTE只能在接下来一条语句中使用,因此,当需要接下来的一条语句中引用多个CTE时,可以定义多个,中间用逗号分隔:
{kind=link}
递归公用表表达式(CTE)
递归公用表表达式很像派生表(Derived Tables ),指的是在CTE内的语句中调用其自身的CTE.与派生表不同的是,CTE可以在一次定义多次进行派生递归.对于递归的概念,是指一个函数或是过程直接或者间接的调用其自身,递归的简单概念图如下:
{kind=link}
递归在C语言中实现的一个典型例子是斐波那契数列:
long fib(int n)
{
if (n==0) return 0;
if (n==1) return 1;
if (n>1) return fib(n-1)+fib(n-2);
}
上面C语言代码可以看到,要构成递归函数,需要两部分。第一部分是基础部分,返回固定值,也就是告诉程序何时开始递归。第二部分是循环部分,是函数或过程直接或者间接调用自身进行递归.
对于递归公用表达式来说,实现原理也是相同的,同样需要在语句中定义两部分:
基本语句
递归语句
在SQL这两部分通过UNION ALL连接结果集进行返回:
比如:在AdventureWork中,我想知道每个员工所处的层级,0是最高级
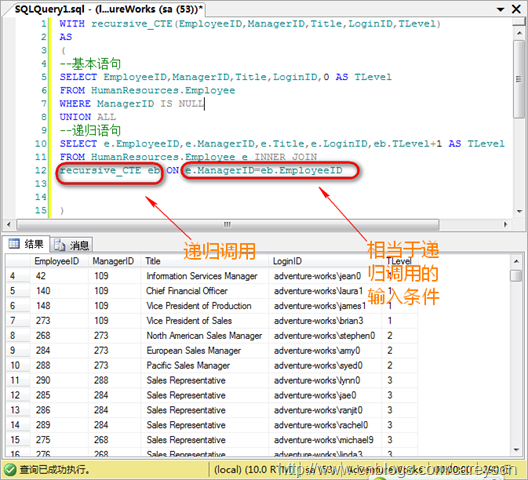{kind=link}
这么复杂的查询通过递归CTE变得如此优雅和简洁.这也是CTE最强大的地方.
当然,越强大的力量,就需要被约束.如果使用不当的话,递归CTE可能会出现无限递归。从而大量消耗SQL Server的服务器资源.因此,SQL Server提供了OPTION选项,可以设定最大的递归次数:
还是上面那个语句,限制了递归次数:
{kind=link}
所提示的消息:
{kind=link}
这个最大递归次数往往是根据数据所代表的具体业务相关的,比如这里,假设公司层级最多只有2层.
总结
CTE是一种十分优雅的存在。CTE所带来最大的好处是代码可读性的提升,这是良好代码的必须品质之一。使用递归CTE可以更加轻松愉快的用优雅简洁的方式实现复杂的查询。
T-SQL查询进阶--SQL Server中CTE的另一种递归方式-从底层向上递归
SQL Server中的公共表表达式(Common Table Expression,CTE)提供了一种便利的方式使得我们进行递归查询。所谓递归查询方便对某个表进行不断的递归从而更加容易的获得带有层级结构的数据。典型的例子如MSDN(https://technet.microsoft.com/en-us/library/ms186243(v=sql.105).aspx)中提到的获取员工关系层级的结构,如图1所示。
{kind=link}
图1.获取员工层级结构
图1所示的例子是一个简单的通过递归获取员工层级的例子,主要理念是通过一个自连接的表(员工表,连接列为员工ID与其上司ID,没有上司的人为公司最大的CEO),不断递归,从而在每次递归时将员工层级+1,最终递归完成后最低级别的员工可以排出其在公司的层级,也就是如图1中所示的3。
图1的例子应用场景比较广泛,网上也有很多文章提到过这种方式,但当我们需要另一种递归方式时,上面的例子就无能为力了。假设我们有这样一个需求,比如现在流程的微商传销的提成方式,假设员工分为3级,分别为一级代理、二级代理、最终销售。那么算业绩的时候可能是重复提成,比如一级代理提二级代理销售额的3%,一级代理提最终销售的1%。二级代理提最终销售的2%等等。那么我们需要从数据库中提取出所有代理的所有利润就不是一件容易的事。一个简单的示意图如图2所示:
{kind=link}
图2.多层提成的模型
而此时每一级代理自身又可以直接进行销售,所以代理的销售额并不简单等于其下级代理销售额的和,因此我们最简单的办法就是列出每个代理所有下属的代理,并将其销售额按照业务规则相乘即可。
因此我们需要一个查询将每个代理以及其下属层级全部列出来。由于实际需求可能都是按照省份划分代理,比如广州省是一级,广州市是二级,下属天河区是三级。下面是我们测试数据用的表:
create table #tb(id varchar(3) , pid varchar(3) , name varchar(10))
insert into #tb values('1' , null , '广东省')
insert into #tb values('2' , '1' , '广州市')
insert into #tb values('3' , '1' , '深圳市')
insert into #tb values('4' , '2' , '天河区')
insert into #tb values('5' , '3' , '罗湖区')
insert into #tb values('6' , '3' , '福田区')
insert into #tb values('7' , '3' , '宝安区')
insert into #tb values('8' , '7' , '西乡镇')
insert into #tb values('9' , '7' , '龙华镇')
代码清单1.测试数据
而我们希望获得的数据类似:
{kind=link}
图3.希望获得的数据
在此,我们采用的策略不是与MSDN中的例子不同,而是自下而上递归。代码如代码清单2所示:
WITH cte ( id, pid, NAME )
AS ( SELECT id ,
pid ,
name
FROM #tb a
WHERE a.pid IS NOT NULL
UNION ALL
SELECT b.id ,
a.pid ,
b.NAME
FROM #tb a
INNER JOIN cte b ON a.id = b.pid
WHERE a.pid IS NOT NULL
)
SELECT pid AS id,id AS SID,NAME
FROM cte a
UNION
SELECT id,id,name FROM #tb
ORDER BY id,sid
代码清单2.从下而上的递归
代码清单2展示了方案,与MSDN自顶向下的例子不同,我们这里采用了自下而上的递归,递归的终止条件是WHERE a.pid IS NOT NULL,而不是a.pid IS NULL,该条件使得先从底层开始递归,然后通过a.id = b.pid而不是a.pid=b.id使得查找的过程变为由子节点找父节点,从而实现了上述需求。
T-SQL查询进阶--理解SQL Server中索引的概念,原理以及其他
简介
在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,SQL Server仍然可以实现应有的功能。但索引可以在大多数情况下大大提升查询性能,在OLAP中尤其明显.要完全理解索引的概念,需要了解大量原理性的知识,包括B树,堆,数据库页,区,填充因子,碎片,文件组等等一系列相关知识,这些知识写一本小书也不为过。所以本文并不会深入讨论这些主题。
索引是什么
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
精简来说,索引是一种结构.在SQL Server中,索引和表(这里指的是加了聚集索引的表)的存储结构是一样的,都是B树,B树是一种用于查找的平衡多叉树.理解B树的概念如下图:
{kind=link}
理解为什么使用B树作为索引和表(有聚集索引)的结构,首先需要理解SQL Server存储数据的原理.
