今天尝试使用pycharm+beautifulsoup进行爬虫测试。我理解的主要分成了自己写的HTML和百度上的网页两种吧。第一种,读自己写的网页(直接上代码):
(主要参考博客:https://blog.csdn.net/Ka_Ka314/article/details/80999803)
from bs4 import BeautifulSoup
file = open('aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser")
# 缩进格式
print(bs.prettify())
# 获取title标签的所有内容
print(bs.title)
# 获取title标签的名称
print(bs.title.name)
# 获取title标签的文本内容
print(bs.title.string)
# 获取head标签的所有内容
print(bs.head)
# 获取第一个div标签中的所有内容
print(bs.div)
# 获取第一个div标签的id的值
print(bs.div["id"])
# 获取第一个a标签中的所有内容
print(bs.a)
# 获取所有的a标签中的所有内容
print(bs.find_all("a"))
# 获取id="u1"
print(bs.find(id="u1"))
# 获取所有的a标签,并遍历打印a标签中的href的值
for item in bs.find_all("a"):
print(item.get("href"))
# 获取所有的a标签,并遍历打印a标签的文本值
for item in bs.find_all("a"):
print(item.get_text())
HTML代码:
<!DOCTYPE html>
<!--STATUS OK-->
<html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="content-type"/>
<meta content="IE=Edge" http-equiv="X-UA-Compatible"/>
<meta content="always" name="referrer"/>
<link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css"/>
<title>
百度一下,你就知道
</title>
</head>
<body link="#0000cc">
<div id="wrapper">
<div id="head">
<div class="head_wrapper">
<div id="u1">
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">
新闻
</a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">
hao123
</a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">
地图
</a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">
视频
</a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">
贴吧
</a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">
更多产品
</a>
</div>
</div>
</div>
</div>
</body>
</html>
项目目录:

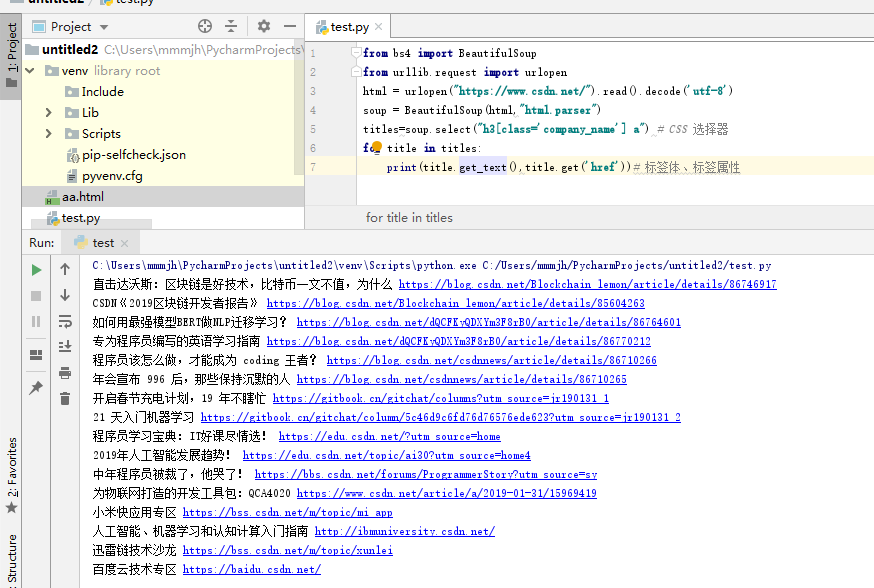
第二种是爬取在线网页内容,使用URL解析,这里我使用时出现了问题,就是URLopen。因为没有找到python27和python36区别,所以这里直接上结果(我用的python36),下载urllib.request的包。网上个别教程直接使用urllib,这里我把urllib3、5进行了下载,会报一个错误,显示连接网页超时。下下载这个urllib没问题