Hadoop 作为一个分布式计算平台,从集群计算的角度分析,Hadoop可以将底层的计算资源整合后统一分配到集群中的计算节点,从而达到分布式和并行计算的目的,最终完成任务的高效执行。在调度机制中涉及的三个核心问题:
- 计算资源的组织
- 用户作业的选择
- 任务的分配策略
在目前的Hadoop 系统中,默认的调度器为FIFO调度,主要适合单队列的批处理作业需求,针对多用户多队列的控制需求,雅虎开发并且向开源社区贡献了容量调度器(Capacity Scheduler)和Facebook开发并贡献了公平调度器(FAIR Scheduler)。
1. 作业调度概述
1.1 作业调度相关概念
- 作业管理:在调度系统中作业管理包括作业提交权限控制,作业运行状态查看权限控制等。
- 用户和分组:在Hadoop系统中以组为单位组织管理作业,每个用户只能向固定分组中提交作业,只能使用固定分组中配置的资源。同时可以限制每个用户提交的作业数、使用的资源等。
- 资源池:是Hadoop公平调度Fiar Scheduler中的概念,一个资源池可以对应一个用户(User)、一个分组(Group)、或者一个队列(Queue)。
- 队列:队列是Hadoop中提出的概念,一个队列(Queue)可以由任意几个分组(Group)和任意几个用户(User)组成。
- 资源槽位:是Hadoop分布式系统进行资源管理的基本单位,是集群计算资源的抽象化,每个资源槽位都代表可以运行的一个任务(Map任务和Reduce任务)。Hadoop集群中的每个计算节点都拥有一定数量的资源槽,具体数目需要每个用户依据每个节点的内存、CPU等信息确定并配置,默认每个节点两个资源槽位,表示每个计算节点可以并发运行两个任务
- 作业调度和任务调度:第一级是作业调度,也就是作业选择,作业调度器选取作业集合中的一个等待调度的作业。第二级是任务调度,也就是任务分配,由任务调度器在第一级选择的作业中选取一个就绪的任务来运行。
- 心跳:主节点负责管理所有从节点的资源,而这种管理是通过主从节点之间的心跳信息来互相通信的,也就是从节点定时向主节点发送状态信息————心跳信息来报告自己当前的状况
- 本地化资源和非本地化资源:待调度资源的作业集合中有一个作业至少存一个任务的代处理数据存位于该计算节点上,那么就可以称为这个计算节点是这个作业的本地化资源。
- 本地化调度和非本地化调度
1.2 作业调度流程
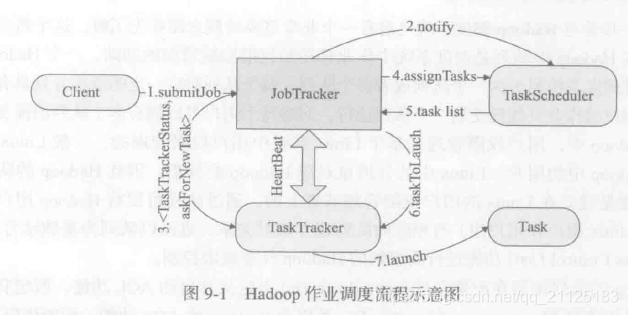
- Client 通过submitJob()函数向JobTracker提交一个作业。
- JobTacker接收到用户的作业提交后会通过notify()函数通知调度器TaskScheduler有新作业
- TaskTracker通过heartbeat心跳机制向JobTacker汇报TaskTracker的资源情况,JobTreacker同时获取TaskTrackerStatus信息,如果TaskTracker资源是空闲的,则主动向JobTracker请求分配任务。
- JobTracker根据对TaskTracker资源的管理情况,请求调度器TaskScheduler分配作业,TaskScheduler根据对应的资源情况和任务数量,分配作业列表返回给JobTracker。
- JobTracker接收到分配的作业列表,再通过HeartBeat心跳信息将任务分发给具体的TaskTracker,最终启动Task任务完成作业。
1.3 集群资源组织和管理
