缓存雪崩
由于原有的缓存过期失效,新的缓存还没有缓存进来,请求缓存请求不到,导致所有请求都跑去了数据库,导致数据库IO、内存和CPU压力过大,甚至导致宕机,使得整个系统崩溃。
解决思路:
1,采用加锁计数,或者使用合理的队列数量来避免缓存失效时对数据库造成太大的压力。这种办法虽然能缓解数据库的压力,但是同时又降低了系统的吞吐量。
2,分析用户行为,尽量让失效时间点均匀分布。避免缓存雪崩的出现。
3,如果是因为某台缓存服务器宕机,可以考虑做主备,比如:redis主备,但是双缓存涉及到更新事务的问题,update可能读到脏数据,需要好好解决。
加锁:加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法。
缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
(大并发的缓存穿透 会导致缓存雪崩)
解决思路:
1,如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。
2,采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的BitSet中,不存在的数据将会被拦截掉,从而避免了对底层存储系统的查询压力。关于布隆过滤器,详情查看:基于BitSet的布隆过滤器(Bloom Filter)
缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样避免,用户请求的时候,再去加载相关的数据。
解决思路:
1,直接写个缓存刷新页面,上线时手工操作下。
2,数据量不大,可以在WEB系统启动的时候加载。
3,定时刷新缓存。
缓存更新
缓存淘汰的策略有两种:
(1) 定时去清理过期的缓存。
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
主从复制 读写分离
redis提供了一个master,多个slave 的服务,也就是一个主机多个从机
准备多个redis,来模拟多台电脑上的服务,一个master,两个slave
master 的配置文件 (redis.windows.conf)
requirepass ws #设置密码
port 6379 # 设置端口
dir dump.rdb 文件的地址
slave1 的配置文件(redis.windows.conf)
requirepass ws # 方便后续操作,和master的操作一致
