python小课堂23 - 正则表达式(一)
前言
今天来介绍一下Python的正则表达式。先来看下定义,何为正则表达式?
正则表达式是一个特殊的字符序列,一个字符串是否与我们给定的这个字符序列相匹配。正则最重要的功能就是处理字符串,例如检索你在某一段字符串中的特定单词,或者将原来某个位置的特定字符换成你想要的字符。而对于爬虫来说,正则表达式是必不可少的技能之一,要想正确提取源代码中你想要的信息内容,一般来说都会用到正则。
Python的re模块初体验
这里用例子来假设一个场景吧…现在你正打算转行踏入程序员的领域,然而面临的第一个问题就是选择一个主修语言来作为你转行后的学习动力。于是有个字符串language=“Java,Python,Go,Js,C,C++,PHP”,你下定决心要学Python,于是让你判断Python这门语言是否在这个字符串中存在!你会怎么做呢?
方案一:
通过python内置函数string.index(‘Python’)
language = 'Java,Python,Go,Js,C,C++,PHP'
print(language.index('Python'))
>>> 5
结果说明在索引下标第5位开始,寻找到了Python字符串。
方案二:
通过in关键词
language = 'Java,Python,Go,Js,C,C++,PHP'
print('Python' in language)
>>> True
结果说明Python字符串存在于language中。
方案三:
通过re模块,需要import re。
import re
language = 'Java,Python,Go,Js,C,C++,PHP'
"""
re.findall(pattern, string, flags=0):
必填的两个参数:
第一个参数是正则表达式的模式;
第二个参数是原字符串
选填参数: flags ,传入例如忽略大小写的官方参数
返回的结果是: list
"""
result = re.findall('Python',language)
print(result)
>>> ['Python']
大家可以仔细看下代码,注释已经写得很清楚啦…使用re.findall,见名知意,是查找到所有匹配到的,所以返回的肯定是list。不信的话,我们将代码修改一下,在language里多加一个Python,看下结果如何:
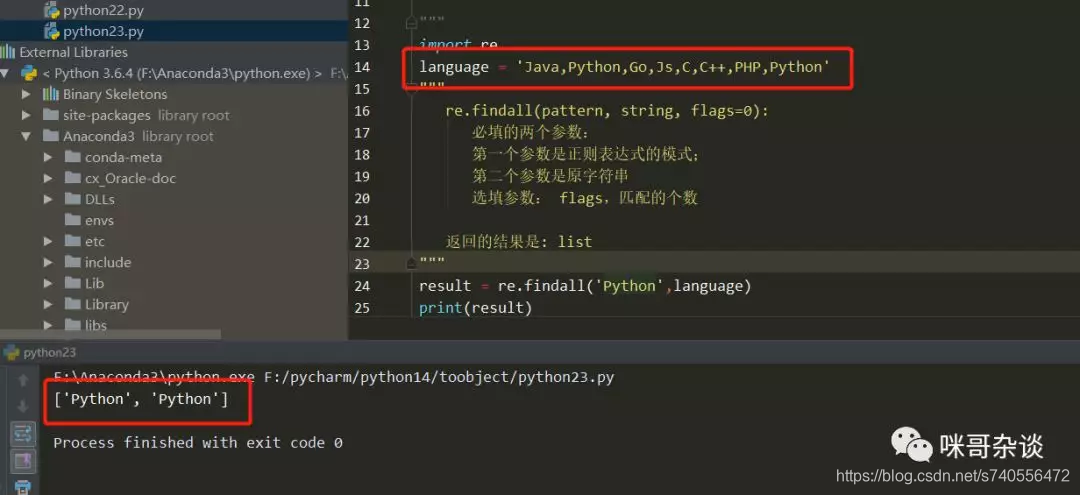
Python正则表达式的原理性概念
这个标题起的名字有些拗口,因为我找不到好的概括词语了,现在就来解释一下吧…在2中我们通过re模块来判断了一个字符串包含不包含与原始字符串,实际上这种用法是没有意义的,真正的正则表达式用法场景,应该是依赖于规则!
