一、Mycat相关知识简介
1、Haproxy是一个开源的、高性能的基于TCP(四层)和HTTP(七层)应用的负载均衡软件。借助Haproxy可以更加快速的可靠的提供基于TCP和HTTP应用的负载均衡解决方案。是使用C语言编写的实现了一种事件驱动, 单一进程模型,此模型支持非常大的并发连接数。
2、四层和七层负载均衡区别
四层就是ISO参考模型的第四层。常见的四层负载均衡有LVS(Linux Virtual Server)、F5等。
七层负载均衡:也称为七层交换机,位于ISO最高层,即应用层。常见的七层负载均衡器有Haproxy、nginx等。
在七层负载均衡模式下,负载均衡与客户端及后端服务器分别建立一次TCP连接,而在四层负载模式下,仅建立一次TCP连接。由此可见,七层负载均衡对负载均衡设备的要求更高,而七层负载均衡处理能力必然低于四层负载均衡。
Haproxy与LVS的异同点:
两者都是软件负载均衡。但LVS是基于linux操作系统实现的一种软负载均衡,Haproxy是根据第三方应用实现的软负载均衡。
LVS是基于四层的IP负载均衡技术,而Haproxy是基于四层和七层技术、可提供TCP和HTTP应用的综合负载均衡技术
LVS工作在ISO模型的第四层,因此其状态检测功能单一,而Haproxy状态检测功能强大,可支持端口、URL、脚本等多种状态检测方式
Haproxy功能强大,但整理处理性能低于四层负载均衡模式的LVS。
更全面的Haproxy、Nginx、LVS三者的优缺点总结:
(1) Nginx
优点:
a) Nginx对网络稳定性的依赖非常小
b) Nginx安装与配置比较简单,测试也比较方便
c) 可以承担高负载压力且稳定
d) 不仅仅是优秀的负载均衡器/反向代理软件,同时也是强大的Web应用服务器
e) 可作为中层反向代理使用
f) 可作为静态网页和图片服务器
缺点:
a) 适应范围较小,仅能支持http、https、Email协议
b) 对后端服务器的健康检查,只支持通过端口检测,不支持url来检测
(2) LVS
优点:
a) 抗负载能力强、是工作在网络4层之上仅作分发之用,没有流量的产生,这个特点也决定了它在负载均衡软件里的性能最强的,对内存和cpu资源消耗比较低
b) 配置性比较低
c) 工作稳定,因为其本身抗负载能力很强,自身有完整的双机热备方案,如LVS+Keepalived,不过我们在项目实施中用得最多的还是LVS/DR+Keepalived
d) 无流量,LVS只分发请求,而流量并不从它本身出去,这点保证了均衡器IO的性能不会收到大流量的影响
e) 应用范围比较广,因为LVS工作在4层,所以它几乎可以对所有应用做负载均衡,包括http、数据库、在线聊天室等等
缺点:
a) 软件本身不支持正则表达式处理,不能做动静分离;而现在许多网站在这方面都有较强的需求,这个是Nginx/HAProxy+Keepalived的优势所在
b) 如果是网站应用比较庞大的话,LVS/DR+Keepalived实施起来就比较复杂了
(3) HaProxy
优点:
a) HAProxy是支持虚拟主机的,可以工作在4、7层(支持多网段)
b) HAProxy的优点能够补充Nginx的一些缺点,比如支持Session的保持,Cookie的引导;同时支持通过获取指定的url来检测后端服务器的状态
c) HAProxy跟LVS类似,本身就只是一款负载均衡软件;单纯从效率上来讲HAProxy会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的
d) HAProxy支持TCP协议的负载均衡转发,可以对MySQL读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,大家可以用LVS+Keepalived对MySQL主从做负载均衡
e) HAProxy负载均衡策略非常多,HAProxy的负载均衡算法现在具体有如下8种:roundrobin轮询、leastconn连接数最少优先、static-rr权重轮流、source对请求源IP进行HASH、uri、url_param参数哈希、hdr(name)根据name指定、rdp-cookie对rdp哈希。
缺点:
a) 不支持POP/SMTP协议
b) 不支持HTTP cache功能
c) 多进程模式支持不够好
3、Mycat的主要作用:
实现后端数据库的读写分离及负载均衡
对业务数据库进行垂直切分
对业务数据库进行水平切分(表结构相同)
控制数据库连接的数量
逻辑库(虚拟库,类似于视图)
逻辑表:不存储数据
逻辑表的类别:
- 分片表与非分片表(是否被分片划分,分片就是指是否进行了水平切分)
- 全局表,在所有分片中都存在的表(一般指字典表)
- ER关系表(按ER关系进行分片的表)
4、Mycat安装
- 安装JDK
- 下载并解压Mycat
- 新建Mycat账号
- 配置环境变量
- 修改Mycat启动参数
Mycat的配置在conf文件夹中的wrapper.conf文件中:
# 配置mycat使用内存的大小,默认2G
wrapper.java.additional.5=-XX:MaxDirectMemorySize=2G
wrapper.java.additional.6=-Dcom.sun.management.jmxremote
在环境变量中新增mycat的目录。
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export MyCAT_HOME=/usr/local/mycat
export PATH=$PATH:/usr/local/mycat/bin:/usr/local/java/jdk1.8.0_201/bin
最后要使配置生效:source /etc/profile
启动Mycat:>mycat start
二、Mycat实践
1、详解Mycat主要配置文件中的标签和属性
Server.xml用来配置系统参数、用户权限、配置SQL防火墙及SQL拦截功能。
Schema.xml用来配置逻辑库和逻辑表。
Rule.xml用来配置切分规则。(水平切分)
Log4j2.xml配置日志输出。
App需要通过server.xml中的用户认证才能使用Mycat。
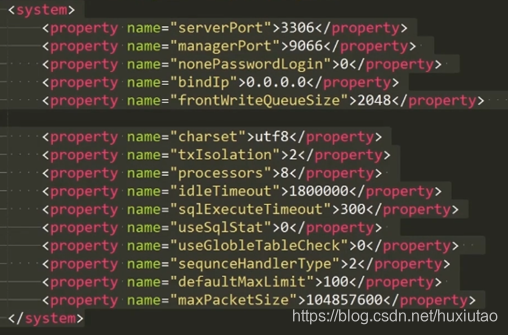
Server.xml中系统参数配置:
<property name="bindIp">0.0.0.0</property>指定监控哪个IP,如果是0.0.0.0则监控所有IP
<property name="frontWriteQueueSize">4096</property>指定前端写队列的大小
<property name=”txIsolation”>2</property>指定隔离级别,默认为2可重复读
<property name="processors">32</property>等于CPU的核数
<property name="defaultMaxLimit">100</property>返回数据集的大小,默认100行
<property name="maxPacketSize">104857600</property>返回数据包的大小
一般保持默认即可:
Server.xml中用户权限参数配置:
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>(可以指定多个逻辑数据库)
<property name="readOnly">true</property>
</user>

