版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/xufei_0320/article/details/87902526
LinkedList简介
LinkedList是基于双向链表实现的,其不仅实现了List接口实现了一个列表,同时也实现了Deque接口,使其可以作为一个队列甚至是栈使用。在Java 7以前,LinkedList实现的是双向循环链表,在Java 7时改为双向链表。它是非线程安全的,链表的特性使其具有高效的插入和删除,但是在查询上效率稍低。
源码分析
节点源码
既然它是基于双向链表实现的,那么首先来看一下它的节点源码:
/**
* LinkedList内部类,用于双向链表的节点
*/
private static class Node<E> {
// 实际存放元素的
E item;
// 指向当前节点的后继节点
Node<E> next;
// 指向当前节点的前驱节点
Node<E> prev;
/**
* 节点的构造函数,传入前驱节点和节点内容以及后继节点,构造一个新节点
*/
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
节点的源码相对简单,上面代码中已经加上了详细注释,就不再多展开了。
添加节点
添加节点有两个方法,即add(E e)和add(int index, E e),我们一一来看:
-
add(E e)这个方法是用于直接向链表后面添加元素,其源码如下
/** * 向链表后添加元素 */ public boolean add(E e) { linkLast(e); return true; } /** * 在链表尾节点后添加元素 */ void linkLast(E e) { // 拿到LinkedList尾节点 final Node<E> l = last; // 以元素e构造新节点,其前驱节点为原尾节点,后继节点为null final Node<E> newNode = new Node<>(l, e, null); // 以新节点替换原尾节点 last = newNode; // 是否为空链表 if (l == null) // 若是,则头节点也设置为新节点 first = newNode; else // 若不是,则让原尾节点的后继指向新节点 l.next = newNode; size++; modCount++; }其图示如下:
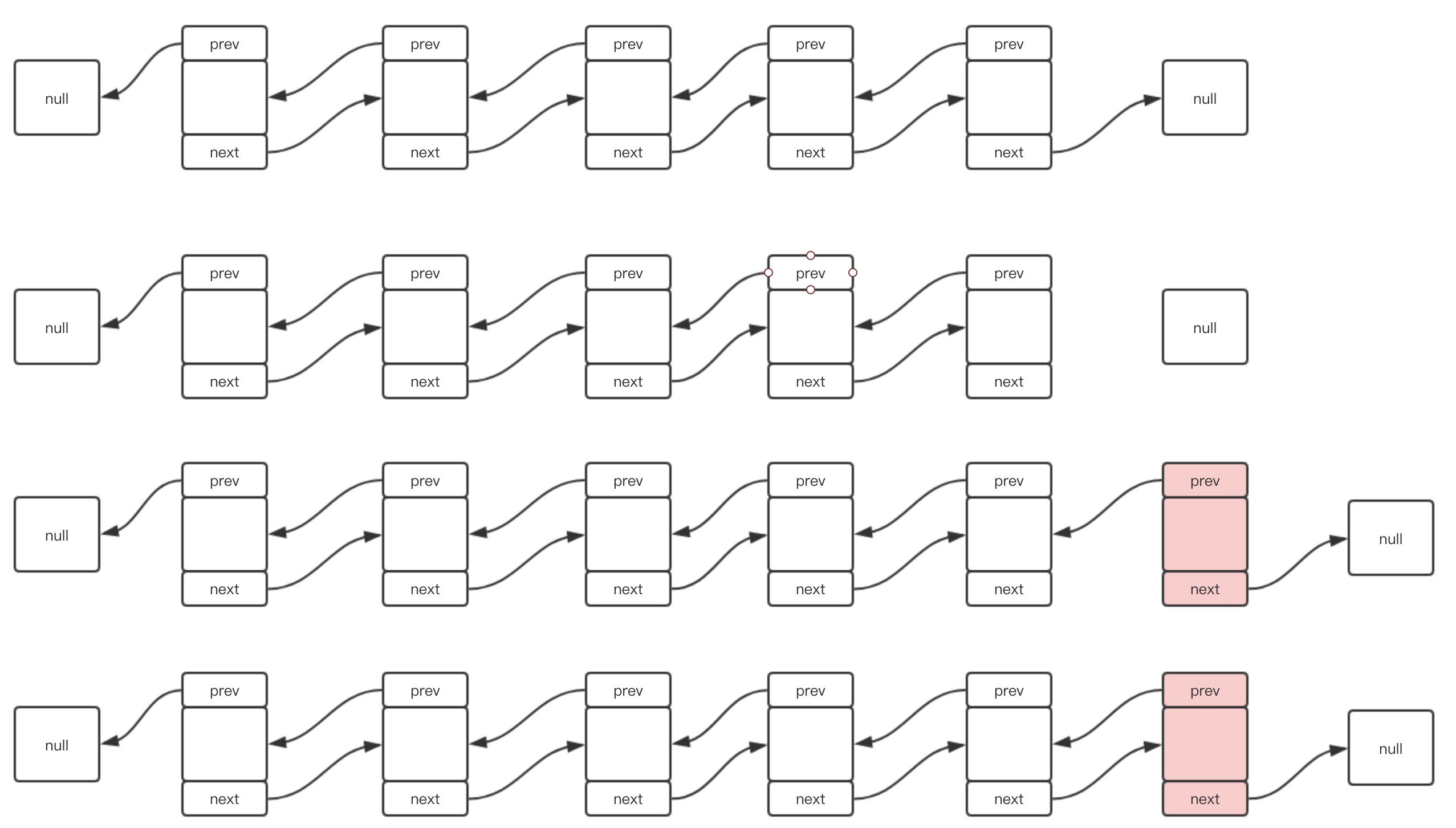
-
add(int index, E e)该方法用于在指定位置插入一个新节点,其源码稍微复杂一些,如下:
/** * 在指定索引位置插入元素e */ public void add(int index, E element) { // 判断index是否合法 checkPositionIndex(index); // 判断index是否为链表长度 if (index == size) // 若是,则在最后插入 linkLast(element); else // 若不是,则在指定的索引位置插入 linkBefore(element, node(index)); } /** * 在指定节点前插入节点 */ void linkBefore(E e, Node<E> succ) { // assert succ != null; // 拿到原节点的前驱节点 final Node<E> pred = succ.prev; // 构建新节点 final Node<E> newNode = new Node<>(pred, e, succ); // 原节点前驱指向新节点 succ.prev = newNode; // 判断是否空链表 if (pred == null) // 空链表令新节点为头节点 first = newNode; else // 非空链表则令原节点的前驱节点的后继指向新节点 pred.next = newNode; size++; modCount++; } /** * 