1.普通字符和元字符
还是举例说明,还是上边找工作的那堆语言,假设每门语言的分割,我不用逗号进行分割了,我将各种公共电话号码随机插入来代替逗号,于是得到language=“Java110Python120Go119Js4399C999C++666PHP”。
需求变更了,现在让你提取出电话号码!如何去做呢?
import re
language="Java110Python120Go119Js4399C999C++666PHP"
"""
re.findall(pattern, string, flags=0):
必填的两个参数:
第一个参数是正则表达式的模式;
第二个参数是原字符串
选填参数: flags,传入例如忽略大小写的官方参数
返回的结果是: list
"""
result = re.findall('\d',language)
print(result)
>>> ['1', '1', '0', '1', '2', '0', '1', '1', '9', '4', '3', '9', '9', '9', '9', '9', '6', '6', '6']
由于每个数字都不近相同,你可以用一堆数字去写,但是比较麻烦。若换成字符,难不成还写满了你要匹配的字符吗?所以这里提出两个概念:普通字符和元字符。
普通字符:re.findall(‘Python’,language)中的’Python’,就是普通字符。
元字符:re.findall(’\d’,language)中的’\d’,就是元字符。
所谓的普通字符,就是你写死了的固定字符,而元字符则不一样,它代表的是一类的字符,而我现在写的’\d’的含义就是匹配所有数字。需要注意的是,普通字符和元字符是在正则表达式中可以混合使用的!
而我这里不会详细的介绍每个元字符的用法,重要的是自己查阅相关文档的方法,而非死记硬背这些元字符的含义,可以用到的时候再去查即可。这里给出相关图吧,有兴趣的可以看下:


以上图片原址:
https://baike.baidu.com/item/正则表达式/1700215?fr=aladdin#3
具体使用可以自行百度查看。
2. 字符集
在上面的例子中,我们可以看到,正则表达式匹配完的list得到的都是一个个拆分的字符,而所谓的字符集就是匹配出来的字符集合,也就是多个字符。如下面的例子:
import re
words = "abz,acz,adz,aez,afz"
result = re.findall('a[bcd]z', words)
print(result)
>>> ['abz', 'acz', 'adz']
若想匹配到原字符串中的多个字符,我们可以用[]这样的形式来匹配多个符合的内容,而[]中的元素相互之间是或的关系。a,z来限定边界, [bcd] 则是匹配a,z中间符合的bcd的元素,所以最终得到的结果如上。
import re
words = "abz,acz,adz,aez,afz"
result = re.findall('a[^bcd]z', words)
print(result)
>>> ['aez', 'afz']
若在字符集的正则规定前,加上^则是代表取反的意思,可以看到结果,不匹配bcd,最终结果得到的是e,f。
当然还有一种写法是下面这样:
import re
words = "abz,acz,adz,aez,afz"
result = re.findall('a[b-e]z', words)
print(result)
>>> ['abz', 'acz', 'adz', 'aez']
用 - 也可以来表示一个范围,比如A-Z,a-z,0-9等…
3. 数量词
import re
words = "I am learning Pythonnnnnn, that 's awesome!"
result = re.findall('[a-z]{4}', words)
print(result)
>>> ['lear', 'ning', 'ytho', 'nnnn', 'that', 'awes']
在字符集的基础上,我们如果想限定多少长度的字符,可以通过{}来限定匹配字符集的长度,当我写入4的时候,可以看到从左到右,只有当相邻字符组成的长度为4时,才会被匹配到。
然而这样匹配是没有实际意义的,我现在需要的是将每个词语拆分并且匹配到,于是有了下面的写法:
import re
words = "I am learning Pythonnnnnn, that 's awesome!"
result = re.findall('[a-zA-Z]{1,11}', words)
print(result)
>>> ['I', 'am', 'learning', 'Pythonnnnnn', 'that', 's', 'awesome']
{最短匹配长度,最长匹配长度},在配合上字符集的正则写法,既可拆分出原有的单词,注意的是[a-zA-Z] 这里用到了组合的写法,匹配字符是符合大小写a-z的。
大家有没有注意到一个点,就是在数量词这里,我对原字符串进行正则匹配,取得长度是1~11位,那么在am时候就已经符合一位长度了,即字母a,为什么没有被单独匹配出来作为结果呢?这里就涉及到下面要说的正则表达式的贪婪模式与非贪婪模式了。
正则表达式的贪婪与非贪婪模式
贪婪模式:意如其名,贪婪嘛,就是要多多多!多匹配既是王道!