对密码加密:(不使用明文)
java –cp mycat-server-1.6.5-release.jar io.mycat.util.DecryptUtil 0:root:123456
零0代表的是:前端加密
Root:用户名
123456:密码


要想使用加密后的密码就必须加usingDecrypt属性设置为1

Rule.xml中参数配置:
配置水平分片的分片规则
配置分片规则所对应的分片函数

指定表的分片算法,取的name属性

常用的分片算法:
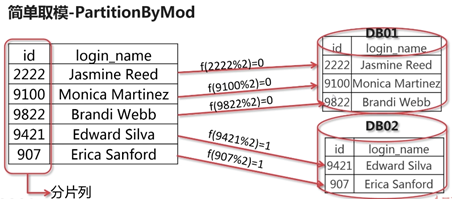
- 简单取模—PartitionByMod(最常用)
主要用于分片列为整数类型的表
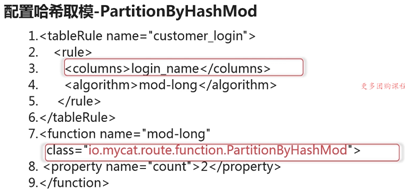
类全名:io.mycat.route.function.PartitionByMod - 哈希取模—PartitionByHashMod
用于多种数据类型如字符串、日期等
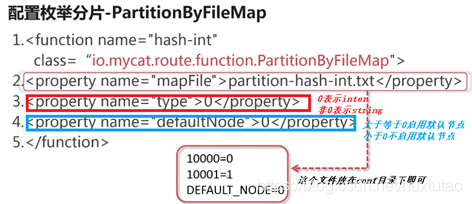
类全名:io.mycat.route.function.PartitionByHashMod - 分片枚举—PartitionByFileMap(根据地区分片)
认为指定按照哪些字符进行分片
类全名:io.mycat.route.function.PartitionByFileMap - 字符串范围取模分片
根据指定字符串的前N个字符确定存储位置
类全名:io.mycat.route.function.PartitionByPrefixPattern


