上篇讲的是PCA基于矩阵操作方法的实现,本文讲的是基于梯度上升法实现的PCA。
PCA原理
假设现有样本的分布如下图所示。

样本有两个特征,也就是二维的数据:特征1和特征2,如果对样本进行降维,首先可以考虑基于坐标轴进行降维。会有如下两种方式:舍弃特征1,只保留特征2,或者舍弃特征2,只保留特征1。做这样的处理就会变得这样,如下图:

昨晚上述处理,会发现数据就变成一维的了(其他的特征被舍弃了),单纯从降维的效果来看,似乎右图的效果会好些,因为样本之间的间距比较大,样本之间有更好的可区分度。但是这种处理方式只是比较随意的方式,不一定就是最好的方案。从这图1的数据来看,将样本映射到这样的一根斜线上效果会更好,如下图:

因此,降维的目标就是找到样本间距最大的轴。也就是样本映射到这个轴之后,使得样本间距最大。
在信号处理中认为信号具有较大的方差,****噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。因此我们认为,最好的kk维特征是将nn维样本点变换为kk维后,每一维上的样本方差都尽可能的大。
在数学上,样本间距离反映了样本的离散程度,而方差可以很好的表示这种程度,因此我们定义样本间距离——方差。
主成分分析PCA
PCA算法步骤大致如下:
- 将样本的均值归零(demean)
- 求一个轴的方向w,使得映射后的方差值最大
均值归零(demean)
原有样本分布:

而,归零之后:

归零的作用是使得样本的均值为0,这样就可以在计算方差时,将原有公式中的均值置为0,即获得图中均值归零后的方差表达式。
注意这里的
表示的是映射之后样本的数据,也就是降维之后的数据。
映射轴和方差
映射的轴可以视为一个向量, ,n即为样本的特征数。
方差公式:
我们的目标就是使得这个公式得到的方差值最大。
如果将样本的数据映射到坐标系中,那么每个样本就可以看做是个向量,而样本的均值也可以看做是一个向量。这样我们的方差公式可以变为:
也就是求每个向量和均值向量之间距离的平方和再除以向量个数,得到的结果本质上也是方差。由于前一步中的均值归零操作,使得样本在各个维度的均值都是0,那么进一步化简公式为:
假设在数据有两个维度,则可以得到一个二维平面。
这里其实不应使用取模的符号,因为
样本有n个属性,可以理解为一个n个元素的向量,w也是有n个元素的向量,两个向量相乘的结果是一个实数。而放到矩阵来说,Xi是一个1 * n的矩阵,w理解为一个n * 1的矩阵,相乘之后也是一个实数,因此,最佳的表达式应该是:
展开来看:
合并一下w各个值:
而得到这个算式最大值的过程可以采用梯度上升法求解。
梯度上升法
回忆梯度下降法,通过求函数在一个点的导数值,得到函数在该点的斜率,之后使用减去斜率与学习率乘积的方式下降,逐渐靠近极小值点。
梯度上升法与之类似,上升不过就是将减法变为加法。第一步还是对方差函数f在每个特征维度求导。

对括号中的式子化简:

提出每个式子的Xi * w:

此时得到一个向量和X样本矩阵,由于向量w和X中每个样本都有相乘的操作,因此,可以将其写为
,左侧算式可以理解为
需要和每个样本的第i列做一次乘法,因此,可以认为最终是要乘以整个样本X的矩阵。因此得到最右侧的两个式子,下面的算式是为了方便运算而对上面的式子进行转换得到的。
代码实现
单个主成分分析
- 先模拟一个数据集
import numpy as np
import matplotlib.pyplot as plt
X = np.empty((100, 2))
X[:, 0] = np.random.uniform(0., 100., size=100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 10, size=100)
plt.scatter(X[:, 0], X[:, 1])
plt.show()
该数据集有两个属性,打印初始图像:
2. 接下来对数据进行主成分分析,第一步是均值归零,定义相应的函数:
'''均值归零'''
def demean(X):
# axis=0即按列计算均值,及每个属性的均值,1则是计算行的均值
#注意要明白为什么使用列,一列就是一个特征维度,生成数据的时候是俩列
return (X - np.mean(X, axis=0))
X_demean = demean(X)
plt.scatter(X_demean[:, 0], X_demean[:, 1])
plt.show()
绘出归零后的图:
从分布上看貌似没啥区别,但看看坐标就会发现还是有所不同
- 对方差函数和其导数函数的定义
(1) 方差函数:
(2) 方差函数导数:
'''方差函数'''
def f(w, X):
return np.sum((X.dot(w)**2)) / len(X)
'''方差函数导数'''
def df_math(w, X):
return X.T.dot(X.dot(w)) * 2. / len(X)
'''将向量化简为单位向量'''
def direction(w):
return w / np.linalg.norm(w)
'''梯度上升法'''
def gradient_ascent(w, X, eta, n_iter=1e4, epsilon=0.0001):
'''
梯度上升法
:param w:
:param X:
:param eta: ---->学习率
:param n_iter: ---------->迭代次数
:param epsilon:---------->精度
:return:
'''
#先化简w为单位向量,方便运算
w = direction(w)
i_iter = 0
while i_iter < n_iter:
gradient = df_math(w, X)
last_w = w
w += gradient * eta
#每次更新后将w化简为单位向量
w = direction(w)
if abs(f(w, X) - f(last_w, X)) < epsilon:
break
i_iter += 1
return w
和线性回归梯度下降寻找极小值点类似,只不过这次的方向是上升。而且有需要注意限定循环次数,避免学习率过大造成陷入无限循环中。我们来测试下数据降维的结果:
w_init = np.random.random(X_demean.shape[1])#随机初始化w
eta = 0.01#设置学习率
w = gradient_ascent(w_init, X_demean, eta)#调用梯度上升法
print(w)
plt.scatter(X_demean[:, 0], X_demean[:, 1])
plt.plot([0, w[0] * 30], [0, w[1] * 30], color='r')
plt.show()
w的值为:
[0.77041573 0.63754185]
注意:
线性回归中,通常将特征系数θ的值设为全部为0的向量(也就是w设为0向量),但在主成分分析中w的初始值不能为0!!
得到映射向量如图中红线:
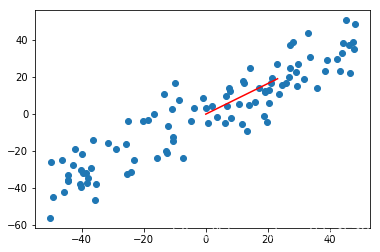
多个主成分分析
问:对于上面的二维数据,如果想求第二个成分,该怎么做?
答:需要先将数据集在第一个主成分上的分量去掉,然后在没有第一个主成分的基础上再寻找第二个主成分。

