01 摘要
对分布式系统进行大规模测试通常是一个昂贵但又必要的流程。由于世界上很多公司和机构都依赖Alluxio技术,我们非常重视Alluxio的测试。因此,我们需要解决的一个问题是如何在不耗尽资源的情况下进行大规模测试。在本博客中,我们将展示Alluxio开源项目的开发维护者如何利用公有云基础设施以经济高效的方式构建和测试我们的系统。我们将Alluxio与流行的计算框架(如Spark和Hive)和广泛使用的存储系统(如HDFS和S3)进行测试。通过使用Amazon AWS EC2,我们能够以每小时16美元的成本,测试包含1000多个Alluxio woker的集群。
以下是本文提供的一些要点:
- 给希望在公有云上进行大规模测试软件的用户提供建议
- Alluxio开发维护人员是如何进行大规模系统测试的
- Alluxio大规模运行的调优技巧
- 在试验大规模分布式系统时可能面临的挑战及其分析
02 大规模测试分布式系统
软件工程师面临的一个主要挑战是在将代码发布交付给用户之前正确地测试代码。当软件同时在数百或数千台机器上运行时,需彼此进行通信和协调,这些挑战将更加复杂。许多为“大数据”设计的分布式系统都是为了方便水平扩展而设计的。然而,现实中往往很难说明这些系统可以实际扩展到什么程度,直到有人真正投入时间和资源来在现实环境中对它们进行大规模测试。这是由于在小规模测试期间,各种类型的瓶颈问题可能难以被发现。很多时候,在开发者自己验证他们的系统可以承受多大压力前,用户在使用过程中已经不小心给系统的压力到了极限。
那么为什么开发人员不能在用户之前构建大型集群并进行充分测试呢?这一切归根到底是因为为时间和金钱,配置具有数千个节点的集群是昂贵且耗时的。许多公司会聘请几名全职工程师来维护单个集群。许多工程团队根本没有可用的资源来在数千个节点上安装、启动和定期测试他们的软件。Alluxio的开发维护者尽最大努力减轻这种影响,以便我们可以在发布之前测试并完全审查所有功能。
03 大规模测试Alluxio
3.1 什么是Alluxio
对于新手来说,Alluxio是一个开源虚拟分布式文件系统,为混合和多云部署环境中的大数据和机器学习应用程序提供统一的数据访问层。Alluxio支持像Spark,Presto等分布式计算引擎或TensorFlow等机器学习框架透明地访问底层不同的持久存储系统(包括HDFS,S3,Azure等),同时积极利用内存缓存以加速数据访问。

图1 Alluxio位于存储和计算应用程序之间
Alluxio遵循主从架构。Worker负责处理数据的传输、存储和检索,master负责处理整个集群的元数据。如果您有兴趣了解有关Alluxio架构的更多信息,我们建议您阅读我们的架构文档(见文末链接1 )。
3.2 我们如何测试
Alluxio用户面临的大多数扩展性问题通常与存储在Alluxio中的文件数据大小无关。相反,许多问题是由元数据大小(与文件和目录的数量成比例)以及在大量worker节点执行某些操作的开销导致的。对于维护者来说,扩展性测试的重点是在启动大量Alluxio worker并导入大量文件/目录之后,验证功能的正确性并评测某些操作的性能。
Alluxio的设计允许我们能够模拟大型集群,且无需启动数百或上千个公有云实例。我们在单个EC2实例上从alluxio映像启动多个docker容器,与在每个单实例上对应启动一个Alluxio worker相比,这使我们节省了成本和时间。每个云实例加载多个worker可以尽可能多地压榨并利用实例中的资源。通过仔细选择实例类型,可以在一个实例上容纳多达100个Alluxio worker!每个worker都可以访问自己的小型ramdisk,其大小在64MB到256MB之间。通过这种配置,Alluxio worker的整个占用空间通常保持在1.2GB的RAM内,包括ramdisk。借助一些自动化工具,我们可以在不到15分钟的时间内部署和拆除包含1000个worker的集群。
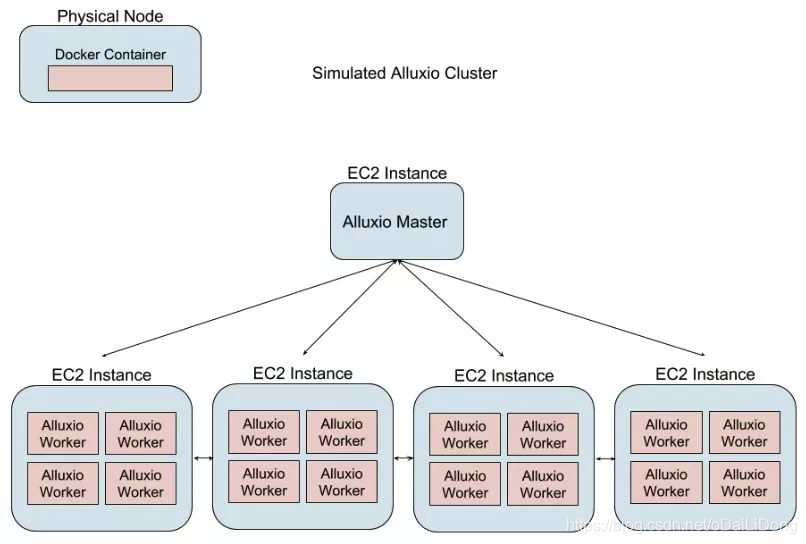
图2 模拟Alluxio集群的架构
在我们的模拟集群中,当一次在同一节点上运行多个worker,它们将在单个系统中争用相同的资源。这会产生人们通常不会看到的瓶颈。因此,这些模拟部署不能用于运行性能测试,它的性能测试结果也不能与真实集群相比较。但是,我们仍然可以使用这些集群进行功能性验证,仍然可以测试Alluxio的功能正确性,以确保新旧功能在包含数千个worker的集群的端到端测试场景中正常运行。