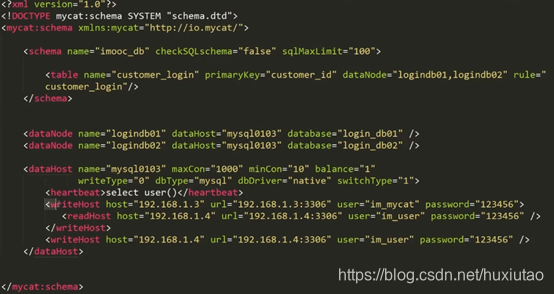
Schema.xml中参数配置:最重要的配置文件
配置逻辑库和逻辑表
配置逻辑表所存储的数据节点(对应关系)

CheckSQLschema属性判断是否检查发给MyCat的SQL是否含有库名(库名.表名),默认为false不检查。True则检查,如果有库名,则mycat自动去掉库名。
逻辑表与实际表的名称必须一致。



Mycat可以指定NoSQL数据库,上面的dbType就是配置的。
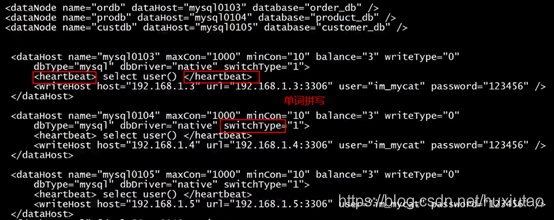
DbDriver=”native”代表是原生的,也可以指定为jdbc
Switch=1时表示的是:当每一个dataHost都不可以访问的时候,就会切换到第二个dataHost。如果为-1,表示的是关闭自动切换功能。一主多从时建议关闭。
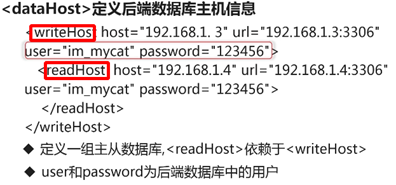
<dataHost>定义后端数据库主机信息
<heartbeat>select user(),这条语句要尽量的简单</heartbeat>
检查后端数据库是否可用。
2、垂直分库
步骤:
1、 收集分析业务模块间的关系
2、 复制数据库到其他实例
3、 配置Mycat垂直分库
4、 通过Mycat访问DB
5、 删除原库中已迁移的表
复制数据库到其他实例:
1、 备份原数据库并记录相关事务点
2、 在原数据库中建立复制用户
3、 在新实例上恢复备份数据库
4、 在新实例上配置复制链路
5、 在新实例上启动复制
备份Master上的数据库:
mysqldump --master-data=2 --single-transaction --routines --triggers --events -uroot -p imooc_db > bak_imooc.sql // master-data记录日志点,single-transaction指定备份是在一个事务中完成,routines备份存储过程,triggers备份触发器,events备份事件
输入密码后有可能显示如下异常:
mysqldump: Error: Binlogging on server not active
则需要开启日志功能:
/etc/my.conf中新增:
必须放在mysqld的下面
log-bin=mysql
server-id=1
再次执行则可成功。
将备份文件导入到数据库中:
新建数据库:order_db:># mysql -u root -p -e"create database order_db"
导入备份文件到数据库中:>#mysql -uroot -p order_db < bak_imooc.sql
在主节点中新建主从复制的账号:
mysql> create user ‘im_repl’@‘172.22.%.%’ identified by ‘123456’;
可能会由于安全策略出现创建失败的情况,只需要修改一下安全策略:
在/etc/my.cnf配置文件中增加validate_password=off([mysqld]的下面);或者set global validate_password_policy=0;(修改密码策略为LOW),set global validate_password_length=0;(修改密码长度);
授予主从复制账号权限:mysql> grant replication slave on . to ‘im_repl’@‘172.22.%.%’;
在从节点中新建复制链路:
不熟悉的命令可以通过\h 命令关键字,进行查看
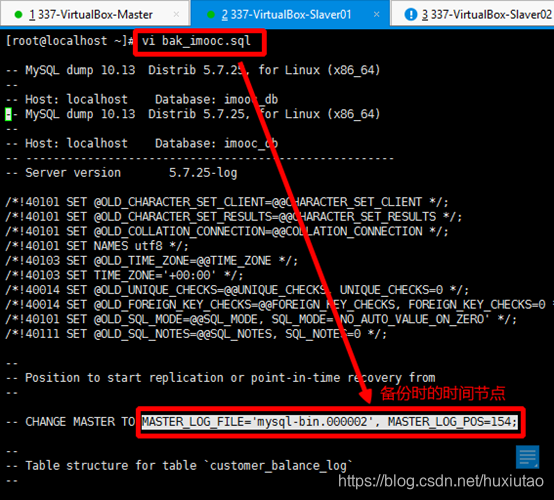
mysql> change master to master_host=‘172.22.34.28’, master_user=‘im_repl’,master_password=‘123456’, MASTER_LOG_FILE=‘mysql-bin.000002’, MASTER_LOG_POS=154;
master_host是同步的主机地址
master_user是同步的用户
master_password是同步的密码
master_log_file是同步的文件名
MASTER_LOG_POS是同步的位置
以上两个值都是从备份文件中直接复制的:
但在正式启动主从复制时,还有一个问题:
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 172.22.34.28
Master_User: im_repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 154
Relay_Log_File: localhost-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000002
Slave_IO_Running: No