在SQL SERVER中,存储的单位最小是页(PAGE),页是不可再分的。就像细胞是生物学中不可再分的,或是原子是化学中不可再分的最小单位一样.这意味着,SQL SERVER对于页的读取,要么整个读取,要么完全不读取,没有折中.
在数据库检索来说,对于磁盘IO扫描是最消耗时间的.因为磁盘扫描涉及很多物理特性,这些是相当消耗时间的。所以B树设计的初衷是为了减少对于磁盘的扫描次数。如果一个表或索引没有使用B树(对于没有聚集索引的表是使用堆heap存储),那么查找一个数据,需要在整个表包含的数据库页中全盘扫描。这无疑会大大加重IO负担.而在SQL SERVER中使用B树进行存储,则仅仅需要将B树的根节点存入内存,经过几次查找后就可以找到存放所需数据的被叶子节点包含的页!进而避免的全盘扫描从而提高了性能.
下面,通过一个例子来证明:
在SQL SERVER中,表上如果没有建立聚集索引,则是按照堆(HEAP)存放的,假设我有这样一张表:
{kind=link}
现在这张表上没有任何索引,也就是以堆存放,我通过在其上加上聚集索引(以B树存放)来展现对IO的减少:
{kind=link}
理解聚集和聚集索引
在SQL SERVER中,最主要的两类索引是聚集索引和非聚集索引。可以看到,这两个分类是围绕聚集这个关键字进行的.那么首先要理解什么是聚集.
聚集在索引中的定义:
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚集码)上具有相同值的元组集中存放在连续的物理块称为聚集。
简单来说,聚集索引就是:
{kind=link}
在SQL SERVER中,聚集的作用就是将某一列(或是多列)的物理顺序改变为和逻辑顺序相一致,比如,我从adventureworks数据库的employee中抽取5条数据:
{kind=link}
当我在ContactID上建立聚集索引时,再次查询:
{kind=link}
在SQL SERVER中,聚集索引的存储是以B树存储,B树的叶子直接存储聚集索引的数据:
{kind=link}
因为聚集索引改变的是其所在表的物理存储顺序,所以每个表只能有一个聚集索引.
非聚集索引
因为每个表只能有一个聚集索引,如果我们对一个表的查询不仅仅限于在聚集索引上的字段。我们又对聚集索引列之外还有索引的要求,那么就需要非聚集索引了.
非聚集索引,本质上来说也是聚集索引的一种.非聚集索引并不改变其所在表的物理结构,而是额外生成一个聚集索引的B树结构,但叶子节点是对于其所在表的引用,这个引用分为两种,如果其所在表上没有聚集索引,则引用行号。如果其所在表上已经有了聚集索引,则引用聚集索引的页.
一个简单的非聚集索引概念如下:
{kind=link}
可以看到,非聚集索引需要额外的空间进行存储,按照被索引列进行聚集索引,并在B树的叶子节点包含指向非聚集索引所在表的指针.
MSDN中,对于非聚集索引描述图是:
{kind=link}
可以看到,非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针.
通过非聚集索引的原理可以看出,如果其所在表的物理结构改变后,比如加上或是删除聚集索引,那么所有非聚集索引都需要被重建,这个对于性能的损耗是相当大的。所以最好要先建立聚集索引,再建立对应的非聚集索引.
聚集索引 VS 非聚集索引
前面通过对于聚集索引和非聚集索引的原理解释.我们不难发现,大多数情况下,聚集索引的速度比非聚集索引要略快一些.因为聚集索引的B树叶子节点直接存储数据,而非聚集索引还需要额外通过叶子节点的指针找到数据.
还有,对于大量连续数据查找,非聚集索引十分乏力,因为非聚集索引需要在非聚集索引的B树中找到每一行的指针,再去其所在表上找数据,性能因此会大打折扣.有时甚至不如不加非聚集索引.
因此,大多数情况下聚集索引都要快于非聚集索引。但聚集索引只能有一个,因此选对聚集索引所施加的列对于查询性能提升至关紧要.
索引的使用
索引的使用并不需要显式使用,建立索引后查询分析器会自动找出最短路径使用索引.
但是有这种情况.当随着数据量的增长,产生了索引碎片后,很多存储的数据进行了不适当的跨页,会造成碎片(关于跨页和碎片以及填充因子的介绍,我会在后续文章中说到)我们需要重新建立索引以加快性能:
比如前面的test_tb2上建立的一个聚集索引和非聚集索引,可以通过DMV语句查询其索引的情况:
SELECT index_type_desc,alloc_unit_type_desc,avg_fragmentation_in_percent,fragment_count,avg_fragment_size_in_pages,page_count,record_count,avg_page_space_used_in_percentFROM sys.dm_db_index_physical_stats(DB_ID('AdventureWorks'),OBJECT_ID('test_tb2'),NULL,NULL,'Sampled')
{kind=link}
我们可以通过重建索引来提高速度:
ALTER INDEX idx_text_tb2_EmployeeID ON test_tb2 REBUILD
还有一种情况是,当随着表数据量的增大,有时候需要更新表上的统计信息,让查询分析器根据这些信息选择路径,使用:
UPDATE STATISTICS 表名
那么什么时候知道需要更新这些统计信息呢,就是当执行计划中估计行数和实际表的行数有出入时:
{kind=link}
使用索引的代价
我最喜欢的一句话是”everything has price”。我们通过索引获得的任何性能提升并不是不需要付出代价。这个代价来自几方面.
1.通过聚集索引的原理我们知道,当表建立索引后,就以B树来存储数据.所以当对其进行更新插入删除时,就需要页在物理上的移动以调整B树.因此当更新插入删除数据时,会带来性能的下降。而对于聚集索引,当更新表后,非聚集索引也需要进行更新,相当于多更新了N(N=非聚集索引数量)个表。因此也下降了性能.
2.通过上面对非聚集索引原理的介绍,可以看到,非聚集索引需要额外的磁盘空间。
3.前文提过,不恰当的非聚集索引反而会降低性能.
所以使用索引需要根据实际情况进行权衡.通常我都会将非聚集索引全部放到另外一个独立硬盘上,这样可以分散IO,从而使查询并行.
