Hadoop第二篇:使用Maven开发Hadoop编程进阶
如何进行java代码开发进行符合自己需求的实践,先从Wordcount看看它是如何做的,这里从使用java接口看看一些基本的操作开始。
基础环境
- win7
- JDK1.8
- maven安装
- IDEA
- Hadoop在centos上部署完成(单机版,请参看前一篇)
java代码
IDEA创建一个java项目
pom.xml如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bamboo</groupId>
<artifactId>hadoop-1</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.2</version>
</dependency>
</dependencies>
</project>
文件的创建和读取
直接本地运行即可
使用mapredace进行数据处理
代码重现wordCount的内容,这里类取名为hadoop2
MapReduce理论
这部分可以跳过直接后面的代码,然后再回过头看看。
MapReduce分成了两个部分:
1)映射(Mapping)对集合里的每个目标应用同一个操作。如把大象放进冰箱分几个步骤,那么就可以把每个步奏当成一个mapping.
2)化简(Reducing)遍历集合中的元素来返回一个综合的结果。即,每个步奏的输出结果的过程,这个任务属于reducing。
你向MapReduce框架提交一个计算作业时
1.它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,每一个Map任务处理输入数据中的一部分
2.当Map任务完成后,它会经历Shuffle将多个map结果合并生成一些中间文件
3.这些中间文件将会作为Reduce任务的输入数据,经过Reduce处理之后把结果合并输出
Shuffle的主要目标就是把前面若干个Map的输出合并成若干个租(相当于group by)。
Reduce任务的主要目标就是把Shuffle合并后的数据作为输入数据处理后输出
MapReduce的伟大之处就在于编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
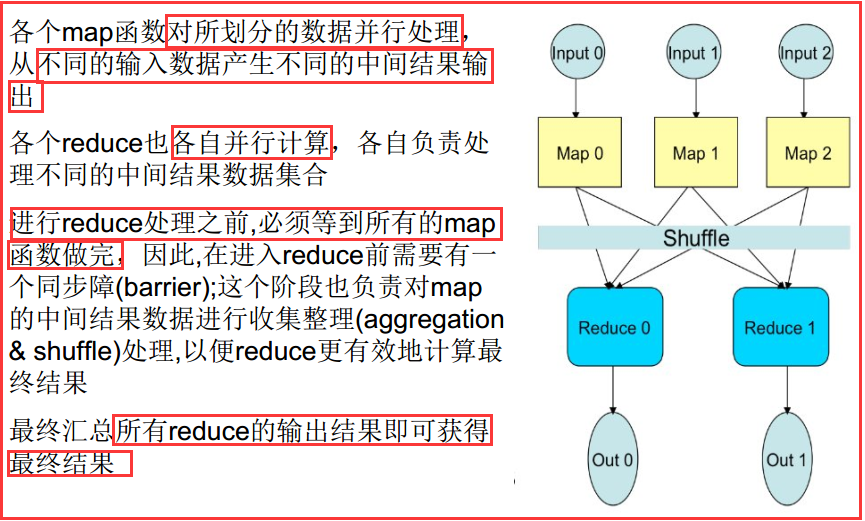
案例讲解
在map(v1)->k2函数中,输入端v1代表的是一行数据,输出端的k2可以代表是被引用的专利,在一行数据中所有v2和引用的次数。
在reduce函数中,k2还是被引用的专利,而[v2]是一个数据集,这里是将k2相同的键的v2数据合并起来。最后输出的是自己需要的数据k3代表的是被引用的专利,v3是引用的次数。
以wordcount为例,有如下数据集2份文档
hello word
hello hadoop
处理过程如下
1.每个个文档都有一个mapping
·每读取一行就按空格分割字符串为单词,则每个单词作为key,值默认为1
2.reduce处理:
·把所有的mapping处理结果合并,如单词hello的结果是 hello,[1,1] 因为出现了两次hello,这个过程由框架自己完成 我们不用处理
.按照key遍历所有的vlue集合需要手工处理,这里把所有的1相加就是该单词出现的个数
3.把结果集合输出出来
代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
/**
* MapReduce作业:功能和wordcount一样,在运行jar时设置文件输源和结果输出源
*
* 补充:
* 设置命令行参数变量来编程
这里需要借助Hadoop中的一个类Configured、一个接口Tool、ToolRunner(主要用来运行Tool的子类也就是run方法)
* <p>源码出自https://blog.csdn.net/yinbucheng/article/details/70243593</p>
* 拷贝人
*/
public class Hadoop2 {
//输入资源映射处理
public static class MyMapper extends Mapper<Object, Text, Text, IntWritable>{
private Text event = new Text();//字符串
private final static IntWritable one = new IntWritable(1);//默认字符串的个数为1
//字符串的分隔
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
int idx = value.toString().indexOf(" ");//空格的位置
if (idx > 0) {
String e = value.toString().substring(0, idx);//
event.set(e);
context.write(event, one);//反正结果<e,1>
}
}
}
//对输出结果集处理
public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
//把多个map中返回的<e,1>合并<key,values>即<e,[1,1,1]>后遍历
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {//遍历相同key的所有结果集,这里保存的是int计算结果和
sum += val.get();
}
result.set(sum);//把结果放入int
context.write(key, result);//注意:在map或reduce上面的打印语句是没有办法输出的,但会记录到日志文件当中。
}
}
/**
* args 在运行jar时设置参数
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
//如果args的参数长度小于2直接退出程序
if (otherArgs.length < 2) {
System.err.println("Usage: EventCount <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "event count");//构建作业配置job
//设置该作业所要执行的类
job.setJarByClass(Hadoop2.class);
job.setMapperClass(MyMapper.class);//设置map
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setCombinerClass(MyReducer.class);//设置
//设置自定义的Reducer类以及输出时的类型
