本文主要对Java集合类进行详情分析
1. Java集合类基本概念
Java容器类类库的用途是"保存对象",并将其划分为两个不同的概念:
1) Collection
一组"对立"的元素,通常这些元素都服从某种规则
1.1) List必须保持元素特定的顺序
1.2) Set不能有重复元素
1.3) Queue保持一个队列(先进先出)的顺序
2) Map
一组成对的"键值对"对象
Collection和Map的区别在于容器中每个位置保存的元素个数:
1) Collection 每个位置只能保存一个元素(对象)
2) Map保存的是"键值对",就像一个小型数据库。我们可以通过"键"找到该键对应的"值",也可分开获取
2. Java集合类架构层次关系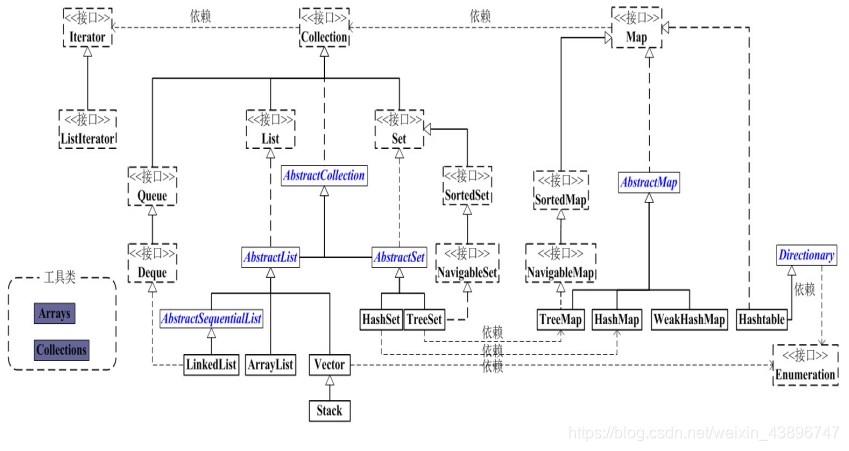
1. Interface Iterable 迭代器接口
这是Collection类的父接口。实现这个Iterable接口的对象允许使用foreach进行遍历,也就是说,所有的Collection集合对象都具有"foreach可遍历性"。
有一个方法: iterator()。它返回一个代表当前集合对象的泛型迭代器,用于之后的遍历操作,
*Object next():*返回迭代器刚越过的元素的引用,返回值是 Object,需要强制转换成自己需要的类型
*boolean hasNext():*判断容器内是否还有可供访问的元素
*void remove():*删除迭代器刚越过的元素
所以除了 map 系列的集合,我们都能通过迭代器来对集合中的元素进行遍历。
LinkedList<String> list = new LinkedList<>();
list.add("AAA");
list.add("BBB");
list.add("CCC");
Iterator<String> Iterator = list.Iterator();//使用迭代器遍历集合
while (Iterator.hasNext()) {
System.out.print(Iterator.next() + "\t");
}
结果:

1.1 Collection
Collection是一个接口,用以提供规范定义,不能被实例化使用
1. Set:
1.Set集合类似于一个罐子,"丢进"Set集合里的多个对象之间*没有明显的顺序*。
Set继承自Collection接口,*不能包含有重复元素*(记住,这是整个Set类层次的共有属性)
2.特点:1)没有明显的顺序、2)能包含有重复元素
3.注意两点: 1) 为Set集合里的元素的实现类实现一个有效的equals(Object)方法、
2) 对Set的构造函数,传入的Collection参数不能包含重复的元素
- 1.1 HashSet
1. HashSet是Set接口的典型实现,HashSet使用HASH算法来存储集合中的元素,
因此具有良好的存取和查找性能。
2. 当向HashSet集合中存入一个元素时,HashSet会调用该对象的 hashCode()
方法来得到该对象的hashCode值,然后根据该HashCode值决定该对象在HashSet中的存储位置。
3. 值得注意的是,HashSet集合判断两个元素相等的标准是两个对象通过equals()方法比较相等,
并且两个对象的hashCode()方法的返回值相等并且两个对象的hashCode()方法的返回值相等
-
1.1.1LinkedHashSet
1.LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但和HashSet不同的是,它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。
2.LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时(遍历)将有很好的性能(链表很适合进行遍历) -
1.2 SortedSet
此接口主要用于排序操作,即实现此接口的子类都属于排序的子类 -
1.2.1 TreeSet
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态,采用二叉树存储形式,并根据其元素的自然排序进行排序。 -
1.3 EnumSet
EnumSet是一个专门为枚举类设计的集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式、或隐式地指定。EnumSet的集合元素也是有序的,它们以枚举值在Enum类内的定义顺序来决定集合元素的顺序
2. List
List集合代表一个元素有序、可重复、可空的集合,集合中每个元素都有其对应的顺序索引。List集合允许加入重复元素,因为它可以通过索引来访问指定位置的集合元素。List集合默认按元素的添加顺序设置元素的索引
-
2.1 ArrayList
ArrayList是基于数组实现的List类,它封装了一个动态的增长的、允许再分配的Object[]数组。
1、ArrayList基于数组实现,是一个动态的数组队列。但是它和Java中的数组又不一样,
它的容量可以自动增长,类似于C语言中动态申请内存,动态增长内存!
2、ArrayList继承了AbstractList,实现了RandomAccess、Cloneable和Serializable接口!
3、集成了AbstractList,AbstractList又继承了AbstractCollection实现了List接口,它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能!