非贪婪模式:与贪婪模式相反呗,即少匹配就是王道!
对应上面的数量词案例时,数量词若是采用范围取长度时,则是默认使用贪婪模式,即多多匹配,所以才会看到能匹配到字符集长度多的单词。而Python默认倾向于是贪婪模式的!
1. “?” 匹配0次或者1次
在实际的应用中,我们也会遇到非贪婪的情况,即少匹配,那么如何书写呢?
import re
words = "I am learning Pythonnnnnn, that 's awesome!"
result = re.findall('[a-zA-Z]{1,11}?', words)
print(result)
>>> ['I', 'a', 'm', 'l', 'e', 'a', 'r', 'n', 'i', 'n', 'g', 'P', 'y', 't', 'h', 'o', 'n', 'n', 'n', 'n', 'n', 'n', 't', 'h', 'a', 't', 's', 'a', 'w', 'e', 's', 'o', 'm', 'e']
只需要在数量词后面加一个?即可。代表的是匹配前面的数量词0次或者1次。
特殊的小技巧:?一般可以来去掉字符后面的重复项,例如原字符串:“Pythonnnnn”,可以用 ‘Python?’ 得到Python, 这点自己可以思考并实验下。
2. “*” 匹配0次或者无限次
下面这段代码,你认为会打印出什么样的结果呢?
import re
words = "I am learning Pytho,Python,Pythonnnnnn, that 's awesome!"
result = re.findall('Pytho*', words)
print(result)
输出结果:
>>> ['Pytho', 'Pytho', 'Pytho']
因为在原字符串中匹配到o,后面就截止了。
若是这样呢:
import re
words = "I am learning Pytho,Python,Pythonnnnnn, that 's awesome!"
result = re.findall('Python*', words)
print(result)
#输出结果
>>> ['Pytho', 'Python', 'Pythonnnnnn']
匹配 * 号的前一个字符无限次,所以有多少n,就会被匹配到多少n。为什么Pytho也能被匹配到呢?因为 * 号代表的是前面的字符匹配到0次也是可以的!所以pytho也会被匹配到,这里需要注意。
3. “+” 匹配1次或者无限次
import re
words = "I am learning Pytho,Python,Pythonnnnnn, that 's awesome!"
result = re.findall('Python+', words)
print(result)
# 输出结果
>>> ['Python', 'Pythonnnnnn']
+号是匹配前面的字符至少一次,或者n次。所以不会匹配到Pytho!
4. “.” 匹配除换行符\n之外的其他所有字符