总结
本文从索引的原理和概念对SQL SERVER中索引进行介绍,索引是一个很强大的工具,也是一把双刃剑.对于恰当使用索引需要对索引的原理以及数据库存储的相关原理进行系统的学习.
T-SQL查询进阶--理解SQL SERVER中的分区表
简介
分区表是在SQL SERVER2005之后的版本引入的特性。这个特性允许把逻辑上的一个表在物理上分为很多部分。而对于SQL SERVER2005之前版本,所谓的分区表仅仅是分布式视图,也就是多个表做union操作.
分区表在逻辑上是一个表,而物理上是多个表.这意味着从用户的角度来看,分区表和普通表是一样的。这个概念可以简单如下图所示:
{kind=link}
而对于SQL SERVER2005之前的版本,是没有分区这个概念的,所谓的分区仅仅是分布式视图:
{kind=link}
本篇文章所讲述的分区表指的是SQL SERVER2005之后引入的分区表特性.
为什么要对表进行分区
在回答标题的问题之前,需要说明的是,表分区这个特性只有在企业版或者开发版中才有,还有理解表分区的概念还需要理解SQL SERVER中文件和文件组的概念.
对表进行分区在多种场景下都需要被用到.通常来说,使用表分区最主要是用于:
存档,比如将销售记录中1年前的数据分到一个专门存档的服务器中
便于管理,比如把一个大表分成若干个小表,则备份和恢复的时候不再需要备份整个表,可以单独备份分区
提高可用性,当一个分区跪了以后,只有一个分区不可用,其它分区不受影响
提高性能,这个往往是大多数人分区的目的,把一个表分布到不同的硬盘或其他存储介质中,会大大提升查询的速度.
分区表的步骤
分区表的定义大体上分为三个步骤:
定义分区函数
定义分区构架
定义分区表
分区函数,分区构架和分区表的关系如下:
{kind=link}
分区表依赖分区构架,而分区构架又依赖分区函数.值得注意的是,分区函数并不属于具体的分区构架和分区表,他们之间的关系仅仅是使用关系.
下面我们通过一个例子来看如何定义一个分区表:
假设我们需要定义的分区表结构如下:
{kind=link}
第一列为自增列,orderid为订单id列,SalesDate为订单日期列,也就是我们需要分区的依据.
下面我们按照上面所说的三个步骤来实现分区表.
定义分区函数
分区函数是用于判定数据行该属于哪个分区,通过分区函数中设置边界值来使得根据行中特定列的值来确定其分区,上面例子中,我们可以通过SalesDate的值来判定其不同的分区.假设我们想定义两个边界值(boundaryValue)进行分区,则会生成三个分区,这里我设置边界值分别为2004-01-01和2007-01-01,则前面例子中的表会根据这两个边界值分成三个区:
{kind=link}
在MSDN中,定义分区函数的原型如下:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type )AS RANGE [ LEFT | RIGHT ] FOR VALUES ( [ boundary_value [ ,...n ] ] )
[ ; ]
通过定义分区函数的原型,我们看出其中并没有具体涉及具体的表.因为分区函数并不和具体的表相绑定.上面原型中还可以看到Range left和right.这个参数是决定临界值本身应该归于“left”还是“right”:
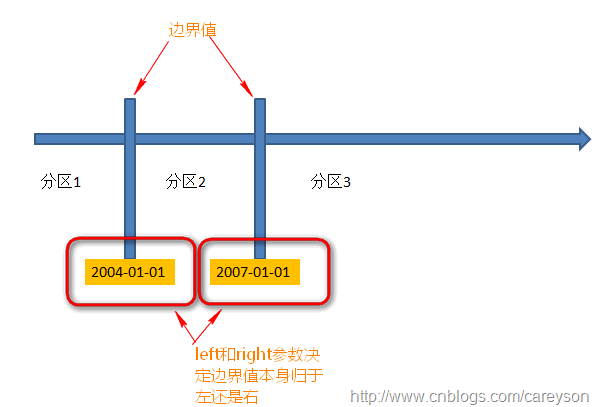{kind=link}
下面我们根据上面的参数定义分区函数:
{kind=link}
通过系统视图,可以看见这个分区函数已经创建成功
定义分区构架
定义完分区函数仅仅是知道了如何将列的值区分到了不同的分区。而每个分区的存储方式,则需要分区构架来定义.使用分区构架需要你对文件和文件组有点了解.
我们先来看MSDN的分区构架的原型:
CREATE PARTITION SCHEME partition_scheme_nameAS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )
[ ; ]
从原型来看,分区构架仅仅是依赖分区函数.分区构架中负责分配每个区属于哪个文件组,而分区函数是决定如何在逻辑上分区:
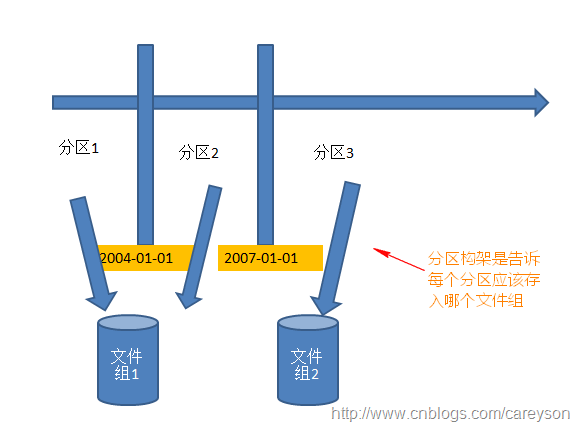{kind=link}
基于之前创建的分区函数,创建分区构架:
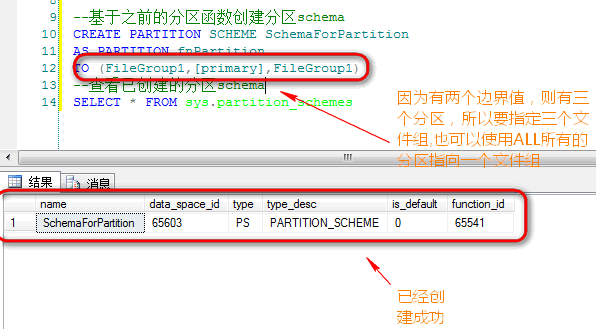{kind=link}
定义分区表
接下来就该创建分区表了.表在创建的时候就已经决定是否是分区表了。虽然在很多情况下都是你在发现已经表已经足够大的时候才想到要把表分区,但是分区表只能够在创建的时候指定为分区表。
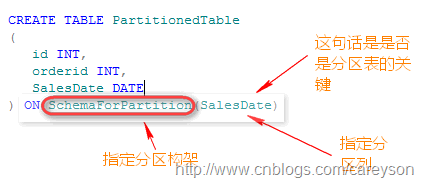{kind=link}
为刚建立的分区表PartitionedTable加入5万条测试数据,其中SalesDate随机生成,从2001年到2010年随机分布.加入数据后,我们通过如下语句来看结果:
select convert(varchar(50), ps.name) as partition_scheme,
p.partition_number, convert(varchar(10), ds2.name) as filegroup, convert(varchar(19), isnull(v.value, ''), 120) as range_boundary,
