版权声明:斌哥版权,如有雷同,纯属虚构 https://blog.csdn.net/iostream992/article/details/85179498
1、schema约束
-
dtd语法:<!ELEMENT 元素名称 约束>
-
schema符合xml的语法,xml语法
-
一个xml中可以由多个schema,多个schema使用名称空间区分(类似java包名)
-
dtd里面有PCDATA类型,但是在schema里面可以支持更多的数据类型
-
比如 年龄 只能是证书,在schema可以直接定义一个整数类型
-
-
schema语法更加复杂,schema目前不能替代dtd
-
2、schema的快速入门





3、sax解析的原理

画图分析:










5、使用dom4j解析xml(**)
-
Dom4j,是一个组织,针对xml解析,提供解析器dom4j
-
Dom4j表示javese的一部分,想要使用怎么做?
-
导入dom4j提供的jar包
-
创建一个文件夹到文件夹lib
-
复制jar包到礼包下面
-
右键点击jar包,build path->add to buildpath
-
看到jar包变成奶瓶样子,表示导入成功
-

-
得到document
-

-
documnet的发接口是Node
-
如果在document里面找不到想要的方法,到Node里面去找
-
-
document里面的方法 getRootElement():获取根节点 返回的是Element
-
Element也是一个接口,父接口是Node
-
Element和Node里面方法
-
getParent():获取父节点
-
addElement:添加标签
-
element(qname)
-
表示获取标签下面的第一个子标签
-
qname:标签的名称
-
-
elements(qname)
-
获取标签下面的是中国名称的所有子标签(一层)
-
qname:标签的名称
-
-
elements()
-
获取标签下面的所有一层子标签
-
-
-
-
-
6、使用dom4j查询xml
-
查询所有name元素里面的值
-
1、创建解析器
-

-
2、得到document
-

-
3、得到根节点 getRootElement() 返回Element
-

-
4、得到所有的p1标签
-

-
Element("p1") 返回list集合
-
遍历list得到每个p1
-
-
5、得到name
-
在p1下面执行 element("name")方法 返回Element
-
-
6、得到name里面的值
-
getText方法得到值
-
-

-
-
查询第一个name元素的值
-
1、创建解析器
-

-
2、得到document
-

-
3、得到根节点 getRootElement() 返回Element
-

-
4、得到第一个p1元素
-

-
Element("p1") 方法 返回ELement
-
-
5、得到p1下面的name
-

-
element("name")方法 返回Element
-
-
6、得到name里面的值
-

-
getText方法得到值
-
-
-
获取第二个name元素的值
-


7、实现添加操作
-
在第一个p1标签下添加一个操作
-
1、创建解析器
-

-
2、得到document
-

-
3、得到根节点
-

-
4、获取到第一个p1
-

-
使用Element方法
-
-
5、在p1下直接添加元素
-

-
在p1上面直接使用addElemnet("标签名称")方法 返回一个Element
-
-
6、在添加完成后的元素下方添加文本
-

-
在sex上直接使用setText("文本内容")方法
-
-
7、回写xml
-

-
格式化OutputFormat
-
使用createPrettyPrint方法可以有缩进效果
-
使用类XMLWriter直接new这个类,传递两个参数
-
第一个参数是xml文件路径 new FileOutputStream("路径")
-
第二个参数是格式化类的值
-
-
-
8、在特定位置添加元素
-
在第一个p1下面的标签添加<sex>nv</sex>
-
1、创建解析器
-

-
2、得到document
-

-
3、得到根节点
-

-
4、获取到第一个p1
-

-
5、获取p1下面的所有元素
-
elements()方法 返回list集合
-

-
创建元素 使用
-

-
在元素(school)下面创建文本
-

-
在特定位置添加元素、
-
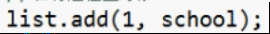
-
add(int index,E element)
-
第一个参数:位置下标,从0开始
-
第二个参数:要添加的元素
-
-
-
-
6、回写xml
-