但是,我们并没有将master容器化,它运行在单独EC2实例上,和worker节点分离,这点与真实环境相似。在此架构中,即使使用容器化的worker,仍然可以捕获有关master性能的信息。可以通过master记录元数据操作的性能,这对Alluxio的整体性能及其处理数千个并发客户端的能力至关重要。
04 挑战
本节我们将讨论构建支持上千个worker测试集群的基础架构所面临的一些挑战及其对我们测试的相关影响。
4.1 端口分配
为了能够在单个集群上启动多个worker,每个容器的网络配置必须允许它与Alluxio集群中的其他进程通信。幸运的是,Docker公开了几种不同类型的网络驱动程序(见文末链接2)。因为Alluxio worker必须能够跨多个主机相互通信,最简单的驱动程序是host networking(见文末链接3)。该网络驱动程序使用物理实例的网络适配器,还利用系统端口命名空间内的端口。但是对于host networking,如果不同worker的配置完全相同,那么Alluxio worker实例上将存在端口冲突。
模拟部署的另一要求是集群必须能够在部署之前动态扩展,而非固定大小。在运行时跟踪已使用和未使用的端口可能会很麻烦,尤其是对于可能会改变大小的集群。我们意识到,端口为0的套接字syscalls的默认行为是在临时端口的允许范围内分配端口(请参阅Java文档见文末链接4 )。因此,通过将所有Alluxio worker端口设置为0,可以实现在运行时动态分配端口。唯一必须保持一致的属性是Alluxio master RPC端口和主机名,以便worker可以正确地向master注册。
如果其他服务与Alluxio一起运行(例如Hadoop DataNode或NodeManagers),那么Alluxio worker必须在Hadoop服务之后启动,否则其他服务之间的端口冲突可能性会增加。
当每个worker向Alluxio master注册时,会向master告诉它使用的端口号。利用每个Alluxio worker的端口信息,Alluxio master能够通过端口区分同一主机上的worker。
4.2 DNS
需要解决的另一个问题是集群中节点之间的DNS,以便Alluxio master可以联系各个worker,worker间也可以相互联系。每个容器都需要具有唯一的主机名,但因为同一EC2实例上有许多worker,因此需要许多不同的主机名又需要能够被解析为相同的IP地址。
有如下一些方式能够让DNS在模拟集群的节点间工作。因为我们的许多测试集群都是短暂运行的,最简单的方法是使用私有EC2实例IP修改每台机器上的/etc/hosts文件。我们的配置工具负责生成和添加条目,这只有在创建集群时才需要完成。
{IP address_1} {container_hostname_1_1}{container_hostname_1_2} …
{IP address_2} {container_hostname_2_1}{container_hostname_2_2} …
使用这种格式后,我们发现Java(Alluxio的开发语言)由于某种原因,解析此文件不同于其他Linux系统实用程序。在为单个实体添加15-20个容器的主机名后,Java无法为该主机上的容器提供正确的DNS解析,虽解析失败但未声明原因。我们的解决方法是简单地将每个实体分为单独IP和主机名。
{IP_address_1} {container_hostname_1_1}
{IP_address_1} {container_hostname_1_2}…
{IP_address_2} {container_hostname_2_1}
{IP_address_2}{container_hostname_2_1}…
这种方法适用于我们的场景,并允许每个节点解析主机名。Alluxio master和worker可以在同一主机内或不同主机之间相互通信。
4.3容器占用和内存约束
扩展群集时,必须启动尽可能多的worker。在测试之前,我们尝试分析worker进程的内存占用情况,以查看在不同工作负载大小下运行时worker使用了多少系统内存。通过了解Alluxio worker如何使用内存,我们可以更好地规划在单个云实例上启动的实例类型和worker数量,结果如下所示。
