Problem
Description
小 \(G\) 是一个出色的诗人,经常作诗自娱自乐。但是,他一直被一件事情所困扰,那就是诗的排版问题。
一首诗包含了若干个句子,对于一些连续的短句,可以将它们用空格隔开并放在一行中,注意一行中可以放的句子数目是没有限制的。小 \(G\) 给每首诗定义了一个行标准长度(行的长度为一行中符号的总个数),他希望排版后每行的长度都和行标准长度相差不远。显然排版时,不应改变原有的句子顺序,并且小 \(G\) 不允许把一个句子分在两行或者更多的行内。在满足上面两个条件的情况下,小 \(G\) 对于排版中的每行定义了一个不协调度, 为这行的实际长度与行标准长度差值绝对值的 \(P\) 次方,而一个排版的不协调度为所有行不协调度的总和。
小 \(G\) 最近又作了几首诗,现在请你对这首诗进行排版,使得排版后的诗尽量协调(即不协调度尽量小),并把排版的结果告诉他。
Input Format
输入文件中的第一行为一个整数 \(T\),表示诗的数量。
接下来为 \(T\) 首诗,这里一首诗即为一组测试数据。每组测试数据中的第一行为三个由空格分隔的正整数 \(N\),\(L\),\(P\),其中:\(N\) 表示这首诗句子的数目,\(L\) 表示这首诗的行标准长度,\(P\) 的含义见问题描述。
从第二行开始,每行为一个句子,句子由英文字母、数字、标点符号等符号组成(ASCII码33~127,但不包含'-')。
Output Format
于每组测试数据,若最小的不协调度不超过 \(10^{18}\) ,则第一行为一个数,表示不协调度。
\(Luogu\) 额外快乐:接下来若干行,表示你排版之后的诗。注意:在同一行的相邻两个句子之间需要用一个空格分开。如果有多个可行解,它们的不协调度都是最小值,则输出任意一个解均可。
若最小的不协调度超过 \(10^{18}\) ,则输出“\(Too\ hard\ to\ arrange\)”(不含引号)。每组测试数据结束后输出“--------------------”(不含引号),共20个“-”,“-”的ASCII码为45,请勿输出多余的空行或者空格。
Sample
Input
4
4 9 3
brysj,
hhrhl.
yqqlm,
gsycl.
4 9 2
brysj,
hhrhl.
yqqlm,
gsycl.
1 1005 6
poet
1 1004 6
poetOutput
108
brysj,
hhrhl.
yqqlm,
gsycl.
--------------------
32
brysj, hhrhl.
yqqlm, gsycl.
--------------------
Too hard to arrange
--------------------
1000000000000000000
poet
--------------------Explanation
Explanatoin for Input
前两组输入数据中每行的实际长度均为6,后两组输入数据每行的实际长度均为4。一个排版方案中每行相邻两个句子之间的空格也算在这行的长度中(可参见样例中第二组数据)。每行末尾没有空格。
Range
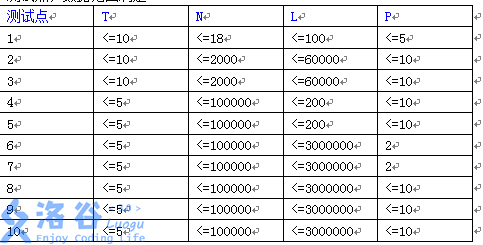
所有句子的长度不超过 \(30\)
Algorithm
\(DP\),决策单调性。
Mentality
我们发现数据范围不小不大,正好是 \(nlog\) 到 \(nlog^2\) 级别的。
先记录一个前缀和 \(q\) ,\(q[i]\) 表示句子 \(1-i\) 的长度总和,注意加上空格的长度。
首先观察到一个很显然的一维 \(dp\) ,\(f[i]\) 代表选到了第 \(i\) 个句子并且在此换行的最小不协调度,设 \(w(i,j)=abs(q[i]-q[j]-L-1)^P\) ,那么我们可以得到这样一个 \(n^2\) 的 \(dp\) :
\[ f[i]=Min_{j<i}(f[j]+w(i,j)) \]
这确确实实是很简单的,但是很显然,复杂度过不了关。
那么考虑如何优化:
众所周知,\(dp\) 分为三个部分,枚举状态×枚举决策点×状态转移=时间复杂度。
我们考虑一个个下手。
对于枚举状态的部分,由于必须顺着推过去,所以 \(O(n)\) 还是跑不了。
对于枚举决策点的部分,我们发现这个式子异常眼熟,一看就符合决策单调性的应用式。
对于状态转移的部分,\(O(1)\) 不能再优化了。
那么我们考虑如何利用决策单调性来优化这道题目。首先,对于一维 \(dp\) ,设 \(g[i]\) 为状态 \(i\) 的最优决策点,它的决策单调性的显著特征自然是:\(g[i-1]\le g[i]\) ,那么我们考虑利用这种决策单调性来做题。
我们利用队列记录下每个决策点 \(que\) ,并记录其对应下一个决策点左区间 \(L\) 。之所以这样做,是因为对于每个决策点,它对于每个区间的优劣性是不同的,所以它必定只会对一个区间最优。
但是这题之所以满足决策单调性,就是因为对于决策点而言,决策点位置的递增也意味着对应区间的递增,也就是说对于最右边的一段区间某个位置至位置 \(n\) ,最优决策点必定是最新的决策点。