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));//设置文件输入源的路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//设置结果输出流的路径
System.exit(job.waitForCompletion(true) ? 0 : 1);//提交作业完成后退出
}
}
运行代码
java项目打包
mvn package
把包上传到centos上
/mnt/hadoop
创建手工数据源
cd /mnt/hadoop/input/event
[root@localhost input]# touch evenet.log.1
[root@localhost input]# touch evenet.log.2
依次vi打开粘贴如下内容
JOB_NEW ...
JOB_NEW ...
JOB_FINISH ...
JOB_NEW ...
JOB_FINISH ...
查看数据源,清除不需要的数据源,清空数据输出路径(第一次运行时可以跳过这一步)
hdfs dfs -ls /mnt/input
hdfs dfs -rm /mnt/input/evenet.log*
hadoop fs -rmr /mnt/out
数据源放入dfs
hdfs dfs -ls /mnt/input
hadoop fs -mkdir -p /mnt/input
hdfs dfs -put /mnt/hadoop/input/event/* /mnt/input
hadoop fs -ls /mnt/input/input
运行代码
hadoop jar hadoop-1-1.0-SNAPSHOT.jar Hadoop2 /mnt/input /mnt/out
等待它执行结束,查看结果
hadoop dfs -cat /mnt/out/*
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
JOB_FINISH 4
JOB_NEW 6
MapReduce深入学习进阶样例
从上面的样例中我们了解了代码处理数据的大致过程,那么如何实现更多业务场景的数据处理呢,毕竟我们不是只做单表数据的个数统计,现实中可能会有更加复杂的运用,就像我们队数据库操作一样,单表到多表,复合统计等等,列出几个比喻的例子:
日志log如下
user.log
112 王小二
113 李小明
trade.log
10:48:20.669 INFO [pool-9-thread-1] c.z.e.a.domain.job.TransSuccessJob [TransSuccessJob.java : 42] 积分交易成功通知 notifyVo={"uid":112,"coin":"yxt","amount":10,"price":13.5555,"oPrice":13.5555,"transFee":0.2711,"oTransFee":0.2711,"tid":4339,"buy":true,"ext":"","dealTime":"2018-09-04 10:03:10"}
1.比如会查询单suer表特定几个字段的结果,单表[uid,coin,amount]统计结果,如结果要求如下
23 yxt 200 ETH 10
2.查询[uaerName,coin,amout]的统计结果,这个就是多表关联查询,如结果要求如下
李三 yxt 200 ETH 10
看上去是不是很像数据库的统计,但是这里操作的不是数据库,而是文本文件甚至流式文件,MapReduce就是要实现从分布式文件中的超大数据中处理结果。而实现的关键就在于两个实现类Mapper和Reducer
而这两个实现类都需要使用的一个地方就是MapReduce<key,value>,从上面的处理过程讲解我们知道,每一个步奏都是把数据处理成为了key,value键值输出并且作为下一个处理过程的输入,第二个处理过程接收到的依然是(key,vaule)键值对的数据类型,如何实现符合我们需要的键值类型才是整个数据处理的最重要的部分,毕竟我们不可能只处理一些基本类型的数据。
一些常见的基础类型数据对<key,value>
(Text,IntWritable)前面的wordCount就用到了,学生成绩统计也可以使用
(LongWritable,LongWritable)比如手机号的流量统计,单位是KB
MapReduce: <key,value>
MapReduce常用数据类型
ByteWritable:单字节数值
IntWritable:整型数
LongWritable:长整型数
FloatWritable:浮点数
DoubleWritable:双字节数值
BooleanWritable:标准布尔型数值
Text:使用UTF8格式存储的文本
NullWritable:当<key,value>中的key或value为空时使用
以上类型中 IntWritable LongWritable Text NullWritable DoubleWritable较为常用,实际中我们可能遇到复杂的类型,比如上面举例的user.log特定字段的统计,vule的值就不是一个基础类型,而是好几个字段的复合类型,这种情况我们该如何处理呢。
MapReduce自定义数据类型
- key实现WritableComparable
- value通常只需要实现Writable
关键就在这里,
key决定了是不是同一个数据,比如是不是同一个人,同一个手机号,因此Comparable的功能必须有;
value则决定了你需要处理的数据是什么格式的
案例1:手机上网流量统计
数据源:
130313143750 1238 17823 3424 2342
每个电话号码每上一次网络,就会生成一条日志数据
需求目标:
手机号码 上行数据包总数 下行数据包总数 上行总流量 下行总流量
13123412431 1238 17823 3424 2342
13622311238 17223 34214 23421 1231
13123412431 12380 1828 34 23
MapReduce设计:
** key是什么?
–电话号码
** value是什么?
–后面四个字段
Map阶段结果:
把数据分割成 key,value这里的valeu是一个对象类型
13123412431 (123,2423,3453,234)
13123412431 (789,1231,4353,234)
13123412431 (1231,231,342,23)
Shuffle阶段的结果
key value list
13123412431 (123,2423,3453,234),(789,1231,4353,234),(1231,231,342,23) ...
13622311238 (1233,23,342353,23234),(78239,123231,42353,2234) ...
Reduce最终结果:
hadoop dfs -cat /mnt/out/*
