Awk使用及网站日志分析
Awk简介
概述
- awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
- awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk。
- awk程序的报告生成能力通常用来从大文本文件中提取数据元素并将它们格式化成可读的报告。最完美的例子是格式化日志文件。awk程序允许从日志文件中只过滤出你想要看的数据
Awk使用
awk命令格式和选项
语法形式
awk [options] 'script' var=value file(s)
awk [options] -f scriptfile var=value file(s)常用命令选项
- -F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:
- -v var=value 赋值一个用户定义变量,将外部变量传递给awk
- -f scripfile 从脚本文件中读取awk命令
- -m[fr] val 对val值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
模式:
- /正则表达式/:使用通配符的扩展集。
- 关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试。
- 模式匹配表达式:用运算符~(匹配)和~!(不匹配)。
- BEGIN语句块、pattern语句块、END语句块。
awk脚本基本结构
awk 'BEGIN{ print "start" } pattern{ commands } END{ print "end" }' file一个awk脚本通常由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块3部分组成,这三个部分是可选的。任意一个部分都可以不出现在脚本中,脚本通常是被单引号或双引号中,例如:
awk 'BEGIN{ i=0 } { i++ } END{ print i }' filename
awk "BEGIN{ i=0 } { i++ } END{ print i }" filenameawk的工作原理
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'第一步:执行BEGIN{ commands }语句块中的语句;
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ commands }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{ commands }语句块。
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中。
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
pattern语句块中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块。
示例
echo -e "A line 1\nA line 2" | awk 'BEGIN{ print "Start" } { print } END{ print "End" }'打印结果:
Start
A line 1
A line 2
End当使用不带参数的print时,它就打印当前行,当print的参数是以逗号进行分隔时,打印时则以空格作为定界符。在awk的print语句块中双引号是被当作拼接符使用,例如:
echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1,var2,var3; }'打印结果:
v1 v2 v3双引号拼接使用:
echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1"="var2"="var3; }'v1=v2=v3{ }类似一个循环体,会对文件中的每一行进行迭代,通常变量初始化语句(如:i=0)以及打印文件头部的语句放入BEGIN语句块中,将打印的结果等语句放在END语句块中。
awk内置变量
说明:[A][N][P][G]表示第一个支持变量的工具,[A]=awk、[N]=nawk、[P]=POSIXawk、[G]=gawk
$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$0 这个变量包含执行过程中当前行的文本内容。
[N] ARGC 命令行参数的数目。
[G] ARGIND 命令行中当前文件的位置(从0开始算)。
[N] ARGV 包含命令行参数的数组。
[G] CONVFMT 数字转换格式(默认值为%.6g)。
[P] ENVIRON 环境变量关联数组。
[N] ERRNO 最后一个系统错误的描述。
[G] FIELDWIDTHS 字段宽度列表(用空格键分隔)。
