文章目录
- 1. 描述一下 MVC 框架
- 2. 如何在 Python 中拷贝一个对象,并说明它们之间的区别
- 3. 1 < (2 == 2) 和 1 < 2 == 2 的结果分别是什么,为什么
- 4. Python Web 开发中,跨域问题的解决思路
- 5. HTTP 请求方法
- 6. 在MySQL中,从 delete 语句中省略 where 子句,将产生什么后果
- 7. 将列表中的元素,根据位数合并成字典
- 8. Python 实现单例模式
- 9. 阅读以下代码,写出结果
- 10. [i % 2 for i in range(10)] 与 (i % 2 for i in range(10)) 的输出结果分别是什么
- 11. 以下代码输出的结果是什么,为什么
- 12. 说说 Django 使用 MySQL 的流程
- 13. Redis、HTTP、HTTPS、MySQL的默认端口分别是什么
- 14. 在Linux系统中,默认情况下管理员创建了一个用户,会在 /home 目录下建立该用户的宿主目录
- 15. 请写一个排序算法
- 16. Flask 中的 Response 返回类型有哪三种
- 17. Flask 中特殊的 Response 对象
- 18. Flask 中 request 的属性
- 29. Flask 中怎么写动态路由参数
- 20. Falsk 中初始化时可以指定的配置
- 21. 说说你做智能玩具项目的目的
- 22. 说说智能玩具有什么功能
- 23. 智能部分使用了什么算法
- 24. 语音 IM 通讯是怎么实现的
- 25. 手机 app 是怎么做的(使用什么方式)
- 26. 谈谈你对人工智能的理解(说出人工智能技术的关键字至少5个)
- 27. MongoDB 中的修改器
- 28. 说说你对 MongoDB 中 $ 的理解
- 29. MongoDB 中的数据类型
- 30. MongoDB 中的比较符
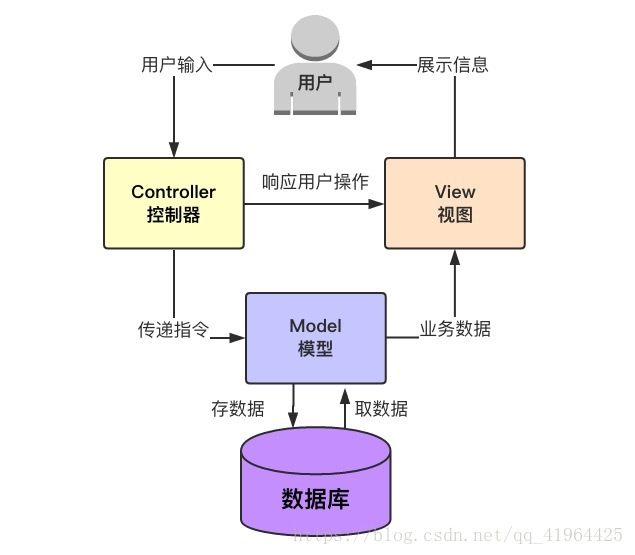
1. 描述一下 MVC 框架
MVC(Model View Controller)是软件工程中的一种软件架构模式。
MVC把软件系统分为三个基础部分:模型 Model、视图 View、控制器 Controller。
优点:耦合性低、重用性高、生命周期成本低等。
Django框架的设计模式便是借鉴了MVC架构的思想。将其分成了三部分,来降低各个部分之间的耦合性。但不同之处在于,Django拆分的三部分为:模型 Model、模板 Template、视图 View。也就是 MTV架构。
2. 如何在 Python 中拷贝一个对象,并说明它们之间的区别
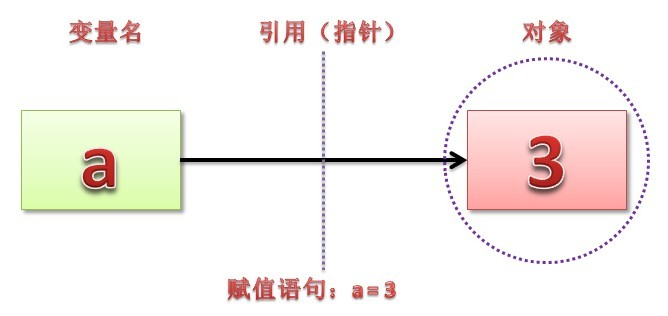
在Python中,对象分为两种:可变对象与不可变对象,不可变对象包括int、float、str、tuple等,可变对象包括list、set、dict等。需要注意的是,这里说的不可变指的是值不可变。对于不可变类型的变量,如果要对其更改,则会创建一个新值,并把变量绑定到新值上,而旧值如果没有被引用便等待垃圾回收。另外,不可变的类型可以计算hash值,比如字典的key。可变类型的数据对象操作的时候,不需要在其它地方申请内存,只需要在此对象后面连续申请(+/-)即可,也就是它的内存地址会保持不变,但区域会变长或者变短。
1. 赋值 引用
在Python中赋值语句总是建立对象的引用值,而不是复制对象。因此,Python变量更像是指针,而不是数据存储区域。
2. 深拷贝deepcopy 与 浅拷贝copy
Python中对象之间的赋值是按引用传送的,如果需要拷贝对象,需要使用标准库中的coppy模块。
import copy
- copy.copy:浅拷贝,只拷贝父对象,不会拷贝子对象,(列表切片也可实现浅拷贝).
- copy.deepcopy:深拷贝,拷贝父对象机器子对象(原始对象).
示例代码
import copy a = [1, [2, 3], {4: 5}] # 1.赋值,对象引用 b = a # 2.列表切片,浅拷贝 c =a[:] # 3.对象拷贝,浅拷贝 d = copy.copy(a) # 4.对象拷贝,深拷贝 e = copy.deepcopy(a) # 开始对原始对象进行操作 a.append(6) a[1].append(7) a[2][8] = 9 # 此时,我们来看看结果 for i in [a, b, c, d, e]: print(i) """ [1, [2, 3, 7], {4: 5, 8: 9}, 6] a [1, [2, 3, 7], {4: 5, 8: 9}, 6] b [1, [2, 3, 7], {4: 5, 8: 9}] c [1, [2, 3, 7], {4: 5, 8: 9}] d [1, [2, 3], {4: 5}] e """
3. 1 < (2 == 2) 和 1 < 2 == 2 的结果分别是什么,为什么
print(1 < (2 == 2)) # False print(1 < 2 == 2) # True这里的知识点是 比较运算符链式写法。
官方文档里有这样一个例子:Comparisons can be chained. For example, a < b == c tests whether a is less than b and moreover b equals c. 就是说:a < b == c 其实是 a > b and b == c 的缩写。
官方链接
4. Python Web 开发中,跨域问题的解决思路
对于Django或者Flask,我们会在中间件中添加响应头,来告知浏览器允许其跨域请求。
还有一种是JsonP,它的原理是利用浏览器不阻止src请求跨域来实现的。但它只能实现GET请求跨域。
在Django中间件中添加响应头实现跨域示例代码:
from django.utils.deprecation import MiddlewareMixin class MyCors(MiddlewareMixin): def process_response(self, request, response): # 等于'*'后,便可允许所有简单请求的跨域访问 response['Access-Control-Allow-Origin'] = '*' # OPTIONS:复杂请求自带特效——预检请求 # 判断当前的请求是否为预检请求,如果是,则允许复杂请求跨域 if request.method == 'OPTIONS': response['Access-Control-Allow-Headers'] = 'Content-Type' response['Access-Control-Allow-Methods'] = 'PUT,PATCH,DELETE' return response # 在settings.py配置文件中注册中间件,注意注册的顺序
5. HTTP 请求方法
GET
请求指定的页面信息,并返回实体主体。
POST
向指定资源提交数据进行处理请求(例如提交表单或上传文件),数据被包含在请求体中。
POST请求可能会导致新资源的建立和/或已有资源的修改。
PUT
从客户端向服务器传送的数据取代指定的文档的内容。
HEAD
类似于GET请求,只不过返回的响应中没有具体的内容,用于获取报头。
DELETE
请求服务器删除指定的页面。
OPTIONS
预检请求,在复杂请求跨域时会先发送此请求。
允许客户端查看服务器的性能。
CONNECT
HTTP/1.1协议中预留给能够将连续改为管道方式的代理服务器。
TRACE
回显服务器收到的请求,主要用于测试或诊断。
PATCH
实体中包含一个表,表中说明该URI所表示的原内容的区别。
MOVE
请求服务器将指定的页面移至另一个网络地址。
COPY
请求服务器将指定的页面拷贝至另一个网络地址。
LINK
请求服务器建立链接关系。
UNLINK
断开链接关系
WRAPPED
允许客户端发送经过封装的请求
Extension-mothed
在不改动协议的前提下,可增加另外的方法。
6. 在MySQL中,从 delete 语句中省略 where 子句,将产生什么后果
delete用于删除数据,where用于指定条件。结合起来就是,删除指定条件的数据。所以,省略where子句就是不指定条件删除数据,即删除所有数据。但由于MySQL的特性,delete语句清空表后会保留自增ID的count值。所以,如果你想清空表且不留任何痕迹,请使用truncate语句。
示例语句:
delete from tb; # 清空表,但留下ID truncate table tb # 清空表,不留任何记录 delete from tb where id=2 # 删除指定表中id为2的行
7. 将列表中的元素,根据位数合并成字典
lst = [1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 32768, 65536, 4294967296] # 将上面的列表,根据 位数 合并成下面的字典 dct = { 1: [1, 2, 4, 8], 2: [16, 32, 64], 3: [128, 256, 512], 4: [1024], 5: [32768, 65536], 10: [4294967296] } # 开始你的操作: dct2 = {} [dct2.setdefault(len(str(i)), []).append(i) for i in lst] print(dct2) # {1: [1, 2, 4, 8], 2: [16, 32, 64], 3: [128, 256, 512], 4: [1024], 5: [32768, 65536], 10: [4294967296]}
