爬虫总结
1. 爬虫流程?
- 准备url列表
- 发起请求、获得响应
- 提取数据,提取url放入url列表
- 保存数据
聚焦爬虫的流程
注意:提取的数据以url对应的响应为准,浏览器element只能作为参考
2. requests的使用
pip install requests
2.1 基本使用
resp = request.get(url,headers=headers,params=parmas)
resp = request.post(url,data=data,headers=headers)
# 原始数据,bytes类型
resp.content
resp.content.decode()
# 根据响应信息进行有规律的推测网页的编码
resp.text
resp.encoding="utf-8"
2.2 保持会话
- session类
session = requests.sesssion() # Session()
session.get()
session.post()
# 每次请求后,会读取响应头的set——cookies,并在下次请求时自动携带
- Cookie字符串
从浏览器的请求头中复制一份Cookie
headers = {
Cookie:"xxxx"
}
requests.get(url,headers=headers)
- cookies参数
参数类型:dict
cookies_dict = {}
requests.get(url, headers=headers, cookies=cookies_dict)
2.3 设置UA,设置代理
headers = {
"User-Agent":"xxx"
}
requests.get(url, headers=headers)
proxies = {
"http":"http://192.168.1.1:80",
"https":"https://192.168.1.1:80"
}
requests.get(url, headers=headers, proxies=proxies)
3. xpath提取数据
pip install lxml
3.1 xpath语法
//a[@class='next'] 通过属性值定位标签
//a[text()='下一页'] 通过文本定位标签
//a[contains(@class,'next')] 定位class属性包含next的所有a标签
//a[not(@class or @name)] 定位所有不包含class属性和name属性的a标签
/div//text() 提取div下面的所有文本
/a/@href 提取属性值
/a/text() 提取文本值
/div/a div下面的a标签,a是div的子结点
/div//a div下面所有的a标签,a是div的后代结点
/a/following-sibling::*[2] 获取a标签下面的所有兄弟结点的第二个
/a/following-sibling::ul[1] 获取a标签下面所有ul的兄弟结点的第一个
3.2 lxml模块的使用
from lxml import etree
el = etree.HTML(str or bytes) # 参数可以是str或者bytes类型网页源代码
el.xpath("//a[@class='next']") # 返回是元素类型为element对象的列表
# element 具有xpath方法
el.xpath("//a/@href") # 返回元素类型为str的列表
4. scray框架
4.1 scrapy框架流程
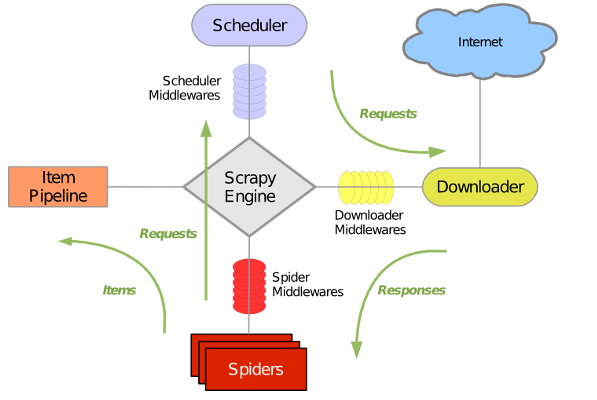
-
调用start_requests()方法,将start_urls中所有的url构造成request对象,并放入调度器
-
引擎从调度器的请求队列中取出一个request,通过下载器中间件process_request()方法,交给下载器
-
下载器发起请求,获得响应,通过下载器中间件process_response()方法,到达引擎,再通过爬虫中间件的process_response()交给爬虫
-
爬虫提取数据
3.1 提取出来的是数据,通过引擎交给管道
3.2 提取出来的是url,构造请求,通过爬虫中间件的process_request()方法,交给调度器 -
管道进行数据清洗、数据保存
4.2 scrapy的基本使用
- scrapy startproject myspider
- cd myspider
- scrapy genspider (-t crawl) itcast itcast.cn
yield scrapy.Request(url,callback,meta,dont_filter) # url不会补全
# callback 将来url响应的处理函数
# dont_filter 默认false,过滤请求,重复的请求会被过滤
yield reponse.follow(url,....) # url会自动补全
def parse(self,repsonse):
item = response.meta['item']
response.xpath("").extract()
response.xpath("").extract_first()
4.3 管道
- 开启管道
在settting中,添加管道的路径
ITEM_PIPELINES = {
'suning.pipelines.SuningPipeline': 300, # 设置管道获取数据的优先级,数字越低,优先级越高
}
- 方法
process_item(item,spdier)
if spider.name = "itcast" # spider当前传递item的爬虫对象
item...