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 154
Relay_Log_Space: 154
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 0
Master_UUID:
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
此时通过状态可以看出还没有开启,但是我们在主服务器中用的数据库名称是“imooc_db”,但是从服务器中的数据库名是“order_db”、“product_db”、“customer_db”,这样一来从库和主库的数据库名不一样,直接启动会报错的。
所以,需要建立过滤链接:
Mysql> change replication filter replicate_rewrite_db=((imooc_db, order_db));
mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 172.22.34.28
Master_User: im_repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 154
Relay_Log_File: localhost-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000002
Slave_IO_Running: No
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 154
Relay_Log_Space: 154
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 0
Master_UUID:
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB: (imooc_db,order_db)
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
就显示了主从库之间的关系。
正式开启主从复制功能:mysql>start slave;
如果show salve staus;显示:
Slave_IO_Running: No
Slave_SQL_Running: Yes
此时,就要查看从节点的日志了(/var/log/mysqld.log):
Slave I/O for channel ‘’: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids; these ids must be different for replication to work (or the --replicate-same-server-id option must be used on slave but this does not always make sense; please check the manual before using it). Error_code: 1593
通过分析可知,mysql 5.6的复制引入了uuid的概念,各个复制结构中的server_uuid得保证不一样才行,查看master和salve上的server_uuid:
show variables like ‘%server_uuid%’;
解决:
vi /etc/my.cnf
找到data目录:datadir=/var/lib/mysql
vi auto.cnf // 修改id即可
重启Salve:service mysqld restart
在主节点上进行配置:schema文件配置——Master
完成数据节点与主机节点的配置:
跨分片关联的解决方法:
可以通过应用程序api的方式。
可以通过数据冗余关键数据的方式。
更常用的是:利用mycat提供的路由表的方式。(MyCat全局表——小表)
配置文件区分大小写!
总结:
-
垂直切分的优点一:简单明了、规则明确
-
垂直切分的优点二:模块清晰、整合容易
-
垂直切分的优点三:维护方便,容易定位
-
垂直切分的缺点一:部分表无法关联查询,需要在应用程序中完成
-
垂直切分的缺点二:对于及其频繁访问的表仍然有性能瓶颈
-
垂直切分的缺点三:扩展性有一定的限制(分担了写节点的负载)
3、水平切分
切分原则:
(需要水平切分的表一定很少)
能不分则不分(订单表分,日志表不分)
选择合适的切分规则和分片键(均匀)
尽量避免跨分片Join操作
步骤:
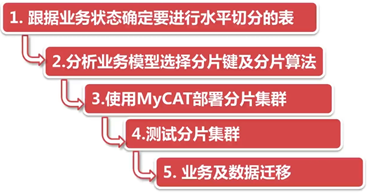
如何选择分片键:
尽可能的均匀分布到各个节点上
该业务字段是最频繁的或者最重要的查询条件。
结论:
对订单相关表进行水平切分、以customer_id作为分片键(另一个最常见的是订单号。如果选择订单号,优点是分布均匀,但很少基于订单号查询;所以customer_id更适合)、采用简单分片算法

