192. Word Frequency
Write a bash script to calculate the frequency of each word in a text file words.txt.
For simplicity sake, you may assume:
words.txtcontains only lowercase characters and space' 'characters.- Each word must consist of lowercase characters only.
- Words are separated by one or more whitespace characters.
Example:
Assume that words.txt has the following content:
the day is sunny the the
the sunny is is
Your script should output the following, sorted by descending frequency:
the 4
is 3
sunny 2
day 1
Note:
- Don't worry about handling ties, it is guaranteed that each word's frequency count is unique.
- Could you write it in one-line using Unix pipes?
一、首先考虑用到grep
- -oE:表示将原文本内容变成一个单词一行的存储方式
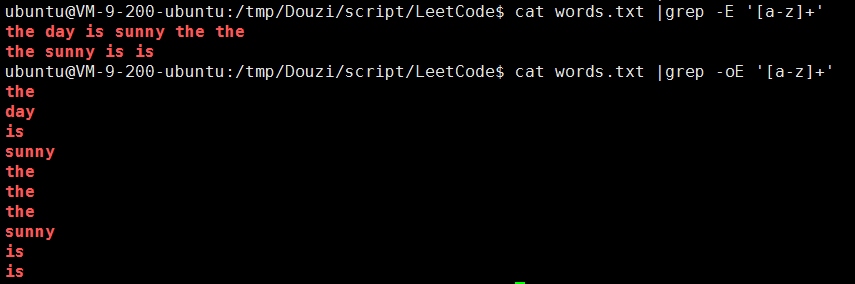
二、排序sort(这里排序是为了后面好去重)
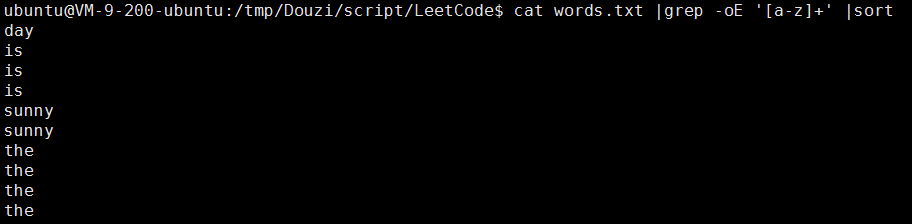
三、去重并计算单词出现次数
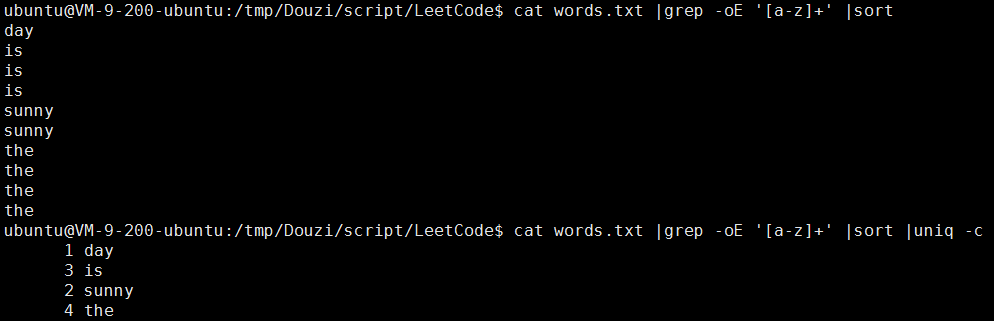
四、再sort排序(-nr表示按数值进行降序排序)

五、再通过awk控制输出方式

cat words.txt |grep -oE '[a-z]+' |sort |uniq -c |sort -nr |awk '{print $2" "$1}'
法二:tr
注意:tr -s:表示如果发现连续字符,就把他们缩减成1个;后面的' ' '\n'是空格和回车:表示把所有空格换成回车。
tr -s ' ' '\n' < words.txt |sort |uniq -c|sort -nr |awk '{print $2" "$1}'
法三:awk
#!/bin/bash
awk '{
for (i = 1; i < NF; ++i) ++s[$i];
} END {
for (i in s) print i, s[i];
}' words.txt |sort -nr -k 2