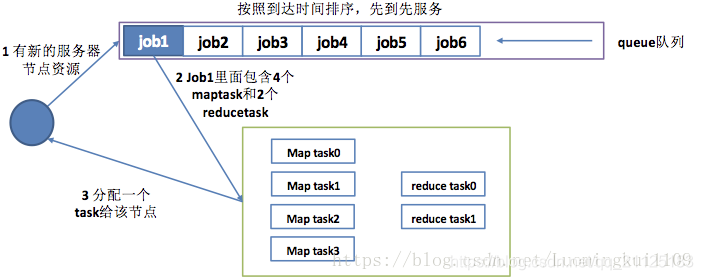
Hadoop系统作业调度是以计算槽位slot来组织集群计算资源的,计算槽位可以认为是Hadoop集群中计算资源的抽象,是集群资源管理的基本单位,计算槽位slot资源包括两种类型:Map slot和Reduce Slot
2. FIFO 调度器
FIFO调度器是Hadoop默认的调度器,其调度策略简单,容易实现,并且调度效率最高。
2.1 基本调度策略
类似于Linux操作系统中的FIFO先进先出进程调度算法,Hadoop FIFO调度器的调度策略是将用户提交的作业按照先后顺序放在一个队列中,然后依据先后顺序和优先级顺序被依次调度执行,整体上遵循先进先出基本原则。
FIFO调度策略遵循以下基本原则:
- 所有用户提交的作业会统一按照提交的先后顺序排列在同一个队列中。
- 支持优先级,包括VERY_HIGH、HIGH、NORMAL、LOW、VERY_LOW
- 在优先级相同的情况下,按照先来先服务的模式调度执行。
- 在优先级不同的情况下,优先级高的作业仙贝调度执行。
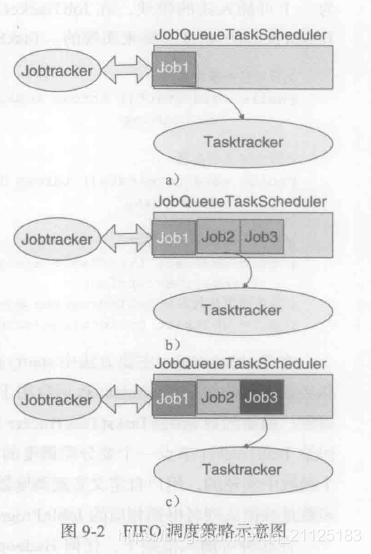
FIFO调度器有三种基本情况:
- 队列中只有一个作业时直接调度执行,如上图a只有一个Job1,则调度器JobQueueTaskSchedule直接将Job1调度分配给集群的计算节点TaskTracker执行;
- 用户在Job1之后先后提交了Job2和Job3,并且Job2和Job3的优先级是相同的。这个时候先运行Job2,然后再运行Job3
- 用户在Job1之后先后提交了Job2和Job3,而Job3的优先级比Job2的优先级高,那么Job1运行完成之后,先调度Job3然后调度Job1.
总结:FIFO调度器逻辑设计简洁,对于单用户集群系统来讲比较适合,同时系统利用率高,响应时间也很短,但是对于多用户共享集群资源的情况下就会出现不能区别不同用户、不同作业类型的情况。
2.2 任务分配算法
- 获取当前TaskTracker的Map和Reduce数量信息
- 计算需要运行的Map和Reduce的数量(也就是处于正在运行状态和挂起状态的)
- 计算Map和Rduce的负载因子:负载因子表示整个集群的负载情况,很明显,负载因子越大集群的负载越高,随着任务的执行集群负载会减少,而用户也会不断地向队列中提交作业,这样集群整个负载因子又会增加,因此在实际的集群环境中比较高效的状态是负载因子维持在一个动态的范围之内。
- 计算tasktracker当前Map容量以及最大可分配的Map任务数量,然后调度分配map任务。
- 计算tasktracker当前Reduce容量以及最大可分配的reduce任务数量,然后调度分配reduce任务。
3. 公平调度器
FIFO调度器的问题:FIOF调度器不支持多个队列,也不支持多个用户共享集群,这样就造成了集群资源利用率过低,对于不同类型的作业不能保证公平调度器等问题,公平调度器FairScheduler就这样产生了。
3.1 主要功能
- 实现了类似Linux内核的Fair-Share调度算法,以保证各个作业基本上能公平共享整个集群的资源。
- 支持多用户、多队列和划分资源池。
- 支持资源池最小共享保证和最大作业限制。
- 共享权重可分配:通过调整共享权重使得高优先级作业、大作业共享更多的资源。
- 支持资源抢占:当一个资源池有空闲资源槽时,调度器会将其共享给需要资源调度的资源池。
- 实现了延迟调度:延迟调度机制可以调数据本地任务的效率。