由之前的推导所知,蓝色部分的模长是Xi向量和w向量的乘积,又因为w是单位向量,向量的模长乘以方向上的单位向量就可以得到这个向量,去掉Xi在w方向的分量得到新的数据
。
求第二主成分就是在新的数据Xi’上寻找第一主成分。以此类推,之后的主成分求法也是这个套路。
'''均值归零'''
def demean(X):
# axis=0即按列计算均值,及每个属性的均值,1则是计算行的均值
return (X - np.mean(X, axis=0))
'''方差函数'''
def f(w, X):
return np.sum((X.dot(w)**2)) / len(X)
'''方差函数导数'''
def df_ascent(w, X):
return X.T.dot(X.dot(w)) / 2 * len(X)
'''将向量化简为单位向量'''
def direction(w):
return w / np.linalg.norm(w)
'''寻找第一主成分'''
def first_component(w_init, X, eta, n_iter=1e4, epsilon=0.0001):
w = direction(w_init)
i_iter = 0
while i_iter < n_iter:
last_w = w
gradient = df_ascent(w, X)
w += eta * gradient
w = direction(w)
if abs(f(w, X) - f(last_w, X)) < epsilon:
break
i_iter += 1
return w
'''取前n个主成分'''
def first_n_component(n, X, eta, n_iter=1e4, epsilon=0.0001):
'''先对数据均值归零'''
X = demean(X)
#res记录每个主成分
res = []
#进行n次
for i in range(n):
#每次初始化w向量,注意不能是0向量
w = np.random.random(X.shape[1])
#寻找当前数据的第一主成分并记录到res
w = first_component(w, X, eta)
res.append(w)
#每次减去数据在主成分方向的分量获得新数据
X = X - X.dot(w).reshape(-1, 1) * w
return res
代码中的前5个函数和第一主成分分析中的一样,注意最后一个函数。每次求当前数据的第一主成分,并减去数据在第一主成分上的分量获得的新数据继续求第一主成分,知道完成n次为止。
去除数据在第一主成分的分量,如刚才的算式推导的,对于每个样本
减去主成分的过程可以写为:
X[i]是第i个样本,可以看作是1 * n的向量,w是一个1 * n的向量,通过dot()方法可以得到一个常数,即为X[i]在w方向上的模长,模长再乘以w即为在w方向上的分量。
对于一个含有m个样本的数据集X,可以写成for循环:
for i in range(len(X)):
X_new[i] = X[i] - X[i].dot(w) * w
for循环方便理解但更好的方式是直接使用矩阵乘法的方式解决,上面的for循环等价于:
X_new = X - X.dot(w).reshape(-1, 1) * w
X是m * n的矩阵,w是n * 1的矩阵,二者dot()之后得到m * 1的矩阵,这里需要使用reshape(-1, 1)使得X和w相乘之后的矩阵真正是一个m * 1的矩阵,之后再乘以w,得到的m * n的矩阵即为每个样本每个维度在w上的分量。再用原始数据X减去即可。
现在,检验下第一次降维后的效果:
'''生成数据'''
X = np.empty((100, 2))
X[:, 0] = np.random.uniform(0., 100., size=100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 10, size=100)
'''均值归零'''
X_demean = demean(X)
'''获得第一主成分'''
w_init = np.random.random(X_demean.shape[1])
eta = 0.01
w = first_component(w_init, X_demean, eta)
print(w)
'''画出第一主成分所在向量'''
plt.scatter(X_demean[:, 0], X_demean[:, 1])
plt.plot([0, w[0] * 30], [0, w[1] * 30], color='r')
plt.show()
'''X减去X在第一主成分上的分量'''
X2 = X_demean - X_demean.dot(w).reshape(-1, 1) * w
plt.scatter(X2[:, 0], X2[:, 1])
plt.show()
这里将 dot的结果reshape了一下,之所以这么做是因为w的shape是 ,则 的结果就变成了(100,),再和w点乘是会报错的。当然更准确的做法是将w也reshape一下,比如:
X2 = X_demean - X_demean.dot(w).reshape(-1, 1) * (w.reshape(1,-1))
结果如下:
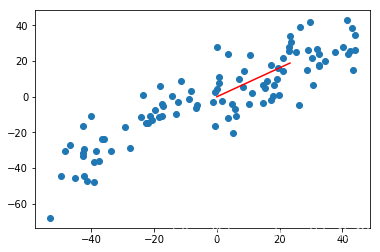
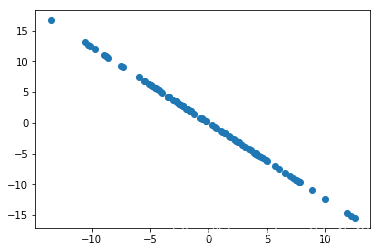
下面在新的数据上获取第二主成分:
'''获取第二主成分'''
w2_init = np.random.random(X2.shape[1])
w2 = first_component(w2_init, X2, eta)
plt.scatter(X2[:, 0], X2[:, 1])
plt.plot([0, w2[0] * 30], [0, w2[1] * 30], color='r')
plt.show()
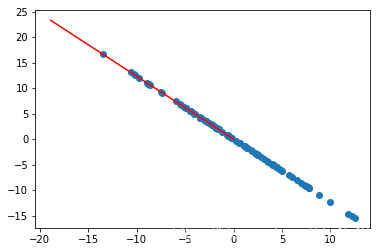
可以看到,俩各分量上的向量在2张图中的红线的走向近乎垂直,可以实现下,俩个向量垂直是否为0:
X = np.empty((100, 2))
X[:, 0] = np.random.uniform(0., 100., size=100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 10, size=100)
eta = 0.01
res = first_n_component(2, X, eta)
print(res)
print(res[0].dot(res[1]))
调用之前定义的first_n_component函数(也可以直接 $),记录前后两次的w,打印res和相乘的结果:
[array([0.79086614, 0.61198917]), array([-0.61198917, 0.79086614])]
-5.551115123125783e-17
返回了俩个数组,也就是w的值以及w之间点乘的结果, ,近乎为0,可以认为俩者垂直。
主成分分析和线性回归的区别
看起来,PCA和线性回归有点类似,都是求这么一条线,求w值,但还是有所不同,如下图:

这张图给出的是样本映射到方差最大的轴上的过程。很像线性回归中找一条拟合各个样本点的直线的图像。但是注意,PCA坐标轴是各个特征,映射的方向是垂直于方差最大的轴而非特征所在的坐标轴,且任务是使得样本间距尽可能大。。
而线性回归呢?二维的线性回归,横轴是特征,纵轴是输出标记。样本是垂直与特征所在的坐标轴,测量的是实际值和预测值的差距,我们的任务是使得这个距离尽可能的小。

PCA之高维数据降维与恢复
通过PCA,我们可以对高维数据降维。比如说,将个m维数据降到k维(k<m)。也就是说,原始数据样本X是一个m×n的矩阵,我们筛选出k个主成分向量,形成一个k × n的矩阵。通俗的来讲,通过上诉过程,我们每找到一个坐标维度
,都有一个与之对应的映射数据。写成矩阵形式如下:

类似于线性回归中的做法,使用线性代数将俩个矩阵相乘,得到
矩阵,原本的数据
就降为k,即实现了降维。公式为:
举个例子,数据
是
大小,即特征维度是3,数据量有100——>
,我们选择2个主成分分量,即
,则
对应
。应用
后生成的
的矩阵——>
,这样就实现了降维。那么我们想,同样通过这个矩阵,低维数据通过与主成分向量w相乘是否能恢复成高维数据?
先这么算:
是
,
是
,似乎
刚好就是
的矩阵。低维数据映射回高维数据的公式:
下面试试:
基于上述代码,做简单处理:
- PCA处理:
- 恢复数据:
W = np.vstack((w,w2))#合并成w_k
X_k = X.dot(W.T)#得到处理后的数据
X_inver = X_k.dot(W)#再从处理后的数据恢复原始数据
plt.scatter(X[:, 0], X[:, 1], color='b', alpha=0.5)#原始数据
plt.scatter(X_inver[:, 0], X_inver[:, 1], color='r', alpha=0.5)#PCA恢复的数据
plt.show()
是这么个图:
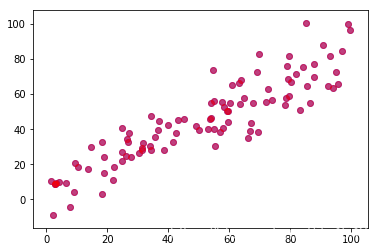
当然也可以生成个类,重新弄:
import numpy as np
import matplotlib.pyplot as plt
class PCA:
def __init__(self, n_component):
assert n_component >= 1, 'n_component is invalidate'
self.n_component = n_component
self.components_ = None
def __repr__(self):
return 'PCA(n_component=%d)' % self.n_component
def fit(self,X, eta, n_iter=1e4, epsilon=0.0001):
'''
主成分分析
:param X:
:param eta:
:param n_iter:
:param epsilon:
:return:
'''
assert X.shape[1] >= self.n_component, 'X is invalidate'
'''均值归零'''
def demean(X):
return X - np.mean(X, axis=0)
'''方差函数'''
def f(w, X):
return np.sum(X.dot(w)**2) / len(X)
'''方差函数导数'''
def df_ascent(w, X):
return X.T.dot(X.dot(w)) * 2 / len(X)
'''将向量化简为单位向量'''
def direction(w):
return w / np.linalg.norm(w)
'''寻找第一主成分'''
def first_component(w, X, eta, n_iter=1e4, epsilon=0.0001):
i_iter = 0
while i_iter < n_iter:
last_w = w
