前面文章介绍了Redis的主从复制,虽然该模式能够在一定程度上提高系统的稳定性,但是在数据访问量比较大的情况下,单个master应付起来还是比较吃力的,这时我们可以考虑将redis集群部署,本文就来重点给大家介绍下Redis的集群部署操作。
Redis集群
一、Redis集群相关概念
1.Redis集群介绍
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令. Redis 集群的优势:
1.自动分割数据到不同的节点上。
>2.整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
2.Redis分片策略
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有==16384==个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500号哈希槽.
节点 B 包含5501 到 11000 号哈希槽.
节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
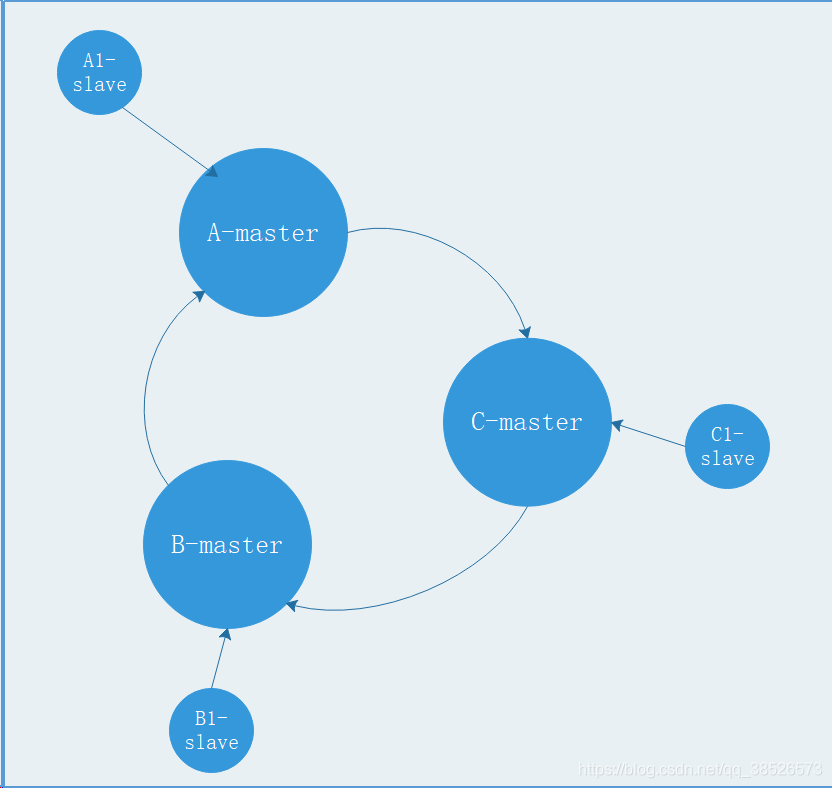
3.Redis的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
二、Redis集群搭建
1.集群的结构
根据官网描述要让redis集群环境正常运行我们必须准备至少3个主节点,所以在本文中的集群环境我们准备3个主节点实例及对应的给每个主节点准备一个从节点实例,一共6个redis实例。正常需要6个虚拟机节点,本文我们在一个虚拟机上模拟。
2.集群的环境准备
搭建集群需要使用到官方提供的ruby脚本。
需要安装ruby的环境。
安装ruby
yum -y install ruby
yum -y install rubygems
gem install redis错误处理
[root@hadoop-node01 src]# gem install redis
ERROR: Error installing redis:
redis requires Ruby version >= 2.2.2.解决方式参考此链接:https://blog.csdn.net/qq_38526573/article/details/87220510
解决完成后再次执行gem install redis命令
[root@hadoop-node01 ~]# gem install redis
Fetching: redis-4.1.0.gem (100%)
Successfully installed redis-4.1.0
Parsing documentation for redis-4.1.0
Installing ri documentation for redis-4.1.0
Done installing documentation for redis after 1 seconds
1 gem installed注意ruby对应的redis版本是4.1.0
各版本下载地址
http://download.redis.io/releases/
3.搭建集群环境
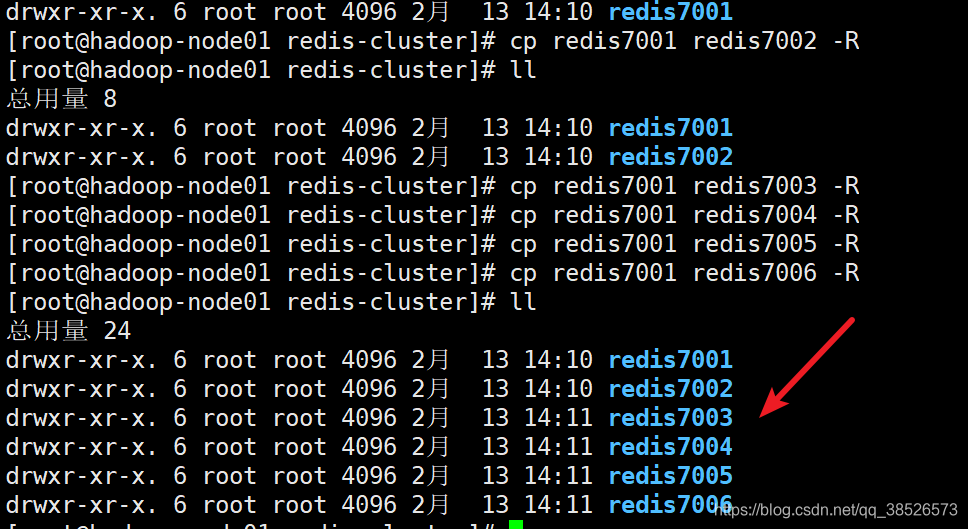
3.1创建实例
在/opt目录下创建redis-cluster目录,并在该目录下创建6个redis实例

3.2修改配置文件
分别修改6个实例的配置文件
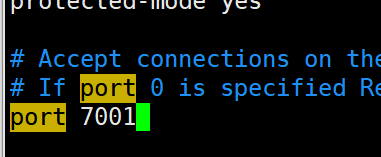
1.修改端口号