str(p.rows, 9) as rowsfrom sys.indexes i join sys.partition_schemes ps on i.data_space_id = ps.data_space_id join sys.destination_data_spaces ddson ps.data_space_id = dds.partition_scheme_id join sys.data_spaces ds2 on dds.data_space_id = ds2.data_space_id join sys.partitions p on dds.destination_id = p.partition_numberand p.object_id = i.object_id and p.index_id = i.index_id join sys.partition_functions pf on ps.function_id = pf.function_id LEFT JOIN sys.Partition_Range_values v on pf.function_id = v.function_idand v.boundary_id = p.partition_number - pf.boundary_value_on_right WHERE i.object_id = object_id('PartitionedTable')and i.index_id in (0, 1) order by p.partition_number
可以看到我们分区的数据分布:
{kind=link}
分区表的分割
分区表的分割。相当于新建一个分区,将原有的分区需要分割的内容插入新的分区,然后删除老的分区的内容,概念如下图:
假设我新加入一个分割点:2009-01-01,则概念如下:
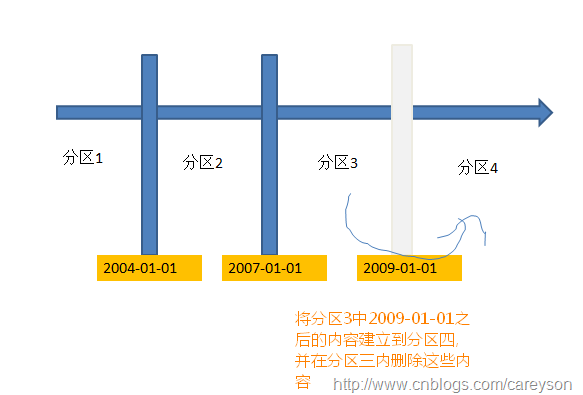{kind=link}
通过上图我们可以看出,如果分割时,被分割的分区3内有内容需要分割到分区4,则这些数据需要被复制到分区4,并删除分区3上对应数据。
这种操作非常非常消耗IO,并且在分割的过程中锁定分区三内的内容,造成分区三的内容不可用。不仅仅如此,这个操作生成的日志内容会是被转移数据的4倍!
所以我们如果不想因为这种操作给客户带来麻烦而被老板爆菊的话…最好还是把分割点建立在未来(也就是预先建立分割点),比如2012-01-01。则分区3内的内容不受任何影响。在以后2012的数据加入时,自动插入到分区4.
分割现有的分区需要两个步骤:
1.首先告诉SQL SERVER新建立的分区放到哪个文件组
2.建立新的分割点
可以通过如下语句来完成:
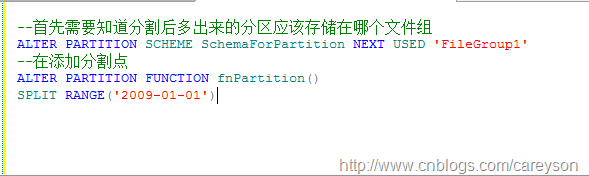{kind=link}
如果我们的分割构架在定义的时候已经指定了NEXT USED,则直接添加分割点即可。
通过文中前面查看分区的长语句..再来看:
{kind=link}
新的分区已经加入!
分区的合并
分区的合并可以看作分区分割的逆操作。分区的合并需要提供分割点,这个分割点必须在现有的分割表中已经存在,否则进行合并就会报错
假设我们需要根据2009-01-01来合并分区,概念如下:
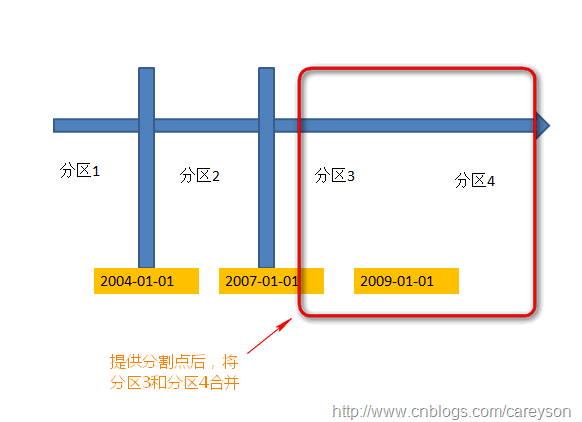{kind=link}
只需要使用merge参数:
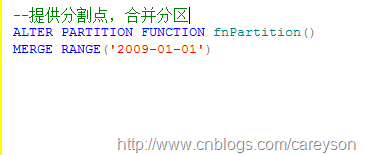{kind=link}
再来看分区信息:
{kind=link}
这里值得注意的是,假设分区3和分区4不再一个文件组,则合并后应该存在哪个文件组呢?换句话说,是由分区3合并到分区4还是由分区4合并到分区3?这个需要看我们的分区函数定义的是left还是right.如果定义的是left.则由左边的分区3合并到右边的分区4.反之,则由分区4合并到分区3:
{kind=link}
总结
本文从讲解了SQL SERVER中分区表的使用方式。分区表是一个非常强大的功能。使用分区表相对传统的分区视图来说,对于减少DBA的管理工作来说,会更胜一筹!
T-SQL查询进阶--理解SQL Server中的锁
简介
在SQL Server中,每一个查询都会找到最短路径实现自己的目标。如果数据库只接受一个连接一次只执行一个查询。那么查询当然是要多快好省的完成工作。但对于大多数数据库来说是需要同时处理多个查询的。这些查询并不会像绅士那样排队等待执行,而是会找最短的路径执行。因此,就像十字路口需要一个红绿灯那样,SQL Server也需要一个红绿灯来告诉查询:什么时候走,什么时候不可以走。这个红绿灯就是锁。
{kind=link}
图1.查询可不会像绅士们那样按照次序进行排队
为什么需要锁
在开始谈锁之前,首先要简单了解一下事务和事务的ACID属性。可以参看我之前的一篇关于ACID的文章。如果你了解了事务之间的影响方式,你就应该知道在数据库中,理论上所有的事务之间应该是完全隔离的。但是实际上,要实现完全隔离的成本实在是太高(必须是序列化的隔离等级才能完全隔离,这个并发性有点….)。所以,SQL Server默认的Read Commited是一个比较不错的在隔离和并发之间取得平衡的选择。
SQL Server通过锁,就像十字路口的红绿灯那样,告诉所有并发的连接,在同一时刻上,那些资源可以读取,那些资源可以修改。前面说到,查询本身可不是什么绅士,所以需要被监管。当一个事务需要访问的资源加了其所不兼容的锁,SQL Server会阻塞当前的事务来达成所谓的隔离性。直到其所请求资源上的锁被释放,如图2所示。
{kind=link}
图2.SQL Server通过阻塞来实现并发
如何查看锁
了解SQL Server在某一时间点上的加锁情况无疑是学习锁和诊断数据库死锁和性能的有效手段。我们最常用的查看数据库锁的手段不外乎两种:
使用sys.dm_tran_locks这个DMV
SQL Server提供了sys.dm_tran_locks这个DMV来查看当前数据库中的锁,前面的图2就是通过这个DMV来查看的.