import re
words = "Python \n !@#%%$*&(%)"
result = re.findall('.', words)
print(result)
>>> ['P', 'y', 't', 'h', 'o', 'n', ' ', ' ', '!', '@', '#', '%', '%', '$', '*', '&', '(', '%', ')']
可以看到,除了\n以外的字符都匹配到了,包括空格以及其他奇怪的字符~
正则表达式组的概念
在说组之前,再来介绍一个正则的用法:
^: 匹配原字符串的首位置开始
$: 匹配原字符串的尾位置结束
如下事例:
import re
words = "110120119999"
result = re.findall('^\d{1,9}$', words)
print(result)
>>> []
因为^和$限定了原始字符串的头和尾,从原始字符串中匹配1~9位长度的数字,并且是从头到尾的去匹配,并没有长度为9的数字,所以匹配出来是空的。
正则表达式组的概念:还记得之前python的基础数据类型元组吗?正则中的组,与字符集恰好相反,字符集中匹配的字符之间是或的关系,而组中匹配的字符之间则是与的关系。
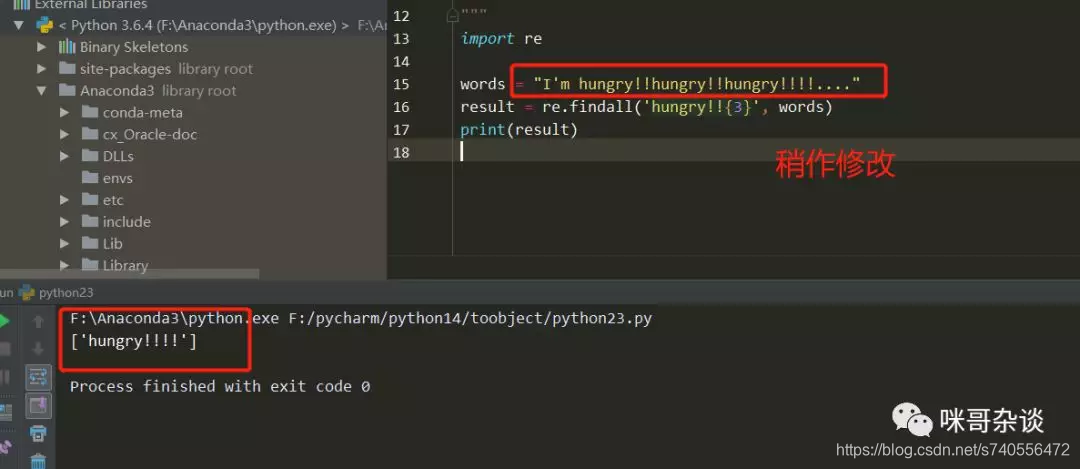
场景如下,我现在想匹配整个hungry!!而若是通过字符匹配的话方法:
import re
words = "I'm hungry!!hungry!!hungry!!...."
result = re.findall('hungry!!{3}', words)
print(result)
>>> []
可以看到,什么也没匹配到,因为现在写的意思是匹配前面是hungry!!且最后一个叹号长度为3个,也就是说如果字符串中有hungry!!!,即可匹配到。
如果想匹配到整个hungry!!并且连续的单词出现3次,就要这么写啦:
import re
words = "I'm hungry!!hungry!!hungry!!!!...."
result = re.findall('(hungry!!){3}', words)
print(result)
>>> ['hungry!!']
用小括号将整个单词括起来,它就是所谓的分组了。若我要是将{3}改成{4},就会发现,匹配不到这个结果了,因为需要组内连续出现4次才可以匹配到。如下:
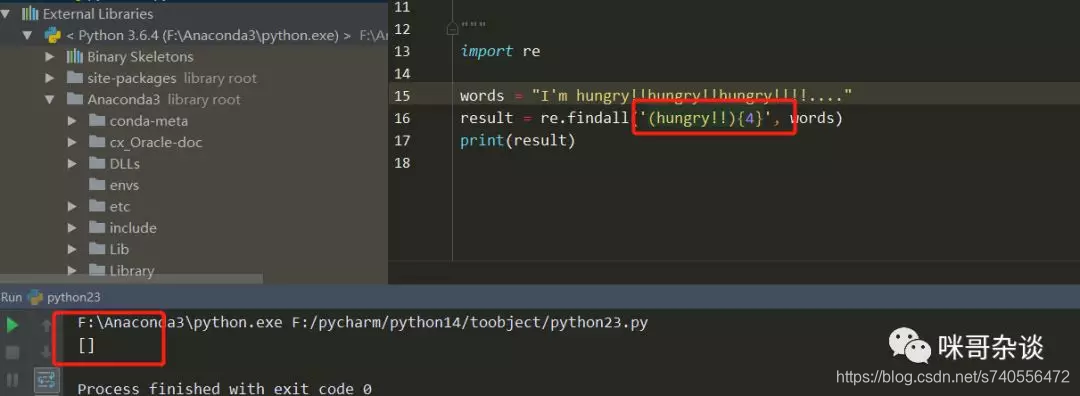
总结
今天主要介绍了python的re模块的findall方法,此方法是入门正则表达式一个比较好的学习方式,通过各种实例可以看到最终匹配到的结果,而需要注意的点是:普通字符和元字符,元字符相当于是系统的写法,每种写法代表不同的含义,在使用的时候可以将二者混合使用来达到你最终想匹配的值,现在也许看着正则还会有很多的疑惑,后续写到爬虫的时候,一讲就明白了!
至此完!
有想交流沟通python相关知识的同学,欢迎关注公号:
