这2天把python又完整地复习了一遍,做了很完整仔细的笔记,很满足,以后 忘了,看这篇文章,我就可以快速使用python了
2018.1.25上午
-----------------------------
def swap(lst,i,j):
tmp=lst[i]
lst[i]=lst[j]
lst[j]=tmp
def selection_sort(lst):
for i in range(len(lst)):
min_index=i
for j in range(i+1,len(lst)):
if lst[j]<lst[min_index]:
min_index=j
swap(lst,i,min_index)
lst=[10,3,2,8]
selection_sort(lst)
print(lst)
学习的是python3.0往后的版本
打印hello world,单引号/双引号都可以,但是必须有括号
print('hello world')
print("hello world")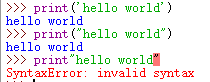
Python有5种数据类型

+加法运算

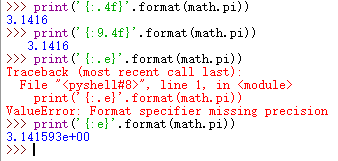
有些浮点数数在计算机中是无法精确表示的,只能近似表示,因此用浮点数表示,会有精度损失,例如
![]()
算术运算符

例子

引入模块

实际操作一下

关系运算符

逻辑运算符

判断2019年是不是闰年
(2019%4==0 and 2019%100!=0) or (2019%400==0)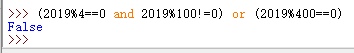
运算符的优先级

增量运算符

标识符规则

输入 input
input函数
功能:读取键盘输入,将所有输入作为字符串看待
语法:input([prompt]), [prompt]是提示符,最好提供
举例,可以看到,变量a是以字符串的形式存储在内存中的
a=input("in:")
输出print
这个开头就知道了,现在考虑如何把多个变量输出到一行呢, 用逗号 ,
看个例子

选择分支结构
score=68
gender="lady"
if score>=60:
if gender=='lady':
print("yes")
else:
print('no')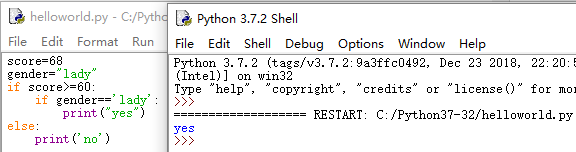
多分支结构
score=68
if score>=90:
print('A')
else:
if score>=80:
print('B')
else:
if score>=70:
print('C')
else:
if score>=60:
print('D')
else:
print('E')
![]()
其实python是有elif的,上面程序可以这样写,省的缩进会弄错
score=68
if score>=90:
print('A')
elif score>=80:
print('B')
elif score>=70:
print('C')
elif score>=60:
print('D')
else:
print('E')
看了例子,判断篮球比分是否安全

points=int(input('Leading points:'))
have_ball=input('the leading team has ball:(yes/no)')
seconds=int(input('the remaining seconds:'))
points-=3
if have_ball=='yes':
points+=0.5
else:
points-=0.5
if points<0:
points=0
points**=2
if points>seconds:
print('safe')
else:
print('not safe')
程序运行结果:

循环结构
while循环
c=0
while c<5:
print('hello')
c+=1
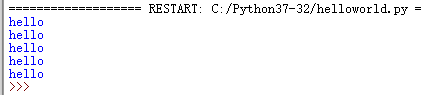
for循环
求e的值

e=1
factorial=1
for i in range(1,100):
factorial*=i
e+=1.0/factorial
print(e)
![]()
求pi的值
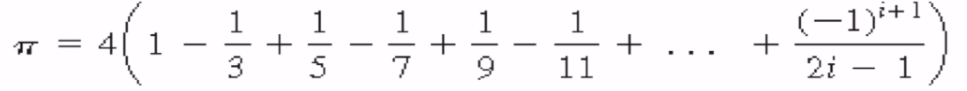
pi=0
sign=1
divisor=1
for i in range(1,10000000):
pi+=sign/divisor
sign*=-1
divisor+=2
pi*=4
print('pi is:',pi)
![]()