这里值得注意的是sys.dm_tran_locks这个DMV看到的是在查询时间点的数据库锁的情况,并不包含任何历史锁的记录。可以理解为数据库在查询时间点加锁情况的快照。sys.dm_tran_locks所包含的信息分为两类,以resource为开头的描述锁所在的资源的信息,另一类以request开头的信息描述申请的锁本身的信息。如图3所示。更详细的说明可以查看MSDN(http://msdn.microsoft.com/en-us/library/ms190345.aspx)
{kind=link}
图3.sys.dm_tran_locks
这个DMV包含的信息比较多,所以通常情况下,我们都会写一些语句来从这个DMV中提取我们所需要的信息。如图4所示。
{kind=link}
图4.写语句来提取我们需要的锁信息
使用Profiler来捕捉锁信息
我们可以通过Profiler来捕捉锁和死锁的相关信息,如图5所示。
{kind=link}
图5.在Profiler中捕捉锁信息
但默认如果不过滤的话,Profiler所捕捉的锁信息包含SQL Server内部的锁,这对于我们查看锁信息非常不方便,所以往往需要筛选列,如图6所示。
{kind=link}
图6.筛选掉数据库锁的信息
所捕捉到的信息如图7所示。
{kind=link}
图7.Profiler所捕捉到的信息
锁的粒度
锁是加在数据库对象上的。而数据库对象是有粒度的,比如同样是1这个单位,1行,1页,1个B树,1张表所含的数据完全不是一个粒度的。因此,所谓锁的粒度,是锁所在资源的粒度。所在资源的信息也就是前面图3中以Resource开头的信息。
对于查询本身来说,并不关心锁的问题。就像你开车并不关心哪个路口该有红绿灯一样。锁的粒度和锁的类型都是由SQL Server进行控制的(当然你也可以使用锁提示,但不推荐)。锁会给数据库带来阻塞,因此越大粒度的锁造成更多的阻塞,但由于大粒度的锁需要更少的锁,因此会提升性能。而小粒度的锁由于锁定更少资源,会减少阻塞,因此提高了并发,但同时大量的锁也会造成性能的下降。因此锁的粒度对于性能和并发的关系如图8所示。
{kind=link}
图8.锁粒度对于性能和并发的影响
SQL Server决定所加锁的粒度取决于很多因素。比如键的分布,请求行的数量,行密度,查询条件等。但具体判断条件是微软没有公布的秘密。开发人员不用担心SQL Server是如何决定使用哪个锁的。因为SQL Server已经做了最好的选择。
在SQL Server中,锁的粒度如表1所示。
| 资源 |
说明 |
| RID |
用于锁定堆中的单个行的行标识符。 |
| KEY |
索引中用于保护可序列化事务中的键范围的行锁。 |
| PAGE |
数据库中的 8 KB 页,例如数据页或索引页。 |
| EXTENT |
一组连续的八页,例如数据页或索引页。 |
| HoBT |
堆或 B 树。 用于保护没有聚集索引的表中的 B 树(索引)或堆数据页的锁。 |
| TABLE |
包括所有数据和索引的整个表。 |
| FILE |
数据库文件。 |
| APPLICATION |
应用程序专用的资源。 |
| METADATA |
元数据锁。 |
| ALLOCATION_UNIT |
分配单元。 |
| DATABASE |
整个数据库。 |
表1.SQL Server中锁的粒度
锁的升级
前面说到锁的粒度和性能的关系。实际上,每个锁会占96字节的内存,如果有大量的小粒度锁,则会占据大量的内存。
下面我们来看一个例子,当我们选择几百行数据时(总共3W行),SQL Server会加对应行数的Key锁,如图9所示
{kind=link}
图9.341行,则需要动用341个key锁
但当所取得的行的数目增大时,比如说6000(表中总共30000多条数据),此时如果用6000个键锁的话,则会占用大约96*6000=600K左右的内存,所以为了平衡性能与并发之间的关系,SQL Server使用一个表锁来替代6000个key锁,这就是所谓的锁升级。如图10所示。
{kind=link}
图10.使用一个表锁代替6000个键锁
虽然使用一个表锁代替了6000个键锁,但是会影响到并发,我们对不在上述查询中行做更新(id是50001,不在图10中查询的范围之内),发现会造成阻塞,如图11所示。
{kind=link}
图11.锁升级提升性能以减少并发为代价
锁模式
当SQL Server请求一个锁时,会选择一个影响锁的模式。锁的模式决定了锁对其他任何锁的兼容级别。如果一个查询发现请求资源上的锁和自己申请的锁兼容,那么查询就可以执行下去,但如果不兼容,查询会被阻塞。直到所请求的资源上的锁被释放。从大类来看,SQL Server中的锁可以分为如下几类:
共享锁(S锁):用于读取资源所加的锁。拥有共享锁的资源不能被修改。共享锁默认情况下是读取了资源马上被释放。比如我读100条数据,可以想像成读完了第一条,马上释放第一条,然后再给第二条数据上锁,再释放第二条,再给第三条上锁。以此类推直到第100条。这也是为什么我在图9和图10中的查询需要将隔离等级设置为可重复读,只有设置了可重复读以上级别的隔离等级或是使用提示时,S锁才能持续到事务结束。实际上,在同一个资源上可以加无数把S锁。
排他锁(X锁): 和其它任何锁都不兼容,包括其它排他锁。排它锁用于数据修改,当资源上加了排他锁时,其他请求读取或修改这个资源的事务都会被阻塞,知道排他锁被释放为止。
更新锁(U锁) :U锁可以看作是S锁和X锁的结合,用于更新数据,更新数据时首先需要找到被更新的数据,此时可以理解为被查找的数据上了S锁。当找到需要修改的数据时,需要对被修改的资源上X锁。SQL Server通过U锁来避免死锁问题。因为S锁和S锁是兼容的,通过U锁和S锁兼容,来使得更新查找时并不影响数据查找,而U锁和U锁之间并不兼容,从而减少了死锁可能性。这个概念如图12所示。
{kind=link}
图12.如果没有U锁,则S锁和X锁修改数据很容易造成死锁
意向锁(IS,IU,IX):意向锁与其说是锁,倒不如说更像一个指示器。在SQL Server中,资源是有层次的,一个表中可以包含N个页,而一个页中可以包含N个行。当我们在某一个行中加了锁时。可以理解成包含这个行的页,和表的一部分已经被锁定。当另一个查询需要锁定页或是表时,再一行行去看这个页和表中所包含的数据是否被锁定就有点太痛苦了。因此SQL Server锁定一个粒度比较低的资源时,会在其父资源上加上意向锁,告诉其他查询这个资源的某一部分已经上锁。比如,当我们更新一个表中的某一行时,其所在的页和表都会获得意向排他锁,如图13所示。
{kind=link}
图13.当更新一行时,其所在的页和表都会获得意向锁
其它类型的构架锁,键范围锁和大容量更新锁就不详细讨论了,参看MSDN(http://msdn.microsoft.com/zh-cn/library/ms175519.aspx)
锁之间的兼容性微软提供了一张详细的表,如图14所示。
{kind=link}
图14.锁的兼容性列表
理解死锁
当两个进程都持有一个或一组锁时,而另一个进程持有的锁和另一个进程视图获得的锁不兼容时。就会发生死锁。这个概念如图15所示。
{kind=link}
图15.死锁的简单示意
下面我们根据图15的概念,来模拟一个死锁,如图16所示。
{kind=link}
图16.模拟一个死锁
可以看到,出现死锁后,SQL Server并不会袖手旁观让这两个进程无限等待下去,而是选择一个更加容易Rollback的事务作为牺牲品,而另一个事务得以正常执行。
总结
本文简单介绍了SQL Server中锁的概念,原理,以及锁的粒度,模式,兼容性和死锁。透彻的理解锁的概念是数据库性能调优以及解决死锁的基础。
本文代码:
--通过DMV查看锁的使用情况
select str(request_session_id, 4,0) as spid,
convert (varchar(20), db_name(resource_database_id)) As DB_Name,
case when resource_database_id = db_id() and resource_type = 'OBJECT'
then convert(char(20), object_name(resource_Associated_Entity_id))
else convert(char(20), resource_Associated_Entity_id)
end as object,
convert(varchar(12), resource_type) as resrc_type,
convert(varchar(12), request_type) as req_type,
convert(char(3), request_mode) as mode,
convert(varchar(8), request_status) as status
from sys.dm_tran_locks
order by request_session_id, 3 desc
--只有设置了Repeatable Read以上的隔离等级,S锁才能持续
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
BEGIN TRAN
SELECT *
FROM [Sales].[SalesOrderHeader]
where SalesOrderID<44000
select resource_type,request_mode,COUNT(*)
from sys.dm_tran_locks
where request_session_id=@@SPID
group by resource_type,request_mode
commit
xpb
T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤
简介
在SQL SERVER中,非聚集索引其实可以看作是一个含有聚集索引的表.但相比实际的表而言.非聚集索引中所存储的表的列数要窄很多,因为非聚集索引仅仅包含原表中非聚集索引的列和指向实际物理表的指针。
{kind=link}
并且,对于非聚集索引表来说,其中所存放的列是按照聚集索引来进行存放的.所以查找速度要快了很多。但是对于性能的榨取来说,SQL SERVER总是竭尽所能,假如仅仅是通过索引就可以在B树的叶子节点获取所需数据,而不再用通过叶子节点上的指针去查找实际的物理表,那性能的提升将会更胜一筹.
下面我们来看下实现这一点的几种方式.
非聚集索引的覆盖
正如前面简介所说。非聚集索引其实可以看作一个聚集索引表.当这个非聚集索引中包含了查询所需要的所有信息时,则查询不再需要去查询基本表,而仅仅是从非聚集索引就能得到数据:
{kind=link}
下面来看非聚集索引如何覆盖的:
在adventureWorks的SalesOrderHeader表中,现在只有CustomerID列有非聚集索引,而BillToAddressID没有索引,我们的查询计划会是这样:
{kind=link}
查询会根据CustomerID列上的非聚集索引找到相应的指针后,去基本表上查找数据.从执行计划可以想象,这个效率并不快。
下面我们来看覆盖索引,通过在CustomerID和BillToAddressID上建立非聚集索引,我们覆盖到了上面查询语句的所有数据:
{kind=link}
通过覆盖索引,可以看到执行计划简单到不能再简单,直接从非聚集索引的叶子节点提取到数据,无需再查找基本表!
这个性能的提升可以从IO统计看出来,下面我们来看有覆盖索引和没有覆盖索引的IO对比:
{kind=link}
索引的覆盖不仅仅带来的是效率的提升,还有并发的提升,因为减少了对基本表的依赖,所以提升了并发,从而减少了死锁!
理解INCLUDE的魔力
上面的索引覆盖所带来的效率提升就像魔术一样,但别着急,正如我通篇强调的一样,everything has price.如果一个索引包含了太多的键的话,也会带来很多副作用。INCLUDE的作用使得非聚集索引中可以包含更多的列,但不作为“键”使用。
比如:假设我们上面的那个查询需要增加一列,则原来建立的索引无法进行覆盖,从而还需要查找基本表:
{kind=link}
但是如果要包含SubTotal这个总金额,则索引显得太宽,因为我们的业务很少根据订单价格作为查询条件,则使用INCLUDE建立索引:
{kind=link}
理解INCLUDE包含的列和索引建立的列可以这样理解,把上述建立的含有INCLUDE的非聚集索引想像成:
{kind=link}
使用INCLUDE可以减少叶子“键”的大小!
非聚集索引的交叉
非聚集索引的交叉看以看作是覆盖索引的扩展!