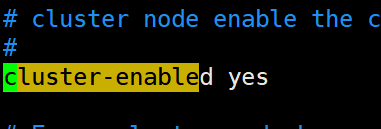
2.打开cluster-enable前面的注释
3.注释掉绑定ip
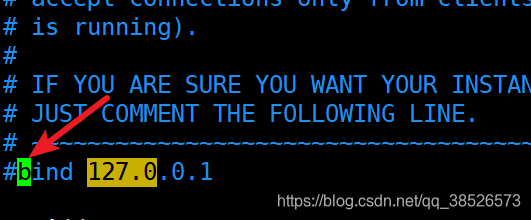
4.保护模式修改为no
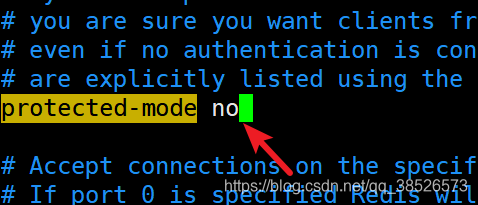
5.设置日志存储路径

注意重复修改6次。
3.3复制ruby脚本
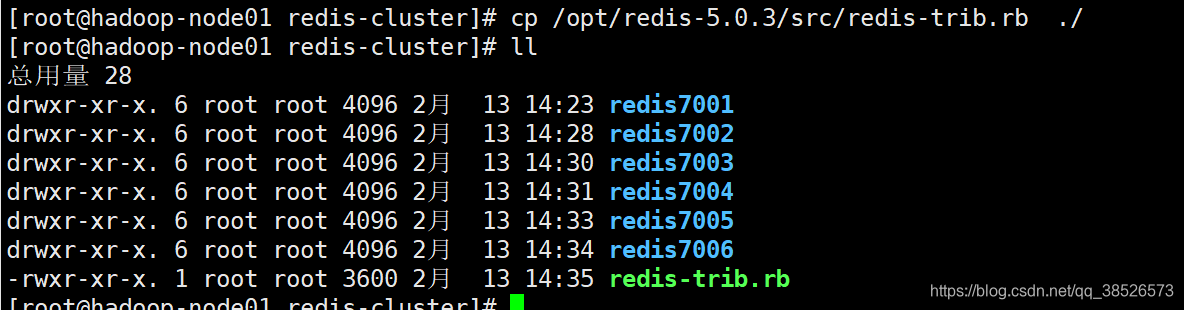
3.4启动6个实例
启动实例时可能报错
Ps: [ERR] Node 172.168.63.202:7001 is not empty. Either the nodealready knows other nodes (check with CLUSTER NODES) or contains some解决办法:
将每个节点下aof、rdb、nodes.conf本地备份文件删除;
编写简单脚本启动
start-all.sh
cd /opt/redis-cluster/redis7001
rm -rf dump.rdb nodes.conf appendonly.aof
src/redis-server redis.conf
cd /opt/redis-cluster/redis7002
rm -rf dump.rdb nodes.conf appendonly.aof
src/redis-server redis.conf
cd /opt/redis-cluster/redis7003
rm -rf dump.rdb nodes.conf appendonly.aof
src/redis-server redis.conf
cd /opt/redis-cluster/redis7004
rm -rf dump.rdb nodes.conf appendonly.aof
src/redis-server redis.conf
cd /opt/redis-cluster/redis7005
rm -rf dump.rdb nodes.conf appendonly.aof
src/redis-server redis.conf
cd /opt/redis-cluster/redis7006
rm -rf dump.rdb nodes.conf appendonly.aof
src/redis-server redis.conf改变文件脚本权限模式:
chmod 777 start-all.sh
然后再启动:
./start-all.sh
3.5创建集群
现在我们已经有了六个正在运行中的 Redis 实例, 接下来我们需要使用这些实例来创建集群, 并为每个节点编写配置文件。
通过使用 Redis 集群命令行工具 redis-trib , 编写节点配置文件的工作可以非常容易地完成: redis-trib 位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查集群, 或者对集群进行重新分片(reshared)等工作
./redis-trib.rb create --replicas 1 192.168.88.121:7001 192.168.88.121:7002 192.168.88.121:7003 192.168.88.121:7004 192.168.88.121:7005 192.168.88.121:7006命令说明
选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点
之后跟着的其他参数则是这个集群实例的地址列表,3个master3个slave