Mycat为我们提供了一个功能:全局自增ID(当然也可以通过redis自动生成id进行插入),防止每个表都有自己的自增主键导致数据不合理的问题出现。
配置全局自增ID步骤:
(1)在mycat主节点中mysql登录数据库新建一个专门用于生成id的数据库。在mycat的conf目录下有dbseq.sql文件,该文件中包含了mycat引用的全局ID的对象
(2)将dbseq.sql文件导入到我们新建的mycat数据库中
(3)server.xml中
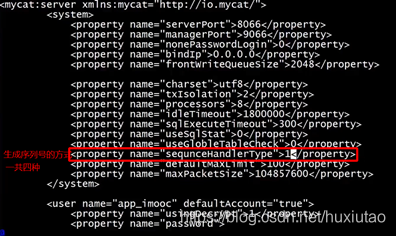
0:本地文件的方式
1:本地数据库的方式
2:时间戳的方式
3:zookeeper的方式
(4)在schema.xml中新增dbseq.sql文件被导入的mycat数据库的主机:

(5)在schema.xml中新增dataNode节点:

(6)修改mycat的conf目录下:sequence_db_conf.properties
#sequence stored in datanode
GLOBAL=mycat // schema.xml新增的数据节点名
COMPANY=dn1 // 不需要,删除即可
CUSTOMER=dn1 // 不需要,删除即可
ORDERS=dn1 // 不需要,删除即可
ORDER_MASTER=mycat //新增逻辑表的表名,就是schema.xml中新增dataNode中name:mycat,ORDER_MASTER一定要大写。
(7)在mycat数据库中新增ORDER_MASTER记录。

(8)告诉Mycat哪个表启动全局自增ID,修改schema.xml

(9)错误
需要给im_mycat执行的权限(在mycat表的数据库中):

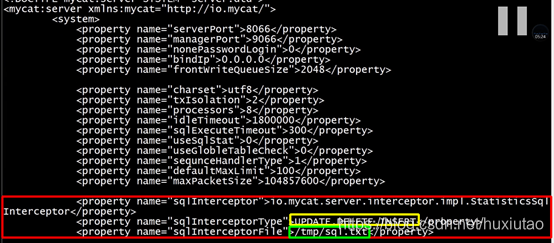
4、Mycat的SQL拦截
通过server.xml文件进行配置。
如果数据库中的数据被莫名其妙的修改了,就可以通过SQL拦截功能查看实际发送的SQL语句。
SQL拦截的功能:
监控记录数据库写入的操作。(不管执行成功不成功,都记录)

5、Mycat的SQL防火墙
通过server.xml文件进行配置。
功能:
统一控制哪些用户可以通过哪些主机访问后端数据库。
统一屏蔽一些SQL语句,强安全控制。