[A] FILENAME 当前输入文件的名。
[P] FNR 同NR,但相对于当前文件。
[A] FS 字段分隔符(默认是任何空格)。
[G] IGNORECASE 如果为真,则进行忽略大小写的匹配。
[A] NF 表示字段数,在执行过程中对应于当前的字段数。
[A] NR 表示记录数,在执行过程中对应于当前的行号。
[A] OFMT 数字的输出格式(默认值是%.6g)。
[A] OFS 输出字段分隔符(默认值是一个空格)。
[A] ORS 输出记录分隔符(默认值是一个换行符)。
[A] RS 记录分隔符(默认是一个换行符)。
[N] RSTART 由match函数所匹配的字符串的第一个位置。
[N] RLENGTH 由match函数所匹配的字符串的长度。
[N] SUBSEP 数组下标分隔符(默认值是34)。示例:
echo -e "line1 f2 f3\nline2 f4 f5\nline3 f6 f7" | awk '{print "Line No:"NR", No of fields:"NF, "$0="$0, "$1="$1, "$2="$2, "$3="$3}'Line No:1, No of fields:3 $0=line1 f2 f3 $1=line1 $2=f2 $3=f3
Line No:2, No of fields:3 $0=line2 f4 f5 $1=line2 $2=f4 $3=f5
Line No:3, No of fields:3 $0=line3 f6 f7 $1=line3 $2=f6 $3=f7使用print $NF可以打印出一行中的最后一个字段,使用$(NF-1)则是打印倒数第二个字段,其他以此类推:
echo -e "line1 f2 f3\n line2 f4 f5" | awk '{print $NF}'f3
f5echo -e "line1 f2 f3\n line2 f4 f5" | awk '{print $(NF-1)}'打印结果:
f2
f4打印每一行的第二和第三个字段:
awk '{ print $2,$3 }' filename统计文件中的行数:
awk 'END{ print NR }' filename以上命令只使用了END语句块,在读入每一行的时,awk会将NR更新为对应的行号,当到达最后一行NR的值就是最后一行的行号,所以END语句块中的NR就是文件的行数。
将外部变量值传递给awk
借助-v选项,可以将外部值(并非来自stdin)传递给awk:
VAR=10000 echo | awk -v VARIABLE=$VAR '{ print VARIABLE }'另一种传递外部变量方法:
var1="aaa"
var2="bbb"
echo | awk '{ print v1,v2 }' v1=$var1 v2=$var2当输入来自于文件时使用:
awk '{ print v1,v2 }' v1=$var1 v2=$var2 filename以上方法中,变量之间用空格分隔作为awk的命令行参数跟随在BEGIN、{}和END语句块之后。
awk高级输入输出
读取下一条记录
awk中next语句使用:在循环逐行匹配,如果遇到next,就会跳过当前行,直接忽略下面语句。而进行下一行匹配。net语句一般用于多行合并:
cat text.txt
a
b
c
d
eawk 'NR%2==1{next}{print NR,$0;}'
text.txt
2 b
4 d简单地读取一条记录
awk getline用法:输出重定向需用到getline函数。getline从标准输入、管道或者当前正在处理的文件之外的其他输入文件获得输入。它负责从输入获得下一行的内容,并给NF,NR和FNR等内建变量赋值。如果得到一条记录,getline函数返回1,如果到达文件的末尾就返回0,如果出现错误,例如打开文件失败,就返回-1。
- 当其左右无重定向符|或<时:getline作用于当前文件,读入当前文件的第一行给其后跟的变量var或$0(无变量),应该注意到,由于awk在处理getline之前已经读入了一行,所以getline得到的返回结果是隔行的。
- 当其左右有重定向符|或<时:getline则作用于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入,那么getline返回的是该文件的第一行,而不是隔行。
示例:
执行linux的date命令,并通过管道输出给getline,然后再把输出赋值给自定义变量out,并打印它:
awk 'BEGIN{ "date" | getline out; print out }'执行shell的date命令,并通过管道输出给getline,然后getline从管道中读取并将输入赋值给out,split函数把变量out转化成数组mon,然后打印数组mon的第二个元素:
awk 'BEGIN{ "date" | getline out; split(out,mon); print mon[2] }'命令ls的输出传递给geline作为输入,循环使getline从ls的输出中读取一行,并把它打印到屏幕。这里没有输入文件,因为BEGIN块在打开输入文件前执行,所以可以忽略输入文件。
awk 'BEGIN{ while( "ls" | getline) print }'关闭文件
awk中允许在程序中关闭一个输入或输出文件,方法是使用awk的close语句。
close("filename")filename可以是getline打开的文件,也可以是stdin,包含文件名的变量或者getline使用的确切命令。或一个输出文件,可以是stdout,包含文件名的变量或使用管道的确切命令。
输出到一个文件
awk中允许用如下方式将结果输出到一个文件:
echo | awk '{printf("hello word!\n") > "datafile"}'或
echo | awk '{printf("hello word!\n") >> "datafile"}'设置字段定界符
默认的字段定界符是空格,可以使用-F "定界符" 明确指定一个定界符:
awk -F: '{ print $NF }' /etc/passwd或
awk 'BEGIN{ FS=":" } { print $NF }' /etc/passwd在BEGIN语句块中则可以用OFS=“定界符”设置输出字段的定界符。
流程控制语句
在linux awk的while、do-while和for语句中允许使用break,continue语句来控制流程走向,也允许使用exit这样的语句来退出。break中断当前正在执行的循环并跳到循环外执行下一条语句。if 是流程选择用法。awk中,流程控制语句,语法结构,与c语言类型。有了这些语句,其实很多shell程序都可以交给awk,而且性能是非常快的。下面是各个语句用法。
条件判断语句
if(表达式)
语句1
else
语句2格式中语句1可以是多个语句,为了方便判断和阅读,最好将多个语句用{}括起来。
awk分枝结构允许嵌套,其格式为:
if(表达式)
{语句1}
else if(表达式)
{语句2}
else
{语句3}示例:
awk 'BEGIN{
test=100;
if(test>90){
print "very good";
}
else if(test>60){
print "good";
} else{
print "no pass";
}
}'每条命令语句后面可以用;分号结尾。
循环语句
while语句:
while(表达式)
{语句}示例:
awk 'BEGIN{
test=100;
total=0;
while(i<=test){
total+=i;
i++;
}
print total;
}'for循环
for循环有两种格式:
格式一:
for(变量 in 数组)
{语句}格式二:
for(变量;条件;表达式)
{语句}do循环
do
{语句} while(条件)示例:
awk 'BEGIN{
total=0;
i=0;
do {total+=i;i++;} while(i<=100)
print total;
}'其他语句
- break 当 break 语句用于 while 或 for 语句时,导致退出程序循环。
- continue 当 continue 语句用于 while 或 for 语句时,使程序循环移动到下一个迭代。
- exit 语句使主输入循环退出并将控制转移到END,如果END存在的话。如果没有定义END规则,或在END中应用exit语句,则终止脚本的执行。
数组应用
数组是awk的灵魂,处理文本中最不能少的就是它的数组处理。因为数组索引(下标)可以是数字和字符串在awk中数组叫做关联数组(associative arrays)。awk 中的数组不必提前声明,也不必声明大小。数组元素用0或空字符串来初始化,这根据上下文而定。
数组的定义
数字做数组索引(下标):
Array[1]="sun"
Array[2]="kai"字符串做数组索引(下标):
Array["first"]="www"
Array["last"]="name"
Array["birth"]="1987"读取数组的值
{ for(item in array) {print array[item]}; } #输出的顺序是随机的
{ for(i=1;i<=len;i++) {print array[i]}; } #len是数组的长度数组相关函数
得到数组长度:
awk 'BEGIN{info="it is a test";lens=split(info,tA," ");print length(tA),lens;}'length返回字符串以及数组长度,split进行分割字符串为数组,也会返回分割得到数组长度。
awk 'BEGIN{info="it is a test";split(info,tA," ");print asort(tA);}'asort对数组进行排序,返回数组长度。
输出数组内容(无序,有序输出):
awk 'BEGIN{info="it is a test";split(info,tA," ");for(k in tA){print k,tA[k];}}'1 it