由于很多原因,比如:
在生产环境中,我们往往不能像上面建立覆盖索引那样随意改动现有索引,这可能导致的结果是你会更频繁的被客户打电话“关照”
现有的非聚集索引已经很“宽”,你如果继续拓宽则增改查带来的性能下降的成本会高过提高查询带来的好处
这时候,你可以通过额外建立索引。正如我前面提到的,非聚集索引的本质是表,通过额外建立表使得几个非聚集索引之间进行像表一样的Join,从而使非聚集索引之间可以进行Join来在不访问基本表的情况下给查询优化器提供所需要的数据:
比如还是上面的那个例子.我们需要查取SalesOrderHeader表,通过BillToAddressID,CustomerID作为选择条件,可以通过建立两个索引进行覆盖,下面我们来看执行计划:
{kind=link}
非聚集索引的连接
非聚集索引的连接实际上是非聚集索引的交叉的一种特例。使得多个非聚集索引交叉后可以覆盖所要查询的数据,从而使得从减少查询基本表变成了完全不用查询基本表:
比如还是上面那两个索引,这时我只查询非聚集索引中包含的数据,则完全不再需要查询基本表:
{kind=link}
非聚集索引的过滤
很多时候,我们并不需要将基本表中索引列的所有数据全部索引,比如说含有NULL的值不希望被索引,或者根据具体的业务场景,有一些数据我们不想索引。这样可以:
减少索引的大小
索引减少了,从而使得对索引的查询得到了加速
小索引对于增删改的维护性能会更高
比如说,如下语句:
{kind=link}
我们为其建立聚集索引后:
{kind=link}
这时我们为其加上过滤条件,形成过滤索引:
{kind=link}
由上面我们可以看出,使用过滤索引的场景要和具体的业务场景相关,对于为大量相同的查询条件建立过滤索引使得性能进一步提升!
总结
本文从介绍了SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤。对于我们每一点从SQL SERVER榨取的性能的提升往往会伴随着另一方面的牺牲。作为数据库的开发人员或者管理人员来说,以全面的知识来做好权衡将会是非常重要.系统的学习数据库的知识不但能大量减少逻辑读的数据,也能减少客户打电话"关照”的次数:-)
T-SQL查询高级—SQL Server索引中的碎片和填充因子
简介
在SQL Server中,存储数据的最小单位是页,每一页所能容纳的数据为8060字节.而页的组织方式是通过B树结构(表上没有聚集索引则为堆结构,不在本文讨论之列)如下图:
{kind=link}
在聚集索引B树中,只有叶子节点实际存储数据,而其他根节点和中间节点仅仅用于存放查找叶子节点的数据.
每一个叶子节点为一页,每页是不可分割的. 而SQL Server向每个页内存储数据的最小单位是表的行(Row).当叶子节点中新插入的行或更新的行使得叶子节点无法容纳当前更新或者插入的行时,分页就产生了.在分页的过程中,就会产生碎片.
理解外部碎片
首先,理解外部碎片的这个“外”是相对页面来说的。外部碎片指的是由于分页而产生的碎片.比如,我想在现有的聚集索引中插入一行,这行正好导致现有的页空间无法满足容纳新的行。从而导致了分页:
{kind=link}
因为在SQL SERVER中,新的页是随着数据的增长不断产生的,而聚集索引要求行之间连续,所以很多情况下分页后和原来的页在磁盘上并不连续.
这就是所谓的外部碎片.
由于分页会导致数据在页之间的移动,所以如果插入更新等操作经常需要导致分页,则会大大提升IO消耗,造成性能下降.
而对于查找来说,在有特定搜索条件,比如where子句有很细的限制或者返回无序结果集时,外部碎片并不会对性能产生影响。但如果要返回扫描聚集索引而查找连续页面时,外部碎片就会产生性能上的影响.
在SQL Server中,比页更大的单位是区(Extent).一个区可以容纳8个页.区作为磁盘分配的物理单元.所以当页分割如果跨区后,需要多次切区。需要更多的扫描.因为读取连续数据时会不能预读,从而造成额外的物理读,增加磁盘IO.
理解内部碎片
和外部碎片一样,内部碎片的”内”也是相对页来说的.下面我们来看一个例子:
{kind=link}
我们创建一个表,这个表每个行由int(4字节),char(999字节)和varchar(0字节组成),所以每行为1003个字节,则8行占用空间1003*8=8024字节加上一些内部开销,可以容纳在一个页面中:
{kind=link}
当我们随意更新某行中的col3字段后,造成页内无法容纳下新的数据,从而造成分页:
{kind=link}
分页后的示意图:
{kind=link}
而当分页时如果新的页和当前页物理上不连续,则还会造成外部碎片
内部碎片和外部碎片对于查询性能的影响
外部碎片对于性能的影响上面说过,主要是在于需要进行更多的跨区扫描,从而造成更多的IO操作.
而内部碎片会造成数据行分布在更多的页中,从而加重了扫描的页树,也会降低查询性能.
下面通过一个例子看一下,我们人为的为刚才那个表插入一些数据造成内部碎片:
{kind=link}
通过查看碎片,我们发现这时碎片已经达到了一个比较高的程度:
{kind=link}
通过查看对碎片整理之前和之后的IO,我们可以看出,IO大大下降了:
{kind=link}
对于碎片的解决办法
基本上所有解决办法都是基于对索引的重建和整理,只是方式不同
1.删除索引并重建
这种方式并不好.在删除索引期间,索引不可用.会导致阻塞发生。而对于删除聚集索引,则会导致对应的非聚集索引重建两次(删除时重建,建立时再重建).虽然这种方法并不好,但是对于索引的整理最为有效
2.使用DROP_EXISTING语句重建索引
为了避免重建两次索引,使用DROP_EXISTING语句重建索引,因为这个语句是原子性的,不会导致非聚集索引重建两次,但同样的,这种方式也会造成阻塞
3.如前面文章所示,使用ALTER INDEX REBUILD语句重建索引
使用这个语句同样也是重建索引,但是通过动态重建索引而不需要卸载并重建索引.是优于前两种方法的,但依旧会造成阻塞。可以通过ONLINE关键字减少锁,但会造成重建时间加长.
4.使用ALTER INDEX REORGANIZE
这种方式不会重建索引,也不会生成新的页,仅仅是整理,当遇到加锁的页时跳过,所以不会造成阻塞。但同时,整理效果会差于前三种.
理解填充因子
重建索引固然可以解决碎片的问题.但是重建索引的代价不仅仅是麻烦,还会造成阻塞。影响使用.而对于数据比较少的情况下,重建索引代价并不大。而当索引本身超过百兆的时候。重建索引的时间将会很让人蛋疼.
填充因子的作用正是如此。对于默认值来说,填充因子为0(0和100表示的是一个概念),则表示页面可以100%使用。所以会遇到前面update或insert时,空间不足导致分页.通过设置填充因子,可以设置页面的使用程度:
{kind=link}
下面来看一个例子:
还是上面那个表.我插入31条数据,则占4页:
{kind=link}
通过设置填充因子,页被设置到了5页上:
{kind=link}
这时我再插入一页,不会造成分页:
{kind=link}
上面的概念可以如下图来解释:
{kind=link}
可以看出,使用填充因子会减少更新或者插入时的分页次数,但由于需要更多的页,则会对应的损失查找性能.