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
13123412431 1276 17846 3448 2384
13123412432 1278 17848 3450 2386
13123412433 1280 17850 3452 2388
13123412434 1282 17852 3454 2390
13123412435 1284 17854 3456 2392
13123412436 1286 17856 3458 2394
13123412437 1288 17858 3460 2396
13123412438 1290 17860 3462 2398
13123412439 1292 17862 3464 2400
13123412440 1294 17864 3466 2402
构造复合类型的数据类型
package entity;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class DataTotalWritable implements Writable {
// 上行数据包总数
private long upPackNum ;
// 下行数据包总数
private long downPackNum ;
// 上行总流量
private long upPayLoad ;
// 下行总流量
private long downPayLoad ;
public DataTotalWritable() {
}
public DataTotalWritable(long upPackNum, long downPackNum, long upPayLoad, long downPayLoad) {
this.set(upPackNum, downPackNum, upPayLoad, downPayLoad);
}
public void set (long upPackNum, long downPackNum, long upPayLoad,long downPayLoad) {
this.upPackNum = upPackNum;
this.downPackNum = downPackNum;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
}
public long getUpPackNum() {
return upPackNum;
}
public void setUpPackNum(long upPackNum) {
this.upPackNum = upPackNum;
}
public long getDownPackNum() {
return downPackNum;
}
public void setDownPackNum(long downPackNum) {
this.downPackNum = downPackNum;
}
public long getUpPayLoad() {
return upPayLoad;
}
public void setUpPayLoad(long upPayLoad) {
this.upPayLoad = upPayLoad;
}
public long getDownPayLoad() {
return downPayLoad;
}
public void setDownPayLoad(long downPayLoad) {
this.downPayLoad = downPayLoad;
}
//^为异或运算, << 带符号左移, >>带符号右移, >>> 无符号右移
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + (int) (downPackNum ^ (downPackNum >>> 32));
result = prime * result + (int) (downPayLoad ^ (downPayLoad >>> 32));
result = prime * result + (int) (upPackNum ^ (upPackNum >>> 32));
result = prime * result + (int) (upPayLoad ^ (upPayLoad >>> 32));
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
DataTotalWritable other = (DataTotalWritable) obj;
if (downPackNum != other.downPackNum)
return false;
if (downPayLoad != other.downPayLoad)
return false;
if (upPackNum != other.upPackNum)
return false;
if (upPayLoad != other.upPayLoad)
return false;
return true;
}
@Override
public String toString() {
return upPackNum + "\t" + downPackNum + "\t"
+ upPayLoad + "\t" + downPayLoad ;
}
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
}
public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong() ;
this.downPackNum = in.readLong() ;
this.upPayLoad = in.readLong() ;
this.downPayLoad = in.readLong() ;
}
}
map实现类和Reduce实现类
import java.io.IOException;
import entity.DataTotalWritable;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* MapReduce复核类型数据处理
*
* <p>源码出自https://blog.csdn.net/helpless_pain/article/details/7015383</p>
* 拷贝人 bamoboo
* 2018-9-14
*/
public class Hadoop3 extends Configured implements Tool {
//输入资源映射处理
public static class DataTotalMapper extends
Mapper<LongWritable, Text, Text, DataTotalWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//split by '\t'