对于这一点,我们可以有如下证明:
- 首先我们回到问题,我们已经选出了一些句子分好了行,在当前行我们还未换行。
- 不考虑下一行,那么如果还有句子加上当前的句子的长度小于标准长度,则一定要选,若长度之和大于标准长度,则只需要考虑选与不选。
- 所以,对于当前行的决策,我们只会浮动在两个左右的决策点之间,因为 \(w\) 函数的指数性递增决定了我们选择的单调性。
- 所以对于越往后的区间,它的最优决策点就越往后,因为 \(w\) 函数过大会造成 \(dp\) 的变劣。
那么我们的 \(dp\) 就分为了如下几个过程,设当前 \(dp[i]\) 正被更新:
- 1、找到对应 \(i\) 的决策点区间,如果队首不符合就 \(head++\) ,直到当前队首决策点的对应区间包括 \(i\) 。
- 2、\(f[i]=f[que[head]]+work(que[head],i)\) ,通过队首的决策点来转移。
- 3、通过二分寻找出最左边的,以队尾决策点为决策点不如以 \(i\) 为决策点更优的位置,由于单调变优性,从这个位置往右的 \(dp\) 都满足以 \(i\) 为决策点是目前最优的。如果这个最左边的位置要小于队尾决策点对应的左区间,那么说明对于这个决策点对应的所有转移都不如 \(i\) 更优,所以弹出队尾,我们继续判断新的队尾与 \(i\) 的决策。
- 4、当队尾的弹出停止的时候,我们二分出的位置往右的 \(dp\) 都以 \(i\) 决策最优,那么把当前队尾的决策区间右端点改为这个位置,\(q[++tail]=i\) 将 \(i\) 入队,且 \(i\) 的对应区间右端点为 \(n\) 。
不过需要注意,我们应用 \(long\ double\) 存下 \(dp\) 值,因为如果 \(dp\) 值大于 \(1e18\) 就不能用 \(long\ long\) 存了,但是用 \(long\ double\) 还是可以比较大小。科学计数法好。
完成!
Code
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
using namespace std;
int head,tail,T,n,len,P,q[100001],g[100001],L[100001],que[100001];
char s[100002][31];
long double f[100001];
long double ksm(long double x)
{
int base=P;
long double a=1;
while(base)
{
if(base&1)
a=a*x;
x=x*x;
base>>=1;
}
return a;
}//快速幂
long double work(int i,int j){return f[j]+ksm((long double)abs(q[i]-q[j]-1-len));}//计算以 j 为决策点 i 将得到的状态转移值
int find(int x,int y)
{
int l=x,r=n+1;
while(l<r)
{
int mid=(l+r)>>1;
work(mid,x)>=work(mid,y)?r=mid:l=mid+1;
}
return l;
}//查找 i 的最左最优决策位置
int main()
{
cin>>T;
while(T--)
{
cin>>n>>len>>P;
for(int i=1;i<=n;i++)
{
q[i]=0;
scanf("%s",s[i]);
q[i]=strlen(s[i])+q[i-1]+1;//单词长度前缀和
}
que[head=tail=1]=0;//初始化决策点队列
for(int i=1;i<=n;i++)
{
while(head<tail&&L[head]<=i)//先找到对应区间包含 i 的位置,L 记录的是下一个决策区间的左端点
head++;
g[i]=que[head];
f[i]=work(i,g[i]);//更新 dp 值
while(head<tail&&L[tail-1]>=find(que[tail],i))//进行队尾判断
tail--;
L[tail]=find(que[tail],i);//更新队尾区间
que[++tail]=i;//决策点入队
}
if(f[n]>1e18)
puts("Too hard to arrange");
else
{
printf("%lld\n",(long long)f[n]);
int top=0;
for(int i=n;i;i=g[i])
q[++top]=g[i];
q[0]=n;
while(top--)
{
int L=q[top+1]+1,R=q[top];
for(int i=L;i<R;i++)
printf("%s ",s[i]);
puts(s[R]);//行末不能有空格
}
}
puts("--------------------");
}
cout<<endl;
}