8. Python 实现单例模式
单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能排上用场了。
1. 使用模块
其实,Python的模块就是天然的单例模式,因为模块在第一次被导入时,会生成 .pyc 文件,当第二次被导入时,就会直接加载 .pyc 文件,而不是再次执行模块代码。因此,我们只需要把相关的函数和数据定义在一个模块中,就可以获得一个单例对象了。如果你真的想要一个单例类,你可以考虑这样做:# mysingleton.py文件 class Singleton(object): def fn(self): pass obj = Singleton()将上面的代码保存在文件mysingleton.py中。要使用时,直接在其它文件中导入此文件中的对象,这个对象即是单例模式的对象。
from mysingleton import obj
2. 使用装饰器
def Singleton(cls): _instance = {} def _singleton(*args, **kwargs): if cls not in _instance: _instance[cls] = cls(*args, **kwargs) return _instance[cls] return _singleton @Singleton class A(object): pass def __init__(self, x): self.x = x a1 = A(1) a2 = A(2) # 验证: print(a1.__dict__, a2.__dict__) # {'x': 1} {'x': 1} print(a1 is a2) # True
3. 基于 __new__ 方法实现(推荐使用,方便)
我们知道,当实例化一个对象时,是先执行 __new__ 方法实例化对象,然后再执行__init__ 方法初始化对象。
所以,我们可以基于这个实现单例模式:import threading class Singleton(object): _instance_lock = threading.Lock() def __init__(self): pass def __new__(cls, *args, **kwargs): if not(hasattr(Singleton, '_instance')): with Singleton._instance_lock: if not hasattr(Singleton, '_instance'): Singleton._instance = object.__new__(cls) return Singleton._instance # 开始验证: obj1 = Singleton() obj2 = Singleton() print(obj1 is obj2) # 验证线程安全: def run(): obj = Singleton() print(obj) for i in range(5): t = threading.Thread(target=run) t.start() # <__main__.Singleton object at 0x000002416C9A0E80> # <__main__.Singleton object at 0x000002416C9A0E80> # <__main__.Singleton object at 0x000002416C9A0E80> # <__main__.Singleton object at 0x000002416C9A0E80> # <__main__.Singleton object at 0x000002416C9A0E80>
4. 基于metaclass方式实现
对象由类创建,创建对象时,类的 __init__ 方法自动执行,类名() 执行类的 __call__ 方法。
而类由 type 创建,创建类时,type 的 __init__ 方法自动执行,类名() 执行 type 的 __call__ 方法(类的 __new__ 方法,类的 __init__ 方法)。
示例代码:
class Foo: def __init__(self): pass def __call__(self, *args, **kwargs): pass obj = Foo() # 类名() 执行type的 __call__ 方法 # 然后调用 Foo类(是type的对象)的 __new__方法,用于创建对象 # 最后调用 Foo类(是type的对象)的 __init__方法,用于初始化对象 obj() # 对象() 执行Foo的 __call__ 方法元类的使用:
class SingletonType(type): def __init__(self, *args, **kwargs): super(SingletonType, self).__init__(*args, **kwargs) def __call__(cls, *args, **kwargs): # 这里的cls,即Foo类 print('cls:', cls) obj = cls.__new__(cls, *args, **kwargs) cls.__init__(obj, *args, **kwargs) # Foo.__init(obj) return obj class Foo(metaclass=SingletonType): # 指定创建的Foo的type为SingletonType def __init__(self, name): self.name = name def __new__(cls, *args, **kwargs): return object.__new__(cls)实现单例模式:
import threading class SingletonType(type): _instance_lock = threading.Lock() def __call__(cls, *args, **kwargs): if not hasattr(cls, '_instance'): with SingletonType._instance_lock: if not hasattr(cls, 'instance'): cls._instance = super(SingletonType, cls).__call__(*args, **kwargs) return cls._instance class Foo(metaclass=SingletonType): def __init__(self, name): self.name = name # 开始验证: obj1 = Foo('name') obj2 = Foo('name') print(obj1 is obj2) # True # 验证线程安全: def run(): obj = Foo('name') print(obj) for i in range(5): t = threading.Thread(target=run) t.start() # <__main__.Foo object at 0x000002B06B9D0EF0> # <__main__.Foo object at 0x000002B06B9D0EF0> # <__main__.Foo object at 0x000002B06B9D0EF0> # <__main__.Foo object at 0x000002B06B9D0EF0> # <__main__.Foo object at 0x000002B06B9D0EF0>
5. 使用类
import threading class Singleton(object): _instance_lock = threading.Lock() def __init__(self, *args, **kwargs): pass @classmethod def instance(cls, *args, **kwargs): with Singleton._instance_lock: if not hasattr(Singleton, '_instance'): Singleton._instance = Singleton(*args, **kwargs) return Singleton._instance # 开始验证 obj1 = Singleton.instance(1) obj2 = Singleton.instance(2) print(obj1 is obj2) # 验证线程安全 def run(): obj = Singleton.instance() print(id(obj)) for i in range(5): t = threading.Thread(target=run) t.start() # 2585842154520 # 2585842154520 # 2585842154520 # 2585842154520 # 2585842154520
9. 阅读以下代码,写出结果
dct = {'a': 0, 'b': 1} def func(d): d['a'] = 1 # 步骤1 return d func(dct) dct['c'] = 2 # 步骤2 print(dct) # {'a': 1, 'b': 1, 'c': 2}解答: 步骤1 与 步骤2 操作的是同一个对象
10. [i % 2 for i in range(10)] 与 (i % 2 for i in range(10)) 的输出结果分别是什么
a = [i % 2 for i in range(10)] b = (i % 2 for i in range(10)) print(a) # [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] print(b) # <generator object <genexpr> at 0x000001C032982A40>解答:
前者是列表表达式,生成的自然是列表;
后者是生成器表达式,生成的自然是生成器。
11. 以下代码输出的结果是什么,为什么
def add_end(l=[]): l.append('end') print(l) add_end() # ['end'] add_end() # ['end', 'end']在定义完函数后,参数 l 的值就被计算出来了,并成为了一个类似于“全局变量”的东西,也就是说,一次调用函数完事之后,这个变量 不会被回收(注意:不管是传参还是不传参,它都不会被回收)。当再次以无参的形式调用该函数时,l 指向的依然是原本的那个 l=[] 的空间。
12. 说说 Django 使用 MySQL 的流程
第一步, 在配置文件 settings.py 中写好你要使用的数据库的信息:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', # 将后缀改为mysql 'NAME': '库名称', 'HOST': '数据库IP', 'PORT': '端口', 'USER': '远程用户', 'PASSWORD': '远程用户密码' } }第二步, 在与配置文件同级的 __init__.py 文件中添加如下代码来告诉Django使用 pymysql 模块连接数据库:
import pymysql pymysql.install_as_MySQLdb() # Django默认使用的是MySQLdb # MySQLdb是Python2.x版本的东东,我们使用的Python3.x,所以要更改为pymysql
13. Redis、HTTP、HTTPS、MySQL的默认端口分别是什么
- Redis 6379
- HTTP 80
- HTTPS 443
- MySQL 3306
14. 在Linux系统中,默认情况下管理员创建了一个用户,会在 /home 目录下建立该用户的宿主目录
15. 请写一个排序算法
下面将写一个快排:
# 思路: # 1. 取一个元素 p(第一个元素),使元素p归位 # 2. 元素p归位后,列表被 p 分成两部分,左边的数一定 不大于p 右边的数一定 不小于p # 3. 递归完成排序 # 用于递归 def quick_sork(data, left, right): if left < right: mid = partition(data, left, right) quick_sork(data, left, mid - 1) quick_sork(data, mid + 1, right) # 挖坑法 def partition(data, left, right): tmp = data[left] # 取一个元素p # 使元素p归位 while left < right: while left < right and data[right] >= tmp: right -= 1 data[left] = data[right] while left < right and data[left] <= tmp: left += 1 data[right] = data[left] data[left] = tmp return left lst = [i for i in range(100, 0, -1)] quick_sork(lst, 0, len(lst) - 1)
16. Flask 中的 Response 返回类型有哪三种
1. HttpResponse
@app.route('/index') def index(): return 'Hello World' # 其内部调用的是HttpResponse方法直接返回结果,其内部调用的是 HttpResponse 方法,在我们看来其实就是直接返回字符串。
2. Redirect
from flask import redirect @app.route('/home') def home(): return redirect('/index') # 将跳转至url路径为'/index'的页面当访问 /index 这个地址时,视图函数会触发其内部的 redirect(’/’) 方法,将跳转url地址为 /index 的页面,同时触发 /index 路径对应的视图函数。
3. render_template
from flask import render_template @app.route('/login') def login(): return render_template('login.html') # 将返回模板目录templates下的login.html页面在使用 render_template 方法之前,请先在当前项目的的根目录下创建一个名为 templates 的目录,此目录将用于存放模板文件。这是Flask框架的规则,存放模板文件的目录名称默认为 templates。如果你不喜欢,可在实例化 app 时通过 template_folder 参数指定新的模板目录。
17. Flask 中特殊的 Response 对象
1. jsonify
jsonify 方法返回的 json 类型的数据,其会使响应头中 Centent-Type 的值变为 application/json 。from flask import jsonify @app.route('/json') def json(): return jsonify({'name': 'yourname', 'gender': 'yourgender'})2. send_file
send_file 方法可将文本内容、图片、视频等信息放到网页上。from flask import send_file @app.route('/text') def text(): return send_file('文件路径')
18. Flask 中 request 的属性
- method 判断请求的类型
- args GET请求的数据,可使用 to_dict 将其转为字典
- form POST 请求的数据,需要在 route 中允许 POST 请求的数据:methods=[‘POST’]
- headers 获取请求头中的信息
- json 如果在请求头中指定了 Content-Type 为 application/json,将返回 json 数据,否则返回空
- data 存放非 mimetype 类型的数据,即 Content-Type 无法解析的数据,原始数据,其类型为 bytes
- path 当前的url路径,例如:/long
- url 完整的url路径
- script_root 返回当前url路径的上一级路径
- url_root 当前url路径的上一级的完整路径
- host 访问主机的url
- host_url 访问主机的完整url
- values 获取说有类型请求的数据
- files 获取上传的文件
- cookies 获取 cookies 信息
- environ 所有数据
request 是基于 mimetype 进行处理的,如果不属于 mimetype 类型的数据,request 会将其转化为 Json 格式并存到data中,其实我们可以通过 request.data 和 json.loads 拿到同样的数据。
