Hive中数据倾斜的表面原因可能各种各样,但是底层都是一个Reducer的节点计算压力过大,造成某一个节点一直在运算造成的。
今天运行SQL的时候,遇到了一次,分享下(由于数据使用公司数据,表名都重新换过,数据量保持不变)
表名信息如下,假设有两张表:
- tmp_user,数据量:267772
- tmp_user_log,数据量:5,617,310,131
初始SQL如下:
SELECT /*+mapjoin(a)*/b.user_type_id
,count(distinct certi_no) certi_no
FROM tmp_user a
JOIN tmp_user_log b
ON a.user_id = b.user_id
GROUP BY b.user_type_id
;
上述逻辑就是查看不同用户类型下的身份证数量,运行结果如下
| user_type_id | certi_no |
+--------------+------------+
| 11 | 114982 |
| 12 | 26654 |
而这段SQL运行了大约6分多钟,其中主要卡在下面
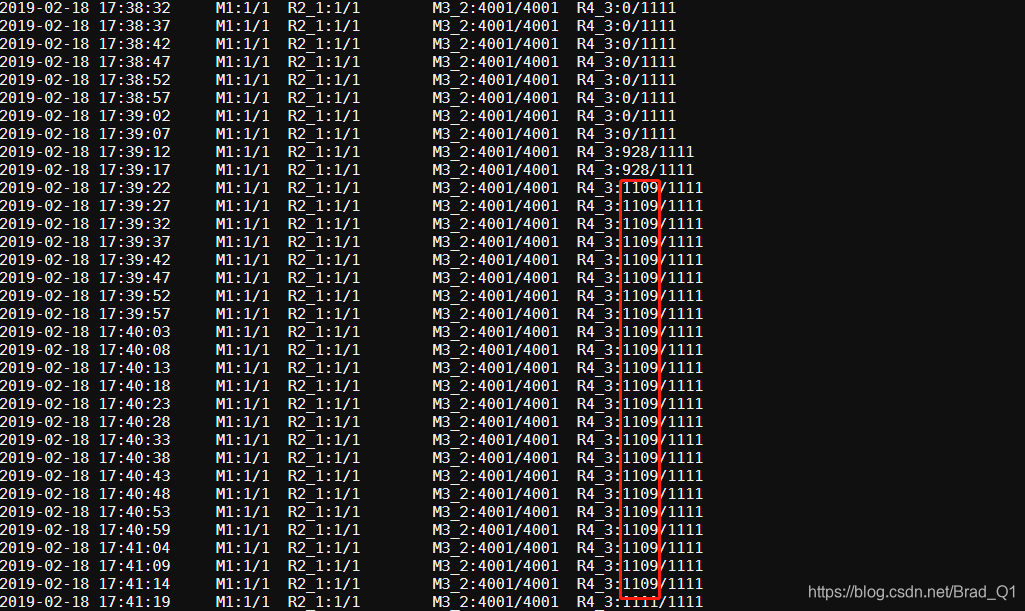
可以看出确实是有倾斜,那么怎么解决呢?
因为本人有点懒,遇到这种问题向来第一反应是,弄张临时表,然后临时表再去 count distinct运算,临时表计算分两步:
第一步、建临时表,把需要的字段都放进去
create table if not exists tmp_user_type_log
AS
SELECT /*+mapjoin(a)*/b.user_type_id
,certi_no
FROM tmp_user a
JOIN tmp_user_log b
ON a.user_id = b.user_id
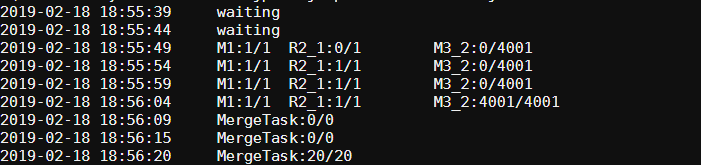
上面运行没用一分钟,还行
第二步,运行临时表的count distinct 计算,语句如下:
select user_type_id
,count(distinct certi_no) as certi_no
from tmp_user_type_log
group by user_type_id
;
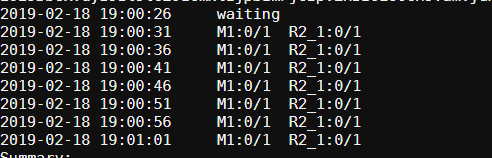
运行也是几十秒,说明也挺快,结果跟前面贴出来的一致,这里不再重复贴出来了。总体来说,已经快了很多了。
后来闲下来的时候想,应该还有其他不这么直接暴力的方法,因为既然是运行count distinct,那么null值是肯定不会被计算进去,而一般倾斜的原因之一的数据分布不均匀,就是由于Null值造成的。
- 检查该字段certi_no的空值数量为:1,258,376,131
- 而总的数据量为:5,617,310,131
- 所占比例:22%
所以有理由认为是null值造成的倾斜,因此优化就简单了,直接在where条件中去掉null值得即可(先大胆测试一般):
SELECT /*+mapjoin(a)*/b.user_type_id
,count(distinct certi_no) certi_no
FROM tmp_user a
JOIN tmp_user_log b
ON a.user_id = b.user_id
where b.certi_no IS NOT NULL
GROUP BY b.user_type_id
;
结果总共30秒不到就出结果了:

运行结果与前面第一个结果一致,如下:
| user_type_id | certi_no |
+--------------+------------+
| 11 | 114982 |
| 12 | 26654 |
可见,再去除掉NULL值后,count distinct的运算还是很快的。了解数据业务逻辑,以及数据分布结构,才能更好的做相关性能的优化。