4、实现了RandomAccess接口,提供了随机访问功能,实际上就是通过下标序号进行快速访问。
5、实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
6、实现了Serializable接口,支持序列化,也就意味了ArrayList能够通过序列化传输。
-
2.2 Vector
Vector和ArrayList在用法上几乎完全相同,但由于Vector是一个古老的集合,所以Vector提供了一些方法名很长的方法,但随着JDK1.2以后,java提供了系统的集合框架,就将 Vector改为实现List接口,统一归入集合框架体系中.
与数组一样,它包含可以使用整数索引进行访问的组件。但是,Vector 的大小可以根据需要增大或缩小,以适应创建 Vector 后进行添加或移除项的操作。Vector 是同步的,可用于多线程。1、Vector 继承了AbstractList,实现了List;所以,它是一个队列,支持相关的添加、删除、修改、遍历等功能。 2、Vector实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在Vector中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。 3、Vector 实现了Cloneable接口,即实现clone()函数。它能被克隆。 4、Vector 实现Serializable接口,支持序列化。 -
2.3 LinkedList
LinkedList是基于链表实现的,从源码可以看出是一个双向链表。除了当做链表使用外,它也可以被当作堆栈、队列或双端队列进行操作。不是线程安全的,1、LinkedList继承AbstractSequentialList,AbstractSequentialList 实现了get(int index)、 set(int index, E element)、add(int index, E element) 和 remove(int index)这些函数。 这些接口都是随机访问List的。 2、 LinkedList 实现 List 接口,能对它进行队列操作。 3、 LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。 4、 LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。 5、 LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化, 能通过序列化去传输。
3. Map
Map用于保存具有"映射关系"的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value。key和value都可以是任何引用类型的数据。Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较结果总是返回false。
关于Map,我们要从代码复用的角度去理解,java是先实现了Map,然后通过包装了一个所有value都为null的Map就实现了Set集合
Map的这些实现类和子接口中key集的存储形式和Set集合完全相同(即key不能重复)
Map的这些实现类和子接口中value集的存储形式和List非常类似(即value可以重复、根据索引来查找)
- 3.1HashMap
和HashSet集合不能保证元素的顺序一样,HashMap也不能保证key-value对的顺序,也不是同步的,允许使用null键和null值。并且类似于HashSet判断两个key是否相等的标准也是: 两个key通过equals()方法比较返回true、同时两个key的hashCode值也必须相等。
HashMap存放元素是通过哈希算法将其中的元素散列的存放在各个“桶”之间。
注:HashMap除了非同步和可以使用null之外,其他的和HashTable大致相同。so ,后面就不在介绍HashTable了!
(1):HashMap是通过哈希表来存储一个key-value的键值对,每个key对应一个value,允许key和value为null!
(2):HashMap 的实例有两个参数影响其性能:初始容量 和加载因子。容量是哈希表中桶的数量,
初始容量只是哈希表在创建时的容量。HashMap的容量不足的时候,
可以自动扩容resize(),但是最大容量为MAXIMUM_CAPACITY==2^30!
(3):put和get都是分为null和非null进行判断!
(4):resize非常耗时的操作,因此,我们在用HashMap的时,最好能提前预估下HashMap中元素的个数,
这样有助于提高HashMap的性能。
(5):求hash值和索引值的方法,这两个方法便是HashMap设计的最为核心的部分,
二者结合能保证哈希表中的元素尽可能均匀地散列。
- 3.2TreeMap
TreeMap是一个有序的key-value集合,基于红黑树(Red-Black tree)的 NavigableMap实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator进行排序,具体取决于使用的构造方法。
在这里插入代码片
1、TreeMap是根据key进行排序的,它的排序和定位需要依赖比较器或覆写Comparable接口,也因此不需要key覆写hashCode方法和equals方法,就可以排除掉重复的key,而HashMap的key则需要通过覆写hashCode方法和equals方法来确保没有重复的key。
2、TreeMap的查询、插入、删除效率均没有HashMap高,一般只有要对key排序时才使用TreeMap。
3、TreeMap的key不能为null,而HashMap的key可以为null。
4、TreeMap不是同步的。如果多个线程同时访问一个映射,并且其中至少一个线程从结构上修改了该映射,则其必须 外部同步。
4.Queue
Queue用于模拟"队列"这种数据结构(先进先出 FIFO)。队列的头部保存着队列中存放时间最长的元素,队列的尾部保存着队列中存放时间最短的元素。新元素插入(offer)到队列的尾部,
访问元素(poll)操作会返回队列头部的元素,队列不允许随机访问队列中的元素。结合生活中常见的排队就会很好理解这个概念.
-
4.1PriorityQueue
PriorityQueue并不是一个比较标准的队列实现,PriorityQueue保存队列元素的顺序并不是按照加入队列的顺序,而是按照队列元素的大小进行重新排序,这点从它的类名也可以看出来。 -
4.2 Deque
Deque接口代表一个"双端队列",双端队列可以同时从两端来添加、删除元素,因此Deque的实现类既可以当成队列使用、也可以当成栈使用。(LinkedList也实现了此接口)
5. EnumMap
EnumMap是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。创建EnumMap时必须显式或隐式指定它对应的枚举类。EnumMap根据key的自然顺序(即枚举值在枚举类中的定义顺序)
本文参考:http://www.cnblogs.com/LittleHann/p/3690187.html
(在此声明) https://www.cnblogs.com/aflyun/p/6501040.html