redis-trib 会打印出一份预想中的配置给你看, 如果你觉得没问题的话, 就可以输入 ==yes==, redis-trib 就会将这份配置应用到集群当中,让各个节点开始互相通讯,最后可以得到如下信息:
[root@hadoop-node01 redis-cluster]# ./redis-trib.rb create --replicas 1 192.168.88.121:7001
192.168.88.121:7002 192.168.88.121:7003 192.168.88.121:7004 192.168.88.121:7005 192.168>>> Creating cluster
Invalid IP or Port (given as 192.168) - use IP:Port format
[root@hadoop-node01 redis-cluster]# ./redis-trib.rb create --replicas 1 192.168.88.121:7001
192.168.88.121:7002 192.168.88.121:7003 192.168.88.121:7004 192.168.88.121:7005 192.168.88.121:7006>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.88.121:7001
192.168.88.121:7002
192.168.88.121:7003
Adding replica 192.168.88.121:7005 to 192.168.88.121:7001
Adding replica 192.168.88.121:7006 to 192.168.88.121:7002
Adding replica 192.168.88.121:7004 to 192.168.88.121:7003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: f97aa0b15e5a7f51c69f26543e7b785d52479afe 192.168.88.121:7001
slots:0-5460 (5461 slots) master
M: 8e4a66caac1f738e9d951d212a5ba2a00e675acd 192.168.88.121:7002
slots:5461-10922 (5462 slots) master
M: 1528779486cb926b11cb996c5682c6b749d26bc1 192.168.88.121:7003
slots:10923-16383 (5461 slots) master
S: ea08ca738d621c5161a0ecfe838ed8fd89f5c0c5 192.168.88.121:7004
replicates 8e4a66caac1f738e9d951d212a5ba2a00e675acd
S: 0ac234a10f28e24173ffc4e686073fa7710dd264 192.168.88.121:7005
replicates 1528779486cb926b11cb996c5682c6b749d26bc1
S: d560e0e3da9a715fb4aae5910cf5533cec2f815f 192.168.88.121:7006
replicates f97aa0b15e5a7f51c69f26543e7b785d52479afe
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join......