return item # 如果下一个管道需要数据,必须返回item
open_spdier(spider) # 每个爬虫开启的时候会执行一次
# 数据库的连接初始化
close_spdier(spider) # 每个爬虫关闭的时候执行一次
# 数据库的关闭
4.4 中间件
- 开启中间件
# SPIDER_MIDDLEWARES = {
# 'suning.middlewares.SuningSpiderMiddleware': 543,
# }
DOWNLOADER_MIDDLEWARES = {
'suning.middlewares.SeleniumMiddleware': 544,
}
- 中间件的两个方法
process_request(request,spider):
return None # 1. 继续请求,
return Request # 2. 请求不再继续,而是放入调度器
return Response # 3. 请求不再下载,交给爬虫提取数据
process_response(request,response,spdier):
return Request # 1. 请求放入调度器
return Response # 2. 继续经过其他中间件的process_response,或者到达引擎,后续交给爬虫处理
- 中间件的功能
- 设置UA
process_request(request,spider):
request.headers['User-Agent'] = random('UA')
- 设置代理
process_request(request,spider):
request.meta['proxy'] = 'http://192.168.1.1:80'
- 设置cookies(主要是为了反反爬)
process_request(request,spider):
request.cookies = cookies# 可以从cookies池随机取出一个
- scrpay集成selenium
open_spdier(spider):
if spider.name = "itcast":
spider.driver = webdirver.Chrome()
close_spider(spider);
if spider.name = "itcast":
spider.driver.quit()
process_request(request,spdier);
if spider.name = "itcast":
spdier.dirver.get(request.url)
return TextResponse(body=spdier.dirver.page_source,request=request,encoding="utf-8",url=spider.dirver.current_url)
4.5 post请求
scrapy.FormRequest(url,callback,formdata)
scrapy.FormRequest.from_response(response,fromdata,callback)
scrapy中默认开启的cookies传递,即本地请求获得的cookies,会在下次请求自动携带
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
5. scrapy_redis
scrapy_redis 是scrapy框架的一个扩展组件,实现了两个功能:
- 增量式爬虫
- 分布式爬虫
实质:就是将请求队列和指纹集合进行了持久化存储
在seeeting.py中继续配置
# 指定了去重的类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 制定了调度器的类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 调度器的内容是否持久化
SCHEDULER_PERSIST = True
REDIS_URL = "redis://127.0.0.1:6379"
5.1 如何去重
1.请求生成指纹
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
return fp.hexdigest()
利用hashlib的sha1,对request的请求体、请求url、请求方法进行加密,返回一个40位长度的16进制的字符串,称为指纹
- 进队
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
self.queue.push(request)
return True
- 如果请求需要过滤,并且当前请求的指纹已经在指纹集合中存在了,就不能进入队列了
- 如果不需要过滤,直接进入队列
- 如果请求需要过滤,并且请求的指纹是一个新的指纹,进入队列
5.2 实现分布式爬虫
类需要继承自 RedisSpider、RedisCrawlSpider
redis_key:表示,在redis数据库中存储start_urls的键的名称
6. 数据去重
- 中间件去重
process_response(request,response,spider):
#set可以是内存set集合,也可以是redis的set
ret = set.add(md5(response.body))
if ret == 0:
return request
else
return response
- 建立复合索引
# 复合索引,加速和去重
stu.ensure_index([("hometown", 1), ("age", 1)], unique=True)
# 根据数据的特征,在mongodb中 对指定字段建立复合索引,所有字段值相同时就无法二次插入了
-
布隆过滤器
6. 验证码如何搞定?
-
常见验证码,可以利用云打码平台去处理
-
利用selemiun破解极验滑动验证码
- 加载页面,获取滑块对象
- 获取两个图片(1张是带缺口的图片,1张隐藏的完整的图片)
- 由于原始图片进行了处理,每一张原图都被拆成52张无序的图片,我们需要找个所有的图片,以及在原图的对应位置,然后将52张图片进行合并
- 如何合并?创建一个空格图片,将52张图片下载下来,按照指定原图位置填充到空白图片中就可以得到完成的原图
- 对比两张图片的像素,找到缺口的左上角位置,这里设定,像素差异值(RGB)大于50,认为满足要求,缺口左上角位置的x 即鼠标需要移动的距离
- 这里不能直接控制鼠标匀速移动,因为这样会被极验平台识别是机器操作,所以模拟人的行为先加速后减速,最后到达位置后,随机算出一个偏移量,再挪动一下,因为拖动的距离不能十分精准,否则也容易被识别是机器操作
- 如何实现先加速后减速?加速度先正后负
-
微博宫格验证码
-
这种验证码一般是频繁登陆后或者账号存在异常时才会显示
-
首先通过分析,这个宫格只有4个,最多的连接方式位24种,可以先把这24中图片全部下载到本地,根据灰色箭头的指向顺序分别命名这24张图片
-
利用selenium进行登陆时,如果弹出验证,可以把本次验证的图片下载到本地,和本地的24张图片进行匹配,设定只要99%的像素差值小于20的,认为两张图片匹配上了
-
获取匹配到的图片的文件名,即滑动的顺序确定
-
通过xpath找到4个按钮的element,根据滑动顺序,依次完成4个按钮的滑动即可
-
7. cookie池的维护
7.1 为啥使用cookies?