2 is
3 a
4 test判断键值存在以及删除键值:
awk 'BEGIN{tB["a"]="a1";tB["b"]="b1";if( "c" in tB){print "ok";};for(k in tB){print k,tB[k];}}'a a1
b b1#删除键值:
awk 'BEGIN{tB["a"]="a1";tB["b"]="b1";delete tB["a"];for(k in tB){print k,tB[k];}}'b b1字符串操作
查找字符串(index使用)
awk 'BEGIN{info="this is a test2010test!";print index(info,"test")?"ok":"no found";}'正则表达式匹配查找(match使用)
awk 'BEGIN{info="this is a test2010test!";print match(info,/[0-9]+/)?"ok":"no found";}'截取字符串(substr使用)
awk 'BEGIN{info="this is a test2010test!";print substr(info,4,10);}'从第 4个 字符开始,截取10个长度字符串
字符串分割(split使用)
awk 'BEGIN{info="this is a test";split(info,tA," ");print length(tA);for(k in tA){print k,tA[k];}}'4
4 test
1 this
2 is
3 a一般函数
打开外部文件(close用法)
awk 'BEGIN{while("cat /etc/passwd"|getline){print $0;};close("/etc/passwd");}'逐行读取外部文件(getline使用方法)
awk 'BEGIN{while(getline < "/etc/passwd"){print $0;};close("/etc/passwd");}'awk 'BEGIN{print "Enter your name:";getline name;print name;}'调用外部应用程序(system使用方法)
awk 'BEGIN{b=system("ls -al");print b;}'网站日志分析
简介
下面使用Linux中的Awk对tomcat中日志文件做一些分析,主要统计pv,uv等。
日志文名称:access_2013_05_30.log,大小57.7 MB 。
这次分析只是简单演示,所以不是太精确地处理数据。
日志地址:http://download.csdn.net/detail/u011204847/9496357
日志数据示例:
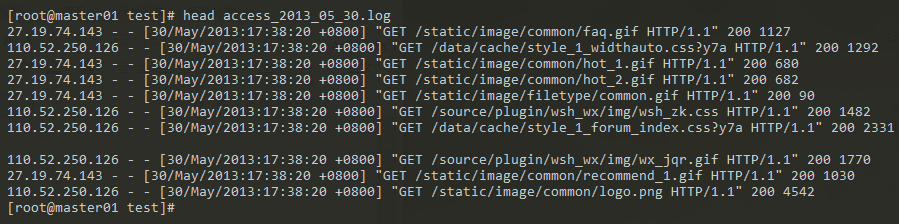
日志总行数:

打印的第七列数据为日志的URL:
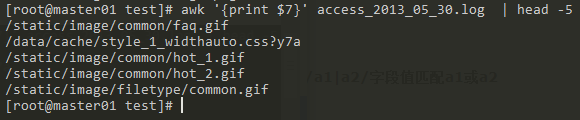
分析中用到的一些知识:
扩展,
shell中的管道|
command 1 | command 2 #他的功能是把第一个命令command 1执行的结果作为command 2的输入传给command 2wc -l #统计行数uniq -c #在输出行前面加上每行在输入文件中出现的次数uniq -u #仅显示不重复的行sort -nr
- -n:依照数值的大小排序
- -r:以相反的顺序来排序
- -k:按照哪一列进行排序
head -3 #取前三名网站日志分析步骤
数据清洗:
1、第一次清洗:去除URL中以/static/开头的URL
awk '($7 !~ /^\/static\//){print $0}' access_2013_05_30.log > clean_2013_05_30.log去除前:

去除后:

2、第二次清洗:去除图片、css和js
awk '($7 !~ /\.jpg|\.png|\.jpeg|\.gif|\.css|\.js/) {print $0}' clean_2013_05_30.log > clean2_201 3_05_30.log
PV
pv是指网页访问次数
方法:统计所有数据的总行数
数据清洗:对原始数据中的干扰数据进行过滤
awk 'BEGIN{pv=0}{pv++}END{print "pv:"pv}' clean2_2013_05_30.log > pv_2013_05_30
UV
uv指的是访问人数,也就是独立IP数
对ip重复的数据进行去重,然后再统计所有行数
awk '{print $1}' clean2_2013_05_30.log |sort -n |uniq -u |wc -l > uv_2013_05_30
访问最多的IP(前10名)
对ip重复的数据进行去重的时候还要汇总,取前10名