gradient = df_ascent(w, X)
w += eta * gradient
w = direction(w)
if abs(f(w, X) - f(last_w, X)) < epsilon:
break
i_iter += 1
return w
self.components_ = np.empty(shape=(self.n_component, X.shape[1]))
X = demean(X)
for i in range(self.n_component):
w = np.random.random(X.shape[1])
w = first_component(w, X, eta, n_iter, epsilon)
X = X - (X.dot(w)).reshape(-1, 1) * w
self.components_[i, :] = w
return self
def transform(self, X):
'''
将X映射到各个主成分中
:param X:
:return:
'''
assert X.shape[1] == self.components_.shape[1]
return X.dot(self.components_.T)
def inverse_transform(self, X):
'''
将低维数据转回高维
:param X:
:return:
'''
assert X.shape[1] == self.components_.shape[0]
return X.dot(self.components_)
定义一个PCA类,有两个属性n_comnponent记录主成分个数,components_记录各个主成分向量。
- fit()函数实际就是通过梯度上升法选去n_component个主成分
- 通过transform()函数从高维向低维映射
- inverse_transform()函数实现了低维映射回高维
'''测试数据'''
X = np.empty((100, 2))
X[:, 0] = np.random.uniform(0., 100., size=100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 10, size=100)
eta = 0.01
pca = PCA(2)
pca.fit(X, eta)
X_new = pca.transform(X)
print(pca.components_)
print(X_new.shape)
X_inverse = pca.inverse_transform(X_new)
plt.scatter(X[:, 0], X[:, 1], color='g', alpha=0.5)
plt.scatter(X_inverse[:, 0], X_inverse[:, 1], color='r', alpha=0.5)
plt.show()
得到主成分向量和降维后的数据集的大小
[[ 0.76809846 0.64033176]
[-0.64033176 0.76809846]]
(100, 2)
绘制结果:
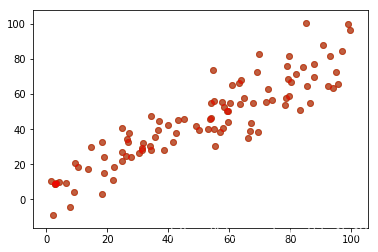
俩者一样,这里原始数据是绿色,PCA恢复的数据是红色,发现并不是完全重合的,也就是说PCA会有数据失真,这还仅仅是相同纬度,降维更加会丢失数据,无法像FFT那样完美恢复数据。
能力有限,仅做参考!
结束语:
通过特征分解和梯度上升法,虽然求解方式不一样,但是我们可以知道的是,通过PCA,我们可以将n维特征换算到k(k<=n)维中,通过线性代数的思维,可以这么认为我们将数据从原始坐标系换算到了一个新的坐标系中,从n维——>n维,维度不变,但是坐标系不一样了。当我们要实行降维时,可以选取其中前k个更重要的维度或者说轴。
参考文章:
主成分分析(PCA)原理详解
从零开始实现主成分分析(PCA)算法
你见过最全的主成分分析PAC与梯度上升法总结