MySql5.5之前默认的引擎是MyISAM,之后默认引擎修改为InnoDB,如果需要修改默认引擎,可以在参数文件中设置default-table-type。
查看当前默认引擎
show variables like '%engine%';
查看当前数据库支持的引擎
show engines;
一、MyISAM
MyISAM不支持事务、不支持外键。有点是访问速度快,对事务完整性没有要求。以select、insert为住的应用基本上都可以用这个引擎来创建表。
MyISAM类型的表可能会损坏,原因可能是多种多样的。可以通过check table语句检查MyISAM表的健康,并用repair table 语句修复一个损坏的MyISAM表。
每个MyISAM磁盘上存储成3个文件,器中文件名和表名相同,但扩展名分别是
.frm(存储表定义)
.MYD(MYData,存储数据)
.MYI(MYIndex,存储索引)
MyISAM的表还支持3种不同的存储格式,分别是:
静态(固定长度)表;
动态表;
压缩表
其中静态表是默认存储格式。
静态表特点:长度固定。优点是存储非常迅速,容易缓存,出现故障时容易恢复;缺点是占用的空间通常比动态表多。静态表的数据在存储时会按照列的宽度补充尾部空格,但是在应用访问的时候并不会得到这些空格,这些空格在返回给应用的实惠就已经被去掉。所以需要注意的是当数据尾部本身就存在空格的时,会导致尾部空格丢失。
动态表特点呢:记录长度不固定,这样存储的优点是占用的控件相对较小,但是频繁的更新和删除记录会产生碎片,需要定期执行 optimize table语句或myisamchk-r命令来改善性能。 并且在出现故障时恢复相对比较困难。
压缩表:有myisampack工具创建,占用非常小的磁盘空间,因为每个记录都是被单独压缩的,所以只有非常小的访问开支。
create table myisam_char( name char(10)) engine=myisam;
二、InnoDB
mysql5.5之后的默认引擎修改为InnoDB。InnoDB存储引擎具有提交、回滚和崩溃恢复能力的事务安全。但是相对MyISAM,InnoDB写的处理效率差一点。并且会占用更多的磁盘以保留数据和索引。
InnoDB的特点:
1、自动增长列(与myisam自动增长的区别)
InnoDB的自动增长可手动插入,但是插入的值如果是空或0的时候,则实际插入的值将是自动增长后的值。
可以通过 " alter table *** auto_increment = n ;"语句强制设置自动增长的初始值。默认是从1开始,但是该强制的默认值是保存在内存中,所以该值在使用之前数据库从新启动,那么这个强制值就会丢失,需要重启数据库后重新设置。
LAST_INSER_ID(),用来查询当前线程最后插入记录使用的值,如果一次插入多条记录,那么返回的是第一条记录使用的自动增长的值。
InnoDB和MyISAM的auto_increment 区别:
对于InnoDB表,自动增长列必须是索引。如果是组合索引,也必须是组合索引的第一列,但是对于MyISAM表,自动增长列可以是组合索引的其他列,这样插入记录后,自动增长列是按照祝贺索引的前几列进行排序后递增。
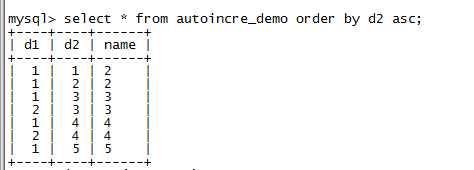
例如创建一个新的MyISAM类型的表autoincre_demo,自动增长列d1作为组合索引的第二列,对该表插入一些记录后,可以发现自己增长列是按照组合索引的第一列d2进行排序后递增
create table autoincre_demo (d1 smallint not null auto_increment, d2 smallint not null, name varchar(10), index(d2,d1) ) engine=myisam; insert into autoincre_demo values(2,'2'),(3,'3'),(4,'4'),(2,'2),,(3,'3'),(4,'4');
结果:
d1 d2 name
1 2 2
1 3 3
1 4 4
2 2 2
2 3 3
2 4 4
2、外键约束
MySQL支持外键的存储引擎之友InnoDB,在创建外键的实惠,要求腐败必须有对应的索引,子表的在创建外键的时候也会自动创建对应的索引。
3、存储方式
InnoDB存储表的索引有一下两种方式:
1、使用共享表空间存储,这种创建的表的表结构保存在.frm文件中,数据和索引保存在innodb_data_home_dir和innodb_data_file_path定义的表中间,可以是多个文件。 2、使用多表空间存储,这种方式创建的表的表结构仍然保存在.frm文件中,但是每个表的数据和索引单独保存在.ibd中,如果是个分区表,则每个分区对应单独的.ibd文件,文件名是“表名+分区名”,可以在创建分区的时候指定每个分区的数据文件位置,以此来将表的IO均匀分布在多个磁盘中。
要使用多表空间存储方式,需要设置参数innodb_file_per_table,并从新启动服务后才可以生效,对于新建的表按照多表空间的方式创建,已有的表仍然使用共享空间存储。如果将已有的多表空间方式修改会共享表空间的方式,则新建表会在共享表空间中创建,单已有的多表空间的表仍然保存原来的访问方式。所以多表空间的参数设置生效后,只对新建的表生效。
主要:即便在多表空间的存储方式下,共享表空间仍然是必须的InnoDB把内部数据字典和在线重做日志放在这文件中。
三、memory
memory存储引擎使用存在内存中的内存来创建表,每个menory表只实际对应一个磁盘文件,格式是.frm。
memory的访问速度非常快,因为它的数据是放在内存中的,并默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
给memory表创建索引的时候,可以指定使用的是HASH索引还是BTREE索引。
create index mem_hash using HASH on tab_memory(city_id);
四、merge
merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据。对merge类型的表可以进行查询、更新、删除操作,这些操作其实是对内部的MyISAM表进行的。
对于memory类型表的插入操作,是通过insert_method字句定义插入的表,可以有三个不同的值,使用first或last值使得插入操作被相应地作用在第一或最后一个表上。不定义这个字句或者定义为no,表示不能对merge表执行插入操作。
可以对merge进行drop操作,这个操作只是删除merge的定义,对内部的表没有任何的影响。
merge表的磁盘中保留了两个文件,文件名以表的名字开始,一个.frm文件存储表定义,另一个.MRG文件包含组合表的信息,包含merge表由哪些表组成,插入新的数据时的依据。可以通过修改.MRG文件修改merge表,但是修改后需要通过flush tables刷新,
示例:
创建三个测试表
create table payment_2018( country_id smallint, payment_date datetime, amount decimal(15,2), key idx_fk_country_id (country_id) )engine = myisam;
create table payment_2019( country_id smallint, payment_date datetime, amount decimal(15,2), key idx_fk_country_id (country_id) )engine = myisam;
create table payment_all( country_id smallint, payment_date datetime, amount decimal(15,2), index(country_id) )engine=merge union=(payment_2018,payment_2019) insert_method=last;
分别向payment_2018、payment_2019插入数据,可以发现payment_all中的数据是payment_2018和payment_2019记录合并的结果集。
下面对payment_all插入一条记录,由于insert_method=last,就会向最后一个表插入记录。下面这条记录会存在payment_2019以及payment_all表中。虽然这条记录是2018年的但是也是会插入到2019的这张表中。
insert into payment_all values(3, '2018-03-31',112200);
这就是merge表和分区表的区别。merge表并不能智能的将记录写到对应表中。而分区表是可以的。通常我们使用merge表来透明的低对多个表进行查询和更新的操作,而对这种按照时间记录的操作日志表则可以透明地进行插入操作。