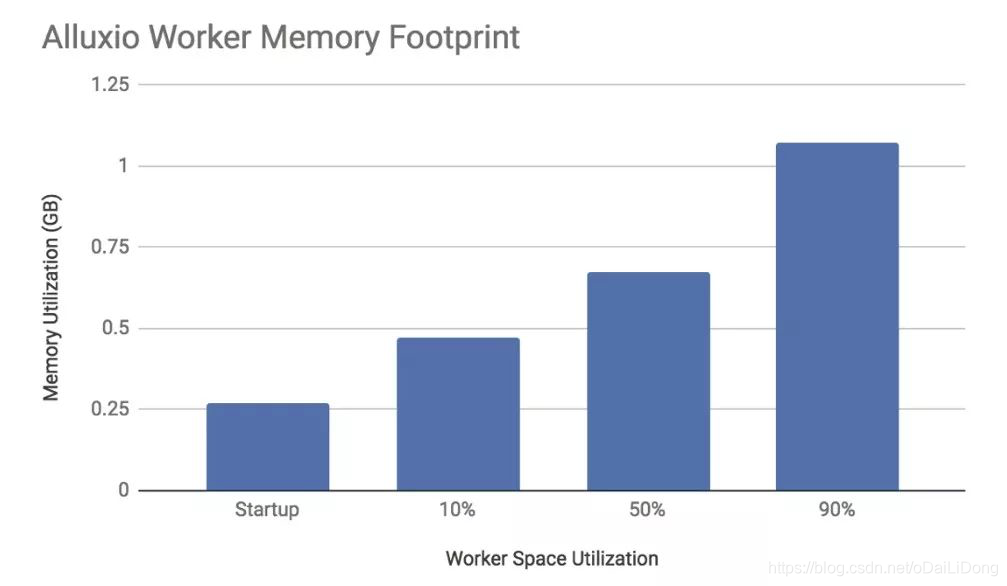
图3 worker系统内存利用率
通过收集这些数据,我们将有足够信息有效地为我们的测试框架计算出集群和实例规模大小。同样地,这能够帮助我们准确确定在给定一组固定计算资源的情况下运行Alluxio测试集群的规模。
4.4 Alluxio配置调优
为了让我们的测试以数千worker的规模运行,需对一些Alluxio配置参数进行调优。Alluxio开源文档(见文末链接5)提供了许多关于如何配置Alluxio以运行更多worker的贴士。需要针对大规模测试场景重新配置的参数是Alluxio master的Java最大堆大小(-Xmx)以及以下Alluxio站点属性。
alluxio.master.worker.threads.min
alluxio.master.workers.threads.max
alluxio.user.block.master.client.threads
alluxio.user.file.master.client.threads
alluxio.worker.block.heartbeat.interval
alluxio.worker.filesystem.heartbeat.interval
每个属性的确切值因集群的大小而异。前四个属性会影响master在与客户端或worker交互进行并发操作时使用的线程数。为了提高响应能力,可以扩展线程池大小。第二组属性关于worker与master心跳的频率。通过增加心跳间隔,master不必经常执行健康检查,这会留下更多CPU周期来为客户端请求提供服务。
4.5 系统参数调优
除了调整Alluxio系统参数外,还有其他操作系统级的参数可以调整,以便Alluxio在运行数千个worker时更顺畅地运行。操作系统参数的确切配置取决于部署情况,推荐配置可以在文末链接5中找到,仅master节点需要这些更改。可能有用的主要参数是:
kernel.pid_max; sysctl -wkernel.pid_max=<new value>
vm.max_map_count; sysctl -wvm.max_map_count=<new value>
在master和worker上配置ulimits 也很有用。增加单个用户的最大进程限制以及打开文件限制可以缓解在单个实例上启动大量worker时遇到的问题。
更具体地,修改RHEL系统上的ulimit是不够的。需要修改 /etc/security/lim- its.d/*-nproc.conf 下的文件才能使新限制生效。
4.6 工作负载配置
最后,为了模拟我们的系统经常在企业部署中看到的高并发环境,我们必须解决两个挑战:能够在短时间内快速重建大型文件系统(包含数十万个文件的目录)以及模拟同时访问同一文件系统的大量的并发客户端。
幸运的是,Alluxio 1.8提供了一个可以同时创建数千个文件的工具,每个文件都存储少量的随机数据。这允许我们快速地重建大型文件目录。下面提供了一个示例命令:
./bin/alluxio runClassalluxio.cli.RunOperation -op CreateFile -t 20 -s 4096 -n100000 -d /test_dir
此命令使用Alluxio中的CreateFile操作创建100,000个4096字节的文件。
cli.RunOperation类,它将创建并行化为20个线程,并将所有文件放入位于/test_dir的目录中。这些文件包含随机字节。
通过创建许多文件,可以测试当master上存储大量元数据时的Alluxio。复本和TTL删除(见文末链接6)等功能是可以通过简单地创建大量文件来进行测试的示例。
我们还想在模拟集群上测试实际工作负载,这意味着在Alluxio上生成数据和运行查询将使用尽可能多的并发连接。最常用的工作负载基准之一是TPC-DS,利用从TPC-DS(见文末链接7)生成的数据,集群可以使用计算框架(如Spark 见文末链接8,基于Tez / MapReduce的HIVE 见文末链接9)来运行基准测试中的查询。为了在较少量的资源上尽可能地模拟大型工作负载,从Tez,MapReduce或Spark生成的任务必须将数据拆分为较小块。通过将数据拆分成更小的块,将创建更多的容器或executor,从而并发访问存储的数据。每个框架都有许多参数,必须调整这些参数才能实现任务高并发。