白名单、黑名单列表对哪些操作进行限制(很多,可以官网查看)
6、Mycat的高可用架构
高可用的要求:
- 系统架构中不存在单点问题
- 可以最大限度的保障服务的可用性
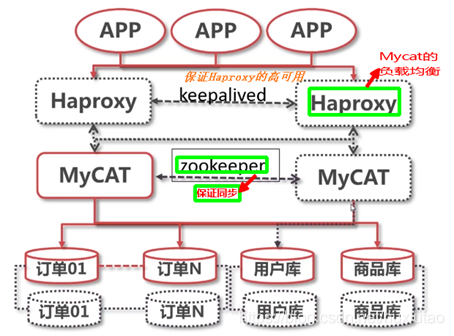
1、如何使用Zookeeper启动Mycat
使用ZK保证多个Mycat的配置同步。Zk本身就是分布式系统协调服务,具备集群功能。
操作步骤:
- (1) 建立zookeeper集群
- (2) 初始化Mycat配置到ZK集群
- (3) 配置Mycat支持ZK启动
- (4) 启动Mycat
具体操作概要:
(1)安装ZK
首先要保证有java环境:Node-2和Node-3中安装JDK(yum –install java-1.8.0-openjdk)
下载ZK:wget http://mirrors…
将下载下来的zk安装包,发送到另外两台主机中:scp ZK root@IP:/root
解压缩:tar –zxf zk
将解压后文件夹移动到 /usr/local/目录下,这是所有软件默认的安装目录
(2)重命名zoo_sample.cfg
在zk目录下新建data文件夹,用来保存数据,并给每一个zk节点生成节点标识:echo 2 > data/myid,在其他两个主机上也进行同样的操作。echo 0 > data/myid,echo 1 > data/myid
(3)修改zoo.cfg
增加集群的配置:
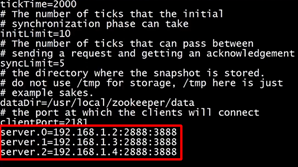
端口说明:
2181是客户端连接服务器端口
2888为组成zookeeper服务器之间的通信端口
3888为用来选举leader的端口
同样将上图中的三个配置在另外两台主机上配置。
(4)启动ZK集群
Zookeeper># bin/zkServer.sh start
(5)初始化ZK中的数据
需要先将使用到的配置文件(schema.xml、rule.xml、server.xml)copy到zkconf/目录下。
Mycat已经为ZK集群时的数据初始化提供了工具(sh脚本),在/usr/local/mycat/bin下:
init_zk_data.sh这个脚本就是向ZK集群中初始化数据的。这个脚本就是读取zkconf/下的配置文件来初始化数据的。
(6)配置Mycat支持ZK启动——配置myid.properties文件
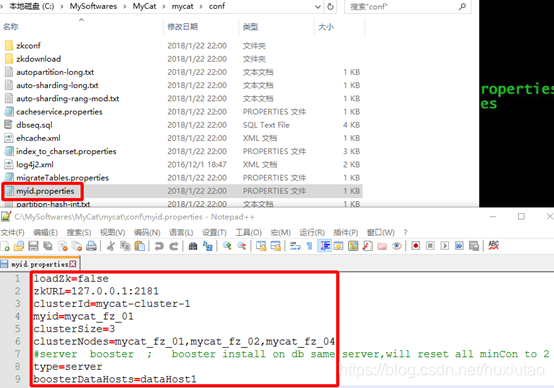
loadZk=false // 是否支持zk启动,默认为false,需要修改成true
zkURL=127.0.0.1:2181 // 所有提供服务的地址,逗号隔开,尽量使用真实的IP地址
clusterId=mycat-cluster-1 // Mycat在zk集群中的ID,这个ID可以从zkcli中的ls查看
myid=mycat_fz_01 // 集群中mycat的实例,这个ID是不能重复的
clusterSize=3 // 集群中一共有几个Mycat节点
clusterNodes=mycat_fz_01,mycat_fz_02,mycat_fz_04 //节点的标识名
#server booster ; booster install on db same server,will reset all minCon to 2
type=server // 尽量不变
boosterDataHosts=dataHost1 // 尽量不变
另外一个Mycat服务器上也进行同样的配置,重启所有Mycat服务。重启后,我们可以看一下后来安装的Mycat中的conf目录下的配置文件都已经配置好了。
2、如何使用HAProxy对Mycat均衡负载
(1)安装HAProxy
(2)使用Keepalived监控HAProxy
(3)配置HAProxy监控Mycat
(4)配置应用通过VIP(Virtual IP)访问HAProxy
注意:HAProxy + Keepalived一定要和Mycat部署到一起,建议MySQL部署到独立的服务器上。
(1)安装:yum install haproxy -y
(2)配置Haproxy:
cd /etc/haproxy/
修改该目录下的haproxy.cfg文件:
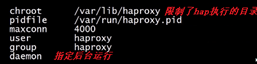
先把server app1 IP:port check/ server app2 IP:port check/ server app3 IP:port check/ server app4 IP:port check/删除掉
增加几个服务器的监听:
建立haproxy的管理端口,用来监听haproxy的运行状况的:
listen admin_status
bind 192.168.1.10:48800 // 这个ip就是后来keepalived虚拟的IP,48800就是对haproxy监控的端口
stats uri /admin-status // 指定监控的路径url
stats auth admin/admin // 用来监控的用户名和密码
增加对Mycat对外提供服务的监听:
listen allmycat_service
bind 192.168.1.10:8096 // 这个ip就是后来keepalived虚拟的IP,通过8096端口haproxy访问后端的mycat服务。(应用程序也是通过这个端口来访问mycat的)
mode tcp // 访问模式
option tcplog
option httpchk OPTIONS * HTTP/1.1\r\nHost: \www
balance roundrobin // 负载均衡的算法:轮询算法
server mycat_01 192.168.1.2:8066 check port 48700 inter 5s rise fall 3 // 对后端数据库的配置,通过48700端口进行检测,间隔5秒,失败后重复三次。
server mycat_04 192.168.1.4:8066 check port 48700 inter 5s rise fall 3 // 配置另一台
增加对Mycat管理的监听:
listen allmycat_admin
bind 192.168.1.10:8097 // 这个ip就是后来keepalived虚拟的IP,通过8096端口haproxy访问后端的mycat服务。(应用程序也是通过这个端口来访问mycat的)
mode tcp // 访问模式
option tcplog
option httpchk OPTIONS * HTTP/1.1\r\nHost: \www
balance roundrobin // 负载均衡的算法:轮询算法
server mycat_01 192.168.1.2:9066 check port 48700 inter 5s rise fall 3 // 对后端数据库的配置,通过48700端口进行检测,间隔5秒,失败后重复三次。
server mycat_04 192.168.1.4:9066 check port 48700 inter 5s rise fall 3
其他的地方不需要修改。
由于上面使用到了48700端口对mycat进行监控,需要安装另一个服务来启动48700端口:
yum install xinetd –y // xinetd是网络守护进程的服务,可以通过这个实现简单的网络服务,通过这个服务达到启动这个端口的目的。
在/etc/xinetd.d/下新建mycatchk文件,并配置:
service xinetd restart
配置虚拟网卡:
启动HAProxy服务:
haproxy –f /etc/haproxy/haproxy.cfg
在/etc/service中增加:
mycatchk 48700/tcp # mycatchk
重启xinetd服务。
检查是否启动正常:
netstat –nltp | grep 48700
用同样的方法在另外一台主机上配置。(配置文件可以直接复制),但是需要注意的是:修改为绑定所有端口:
安装Keepalived服务
yum install keepalived –y
对keepalived进行配置:>cd /etc/keepalived/,keepalived.cnf,内容:
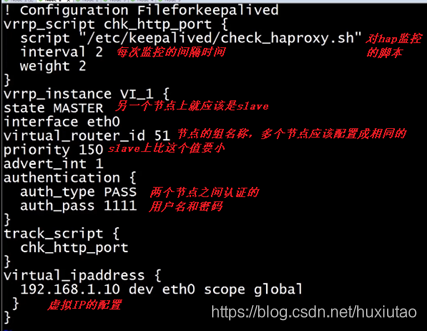
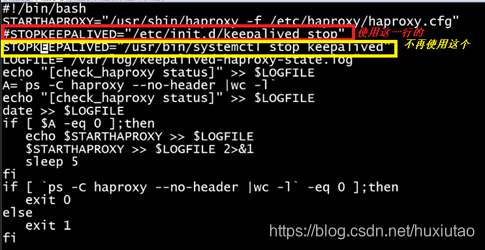
上图中提到的监控脚本:check_haproxy.sh:
启动Keepalived:

监控脚本check_haproxy.sh是一样的,但一定要赋予可执行的权限:>chmod a+X check_haproxy.sh。
运行脚本:>./check_haproxy.sh
启动Keepalived。
只有在节点一挂掉后才会切换到该节点上。
7、MyCat实现读写分离
如果是一主多从的架构还是推荐使用MHA方案,MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案。
操作步骤:
(1)配置各个节点的Mysql的主从复制
(2)配置MyCat对后端DB进行读写分离
(3)滚动应用MyCat配置
三、MyCat管理及监控
1、对于MyCAT管理端口管理MyCat
管理端口默认9066,在server.xml中修改;管理用户和密码也在这个文件中。
>mysql –u –p P9066 –hmycat-host
用户名和密码就是server.xml中配置的。
登录后,可以通过>show @@help命令查看所有可用命令(58个左右)
查看逻辑库:
>show @@databases;
查看数据节点:
>show @@datanode;
可使用\G,显示更整齐。
查看可用的节点(心跳检测)
>show @@heartbeat;
查看连接到Mycat的所有连接信息:
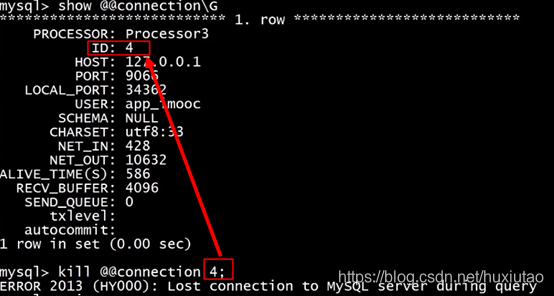
>show @@connection\G
关闭一个连接mycat的连接:
>kill @@connection ID;
查看mycat连接后端数据库的情况:
>show @@backend\G
查看Mycat缓存信息:
>show @@cache\G
2、使用Mycat-WEB管理Mycat
Mycat-WEB是个页面工具,需要安装:
步骤:
(1) 下载mycat-web并解压
(2) 安装jdk
(3) 安装ZK
(4) 启动mycat-web、
四、MyCat集群优化
1、Mysql的优化
通过my.cnf优化MySQL配置
存储引擎:InnoDB
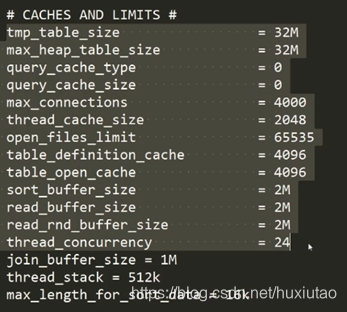
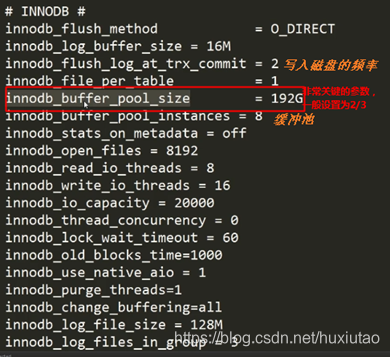
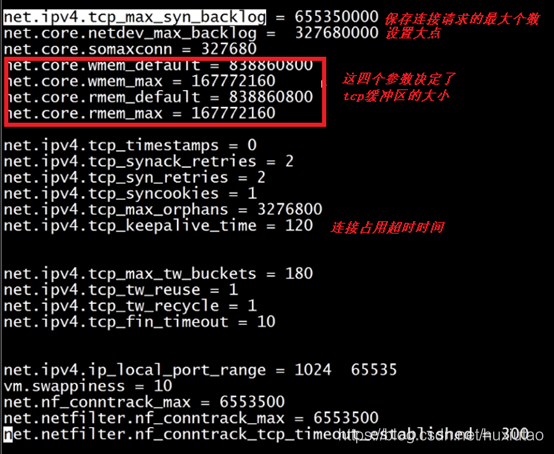
2、Linux优化
编辑/etc/sysctl.conf优化内核相关参数
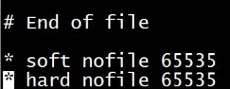
编辑/etc/security/limits.conf修改资源限制:只需要增加两行:
五、MyCat的限制
1、不支持的SQL语句
- create table like xxx / create table select xxx
- 跨库多表关联查询,子查询
- select for update / select lock in share mode
- select into outfile / into var_name
- 多表UPDATE或是UPDATE分片键
- 跨分片update / delete [order by] limit
2、有限的支持事务
Mycat只支持弱分布式事务
如事务commit后某节点失效则无法保证事务的一致性
3、Mycat不适合的场景
- 使用到不支持的SQL的场景
- 需要跨分片关联查询的场景
- 需要保证跨分片事务强一致性的场景