String[] splits = value.toString().split("\t") ;
//以手机号码作为output key
String phoneNum = splits[0];
Text mapOutputKey = new Text();
mapOutputKey.set(phoneNum);
// set map output value
long upPackNum = Long.parseLong(splits[1]) ;
long downPackNum = Long.parseLong(splits[2]) ;
long upPayLoad = Long.parseLong(splits[3]) ;
long downPayLoad = Long.parseLong(splits[4]) ;
DataTotalWritable mapOutputValue = new DataTotalWritable() ;
mapOutputValue.set(upPackNum, downPackNum, upPayLoad, downPayLoad);
//map output
context.write(mapOutputKey, mapOutputValue);
}
}
public static class DataTotalReducer extends
Reducer<Text, DataTotalWritable, Text, DataTotalWritable> {
@Override
protected void reduce(Text key, Iterable<DataTotalWritable> values,
Context context) throws IOException, InterruptedException {
long upPackNumSum = 0;
long downPackNumSum = 0;
long upPayLoadSum = 0;
long downPayLoadSum = 0;
//iterator
for(DataTotalWritable value : values){
upPackNumSum += value.getUpPackNum() ;
downPackNumSum += value.getDownPackNum() ;
upPayLoadSum += value.getUpPayLoad() ;
downPayLoadSum += value.getDownPayLoad() ;
}
// set output value
DataTotalWritable outputValue = new DataTotalWritable() ;
outputValue.set(upPackNumSum, downPackNumSum, upPayLoadSum, downPayLoadSum);
// output
context.write(key, outputValue);
}
}
public int run(String[] args) throws Exception {
//Job
Configuration conf = super.getConf();
Job job = Job.getInstance(conf);
job.setJarByClass(getClass());
//Mapper
job.setMapperClass(DataTotalMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DataTotalWritable.class);
//Reducer
job.setReducerClass(DataTotalReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DataTotalWritable.class);
//输入路径
Path inPath = new Path(args[0]);
FileInputFormat.addInputPath(job, inPath);
//输出路径
Path outPath = new Path(args[1]);
FileSystem dfs = FileSystem.get(conf);
if (dfs.exists(outPath)) {
dfs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
//Submit Job
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1;
}
//这里的运行输入和输出已经在程序中写死了不需要在执行时指定参数
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//运行时设置输入 输出
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
//如果args的参数长度小于2直接退出程序
if (otherArgs.length < 2) {
System.err.println("Usage: EventCount <in> <out>");
System.exit(2);
}
//也可以直接写死
//args = new String[] {"hdfs://blue01.mydomain:8020/input2", "hdfs://blue01.mydomain:8020/output2"};
// run job
int status = ToolRunner.run(conf,new Hadoop3(),args);
System.exit(status);
/* Long p=13123412431L;
for (int i=0;i<10;i++){
System.out.printf("%d\t%d\t%d\t%d\t%d\n",p++ ,38+i, 23+i, 24+i, 42+i);
}*/
}
}
运行数据
把程序中/resources下的phone.log.1,phone.log.1上传到/mnt/hadoop/input/phone/文件夹下
把打包后的程序hadoop-1-1.0-SNAPSHOT.jar上传到/mnt/hadoop路径下
清空数据源和结果集输出源
hdfs dfs -rm /mnt/input/*
hadoop fs -rmr /mnt/out
数据提交到HDFS
hdfs dfs -put /mnt/hadoop/input/phone/* /mnt/input
hdfs dfs -ls /mnt/input
运行程序并查看结果集
hadoop jar hadoop-1-1.0-SNAPSHOT.jar Hadoop3 /mnt/input /mnt/out
hadoop dfs -cat /mnt/out/*
结果就和上面中的结果集一模一样
