shell:为了更加便利执行系统任务
直接开始学习:
编写hello world
#vim test.sh
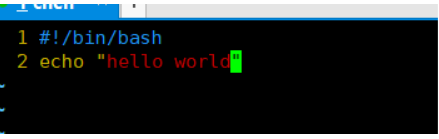
执行结果:
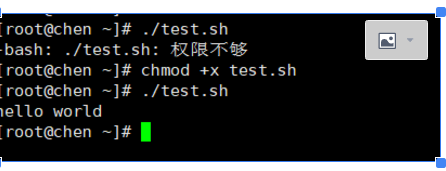
这里可以用几种方式执行
1.在当前目录下的话,执行命令#./test.sh
2.没有在当前目录下的话,可以#source test.sh 或bash test.sh
注:source filename 与bash filename的区别
当shell脚本具有可执行权限时,用bash filename与./filename执行脚本是没有区别得。./filename是因为当前目录没有在PATH中,所以”.”是用来表示当前目录的。
source filename:这个命令其实只是简单地读取脚本里面的语句依次在当前shell里面执行,没有建立新的子shell。那么脚本里面所有新建、改变变量的语句都会保存在当前shell里面。
bash filename 重新建立一个子shell,在子shell中执行脚本里面的语句,该子shell继承父shell的环境变量,但子shell新建的、改变的变量不会被带回父shell。
子shell新建变量,在父shell中不会失效
可以使用pstree查看当前所处位置
这里添加小练习:
练习1:使用root用户帐号创建并执行test2.sh,实现创建一个shelltest用户,并在其家目录中新建文件chen.html。
练习2:统计当前系统总共有多少用户(答案在文章结尾)
答案:
1.vim test2.sh
#!/bin/bash
useradd test2.sh
touch /home/shelltest/chen.sh
2.#!/bin/bash
cat /etc/passwd | wc -l
shell常用命令
grep
选项 描述
-E,–extended-regexp 模式是扩展正则表达式(ERE)
-i,–ignore-case 忽略大小写
-n,–line-number 打印行号
-o,–only-matching 只打印匹配的内容
-c,–count 只打印每个文件匹配的行数
-B,–before-context=NUM 打印匹配的前几行
-A,–after-context=NUM 打印匹配的后几行
-C,–context=NUM 打印匹配的前后几行
–color[=WHEN], 匹配的字体颜色
-v,–invert-match 打印不匹配的行
cut:
cut命令从文件的每一行剪切字节、字符和字段并将这些写至标准输出
-d 自定义分隔符
-f 常与-d使用
案例:
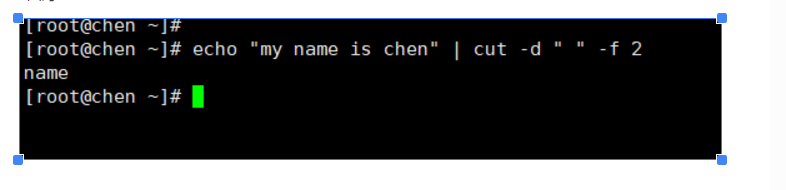
以空格为分隔符,截取这句话的第二段 就是name
sort:
对文件内容以行为单位进行排序
-k:根据切割后的那一段进行排序
-n 依照数值的大小排序(默认是根据字符进行排序)。
-r 以相反的顺序来排序。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
-u:去除重复的行(只要那个指定的字段重复,就认定是重复的行)
常用的是-n -r -u
案例
对此文件进行排序
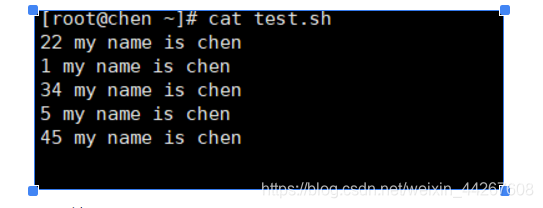
排序结果
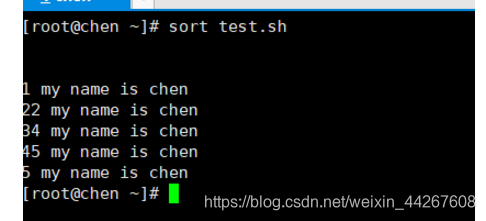
这里是按首位数字大小排序的
#sort -n test.sh 可正常排序
uniq:
去除重复的行(相邻且相同,认定为重复)
-c:在行首用数字表示该行出现了多少次
-u:仅仅显示那些没有出现重复过的行
tr:
Linux tr 命令用于转换或删除文件中的字符。
tr 指令从标准输入设备读取数据,经过字符串转译后,将结果输出到标准输出设备。
[root@ken ~]# echo “this is ken” | tr a-z A-Z
THIS IS KEN
[root@ken ~]# echo “THIS IS KEN” | tr A-Z a-z
this is ken
作业1. 获取主机IP地址,获取结果仅显示IP,例如:192.168.1.2
作业2. 有如下一个文件,文件内容如下。
请把下方的内容复制到你的一个文件中,并完成如下需求
需求1. 统计出各个网址出现的次数
需求2. 按照出现次数排序(升序)
需求3. 取出出现次数排名前两名的网址
文件内容
http://www.baidu.com
http://www.baidu.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.sina.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.qq.com
http://www.qq.com
http://www.qq.com
http://www.qq.com
http://www.qq.com
http://www.qq.com
http://www.qq.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.taobao.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
http://www.baidu.com
1.# ifconfig | grep “broadcast” | cut -d " " -f 10 | head -1
(每个人以空格为分隔符,数的单位数不一定相同,尽量试试数字大的,例如10 或15)

2.统计出各个网址出现的次数
cat test.sh | cut -d “/” -f3 | sort | uniq -c

按照出现次数排序(升序)
cat test.sh | cut -d “/” -f3 | sort | uniq -c | sort -n

取出出现次数排名前两名的网址
#cat test.sh | cut -d “/” -f3 | sort | uniq -c | sort -nr | head -2