>>> Performing Cluster Check (using node 192.168.88.121:7001)
M: f97aa0b15e5a7f51c69f26543e7b785d52479afe 192.168.88.121:7001
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: d560e0e3da9a715fb4aae5910cf5533cec2f815f 192.168.88.121:7006
slots: (0 slots) slave
replicates f97aa0b15e5a7f51c69f26543e7b785d52479afe
M: 1528779486cb926b11cb996c5682c6b749d26bc1 192.168.88.121:7003
slots:10923-16383 (5461 slots) master
1 additional replica(s)
M: 8e4a66caac1f738e9d951d212a5ba2a00e675acd 192.168.88.121:7002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 0ac234a10f28e24173ffc4e686073fa7710dd264 192.168.88.121:7005
slots: (0 slots) slave
replicates 1528779486cb926b11cb996c5682c6b749d26bc1
S: ea08ca738d621c5161a0ecfe838ed8fd89f5c0c5 192.168.88.121:7004
slots: (0 slots) slave
replicates 8e4a66caac1f738e9d951d212a5ba2a00e675acd
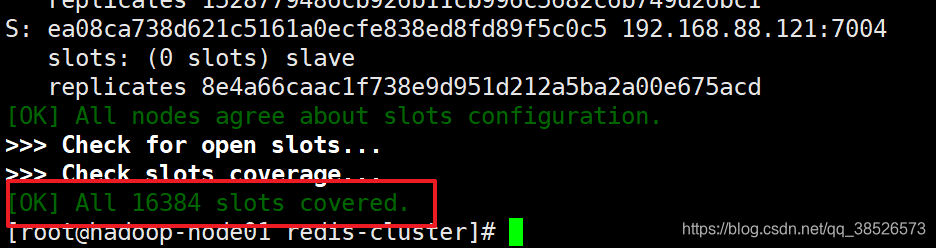
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.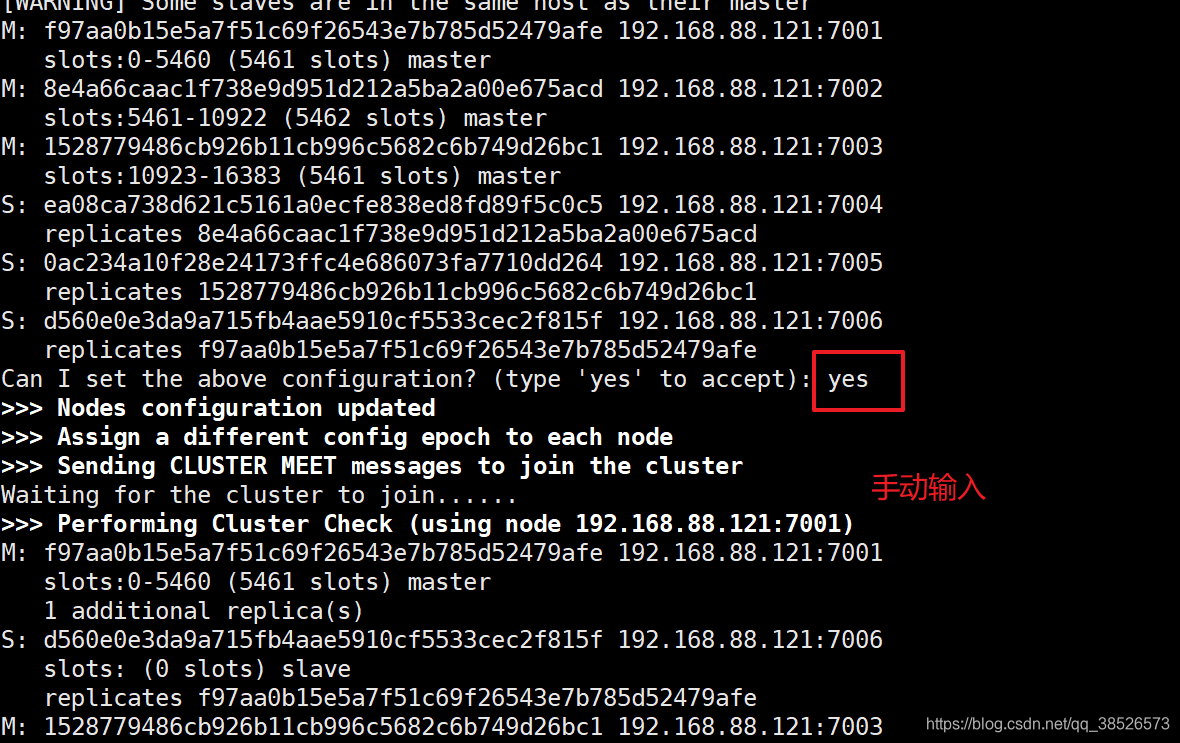