多类型数据行转列
数据文件:
customer文件
用户CID,用户姓名,联系方式
1,Stephanie Leung,555-555-5555
2,Edward Kim,123-456-7890
3,Jose Madriz,281-330-8004
4,David Stork,408-555-0000
order文件
用户CID,订单号,价格,日期
3,A,12.95,02-Jun-2008
1,B,88.25,20-May-2008
2,C,32.00,30-Nov-2007
3,D,25.02,22-Jan-2009
目标:
用户CID,订单号,价格,时间,用户姓名,联系方式
1,B,88.25,20-May-2008,Stephanie Leung,555-555-5555
2,C,32.00,30-Nov-2007,Edward Kim,123-456-7890
3,D,25.02,22-Jan-2009,Jose Madriz,281-330-8004
3,A,12.95,02-Jun-2008,Jose Madriz,281-330-8004
思路:
选用: Join
map阶段:
** map task依次读取两个文件,切割,并设置key和value,取cid为key,同时给来自不同的文件的value打一个标签
value == flag + value
key value list
3 customer('Jose Madriz,281-330-8004')
3 order('A,12.95,02-Jun-2008')
3 order('D,25.02,22-Jan-2009')
Shuffle阶段:
key value list
3 customer('Jose Madriz,281-330-8004'),order('A,12.95,02-Jun-2008'),order('D,25.02,22-Jan-2009')
reduce阶段:
** Join 数据根据flag得不同摆放好次序合并
3 A,12.95,02-Jun-2008,Jose Madriz,281-330-8004
3 D,25.02,22-Jan-2009,Jose Madriz,281-330-8004
数据类型DataJoinWritable
private String flag;
private String data;
public void set(String flag, String data) {
this.flag = flag;
this.data = data;
}
数据拆分合并DataJoinMapper
1.按空格或者tab切割
2.splits.length长度不同则设置不同的flag
key,value存放格式为cid,(str1+str2)+str3的方式字符串拼接
public static class DataJoinMapper extends
Mapper<LongWritable, Text, Text, DataJoinWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] splits = value.toString().split(",");
//output key,以连接值为key
String cid = splits[0];
Text mapOutputKey = new Text();
mapOutputKey.set(cid);
//output value
DataJoinWritable mapOutputValue = new DataJoinWritable();
// length == 3 ==> customer
if (splits.length == 3) {
String name = splits[1];
String phoneNum = splits[2];
mapOutputValue.set("customer", name + "," + phoneNum);
}
// length == 4 ==> order
if (splits.length == 4) {
String name = splits[1];
String price = splits[2];
String date = splits[3];
mapOutputValue.set("order", name + "," + price + "," + date);
}
context.write(mapOutputKey, mapOutputValue);
}
}
reduce数据在进行遍历时,由于cid相同的数据会成为一个list,根据不同的flag进行合并即可,这里customerInfo字符串 和所有OderList中的数据遍历合并,每合并一次就写出一行数据。
public static class DataJoinReducer extends
Reducer<Text, DataJoinWritable, NullWritable, Text> {
@Override
protected void reduce(Text key, Iterable<DataJoinWritable> values, Context context)
throws IOException, InterruptedException {
String customerInfo = null;
List<String> orderList = new ArrayList<String>();
for (DataJoinWritable value : values) {
if ("customer".equals(value.getFlag())) {
customerInfo = value.getData();
} else if ("order".equals(value.getFlag())) {
orderList.add(value.getData());
}
}
//遍历订单列表和客户信息合并为一行数据并写出
Text outputValue = new Text();
for (String order : orderList) {
outputValue.set(key.toString() + "," + order + "," + customerInfo);
context.write(NullWritable.get(), outputValue);
}
}
}
以上案例参考资料
https://blog.csdn.net/helpless_pain/article/details/70153834
参考资料
更多java HDFS操作讲解
https://www.cnblogs.com/zhangyinhua/p/7678704.html
如上代码已经上传到github,请参考我的git仓库地址
https://github.com/BambooZhang/bigData.git