如何设置填充因子的值
如何设置填充因子的值并没有一个公式或者理念可以准确的设置。使用填充因子虽然可以减少更新或者插入时的分页,但同时因为需要更多的页,所以降低了查询的性能和占用更多的磁盘空间.如何设置这个值进行trade-off需要根据具体的情况来看.
具体情况要根据对于表的读写比例来看,我这里给出我认为比较合适的值:
1.当读写比例大于100:1时,不要设置填充因子,100%填充
2.当写的次数大于读的次数时,设置50%-70%填充
3.当读写比例位于两者之间时80%-90%填充
上面的数据仅仅是我的看法,具体设置的数据还要根据具体情况进行测试才能找到最优.
总结
本文讲述了SQL SERVER中碎片产生的原理,内部碎片和外部碎片的概念。以及解决碎片的办法和填充因子.在数据库中,往往每一个对于某一方面性能增加的功能也会伴随着另一方面性能的减弱。系统的学习数据库知识,从而根据具体情况进行权衡,是dba和开发人员的必修课.
有关T-SQL的10个好习惯
1.在生产环境中不要出现Select *
这一点我想大家已经是比较熟知了,这样的错误相信会犯的人不会太多。但我这里还是要说一下。
不使用Select *的原因主要不是坊间所流传的将*解析成具体的列需要产生消耗,这点消耗在我看来完全可以忽略不计。更主要的原因来自以下两点:
扩展方面的问题
造成额外的书签查找或是由查找变为扫描
扩展方面的问题是当表中添加一个列时,Select *会把这一列也囊括进去,从而造成上面的第二种问题。
而额外的IO这点显而易见,当查找不需要的列时自然会产生不必要的IO,下面我们通过一个非常简单的例子来比较这两种差别,如图1所示。
{kind=link}
图1.*带来的不必要的IO
2.声明变量时指定长度
这一点有时候会被人疏忽,因为对于T-SQL来说,如果对于变量不指定长度,则默认的长度会是1.考虑下面这个例子,如图2所示。
{kind=link}
图2.不指定变量长度有可能导致丢失数据
3.使用合适的数据类型
合适的数据类型首先是从性能角度考虑,关于这一点,我写过一篇文章详细的介绍过,有兴趣可以阅读:对于表列数据类型选择的一点思考,这里我就不再细说了
不要使用字符串类型存储日期数据,这一点也需要强调一些,有时候你可能需要定义自己的日期格式,但这样做非常不好,不仅是性能上不好,并且内置的日期时间函数也不能用了。
4.使用Schema前缀来选择表
解析对象的时候需要更多的步骤,而指定Schema.Table这种方式就避免了这种无谓的解析。
不仅如此,如果不指定Schema容易造成混淆,有时会报错。
还有一点是,Schema使用的混乱有可能导致更多的执行计划缓存,换句话说,就是同样一份执行计划被多次缓存,让我们来看图3的例子。
{kind=link}
图3.不同的schema选择不同导致同样的查询被多次缓存
5.命名规范很重要
推荐使用实体对象+操作这种方式,比如Customer_Update这种方式。在一个大型一点的数据库会存在很多存储过程,不同的命名方式使得找到需要的存储过程变得很不方便。因此有可能造成另一种问题,就是重复创建存储过程,比如上面这个例子,有可能命名规范不统一的情况下又创建了一个叫UpdateCustomer的存储过程。
6.插入大量数据时,尽量不要使用循环,可以使用CTE,如果要使用循环,也放到一个事务中
这点其实显而易见。SQL Server是隐式事务提交的,所以对于每一个循环中的INSERT,都会作为一个事务提交。这种效率可想而知,但如果将1000条语句放到一个事务中提交,效率无疑会提升不少。
打个比方,去银行存款,是一次存1000效率高,还是存10次100?下面,根据吉日的要求,补个例子,见代码1.
(
);--循环插入,不给力,我的笔记本45秒DECLARE @index INT;SET @index = 1;
INSERT dbo.TestInsert(Number) VALUES( @index);
--放到一个事务中循环,略好,但也不是最好,我的笔记本1秒BEGIN TRANDECLARE @index INT;SET @index = 1;
INSERT dbo.TestInsert(Number) VALUES( @index);
--批量插入,10W行,显示0秒,有兴趣的同学改成100W行进行测试INSERT dbo.TestInsert(Number)
SELECT TOP (100000) rn = ROW_NUMBER() OVER
--CTE方式,和上面那种方式大同小异,也是批量插入,比如:WITH cte AS(
SELECT TOP (100000) rn = ROW_NUMBER() OVER
)INSERT dbo.TestInsert(Number) SELECT rn FROM cte
代码1.几种插入方式的比较
7.where条件之后尽量减少使用函数或数据类型转换
换句话说,WHERE条件之后尽量可以使用可以嗅探参数的方式,比如说尽量少用变量,尽量少用函数,下面我们通过一个简单的例子来看这之间的差别。如图4所示。
{kind=link}
图4.在Where中使用不可嗅探的参数导致的索引查找
对于另外一些情况来说,尽量不要让参数进行类型转换,再看一个简单的例子,我们可以看出在Where中使用隐式转换代价巨大。如图5所示。
{kind=link}
图5.隐式转换带来的性能问题
8.不要使用旧的连接方式,比如(from x,y,z)
可能导致效率低下的笛卡尔积,当你看到下面这个图标时,说明查询分析器无法根据统计信息估计表中的数据结构,所以无法使用Loop join,merge Join和Hash Join中的一种,而是使用效率地下的笛卡尔积。
> 这里我再补充一点,我说得是“可能”导致,因为上面这个查询可能作为中间结果或是子查询,当你忘写了where条件时,会是笛卡尔积。你在最终结果中再用where过滤,可能得到的结果一模一样,但是中间的过程却大不相同
{kind=link}
所以,尽量使用Inner join的方式替代from x,y,z这种方式。
9.使用游标时,加上只读只进选项
首先,我的观点是:游标是邪恶的,尽量少用。但是如果一定要用的话,请记住,默认设置游标是可进可退的,如果你仅仅设置了
declare c cursor
for
这样的形式,那么这种游标要慢于下面这种方式。
declare c cursor
local static read_only forward_only
for…
所以,在游标只读只进的情况下,加上上面代码所示的选项。
10.有关Order一些要注意的事情
首先,要注意,不要使用Order by+数字的形式,比如图6这种。
{kind=link}
图6.Order By序号
当表结构或者Select之后的列变化时,这种方式会引起麻烦,所以老老实实写上列名。
还有一种情况是,对于带有子查询和CTE的查询,子查询有序并不代表整个查询有序,除非显式指定了Order By,让我们来看图7。
{kind=link}
图7.虽然在CTE中中有序,但显式指定Order By,则不能保证结果的顺序