简介
鉴权功能的位置处于基础服务的接入网关中。
1. 认证简介
本鉴权方案是在api层面上进行,通过使用Access Key/Secret Key加密的方法来对验证某个请求的调用者身份。
当接入网关接收到业务调用方的请求时,将使用相同的SK和同样的认证机制生成认证字符串,并与用户请求中包含的认证字符串进行比对。如果认证字符串相同,系统认为用户拥有指定的操作权限,并执行相关操作;如果认证字符串不同,系统将忽略该操作并返回错误码。
2. 认证过程
业务云侧请求
note left of 业务云侧: 预置分配的AK/SK 业务云侧->业务云侧: 生成认证字符串 业务云侧->网关: 携带认证字符串的业务请求 网关->网关: 鉴权 网关-->业务云侧: 鉴权失败,返回401 网关->基础服务: 鉴权成功,透传请求业务端侧请求
业务端侧->业务云侧: 获取携带认证字符串某个api的请求url note right of 业务云侧: 预置分配的AK/SK 业务云侧->业务云侧: 生成认证字符串 业务云侧->业务端侧: 返回携带认证字符串的url 业务端侧->网关: 使用业务云侧返回的url进行业务请求 网关->网关: 鉴权 网关-->业务云侧: 鉴权失败,返回401 网关->基础服务: 鉴权成功,透传请求
3. 认证字符串生成简介
3.1 概述
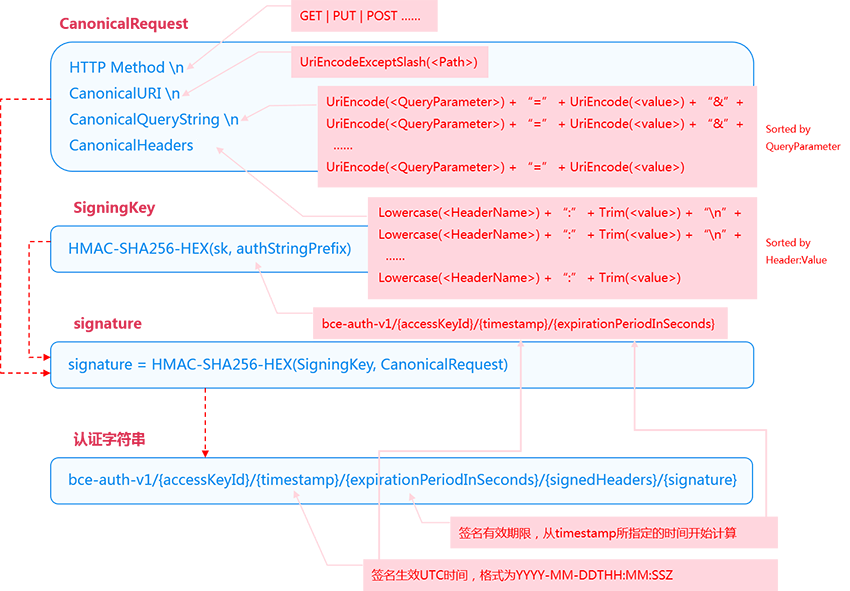
在生成认证字符串之前,首先需要生成Signature。为了生成Signature,用户需要首先构建CanonicalRequest并计算SigningKey。
注:
| 函数名 | 功能描述 |
|---|---|
| HMAC-SHA256-HEX() | 调用HMAC SHA256算法,根据开发者提供的密钥(key)和密文(message)输出密文摘要,并把结果转换为小写形式的十六进制字符串。 |
| Lowercase() | 将字符串全部变成小写。 |
| Trim() | 去掉字符串开头和结尾的空白字符。 |
| UriEncode() | RFC 3986规定,"URI非保留字符"包括以下字符:字母(A-Z,a-z)、数字(0-9)、连字号(-)、点号(.)、下划线(_)、波浪线(~),算法实现如下: 1. 将字符串转换成UTF-8编码的字节流 2. 保留所有“URI非保留字符”原样不变 3. 对其余字节做一次RFC 3986中规定的百分号编码(Percent-encoding),即一个“%”后面跟着两个表示该字节值的十六进制字母,字母一律采用大写形式。 |
| UriEncodeExceptSlash() | 与UriEncode() 类似,区别是斜杠(/)不做编码。一个简单的实现方式是先调用UriEncode(),然后把结果中所有的%2F都替换为/ |
3.2 生成canonicalRequest
CanonicalRequest = HTTP Method + "\n" + CanonicalURI + "\n" + CanonicalQueryString + "\n" + CanonicalHeaders
HTTP Method:全部大写。支持五种:- GET
- POST
- PUT
- DELETE
- HEAD
CanonicalURI:是对URL中的绝对路径进行编码后的结果。要求绝对路径必须以“/”开头,不以“/”开头的需要补充上,空路径为“/”,即CanonicalURI=UriEncodeExceptSlash(Path)。举例:
若URL为
https://bos.cn-n1.baidubce.com/example/测试,则其URL Path为/example/测试,将之规范化得到CanonicalURI = /example/%E6%B5%8B%E8%AF%95。CanonicalQueryString:对于URL中的Query String(Query String即URL中“?”后面的“key1 = valve1 & key2 = valve2 ”字符串)进行编码后的结果。编码方法为:
- 将Query String根据
&拆开成若干项,每一项是key=value或者只有key的形式。 - 对拆开后的每一项进行如下处理:
- 对于
key是authorization,直接忽略。 - 对于只有
key的项,转换为UriEncode(key) + "="的形式。 - 对于
key=value的项,转换为UriEncode(key) + "=" + UriEncode(value)的形式。这里value可以是空字符串。
- 对于
- 将上面转换后的所有字符串按照字典顺序排序。
- 将排序后的字符串按顺序用
&符号链接起来。
举例:
若URL为
https://bos.cn-n1.baidubce.com/example?text&text1=测试&text10=test,在这个例子中Query String是text&text1=测试&text10=test。- 根据
&拆开成text、text1=测试和text10=test三项。 - 对每一项进行处理:
text=>UriEncode("text") + "="=>text=text1=测试=>UriEncode("text1") + "=" + UriEncode("测试")=>text1=%E6%B5%8B%E8%AF%95text10=test=>UriEncode("text10") + "=" + UriEncode("test")=>text10=test
- 对
