一、基本概念
1. mro序列
MRO是一个有序列表L,在类被创建时就计算出来。
通用计算公式为:
mro(Child(Base1,Base2)) = [ Child ] + merge( mro(Base1), mro(Base2), [ Base1, Base2] ) (其中Child继承自Base1, Base2)
如果继承至一个基类:class B(A)
这时B的mro序列为
mro( B ) = mro( B(A) ) = [B] + merge( mro(A) + [A] ) = [B] + merge( [A] + [A] ) = [B,A]
如果继承至多个基类:class B(A1, A2, A3 …)
这时B的mro序列
mro(B) = mro( B(A1, A2, A3 …) ) = [B] + merge( mro(A1), mro(A2), mro(A3) ..., [A1, A2, A3] ) = ...
计算结果为列表,列表中至少有一个元素即类自己,如上述示例[A1,A2,A3]。merge操作是C3算法的核心。
2. 表头和表尾:
表头: 列表的第一个元素
表尾: 列表中表头以外的元素集合(可以为空)
示例
列表:[A, B, C]
表头是A,表尾是B和C
3. 列表之间的+操作
+操作:
[A] + [B] = [A, B] (以下的计算中默认省略)
3. merge操作:
merge操作流程图:
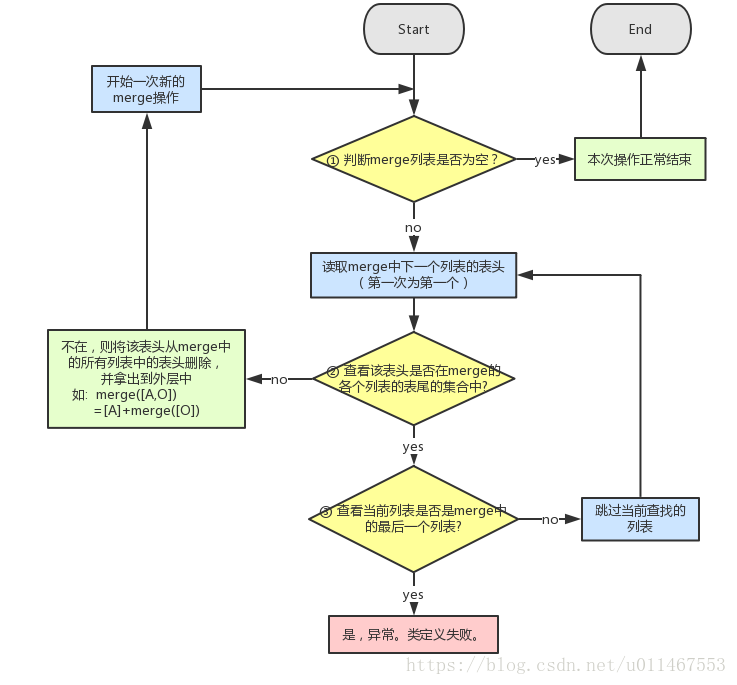
merge操作示例:
如计算merge( [E,O], [C,E,F,O], [C] ) 有三个列表 : ① ② ③ 1 merge不为空,取出第一个列表列表①的表头E,进行判断 各个列表的表尾分别是[O], [E,F,O],E在这些表尾的集合中,因而跳过当前当前列表 2 取出列表②的表头C,进行判断 C不在各个列表的集合中,因而将C拿出到merge外,并从所有表头删除 merge( [E,O], [C,E,F,O], [C]) = [C] + merge( [E,O], [E,F,O] ) 3 进行下一次新的merge操作 ......
二、实例
1. 计算实例1
示例:(多继承UML图,引用见参考) 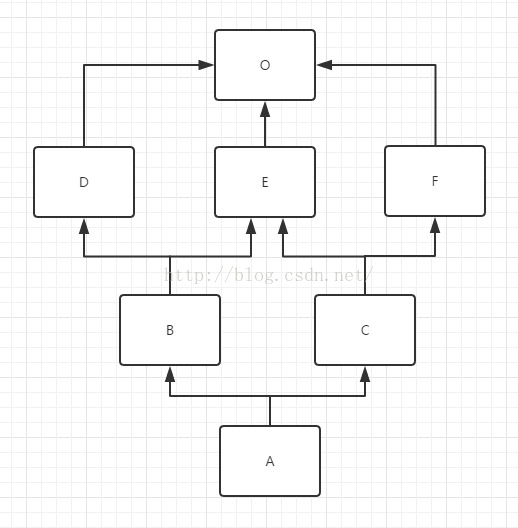
备注:O==object
如何计算mro(A) ?
mro(A) = mro( A(B,C) ) 原式= [A] + merge( mro(B),mro(C),[B,C] ) mro(B) = mro( B(D,E) ) = [B] + merge( mro(D), mro(E), [D,E] ) # 多继承 = [B] + merge( [D,O] , [E,O] , [D,E] ) # 单继承mro(D(O))=[D,O] = [B,D] + merge( [O] , [E,O] , [E] ) # 拿出并删除D = [B,D,E] + merge([O] , [O]) = [B,D,E,O] mro(C) = mro( C(E,F) ) = [C] + merge( mro(E), mro(F), [E,F] ) = [C] + merge( [E,O] , [F,O] , [E,F] ) = [C,E] + merge( [O] , [F,O] , [F] ) # 跳过O,拿出并删除 = [C,E,F] + merge([O] , [O]) = [C,E,F,O] 原式= [A] + merge( [B,D,E,O], [C,E,F,O], [B,C]) = [A,B] + merge( [D,E,O], [C,E,F,O], [C]) = [A,B,D] + merge( [E,O], [C,E,F,O], [C]) # 跳过E = [A,B,D,C] + merge([E,O], [E,F,O]) = [A,B,D,C,E] + merge([O], [F,O]) # 跳过O = [A,B,D,C,E,F] + merge([O], [O]) = [A,B,D,C,E,F,O]
2. 实例代码测试
对于以上计算,用代码来测试。
class D: pass class E: pass class F: pass class B(D,E): pass class C(E,F): pass class A(B,C): pass print("从A开始查找:") for s in A.__mro__: print(s) print("从B开始查找:") for s in B.__mro__: print(s) print("从C开始查找:") for s in C.__mro__: print(s)
结果:
从A开始查找: <class '__main__.A'> <class '__main__.B'> <class '__main__.D'> <class '__main__.C'> <class '__main__.E'> <class '__main__.F'> <class 'object'> 从B开始查找: <class '__main__.B'> <class '__main__.D'> <class '__main__.E'> <class 'object'> 从C开始查找: <class '__main__.C'> <class '__main__.E'> <class '__main__.F'> <class 'object'>
三、总结
每次判断如何读取都要这么麻烦计算吗?可有简单方法?
我对此做了一个简单总结。
1. 规律总结
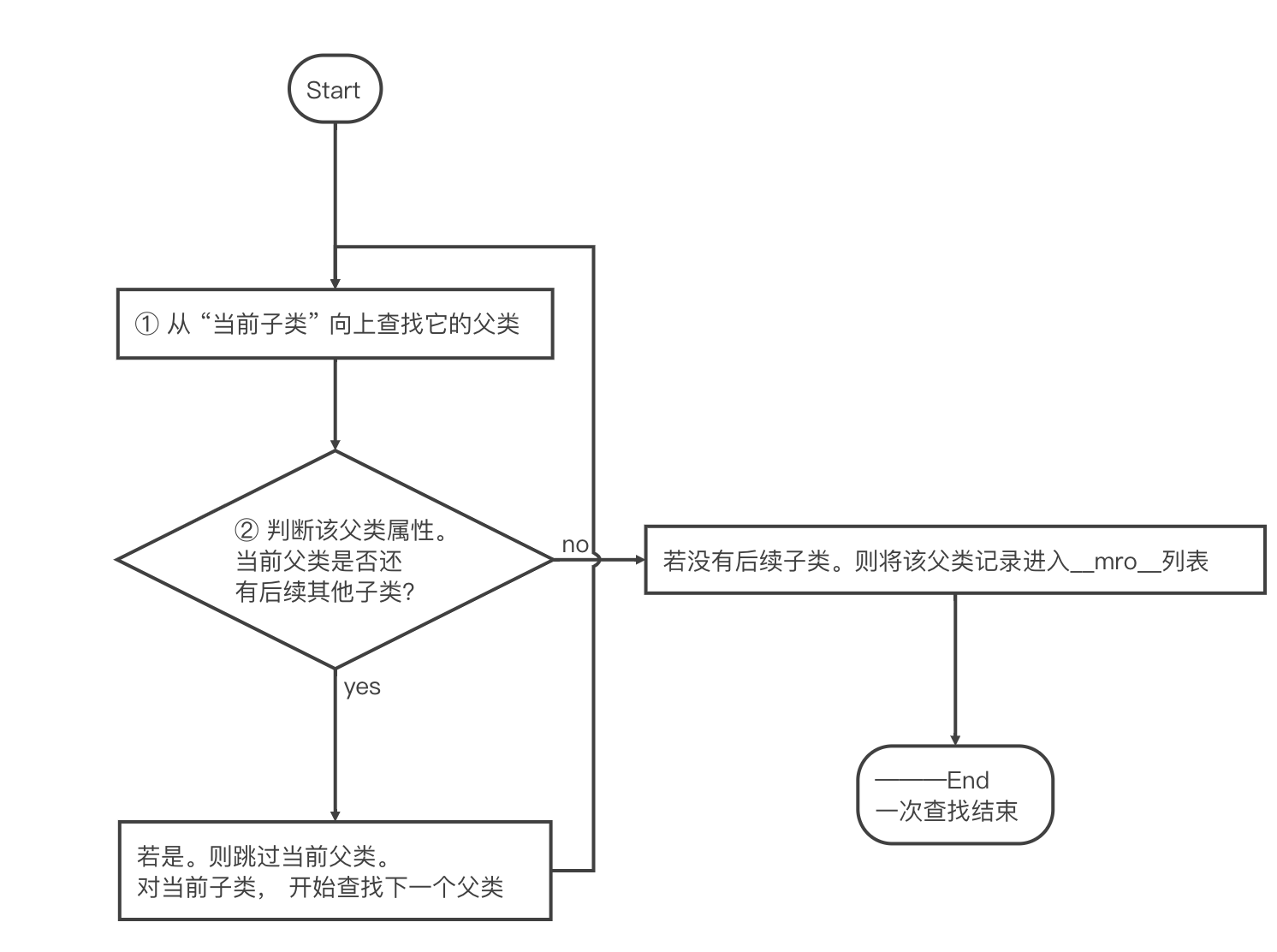
如何快速判断查找规律?
从 “当前子类” 向上查找它的父类,
若 “当前子类” 不是 “查找的父类” 的最后一个继承的子类时,则跳过该 “查找的父类” 的查找,开始查找 “当前子类” 的下一个父类
查找规律流程图:
2. 规律测试
实例2:
对于如下继承:
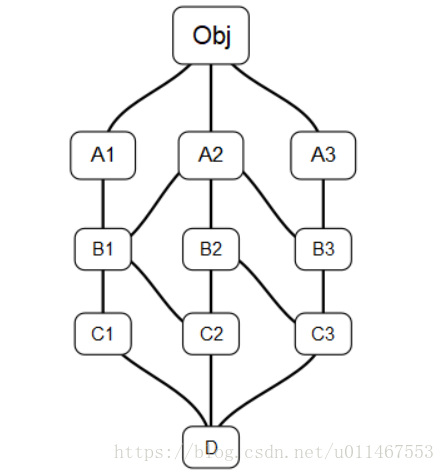
通过如下判断模式:
代码测试:
class A1: pass class A2: pass class A3: pass class B1(A1,A2): pass class B2(A2): pass class B3(A2,A3): pass class C1(B1): pass class C2(B1,B2): pass class C3(B2,B3): pass class D(C1, C2, C3): pass print("从D开始查找:") for s in D.__mro__: print(s) print("从C3开始查找:") for s in C3.__mro__: print(s)
结果:
从D开始查找: <class '__main__.D'> <class '__main__.C1'> <class '__main__.C2'> <class '__main__.B1'> <class '__main__.A1'> <class '__main__.C3'> <class '__main__.B2'> <class '__main__.B3'> <class '__main__.A2'> <class '__main__.A3'> <class 'object'> 从C3开始查找: <class '__main__.C3'> <class '__main__.B2'> <class '__main__.B3'> <class '__main__.A2'> <class '__main__.A3'> <class 'object'>