29. Flask 中怎么写动态路由参数
1. <int:xx>
要求输入的url必须是可转换为 int 类型的@app.route('/test/<int:xx>') def test(xx): pass2. <string:xx>
要求输入的url必须是可转换为 String 类型的@app.route('/test/<string:xx>') def test(xx): pass3. <xx>
默认使用是可转换为 String 类型的@app.route('/test/<xx>') def test(xx): pass
20. Falsk 中初始化时可以指定的配置
from flask import Flask app = Flask( import_name=__name__, # 指定程序的名称 static_folder='static', # 静态文件存放路径,默认为项目根目录下的static目录 static_host=None, # 远程静态文件所使用的Host地址,这个是要与host_matching一起使用的 static_url_path=None, # 静态问价你的目录的url地址,默认不写与static_folder同名,远程文件时服用 host_matching=False, # 是否开启host主机位匹配,这个是要与static_host一起使用的,如果配置了static_host,则必须赋值为True # 如果不是特别需要的话,慎用,否则所有route的都需要host=""的参数 subdomain_matching=False, # 理论上来说是用来限制SERVER_NAME子域名的,但是目前还没有感觉出来区别在哪里 template_folder='templates', # 模板文件存放目录,默认为当前项目根目录下的templates目录 instance_path=None, # 指向另一个Flask实例的路径 instance_relative_config=False, # 是否加载另一个实例的配置 root_path=None, # 主模板所在的目录的绝对路径,默认为项目目录 )
21. 说说你做智能玩具项目的目的
关爱留守儿童,让玩具成为孩子与父母沟通的媒介,建立沟通的桥梁,让玩具成为孩子的玩伴,实现无屏社交,依靠孩子的。玩具能依靠孩子的指令做出相应,比如:“我想和爸爸聊天”,玩具就会根据指令提示“可以和爸爸聊天了”,并打开与手机app通讯的链接;再比如:“我想听世上只有妈妈好”,玩具就会根据指令播放相应的歌曲。
22. 说说智能玩具有什么功能
玩具可以点播朗诵诗歌,播放音乐,做游戏(比如成语接龙),与智能机器人聊天(图灵机器人)。
玩具可以与手机app通讯,玩具与玩具之间进行通讯,手机app可以为玩具点播歌曲。
23. 智能部分使用了什么算法
两种回答
- 使用百度AI中的语音合成和语音识别,点播功能是使用 Gensim 库进行训练的,聊天做游戏使用的是图灵机器人+百度语音合成。
- 使用百度AI中的语音合成和语音识别,NLP自然语言处理。点播功能便是基于百度NLP,聊天做游戏使用的是图灵机器人+百度语音合成。
24. 语音 IM 通讯是怎么实现的
通过 HTTP 传输音频文件,将音频文件保存在服务器中,并将聊天信息存储在服务器中。
在通过 WebSocket 进行实时通讯,收到消息后第一时间去服务器中查询聊天信息。
25. 手机 app 是怎么做的(使用什么方式)
使用 MUI 前端布局,使用 HTML5PLUS 来调用系统硬件驱动(比如摄像头,麦克风等)。
26. 谈谈你对人工智能的理解(说出人工智能技术的关键字至少5个)
- 语音类:语音识别,语音合成
- 图像类:图像识别,文字识别,人脸识别,视频审核
- 语言类:自然语言处理,机器翻译,语法分析,依存语法分析,文本纠错,对话情绪识别,词向量表示,短文本相识度,词义相识度,情感倾向分析
27. MongoDB 中的修改器
1. $set
- 更新数据
2. $push
- 用于对 Array(列表)数据类型进行 增加 元素的
3. $pull
- 用于对 Array(列表)数据类型进行 删除 元素的
4. $pop
- 用于将 Array(列表)数据类型中的第一个或最后一个元素删除
- {$pop: {hobby: 1}} 表示删除最后一个元素,可使用 -1 来删除第一个元素
5. $inc
- 将要操作的数据,加上某个值然后保存,如果是字符串则拼接
- db.table.updateOne({name: ‘张三’}, {$inc: {age: 1}}) 将name为’张三’的age加 1
- db.table.updateOne({name: ‘张三’}, {$inc: {age: -4}}) 将name为’张三’的age减 4
28. 说说你对 MongoDB 中 $ 的理解
我的理解就是代指字符,代指所查询到的数据的值或索引。
29. MongoDB 中的数据类型
类型 描述 Object ID Documents(行)自动生成的 _id String 字符串,必须是 UTF-8 Boolean 布尔值,true 或 false Integer 整数,有 int32 与 int64 子分,一般我们使用 int32 (正负21亿) Double 浮点数,MongoDB中没有 float 类型,所有的小数都是 Double 类型 Arrays 数组,一般在多个值对应一个键时使用 Object 对象,相当于Python中的字典 TimeStamp 时间戳,时间戳可以秒杀一切时间类型 Date 存储当前日期或时间,unix 时间格式 Null 空数据类型,一个特殊的概念
30. MongoDB 中的比较符
比较符 描述 $gt大于 $gte大于等于 $lt小于 $lte小于等于 $eq/:等于 $ne不等于