获取指定索引位置的节点 */ Node<E> node(int index) { // assert isElementIndex(index); // 判断当前索引靠前还是靠后,以决定从前开始查找还是从后开始查找 if (index < (size >> 1)) { // 索引靠前从前查找 Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { // 索引靠后从后查找 Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }其示意图如下:
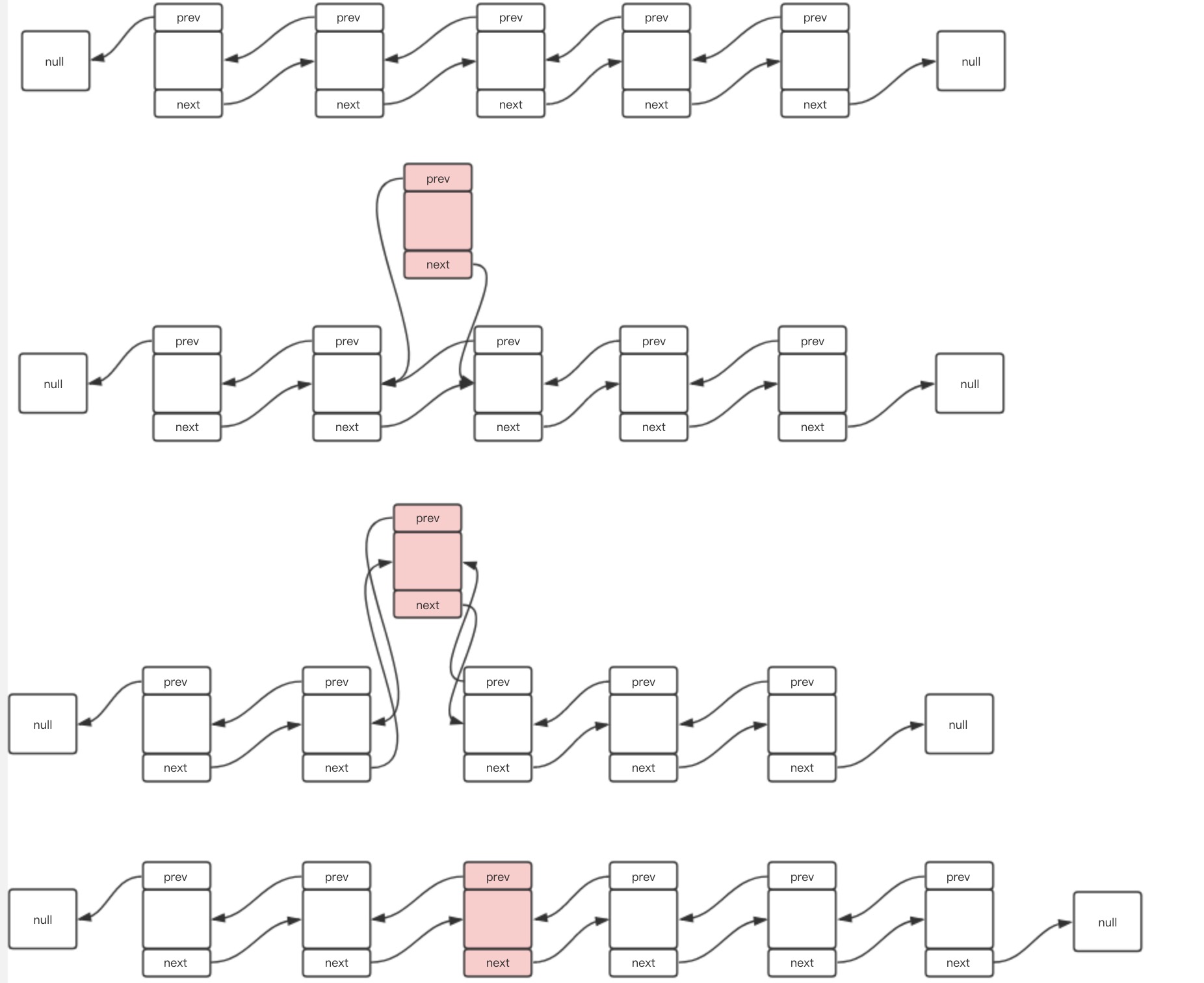
删除节点
常用的删除方法也有两个,即remove(int index)和remove(Object o),其核心都是如下代码:
/**
* 从链表中移除指定节点
*/
E unlink(Node<E> x) {
// assert x != null;
// 得到待移除节点的值
final E element = x.item;
// 得到待移除节点的后继节点
final Node<E> next = x.next;
// 得到待移除节点的前驱节点
final Node<E> prev = x.prev;
// 如果前驱为null,即为头节点
if (prev == null) {
// 若待移除节点为头节点,令头节点为待移除节点的后继节点
first = next;
} else {
// 否则将待移除节点的前驱节点的后继指向待移除节点的后继节点
prev.next = next;
// 断开待移除节点与其前驱节点的联系
x.prev = null;
}
// 判断后继是否为null,即为尾节点
if (next == null) {
// 若待移除节点为尾节点,令尾节点为待移除节点的前驱节点
last = prev;
} else {
// 否则将后继节点的前驱指向待移除节点的前驱节点
next.prev = prev;
// 断开待移除节点与其后继节点的联系
x.next = null;
}
// 释放节点值
x.item = null;
size--;
modCount++;
return element;
}
如果上面源码中的注释看起来有点绕,我们可以结合这个图来看:
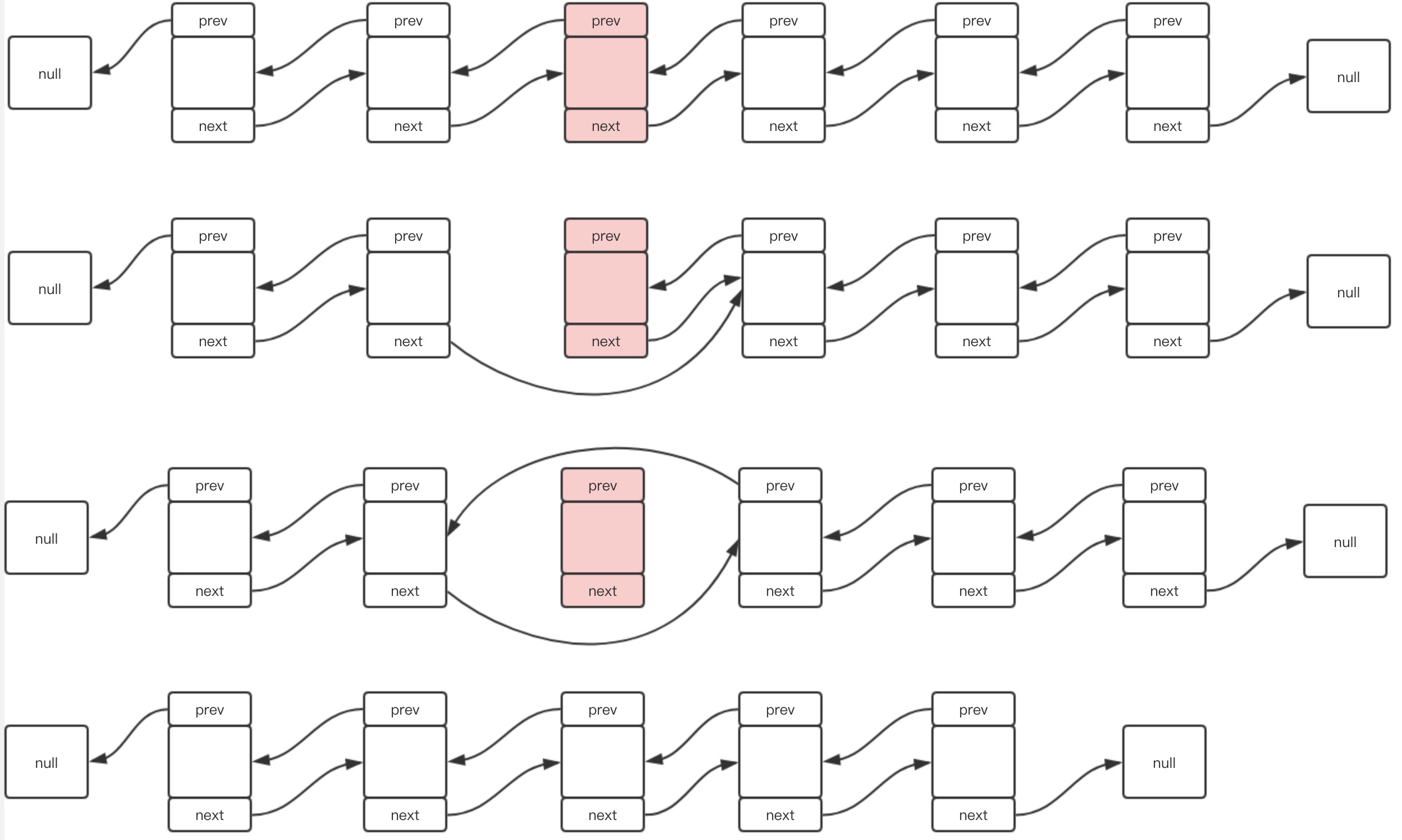
查找节点
至于说到查找节点,其核心其实在上面已经说过了,那就是node(int index)方法,这里再看一眼吧:
/**
* 获取指定索引位置的节点
*/
Node<E> node(int index) {
// assert isElementIndex(index);
// 判断当前索引靠前还是靠后,以决定从前开始查找还是从后开始查找
if (index < (size >> 1)) {
// 索引靠前从前查找
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 索引靠后从后查找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
这里有个小点,即index < (size >> 1)一句,用size >> 1找到中间节点,用一次二分决定其查找该从前开始,还是从后开始,但是其实这样的查找效率也并不高,特别是当index接近链表中间时。
总结
正是由于LinkedList使用双向链表实现,其插入和删除只需要移动指针,所以速度较快,而查找元素时则需要从一端开始遍历查找,速度较慢
ArrayList和LinkedList对比
| ArrayList | LinkedList | |
|---|---|---|
| 数据结构 | 基于动态数组实现 | 基于双向链表实现 |
| 查找 | 支持随机查找,速度较快 | 遍历查找,速度较慢 |
| 增、删 | 需要大量移动数据,速度较慢 | 只需要移动指针,速度较快 |