链接分析
1、不同的搜索关键字 的搜索链接分析:
搜索python工程师:https://sou.zhaopin.com/?jl=538&kw=python工程师&kt=3
搜索java工程师:https://sou.zhaopin.com/?jl=538&kw=java工程师&kt=3
对比结果:两个链接只有 kw= 后的内容有所不同。kw 后的内容就是搜索的关键词,你就可以根据查询内容构造自己的链接。
2、不同页面的搜索链接分析
中间页的链接:https://sou.zhaopin.com/?p=2&jl=538&kw=java工程师&kt=3
最后一页的链接:https://sou.zhaopin.com/?p=12&jl=538&kw=java工程师&kt=3
对比结果:不同页面的链接,只有第一页没有 p= 参数。其余页面只是 p= 后的参数不同。
页面的渲染
我们所看到的网页是浏览器将 HTML、CSS、JavaScript 代码加工后呈现到屏幕上的。因此,为了获得完整的内容,爬虫也需要重复这一过程。
在默认情况下,爬虫获取到的是未经渲染的 HTML、JavaScript、CSS 代码。
渲染页面
在获取的结果上调用reader函数,渲染页面。
from requests_html import HTMLSession session=HTMLSession() firstPage=session.get('https://sou.zhaopin.com/?jl=538&kw=python工程师&kt=3') firstPage.html.render() print(firstPage.html.text)
数据提取
查看网页源代码,写正则表达式
比如薪资的源代码是:<p class="contentpile__content__wrapper__item__info__box__job__saray">10K-15K</p>
其正则表达式可以写成:<p.*>(\d+)K-(\d+)K</p>
再比如下一页的源代码是:<button disabled="disabled" class="btn soupager__btn soupager__btn--disable">下一页</button>
其正则表达式可以写成:<button.* disabled="disabled".*>下一页</button>,你可以用这个正则来判断是不是最后一页。
from requests_html import HTMLSession import re session=HTMLSession() first_page=session.get('https://sou.zhaopin.com/?jl=489&kw=%E7%88%AC%E8%99%AB%E5%B7%A5%E7%A8%8B%E5%B8%88&kt=3') first_page.html.render(sleep=10) #薪资水平源代码正则表达式 salary_element='<p.*>(\d+)K-(\d+)K</p>' salary=re.findall(salary_element,first_page.html.html) #最后一页 下一页 按钮正则表达式 disabled_button_element='<button.* disabled="disabled".*>下一页</button>' disabled_button=re.findall(disabled_button_element,first_page.html.html)
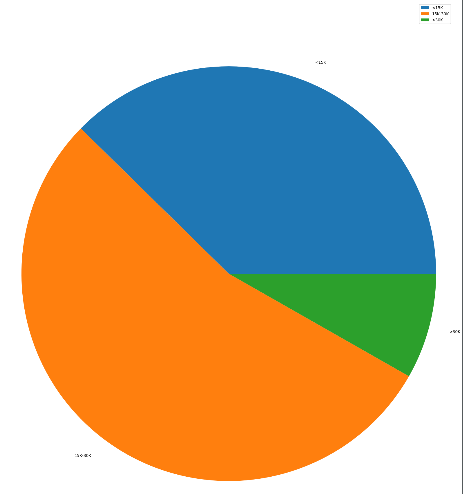
成功匹配薪资水平和 下一页 按钮后,尝试提取所有 python工程师的薪资水平 并利用 matplotlib 绘图展示。
完整代码如下:
from requests_html import HTMLSession import re from matplotlib import pyplot as plt salary_element='<p.*>(\d+)K-(\d+)K</p>' salary=[] disabled_button_element='<button.* disabled="disabled".*>下一页</button>' #disabled_button_element='<button class="btn soupager__btn soupager__btn--disable" disabled="disabled">下一页</button>' disabled_button=None p=1 while not disabled_button: print('正在爬取第'+str(p)+'页') url='https://sou.zhaopin.com/?p='+str(p)+'&jl=530&kw=python工程师&kt=3' session=HTMLSession() page=session.get(url) page.html.render(sleep=3) # 提取出薪资,保存为形如 [[10,20], [15,20], [12, 15]] 的数组 salary+=re.findall(salary_element,page.html.html) # 判断页面中下一页按钮还能不能点击 disabled_button=re.findall(disabled_button_element,page.html.html) p=p+1 session.close() #求出每家公司的平均工资 salary=[(int(s[0])+int(s[1]))/2 for s in salary] low_salary,middle_salary,high_salary=[0,0,0] for s in salary: if s<=15: low_salary+=1 elif s>15 and s<=30: middle_salary+=1 else: high_salary+=1 # 调节图形大小,宽,高 plt.figure(figsize=(16,19)) labels=[u'<15K',u'15K-30K',u'>30K'] data=[low_salary,middle_salary,high_salary] plt.pie(data,labels=labels) plt.axis('equal') plt.legend() plt.show()
数据展示