awk '{print $1}' clean2_2013_05_30.log | sort -n | uniq -c |sort -nr -k 1|head -10 > top10_2013_05_30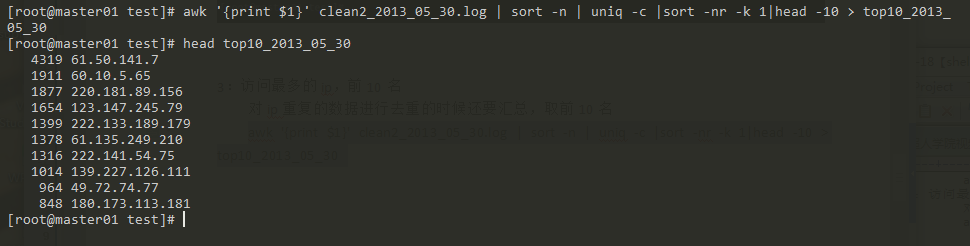
访问前十的URL(可以用来分析网站哪个模块最受欢迎)
awk '{print $7}' clean2_2013_05_30.log | sort | uniq -c |sort -nr -k 1|head -10 > top10URL_2013_ 05_30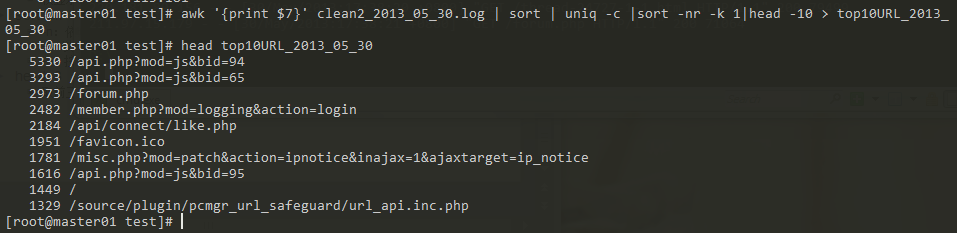
使用Java实现访问量前十的IP地址。
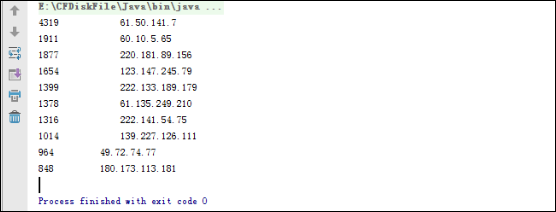
代码示例:
import java.io.*;
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Created by Chen on 2016/4/13.
*/
public class RegexTest {
public static void main(String[] args) throws IOException {
//日志格式:27.19.74.143 - - [30/May/2013:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127
//需要解析的源文件
File file = new File("D:\\clean2_2013_05_30.log");
//高效字符读入流
BufferedReader bufr = new BufferedReader(new InputStreamReader(new FileInputStream(file)));
String line = null;
//建立TreeMap,Key为IP地址,Value为IP出现次数
Map<String, Integer> map = new TreeMap<>();
while ((line = bufr.readLine()) != null) {
String ip = parseIP(line);
map.put(ip, map.get(ip) == null ? 1 : map.get(ip) + 1);
}
Set<String> set = map.keySet();
//创建一个具有匿名比较器的TreeSet集合 :作用是让存入的元素先按照Key排序,相同则继续按照Value排序。
//这个TreeSet将用来存储IP地址和出现次数反转后的每个元素。
TreeSet<Map.Entry<Integer, String>> treeSet = new TreeSet<>(new Comparator<Map.Entry<Integer, String>>() {
@Override
public int compare(Map.Entry<Integer, String> o1, Map.Entry<Integer, String> o2) {
int result = o1.getKey() - o2.getKey();
if (result == 0) {
result = o1.getValue().compareTo(o2.getValue());
}
return -result;
}
});
//把IP地址和出现次数反转,然后放入上面具有比较器的TreeSet中
for (Iterator<String> it = set.iterator(); it.hasNext(); ) {
String ip = it.next();
Integer n = map.get(ip);
treeSet.add(new AbstractMap.SimpleEntry(n, ip));
}
//遍历并打印出现次数和IP地址(次数最多的前十个)
int count = 0;
Iterator<Map.Entry<Integer, String>> itr = treeSet.iterator();
while (itr.hasNext()) {
if (count == 10) {
break;
}
Map.Entry<Integer, String> en = itr.next();
int n = en.getKey();
System.out.println(n + "\t\t\t" + en.getValue());
count++;
}
}
//解析IP地址
public static String parseIP(String str) {
Pattern compile = Pattern.compile("[0-9]+(\\.[0-9]+){3}");
//解析IP地址
Matcher matcher = compile.matcher(str);
String group = "";
if (matcher.find()) {
group = matcher.group();
}
return group;
}
}