爬虫中为了获取登陆后页面的数据,必须携带对应的cookies,网站有时候也会根据账号的频繁请求断定当前是一个爬虫程序在请求,可能会进行限制,为了实现反反爬,需要构建cookies池,每次请求都携带不同cookies
7.2 如何实现?
-
存储形式:存储在redis中,“spider_name:username–password":cookie
-
需要专门创建一个py文件,包含四个方法:
- initcookies() 初始化所有账号的cookies,将所有账号对用进行登陆获取cookies并保存在redis中
- update_cookie(spider_name,username,password) # 重新获取账号对应的cookies,并存入redis中
- remove_cookie(spider_name,usrname,password) # 从redis中删除改账号对应的cookie
- get_cookie(username,password) # 尝试登陆该账号获取cookies
-
在scrapy的下载器中间件(RetryMiddleware)继承自的process_request()随机选择一个cookie,进行设置,并在request的meta中保存该cookies对应的账号
def process_request(self,request,spider): # 获取redis中所有的键(假设redis中只保存了cookies) redisKeys = self.rconn.keys() elem = random.choice(redisKeys) request.cookies = cookie # 在请求中记录当前cookies对应的账号和密码 request.meta["accountText"] = elem.split(":")[-1] -
在中间件的process_response()中获取响应,如果响应状态码是301、302等,说明发生页面重定向,那么当前的这个cookies肯定失效了,需要更新或者删除cookies
def process_response(self,request,response,spider): if response.status in [300, 301, 302, 303]: # 获取重定向的url redirect_url = response.headers["location"] if url == "login_url":# 如果是登陆页面,说明当前cookies失效了,需要更新 username,passworod = request.meta['accountText'].split("--") update_cookie(spider_name,username,password) elif url=="验证页面":# 说明账号被封了 username,passworod = request.meta['accountText'].split("--") remove_cookie(spider_name,username,password) # RetryMiddleware中的尝试重新发起请求 reason = response_status_message(response.status) return self._retry(request, reason, spider) or response # 重试
8. 爬虫数据的存储
一般是mysql和mongodb
-
爬取的数据通常都是非结构化数据,这在关系模型的存储和查询上面都有很大的局限性。但爬回来的数据汇总处理后需要在网页上展示,此时可能需要和django项目对接,可以把爬虫数据组织成结构化数据,此时存储在mysql更好一些
-
根据数据量,200w到2000w的数据量相对来说不是很大,二者都可以。但是基本上数据库达到千万级别都会有查询性能的问 题,MYSQL单表在超过千万级以上性能表现不佳,所以如果数据持续增长的话,可以考虑用mongodb。毕竟mongodb分片集群搭建起来比mysql集群简单多 了,而且处理起来更灵活
9. 常见的反爬虫和应对方法?
- 通过Headers反爬虫:
- 很多网站都会对请求Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站 的防盗链就是检测Referer)。这个容易解决,之前收集了一大堆的User-Agent,如果用的scrapy框架,就在 爬虫中间件中对reqeust请求添加一个随机的User-Agent,如果是requests库,在请求方法中传入一个包含 User-Agent的headers字典即可
- 验证码, 爬虫爬久了通常网站的处理策略就是让你输入验证码验证是否机器人,此时有三种解决方法
详情请查看 - 用户行为检测 有很多的网站会通过同一个用户单位时间内操作频次来判断是否机器人,比如像新浪微博等网站。这种情况 下我们就需要先测试单用户抓取阈值,然后在阈值前切换账号其他用户,如此循环即可。 当然,新浪微博反爬手段不止是账号,还包括单ip操作频次等。所以可以使用代理池每次请求更换不同的代理 ip,也可以考虑维护了一个cooies池,在每次请求时随机选择一个cookies。
- ajax请求参数被js加密
使用selenium + phantomJS,调用浏览器内核,并利用phantomJS执行js来模拟人为操作以及触发页面中的 js脚本。从填写表单到点击按钮再到滚动页面,全部都可以模拟,不考虑具体的请求和响应过程,只是完完整 整的把人浏览页面获取数据的过程模拟一遍。 - 分布式爬虫, 分布式能在一定程度上起到反爬虫的作用,当然相对于反爬虫分布式大的作用还是能做到高效大量的抓取
- 注意配合移动端、web端以及桌面版 其中web端包括m站即手机站和pc站,往往是pc站的模拟抓取难度大于手机站,所以在m站和pc站的资源相 同的情况下优先考虑抓取m站。同时如果无法在web端抓取,不可忽略在app以及桌面版的也可以抓取到目标 数据资源。