port 7000
dir dump.rdb 文件的地址
slaveof 127.0.0.1 6379 #连接master 的路径和端口
masterauth ws #连接master 所需的密码
slave2 的配置文件(redis.windows.conf)
requirepass ws # 方便后续操作,和master的操作一致
port 7001
dir dump.rdb 文件的地址
slaveof 127.0.0.1 6379 #连接master 的路径和端口
masterauth ws #连接master 所需的密码
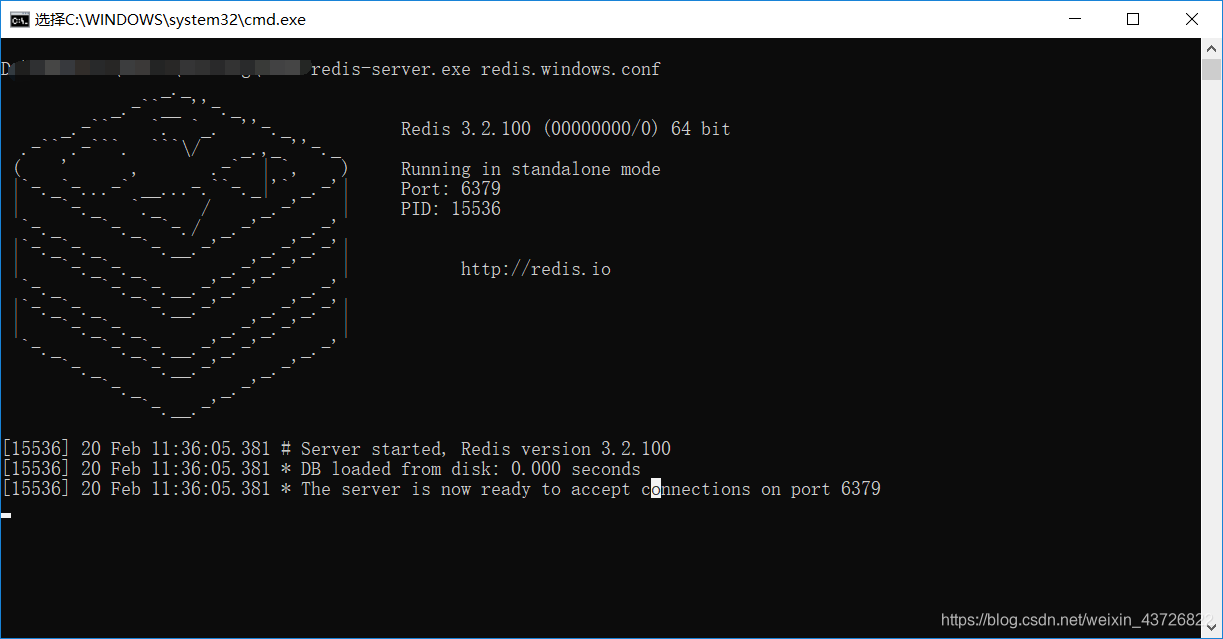
启动master 服务如下
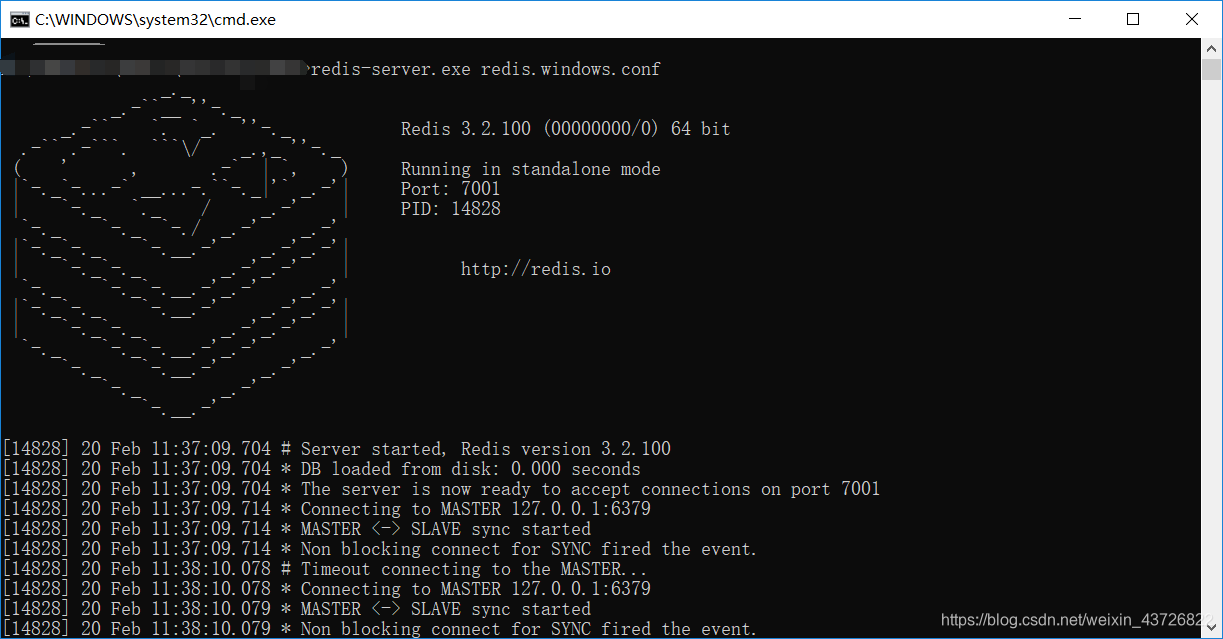
启动两个slave 服务如下

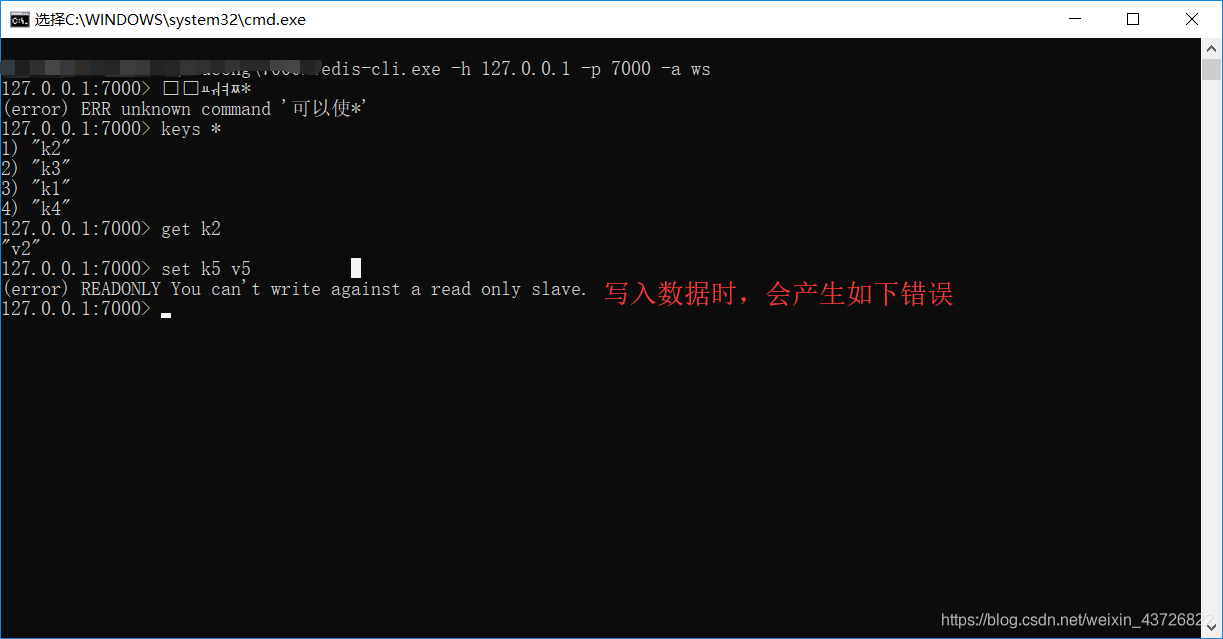
启动master 客户端 (可以随意读写)
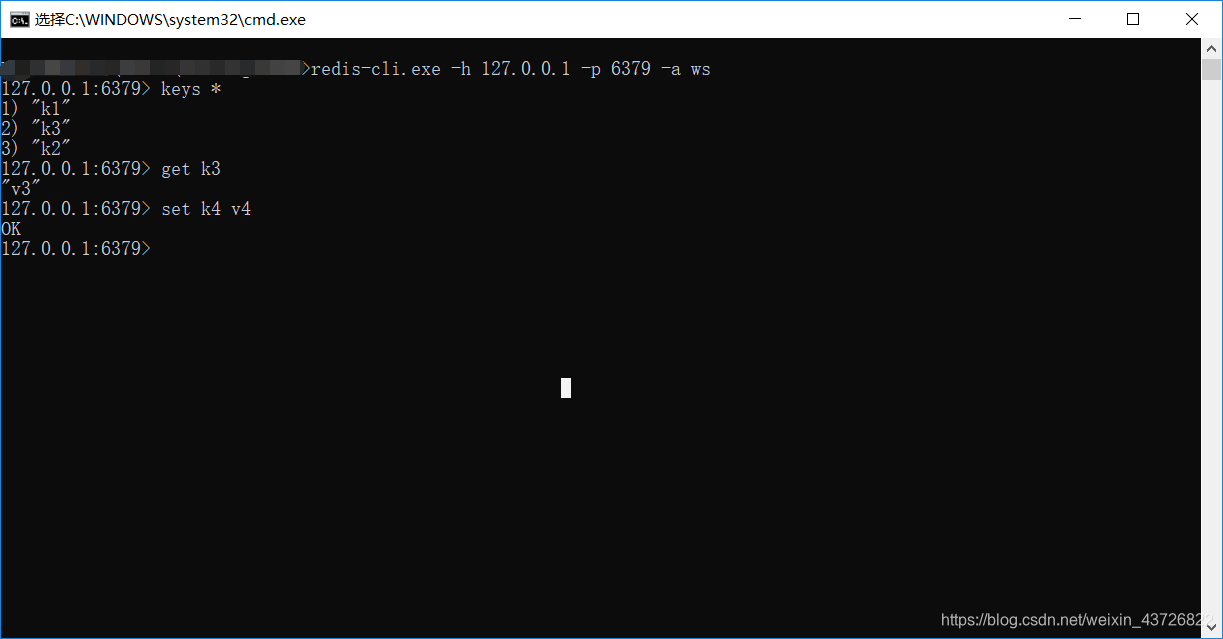
启动任何一个slave 客户端 (只可以读,不可以写 做到读写分离)