Pool-Based Active Learning for Text Classification
这篇文章是Kamal在1999年的文章,比较老,但拿来看看。
1.介绍
在标记的训练数据稀疏时使用大量未标记文档进行文本分类,通过对整个未标记文档池中选择标记请求来增强QBC(Query-by-Committee)主动学习算法,并明确地使用池来估计区域文档密度,将主动学习和期望最大化(EM)结合,利用保留在未标记池中许多文档包含的大量信息。
主动学习旨在选择最具信息性的例子,如果他们类标签已知,将最大限度地减少分类错误和方差分布的变化。
使用更丰富的组合,即池式杠杆采样(pool-leveraged sampling)
任务:已经有一些有标签网页(如标定,体育,娱乐),和大量未标记网页,如何训练模型打标签。
2 朴素贝叶斯与EM
假设文档由混合模型生成,参数
.混合模型包含生成组分
,
表示第j个混合组分和第j个类别。
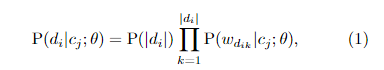
EM算法的E-step:把标签作为隐变量,猜测文档的标签;M-step:模型分类,更新标签信息。
朴素贝叶斯:简单的分类模型。
在本文中,
E-step:标签的当前估计值为无标签样本打标签(概率标签);
M-step:利用有标签样本最大似然估计。
不断迭代。
3主动学习与EM算法
将主动学习与EM算法结合,步骤:
1计算每个文档的密度。
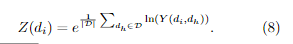
2EM算法
2.1 从有标签样本获得初始值。

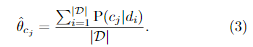
2.2对每类使用Dirichlet分布采样。
2.3 EM算法应用到分类器上。
E:使用当前分类预测无标签样本分布;
M:利用概率化加权的样本,重新计算分类器的参数。
2.4把训练好的分类器预测无标签样本(获得概率化的标签)
2.5计算无标签样本之间的差异(KL散度),乘于各自的密度,获得分数最高的。
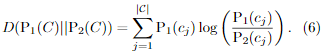
4 总结
方法比较美妙,受启发的点有:使用EM算法来评估哪些文档与原来文档差异性大,或者包含信息量大,用于进行QBC标定。
不懂的地方是,引入pool池密度估计,不是很清楚怎么做的,以及它的含义。(论文说的是,自己用KL散度衡量文档差异而定义的
, 那
值最大为什么就需要进行主动请求标签样本)。这里论文的解释是,选择最具信息性例子,即减少分类错误以及方差分布,使用KL可以衡量这个?
参考:
1原论文;