Spark限制executor的JVM堆大小至少为512MB,根据所需的实例数和并发级别以及手头的资源,加上Alluxio还有GB级没有使用的RAM空间,我们可以将executor的数量增加2倍。在命令行上使用Spark的–executor-memory调整其值。
YARN和相关的计算框架被配置为适应尽可能多的executor或MapReduce容器。如前所述,通过一次利用尽可能多的资源,大规模测试的成本将被降低。通过修改容器大小的最小值(yarn.scheduler.minimum-allocation-mb),我们可以在单个节点上分配更多的YARN容器。然后通过修改MapReduce的最小和最大拆分大小(mapreduce.input.fileinputformat.split.minsize和mapreduce.input.fileinputformat.split.minsize)或Tez(tez.grouping.min-size和tez.grouping.max-size),可以在相同数量的数据上同时启动更多任务。对于Tez,参数tez.grouping.split-waves也可能影响作业的并行度(请参阅tez wiki页面见文末链接10 以获得解释)。通过调整这些参数可以增加单个作业启动的任务数量,从而模拟许多同时连接的Alluxio客户端,进而扩展到数千个节点来压测系统。
05 结果
Alluxio现在能够在模拟环境中以数千个worker的规模进行测试。这使得我们团队能够在向社区发布Alluxio软件之前严格测试Alluxio的可扩展性。通过预先测试,我们团队能够构建更短的开发维护周期,并比以前更快地识别和修复代码中的问题。用户可以放心地知道,我们的软件即使在扩展到数千个节点时也经过了全面测试。
06 未来的改进
在未来,我们希望改进我们处理DNS的方式,以便可以部署更长时运行的集群。更好的DNS系统意味着我们可以随意添加和删除节点,以便扩大我们的集群。它还允许我们大规模测试Alluxio的稳定性。接下来,大规模操作对Alluxio worker内存空间占用的改进将能够取得整体的提升。它不仅可以减少模拟扩展集群中的资源争用,还可以在运行Alluxio时带来整体收益。
更多精彩内容,请点击文末“阅读原文”关注Alluxio官方网站!
附录链接:
链接1:
https://www.alluxio.org/docs/1.8/en/Architecture-DataFlow.html
链接2:
https://docs.docker.com/network/
链接3:
https://docs.docker.com/network/host/
链接4:
https://docs.oracle.com/javase/8/docs/api/java/net/ServerSocket.html#ServerSocket-int-
链接5:
https://www.alluxio.org/docs/1.8/en/advanced/Scalability-Tuning.html
链接6:
https://www.alluxio.org/docs/1.8/en/advanced/Alluxio-Storage-Management.html#setting-time-to-live-ttl
链接7:
https://github.com/hortonworks/hive-testbench
链接8:
https://www.alluxio.org/docs/1.8/en/compute/Spark.html
链接9:
https://www.alluxio.org/docs/1.8/en/compute/Hive.html
链接10:
https://cwiki.apache.org/confluence/display/TEZ/How+initial+task+parallelism+work
摘自:Alluxio官方微信号: Alluxio_China
对alluxio感兴趣的伙伴,可以加我微信: 510570367, 友情帮拉微信群!