版权声明:本文为博主原创文章,转载请注明出处。 https://blog.csdn.net/u012319493/article/details/87039266
项目结构:
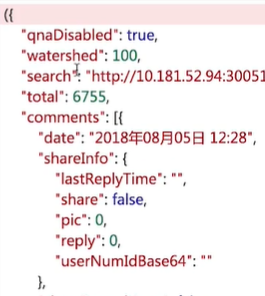
所有的信息位于一个括号内,所有的评论位于 comments 中,comments 中的每个元素的 date、content 等字段为所需的。

将数据存储到 json 文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
from scrapy.loader.processors import MapCompose
from scrapy.loader.processors import Join
def parse_field(text):
return str(text).strip() # 去除两端空格
class SpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class GoodsItem(scrapy.Item):
# 评论时间
date = scrapy.Field(
input_processor=MapCompose(parse_field), # 去除空格
output_processor=Join(),
)
# 评论id
rate_id = scrapy.Field(
input_processor=MapCompose(parse_field),
output_processor=Join(),
)
# 评论内容
content = scrapy.Field(
input_processor=MapCompose(parse_field),
output_processor=Join(),
)
# 商品链接
link = scrapy.Field(
input_processor=MapCompose(parse_field),
output_processor=Join(),
)
# 商品id
auc_num_id = scrapy.Field(
input_processor=MapCompose(parse_field),
output_processor=Join(),
)
skirt.py 中添加:
from scrapy.loader import ItemLoader
from spider.items import GoodsItem
# 解析具体的评论
def parse_rate_list(self, response):
# 将响应信息转换成 json 格式
goods_rate_data = re.findall("\((.*)\)", response.text) # 把小括号内的匹配出来
goods_rate_data_json = json.loads(goods_rate_data[0]) # 转换成 json
comments = goods_rate_data_json['comments'] # 评论内容,通过 key 取 value
# 处理每一条评论
for comment in comments:
# ItemLoader 方式
goods_item_loader = ItemLoader(item = GoodsItem(), response = response)
# 评论时间
goods_item_loader.add_value('date', comment['date'])
# 评论 id
goods_item_loader.add_value('rate_id', comment['rateId'])
# 评论内容
goods_item_loader.add_value('content', comment['content'])
# 商品详情
auction = comment['auction']
# 商品的链接地址
goods_item_loader.add_value('link', auction['link'])
# 商品id
goods_item_loader.add_value('auc_num_id', auction['aucNumId'])
# 将数据交给 scrapy 框架,pipelines 处理
yield goods_item_loader.load_item()
pipelines.py 对 item 进行操作,将数据存储到文件:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import codecs
import json
import MySQLdb.cursors
from twisted.enterprise import adbapi
class SpiderPipeline(object):
def process_item(self, item, spider):
return item
class JsonPipeline(object):
def __init__(self):
self.file = codecs.open("jsondata.json", "w", encoding="utf-8")
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(lines)
return item
def spider_close(self):
self.file.close()
ITEM_PIPELINES = {
'spider.pipelines.SpiderPipeline': 300,
'spider.pipelines.JsonPipeline': 1,
}
得到的 json 文件:

写入 mysql 数据库
pipelines.py 中添加:
import MySQLdb.cursors
from twisted.enterprise import adbapi
# 数据库连接池方式,异步存储,不影响性能
# pip install mysqlclient
class MysqlTwistedPipline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
# 从settings.py 中加载
@classmethod
def from_settings(cls, settings):
dbparams = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset = "utf8",
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode = True
)
adbpool = adbapi.ConnectionPool("MySQLdb", **dbparams)
return cls(adbpool)
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider)
return item
def do_insert(self, cursor, item):
# 获取执行的 sql 语句
insert_sql, params = item.get_insert_sql()
# 执行 sql 语句
cursor.execute(insert_sql, params)
def handle_error(self, failure, item, spider):
print(failure)
为 items.py 中的 GoodsItem 类添加方法:
def get_insert_sql(self):
insert_sql = """
insert into rate(date,rate_id,content,link,auc_num_id)
values (%s,%s,%s,%s,%s)
"""
params = (self["date"], self["rate_id"], self["content"], self["link"], self["auc_num_id"])
return insert_sql, params
settings.py 中添加配置:
ITEM_PIPELINES = {
'spider.pipelines.SpiderPipeline': 300,
'spider.pipelines.JsonPipeline': 1,
'spider.pipelines.MysqlTwistedPipline': 2,
}
MYSQL_HOST = "rm-2ze638.aliyuncs.com"
MYSQL_DBNAME = "spider"
MYSQL_USER = "root"
MYSQL_PASSWORD = "111111"
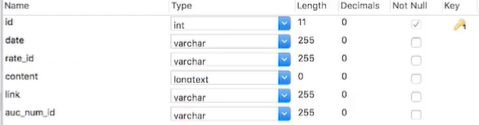
创建数据库表:
结果:

分布式爬虫
pip install scrapy-redis
安装部署 redis:略。
如果修改 redis 配置文件:
vim etc/redis.conf
进入 redis:
bin/redis-cli
查看所有键:
keys *
skirt.py 中修改:
- 修改继承的类。
from scrapy_redis.spiders import RedisSpider
class SkirtSpider(RedisSpider):
- 添加监听的 key,并将 start_url 作为 value。
class SkirtSpider(RedisSpider):
name = 'skirt'
# 允许的域名,如果没有把域名写在这里,那么将会过滤掉
allowed_domains = ['item.taobao.com',
'rate.taobao.com'] # 只保留域名
redis_key = "tabao:start_url"
# 从哪个页面开始抓取
#start_urls = ['https://item.taobao.com/item.htm?id=537194970660&ali_refid=a3_430673_1006:1105679232:N:%E5%A5%B3%E8%A3%85:30942d37a432dd6b95fad6c34caf5bd5&ali_trackid=1_30942d37a432dd6b95fad6c34caf5bd5&spm=a2e15.8261149.07626516002.3']
settings.py 中添加 RedisPipline 的配置:
ITEM_PIPELINES = {
'spider.pipelines.SpiderPipeline': 300,
'spider.pipelines.JsonPipeline': 1,
'spider.pipelines.MysqlTwistedPipline': 2,
'spider.pipelines.RedisPipline': 3,
}
REDIS_HOST = "192.168.1.190"
REDIS_PORT = "6379"
在 redis 添加 key,value:
lpush tabao:start_url https://item.taobao.com/item.htm?id=537194970660&ali_refid=a3_430673_1006:1105679232:N:%E5%A5%B3%E8%A3%85:30942d37a432dd6b95fad6c34caf5bd5&ali_trackid=1_30942d37a432dd6b95fad6c34caf5bd5&spm=a2e15.8261149.07626516002.3