多线程需要注意两个问题——数据计算和数据IO
http的服务,瓶颈一般会出现在数据IO上。类似谷歌这样的查询服务,他们的瓶颈在计算上。在数据IO和数据计算上找到平衡点,是服务器开发的重点。
目前的解决方案是利用多线程来平衡数据计算和数据IO
多线程的弱点:容易出错 mutilthread就是新一代的goto
容易带来的问题:
1、死锁:
2、乱序:多线程下,运行顺序不一定是按照预期计划来的。cpu会做优化处理
3、数据出错:这种错误不好找,测试的时候链接的客户少,真的上线时,隐藏的并发访问的问题才会暴露出来
4、低效
c++11给我们的新概念
1、高阶接口:async、future
2、低阶接口:thread、mutex
标准库中没有说明这两个cout哪一个先被调用,这是未定义行为

头文件
#include<thread>一个简单的例子
假设我们要求10000000个元素经过计算之后的累加和,如果单线程,实现方法如下:
double calculate(double v) {
if (v <= 0) return v;
//假设下面的计算十分耗时
return (v*v);
}
int main() {
vector<double>v;
double res = 0.0;
for (int i = 0; i < 10000000; i++) {
v.push_back(rand());
}
for (auto& i : v) {
res += calculate(i);
}
return 0;
}如果想用多线程,比如用两个线程去做该任务。第一种思路:两个线程分别计算0-500000和500001-1000000这两个区间中的累加和,之后将两个累加和进行累加即可。代码如下(用到的知识:lambda表达式、线程创建、回调函数):
double calculate(double v) {
if (v <= 0) return v;
//假设下面的计算十分耗时
return (v*v);
}
template<typename Iter, typename Fun>
double visitRange(Iter iterBegin, Iter iterEnd, Fun fun) {
double v = 0;
for (auto i = iterBegin; i != iterEnd; ++i) {
v += fun(*i);
}
return v;
}
int main() {
vector<double>v;
double res = 0.0;
for (int i = 0; i < 10000000; i++) {
v.push_back(rand());
}
double another = 0.0;
auto iter = v.begin() + v.size() / 2;
auto iterEnd = v.end();
//使用lambda表达式
//开一个线程计算后半部分的总和
thread s([&another, iter, iterEnd](){
another = visitRange(iter + 1, iterEnd, calculate);
});
//利用总线程计算前半部分的总和
auto half = visitRange(v.begin(), iter, calculate);
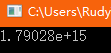
cout << half + another << endl;
//清理工作
s.join();
return 0;
}
既然可以分工协作,那么问题来了:
我们如何区分哪一部分代码在主线程中运行的,哪一部分代码是在额外申请的线程里运行的呢?
答案是利用线程的函数接口 get_id()
//获取主线程id
auto mainThreadId = std::this_thread::get_id();
thread s([&another, iter, iterEnd](){
another = visitRange(iter + 1, iterEnd, calculate);
});
//获取申请的线程s的id
auto id = s.get_id();std中有一个namespace名为this_thread,可以通过该方式在任何函数下获取当前线程的信息。
改写一下上面的代码,输出调用的线程信息:
#include<iostream>
#include<vector>
#include<thread>
using namespace std;
double calculate(double v) {
if (v <= 0) return v;
//假设下面的计算十分耗时
return (v*v);
}
template<typename Iter, typename Fun>
double visitRange(thread::id id, Iter iterBegin, Iter iterEnd, Fun fun) {
//获取线程id
auto curId = std::this_thread::get_id();
if (curId == id) {
cout << "hello main thread : " << curId << endl;
}
else {
cout << "hello new thread : " << curId << endl;
}
double v = 0;
for (auto i = iterBegin; i != iterEnd; ++i) {
v += fun(*i);
}
return v;
}
int main() {
//获取主线程id
auto mainThreadId = std::this_thread::get_id();
vector<double>v;
double res = 0.0;
for (int i = 0; i < 10000000; i++) {
v.push_back(rand());
}
double another = 0.0;
auto iter = v.begin() + v.size() / 2;
auto iterEnd = v.end();
//使用lambda表达式
//开一个线程计算后半部分的总和
thread s([&another, mainThreadId, iter, iterEnd](){
another = visitRange(mainThreadId, iter + 1, iterEnd, calculate);
});
//获取申请的线程s的id
auto id = s.get_id();
cout << "new thread id:" << id << endl;
//利用总线程计算前半部分的总和
auto half = visitRange(mainThreadId, v.begin(), iter, calculate);
cout << half + another << endl;
//清理工作
s.join();
return 0;
}
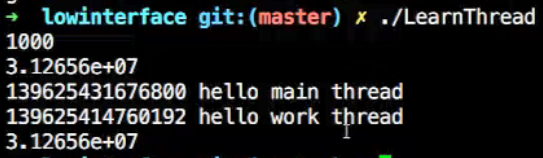
运行结果第一行可以看出,cup先处理新线程的任务,在输出完“hello new thread”之后发生中断,去处理主线程的任务,回到了main函数,去打印“new thread id:20432”,打印完之后又发生了中断,cpu回到新线程去输出各个还没来得及输出的线程id以及换行,因此第二行只有一行数字。
把main函数中的
//获取申请的线程s的id
auto id = s.get_id();
cout << "new thread id:" << id << endl;这两句注释掉之后,干扰会少一点,看运行结果更直接,运行结果如下:

可以很明显的看出,先执行了新线程,在输出完“hello new thread”之后,发生了中断,cpu去处理主线程的任务,输出“hello main thread :4032”。之后进程回到新线程,输出新线程还没输出的数字15956以及换行符。
不过我机器的运行结果和视频里面老师的运行结果不同,老师的是先输出主线程
让线程休眠的函数 sleep_for()
想使用该函数需要使用头文件
#include<chrono>double calculate(double v) {
if (v <= 0) return v;
//sleep 10毫秒
this_thread::sleep_for(chrono::milliseconds(10));
return v;
}