这表示集群中的 16384 个槽都有至少一个主节点在处理, 集群运作正常。
4.测试集群
登录命令
redis7001/src/redis-cli -h 192.168.88.121 -p 7001 -c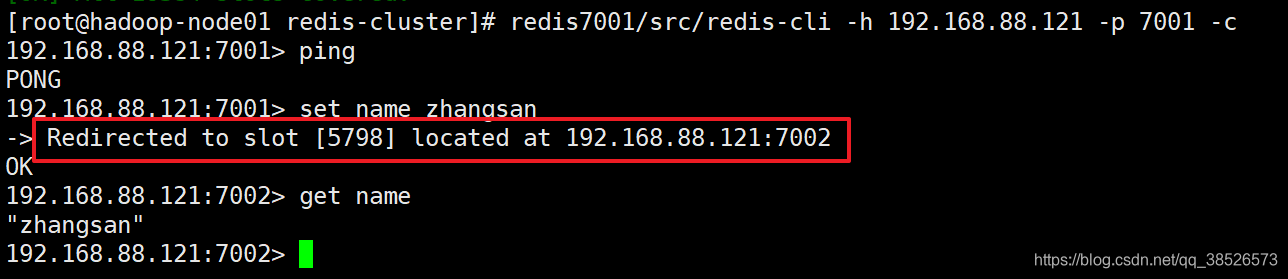 添加一个key被分配到7002节点上,注意连接的端口变为了7002。
添加一个key被分配到7002节点上,注意连接的端口变为了7002。
5.查看集群环境
| 命令 | 说明 |
|---|---|
| cluster info | 打印集群的信息 |
| cluster nodes | 列出集群当前已知的所有节点( node),以及这些节点的相关信息。节点 |
| cluster meet <ip> <port> | 将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。 |
| cluster forget
|
从集群中移除 node_id 指定的节点。 |
| cluster replicate
|
将当前节点设置为 node_id 指定的节点的从节点。 |
| cluster saveconfig | 将节点的配置文件保存到硬盘里面。槽(slot) |
| cluster addslots <slot> [slot ...] |
将一个或多个槽( slot)指派( assign)给当前节点。 |
| cluster delslots <slot> [slot ...] |
移除一个或多个槽对当前节点的指派。 |
| cluster flushslots | 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。 |
| cluster setslot <slot> node <node_id> |
将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。 |
| cluster setslot <slot> migrating <node_id> |