text=、text1=%E6%B5%8B%E8%AF%95和text10=test按照字典序进行排序。它们有共同前缀text,但是=的ASCII码比所有数字的ASCII码都要大,因此text1=%E6%B5%8B%E8%AF%95和text10=test排在text=的前面。同样,text10=test要排在text1=%E6%B5%8B%E8%AF%95之前。最终结果是text10=test、text1=%E6%B5%8B%E8%AF%95、text=。 - 把排序好的三项
text10=test、text1=%E6%B5%8B%E8%AF%95、text=用&连接起来得到text10=test&text1=%E6%B5%8B%E8%AF%95&text=。
- 将Query String根据
CanonicalHeaders:对HTTP请求中的Header部分进行选择性编码的结果。您可以自行决定哪些Header 需要编码。唯一要求是Host域必须被编码。大多数情况下,我们推荐您对以下Header进行编码,也可以使用其他header,此处不做限制:
- Host
- Content-Length
- Content-Type
- Content-MD5
对于每个要编码的Header进行如下处理:
- 将Header的名字变成全小写。
- 将Header的值去掉开头和结尾的空白字符。
- 经过上一步之后值为空字符串的Header忽略,其余的转换为
UriEncode(name) + ":" + UriEncode(value)的形式。 - 把上面转换后的所有字符串按照字典序进行排序。
- 将排序后的字符串按顺序用
\n符号连接起来得到最终的CanonicalQueryHeaders。
举例:
不使用signedHeaders默认值。若希望对
Date进行编码,则需要用到signedHeaders。要编码的Header如下:
Host: bj.bcebos.com Date: Mon, 27 Apr 2015 16:23:49 +0800 Content-Type: text/plain Content-Length: 8 Content-Md5: NFzcPqhviddjRNnSOGo4rw==首先把所有名字都改为小写。
host: bj.bcebos.com date: Mon, 27 Apr 2015 16:23:49 +0800 content-type: text/plain content-length: 8 content-md5: NFzcPqhviddjRNnSOGo4rw==将Header的值去掉开头和结尾的空白字符。
host:bj.bcebos.com date:Mon, 27 Apr 2015 16:23:49 +0800 content-type:text/plain content-length:8 content-md5:NFzcPqhviddjRNnSOGo4rw==做UriEncode。
host:bj.bcebos.com date:Mon%2C%2027%20Apr%202015%2016%3A23%3A49%20%2B0800 content-type:text%2Fplain content-length:8 content-md5:NFzcPqhviddjRNnSOGo4rw%3D%3D?把上面转换后的所有字符串按照字典序进行排序。
content-length:8 content-md5:NFzcPqhviddjRNnSOGo4rw%3D%3D? content-type:text%2Fplain date:Mon%2C%2027%20Apr%202015%2016%3A23%3A49%20%2B0800 host:bj.bcebos.com将排序后的字符串按顺序用
\n符号连接起来得到最终结果。content-length:8 content-md5:NFzcPqhviddjRNnSOGo4rw%3D%3D? content-type:text%2Fplain date:Mon%2C%2027%20Apr%202015%2016%3A23%3A49%20%2B0800 host:bj.bcebos.com这时候认证字符串的
signedHeaders内容应该是content-length;content-md5;content-type;date;host
3.3 生成SigningKey
SigningKey = HMAC-SHA256-HEX(sk, authStringPrefix),其中:
sk为用户的Secret Access Key,可以通过在控制台中进行查询,关于SK的获取方法,请参看获取AK/SK。authStringPrefix代表认证字符串的前缀部分,即:auth-v1/{accessKeyId}/{timestamp}/{expirationPeriodInSeconds}。
3.4 生成Signature
Signature = HMAC-SHA256-HEX(SigningKey, CanonicalRequest)
3.5 生成认证字符串
认证字符串 = auth-v1/{accessKeyId}/{timestamp}/{expirationPeriodInSeconds}/{signedHeaders}/{signature}
timestamp:签名生效UTC时间,格式为yyyy-mm-ddThh:mm:ssZ,例如:2015-04-27T08:23:49Z,默认值为当前时间。(为实现方便,直接使用时间戳!!)expirationPeriodInSeconds:签名有效期限,从timestamp所指定的时间开始计算,时间为秒,默认值为1800秒(30)分钟。signedHeaders:签名算法中涉及到的HTTP头域列表。HTTP头域名字一律要求小写且头域名字之间用分号(;)分隔,如host;range;x-bce-date。列表按照字典序排列。当signedHeaders为空时表示取默认值。