一、径向基函数
径向基函数是某种沿径向对称的标量函数,通常定义为样本到数据中心之间径向距离(通常是欧氏距离)的单调函数(由于距离是径向同性的)。RBF核是一种常用的核函数。它是支持向量机分类中最为常用的核函数。常用的高斯径向基函数形如:
其中,





因为RBF核函数的值随距离减小,并介于0(极限)和1(当x = x’的时候)之间,所以它是一种现成的相似性度量表示法。核的特征空间有无穷多的维数;对于
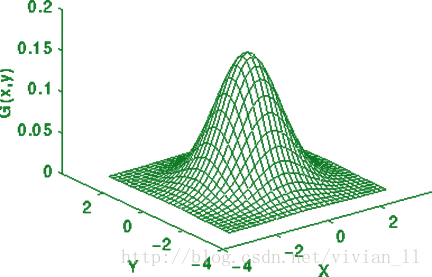
径向基函数二维图像:
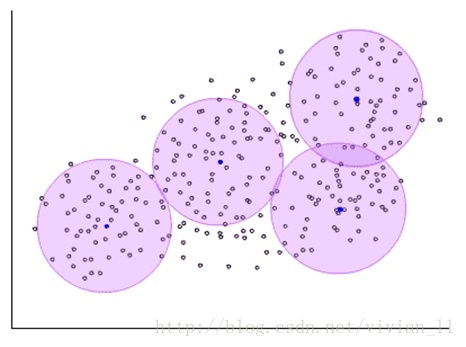
RBF 拥有较小的支集。针对选定的样本点,它只对样本附近的输入有反应,如下图。
RBF 使样本点只被附近(圈内)的输入激活。
T. Poggio 将 RBF 比作记忆点。与记忆样本越近,该记忆就越被激活。
RBF 核与多项式核相比具有参数少的优点。因为参数的个数直接影响到模型选择的复杂性。
其他的径向基函数有:
Reflected Sigmoidal(反常S型)函数: 
Inverse multiquadrics(拟多二次)函数: 
σ称为径向基函数的扩展常数,它反应了函数图像的宽度,σ越小,宽度越窄,函数越具有选择性。

二、径向基网络
RBF(Radial Basis Function,径向基)网络是一种单隐层前馈神经网络,它使用径向基函数作为隐层神经元激活函数,而输出层则是对隐层神经元输出的线性组合。径向基函数网络具有多种用途,包括包括函数近似法、时间序列预测、分类和系统控制。他们最早由布鲁姆赫德(Broomhead)和洛维(Lowe)在1988年建立。
RBF网络分为标准RBF网络,即隐层单元数等于输入样本数;和广义RBF网络,即隐层单元数小于输入样本数。但广义RBF的隐藏层神经元个数大于输入层神经元个数,因为在标准RBF网络中,当样本数目很大时,就需要很多基函数,权值矩阵就会很大,计算复杂且容易产生病态问题。
径向基网络:
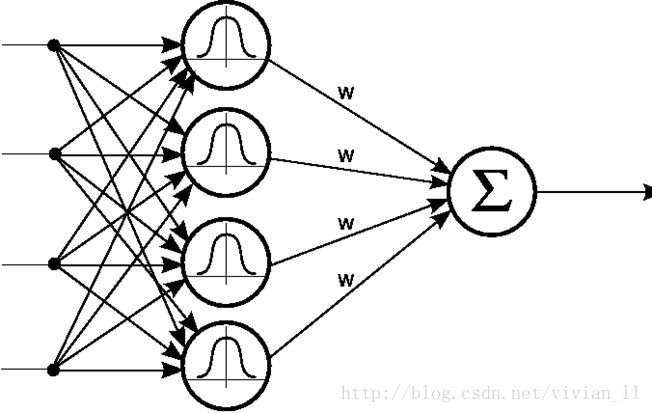
RBF神经网络的基本思想:用RBF作为隐单元的“基”构成隐藏层空间,隐藏层对输入矢量进行变换,将低维的模式输入数据变换到高维空间内,使得在低维空间内的线性不可分问题在高维空间内线性可分。详细一点就是用RBF的隐单元的“基”构成隐藏层空间,这样就可以将输入矢量直接(不通过权连接)映射到隐空间。当RBF的中心点确定以后,这种映射关系也就确定 了。而隐含层空间到输出空间的映射是线性的(注意这个地方区分一下线性映射和非线性映射的关系),即网络输出是隐单元输出的线性加权和,此处的权即为网络可调参数。
通常采用两步过程来训练RBF网络:第一步,确定神经元中心,常用的方式包括随机采样、聚类等;第二步,利用BP算法等来确定参数。
[Park and Sandberg,1991]证明,具有足够多隐层神经元的RBF网络能以任意精度逼近任意连续函数。
且RBF网络可以处理系统内的难以解析的规律性,具有良好的泛化能力,并有很快的学习收敛速度。
RBF网络学习收敛得比较快的原因:当网络的一个或多个可调参数(权值或阈值)对任何一个输出都有影响时,这样的网络称为全局逼近网络。由于对于每次输入,网络上的每一个权值都要调整,从而导致全局逼近网络的学习速度很慢。BP网络就是一个典型的例子。如果对于输入空间的某个局部区域只有少数几个连接权值影响输出,则该网络称为局部逼近网络。常见的局部逼近网络有RBF网络、小脑模型(CMAC)网络、B样条网络等。
三、参数计算
中心点的计算:
标准RBF的样本点即为中心
广义RBF的中心点通过随机采用、聚类等方法确定
w和β的计算:
人为指定:所有神经元的β都一样,β=1/2(
BP算法迭代确定。
四、RBF神经网络与SVM with RBF Kernel的区别和联系:
从模型上看,区别不大,区别在于训练方式。
RBF神经网络训练分两阶段。第一阶段为非监督学习,从数据中选取记忆样本(上上图中的紫色中心)。例如聚类算法可在该阶段使用。第二阶段为监督学习,训练记忆样本与样本输出的联系。该阶段根据需要可使用 AD/BP。(AD,即 Automatic Differentiation (Backpropagation) )