3.2 基本调度策略
公平调度策略的核心概念是随着时间的推移能平均获取同等的共享资源。当单独一个作业任务运行时,它将使用整个集群;当有其他作业被提交时,系统会将任务(task)空闲时间片(slot)赋给新的作业,以使得每一个作业都能获取等量的CPU时间。
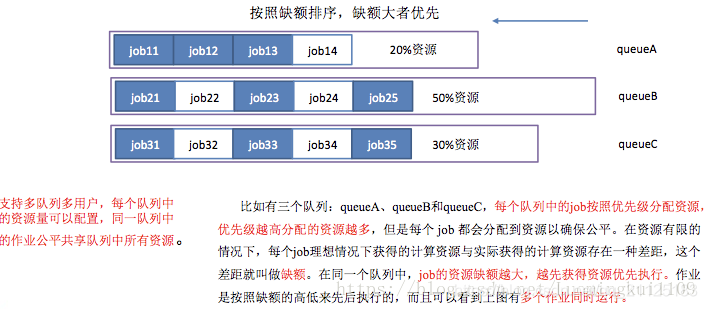
公平调度器中有一个资源池pool的概念,并通过资源池来组织作业,把资源公平地分配到这些资源池里面。在默认的情况下,每一个用户都拥有一个独立的资源池,以使得每一个用户都能获取一份同等的集群资源而不管其提交了多少作业。
在每一个资源池内,会使用公平共享的方式在运行的作业间共享资源。用户可以给予资源池相应的权重,以不按比例的方式共享集群。除了提供公平共享的方法之外,公平调度器允许赋给资源池以保证最小的共享资源。
公平调度器也支持在可配置的超时时间后对允许的作业进行抢占。如果新的作业在一定时间内还获取不到最小的共享资源,这个作业别允许去终结已运行的作业中任务以获取运行所需要的资源。
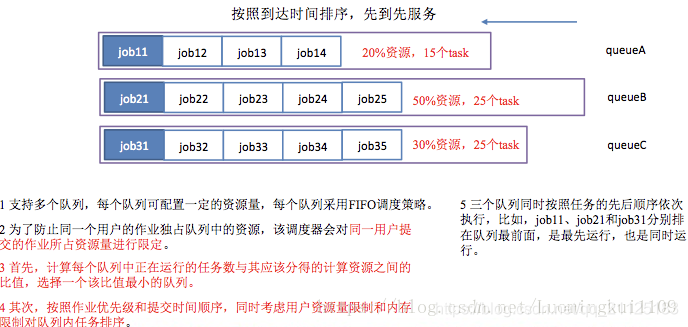
4. 容量调度器
容量调度器是雅虎结合自己的集群业务类型,提出的一种多用户调度器,这种调度器支持多用户、多队列,每一个队列都可以单独配置一定的资源量,每个队列采用FIFO策略,可以看做是FIFO调度器的多队列版本。
4.1 产生背景
公平调度器强调的是各个作业的公平共享原则,主要是保证资源池之间以公平地共享整个集群资源,然而整个集群的资源利用率的角度来看,公平调度并不能保证整个集群的资源的利用率最高,也就是虽然各种作业对资源的使用可以达到公平地原则,保证用户都可以公平地分享整个集群的资源,但是仍然存在计算资源利用率不高的问题,容量调度器就是用来解决这个问题。
在容量调度器中,每个作业被提交到一个队列中,每个队列分配整个集群资源的容量(capacity)的一定比例,队列中的作业以FIFO的方式占用整个队列分配的资源(capacity)。调度的基本策略是首先选择一个容量capacity实际占用率最低的队列,这样最需要资源的队列优先调度,然后从FIFO队列中选择一个合适的作业。
4.2 主要功能
- 支持多用户多队列
- 层次化队列机制
- 资源容量保证
- 作业权限控制
- 弹性资源分配
- 运行时的控制功能
- 基于资源的调度
- 作业内存控制
- 延迟调度机制
4.3 基本调度策略
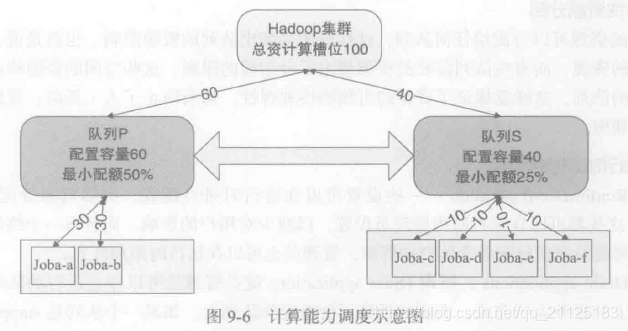
容量调度器的计算能力调度示意图如下:假定Hadoop集群中有100个计算资源槽位。调度器中配置了队列P和队列S,队列P中配置容量为60;S队列中配置容量为40。P中队列最小配额为50%,也就是P队列中可以同时运行两个作业,每个作业分配30个计算资源;S队列中最小配额为25%,也就是可以同时运行4个作业。在队列之间也会共享空闲的计算资源。容量调度算法中最重要的就是在选择作业的时候,会关注作业所属的用户是否已经超过了他所能使用的计算资源限制。
容量调度器还可以有效地对集群中资源中的内存资源进行管理,从而可以有效的支持内存密集型作业。如果一个作业对内存的资源需求比较高,那么调度算法就要保证将该作业的相关任务分派到具有充足内存资源的TaskTacker上执行,已避免由于内存不足造成无法执行。因此,在作业选择的过程中,计算能力调度算法还需要检查空闲TaskTracekr上的内存资源是否能够满足作业的内存需求。