将本节点的槽 slot 迁移到 node_id 指定的节点中。 |
| cluster setslot <slot> importing <node_id> |
从 node_id 指定的节点中导入槽 slot 到本节点。 |
| cluster setslot <slot> stable | 取消对槽 slot 的导入( import)或者迁移( migrate)。键 |
| cluster keyslot <key> | 计算键 key 应该被放置在哪个槽上。 |
| cluster countkeysinslot <slot> |
返回槽 slot 目前包含的键值对数量。 |
| cluster getkeysinslot <slot> <count> |
返回 count 个 slot 槽中的键 |
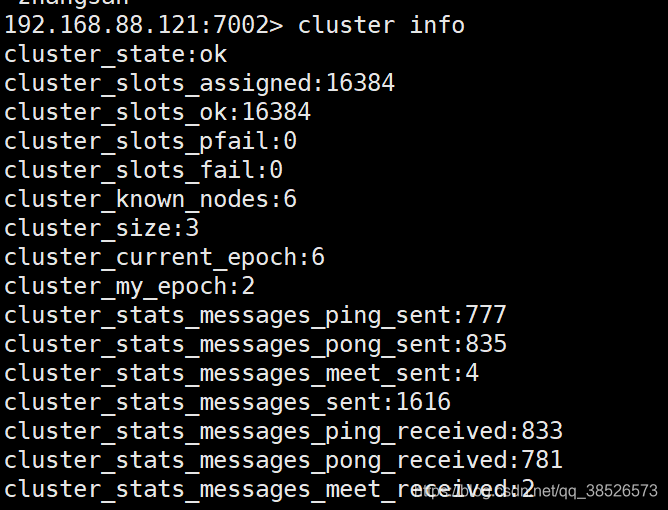
cluster info命令
cluster nodes

6.增加节点
添加新的节点的基本过程就是添加一个空的节点然后移动一些数据给它,有两种情况,添加一个主节点和添加一个从节点(添加从节点时需要将这个新的节点设置为集群中某个节点的复制)
添加一个新的实例
启动新的7007节点,使用的配置文件和以前的一样,只要把端口号改一下即可,过程如下:
在终端打开一个新的标签页.
进入redis-cluster 目录.
复制并进入redis7007文件夹.
和其他节点一样,创建redis.conf文件,需要将端口号改成7007.
最后启动节点 ../redis-server ./redis.conf
如果正常的话,节点会正确的启动.

1.添加主节点
./redis-trib.rb add-node 192.168.88.121:7007 192.168.88.121:7001第一个参数是新节点的地址,第二个参数是任意一个已经存在的节点的IP和端口
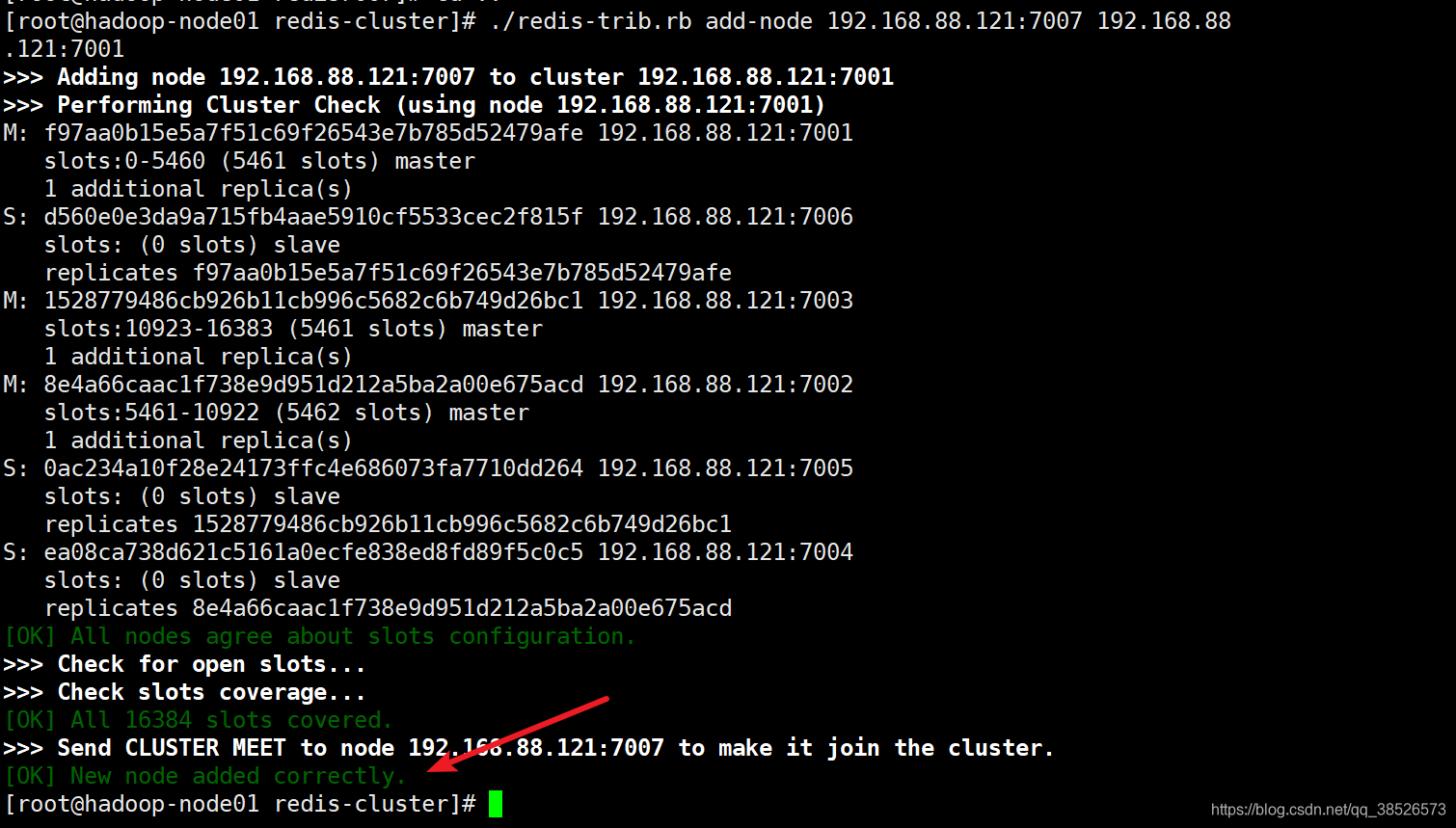

新节点现在已经连接上了集群, 成为集群的一份子, 并且可以对客户端的命令请求进行转向了, 但是和其他主节点相比, 新节点还有两点区别:
- 新节点没有包含任何数据, 因为它没有包含任何哈希槽.
- 尽管新节点没有包含任何哈希槽, 但它仍然是一个主节点, 所以在集群需要将某个从节点升级为新的主节点时, 这个新节点不会被选中。
接下来, 只要使用 redis-trib 程序, 将集群中的某些哈希桶移动到新节点里面, 新节点就会成为真正的主节点了。
重新分配slot
./redis-trib.rb reshard 192.168.88.121:7001只需要指定集群中其中一个节点的地址, redis-trib 就会自动找到集群中的其他节点
 7007节点被分类slot,成了真正意义上的主节点
7007节点被分类slot,成了真正意义上的主节点
2.添加从节点
添加的从节点被随机的配置任意的主节点
./redis-trib.rb add-node --slave 192.168.88.121:7008 192.168.88.121:7001将从节点添加给指定的主节点
./redis-trib.rb add-node --slave --master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e 127.0.0.1:7006 127.0.0.1:70007.删除节点
使用del-node命令移除节点。
./redis-trib.rb del-node 192.168.2.11:7007 <node-id>第一个参数:任意集群中现有的地址192.168.88.121:7001
第二个参数:你想移除的节点id ab853f5e95f1e32e0ee40543a9687d60fc3bd941 (该id可以在想要移除的节点nodes.conf文件中找到)
关闭redis
redis7001/redis-cli -p 7001 shutdown
./redis-cli shutdown
pkill -9 redis-server –关闭所有的redis服务
~好了redis的集群操作就介绍到此,
更多内容可以查看官网手册:http://www.redis.cn/documentation.html