-
导包注意
-

-
9、dom4j里面封装方法


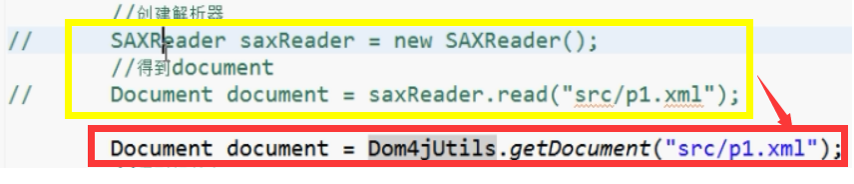


10、dom4j实现修改节点操作
-
修改第一个pi下的age元素的值<age>300</age>
-
1、得到document(用封装方法)
-

-
2、得到根节点
-

-
3、得到第一个p1的元素
-

-
4、得到第一个p1下面的age
-

-
5、原始值是20,变成300
-

-
6、回写xml
-

-
11、使用dom4j实现删除节点的操作
-
删除第一个p1下边的school操作
-
1、得到document(用封装方法) ctrl+shift+o快速导包
-

-
2、得到根节点
-

-
3、得到第一个p1的元素
-

-
4、得到第一个p1下面的school
-

-
5、删除(使用父节点p1删除school)
-

-
取父节点的方法:getParent()【本题不需要】
-

6、回写xml
-
-

-
12、使用dom4j获取属性的操作
-
获取第一个p1里面的属性id1的值
-
1、得到document(用封装方法) ctrl+shift+o快速导包
-

-
2、得到根节点
-

-
3、得到第一个p1的元素
-

-
4、得到p1里面的属性值
-

-
13、使用dom4j支持xpath的操作
-
可以直接获取到某个元素
-
第一种形式
-
/AAA/DDD/BBB: 表示一层一层的,AAA下面DDD下面的BBB
-
-
第二种形式
-
//BBB: 表示和这个名称相同,表示主要名称是BBB都可以得到
-
-
第三种形式
-
/*: 所有元素
-
-
第四种形式
-
BBB[1]: 表示第一个BBB元素
-
BBB[last( )]: 表示最后一个BBB元素
-
-
第五种形式
-
//BBB[@id]: 表示BBB元素上有id属性,都可得到
-
-
第六种形式
-
//BBB[@id='b1']: 表示元素名称是BBB,在BBB上面有id属性,并且id的属性值是b1
-
14、使用dom4j支持xpath具体操作
-
默认的情况下,dom4j不支持xpath
-
如果想要在dom4j里面有xpath
-
第一步需要,引入支持xpath的jar包,使用jaen-1.1-beta-6.jar
-
需要把jar包导入到项目中
-
-
在dom4j里面提供了两种方法,用来支持xpath
-
selectNodes("xpath表达式")
-
获取多个节点
-
-
selectSingleNode("xpath表达式")
-
获取单一节点
-
-
-
# 使用xpath实现:查询xml中所有name元素的值
-
所有name元素的xpath表示: //name
-
使用selectNodes("//name")
-
-
步骤:
-
1、得到document(用封装方法)
-

-
2、使用使用selectNodes("//name")方法得到所有name元素
-

-
3、遍历list集合
-
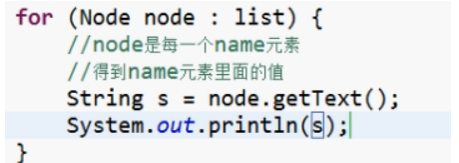
-
-
#使用xpath实现:获取第一个p1下面的name值
-
//p1[@id="aaaa"]/name
-
使用到selectSingleNode("//p1[@id="aaaa"]/name")
-
-
步骤:
-
1、得到document(用封装方法)
-

-
2、直接使用selectSingleNode方法实现
-
xpath: //p1[@id="aaaa"]/name
-
-

-
3、得到name里面的值
-

-