n=27
for n in range(1,10):
while n!=1:
if n%2==0:
n/=2
else:
n=n*3+1
print(n)
求平方根
x=2
low=0.0
high=x
guess=(low+high)/2
while abs(guess**2-x)>1e-4:
if guess**2>x:
high=guess
else:
low=guess
guess=(low+high)/2
print(guess)
![]()
判断素数
import math
n=10
for i in range(2,int(math.sqrt(n))+1):
if n%i==0:
print('the number is not a prime')
break
else:
print('the number is a prime')
![]()
打印前50个素数
import math
n=2
count=0
while count<50:
for i in range(2,int(math.sqrt(n))+1):
if n%i==0:
break
else:
print(n)
count+=1
n+=1
判断回文数
num=12321
num_p=0
num_t=num
while num!=0:
num_p=num_p*10+num%10
num=num/10
if num_t==num_p:
print('ok')
else:
print('no')
![]()
函数
def sum(start,stop):
sum=0
for i in range(start,stop+1):
sum+=i
return sum
运行结果
![]()
global
x=1
def fun():
global x
x=2
fun()
print(x)
![]()
同时判断回文数和素数
num=121
def is_palin(num):
num_p=0
num_t=num
while num!=0:
num_p=num_p*10+num%10
num=num/10
if num_t==num_p:
return True
else:
return False
def is_prime(num):
for i in range(2,int(math.sqrt(n))+1):
if n%i==0:
return False
else:
return True
if is_palin(num) and is_prime(num):
print('ok')
else:
print('no')
![]()
打印月份日历
def is_leap_year(year):
if year%4==0 and year%100!=0 or year%400==0:
return True
else:
return False
def get_num_of_days_in_month(year,month):
if month in (1,3,5,7,10,12):
return 31
elif month in(4,6,9,11):
return 30
elif is_leap_year(year):
return 29
else:
return 28
def get_total_num_of_day(year,month):
days=0
for y in range(1800,year):
if is_leap_year(y):
days+=366
else:
days+=365
for m in range(1,month):
days+=get_num_of_days_in_month(m)
return days
def get_start_day(year,month):
return (3+get_total_num_of_day(year,month))%7
def get_month_english_name(month):
if month==1:
return 'January'
elif month==2:
return 'February'
elif month==3:
return 'March'
elif month==4:
return 'April'
elif month==5:
return 'May'
elif month==6:
return 'June'
elif month==7:
return 'July'
elif month==8:
return 'August'
elif month==9:
return 'September'
elif month==10:
return 'October'
elif month==11:
return 'November'
else:
return 'December'
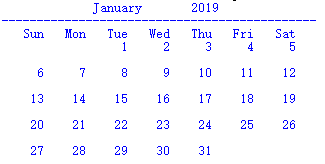
year=2019
month=1
start_weekday=get_start_day(year,month)
print("%20s" %get_month_english_name(month),end=" ")
print("%10d" %year)
print("---------------------------------------------")
print(" Sun Mon Tue Wed Thu Fri Sat ")
for i in range(0,start_weekday):
print(" ",end="")
round=start_weekday
days_of_this_month=get_num_of_days_in_month(year,month)
for j in range(1,days_of_this_month+1):
print(" %3d" %j,end="")
round+=1
if round%7==0:
print("\n")
print("\n")
程序运行结果:
递归函数
阶乘
def p(n):
if n==0 or n==1:
return 1
else:
return n*p(n-1)
print(p(3))
![]()
斐波那契数列
def fib(n):
if n==1 or n==2:
return 1
else:
return fib(n-1)+fib(n-1)
print(fib(5))
![]()
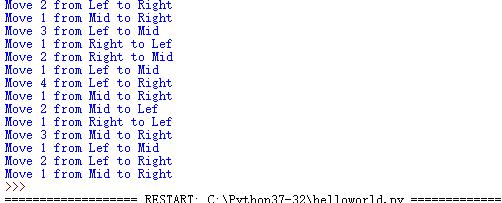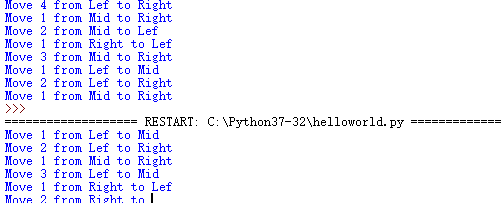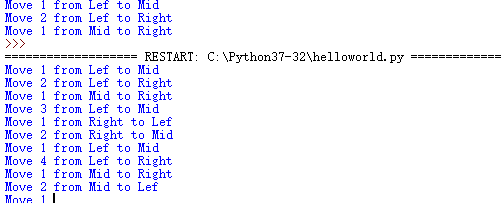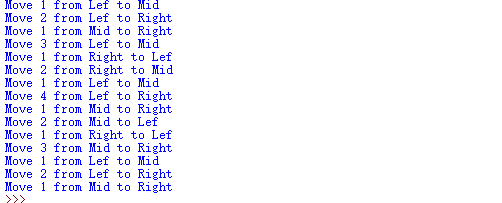
汉诺塔
def hanoi(n,A,B,C):
if n==1:
print('Move',n,'from',A,'to',C)
else:
hanoi(n-1,A,C,B)
print('Move',n,'from',A,'to',C)
hanoi(n-1,B,A,C)
hanoi(4,'Lef','Mid','Right')
这样也可以
def hanoi(n,A,B,C):
if n==0:
return
else:
hanoi(n-1,A,C,B)
print('move',n,'from',A,'to',C)
hanoi(n-1,B,A,C)
hanoi(4,'Lef','Mid','Right')

随机停车,车长为1
import random
def parking(low,high):
if high-low<1:
return 0;
else:
x=random.uniform(low,high-1)
return parking(low,x)+1+parking(x+1,high)
print(int(parking(0,5)))
import random
def parking(low,high):
if high-low<1:
return 0;
else:
x=random.uniform(low,high-1)
return parking(low,x)+1+parking(x+1,high)
s=0
time=10000
for i in range(time):
s+=parking(0,5)
print(1.0*s/time/5)
![]()

递归和循环比较
def fib_loop(n):
if n==1 or n==2:
return 1
else:
i=2
f1=1
f2=1
while(i<n):
f3=f1+f2
f1=f2
f2=f3
i+=1
return f3
print(fib_loop(100))
循环不到0.01秒
![]()
def fib_recursive(n):
if n==1 or n==2:
return 1
else:
return fib_recursive(n-1)+fib_recursive(n-2)
print(fib_recursive(100))
递归要超过1小时,不等了hhhh
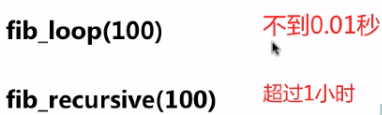
字符串
单引号或双引号,三引号都可以
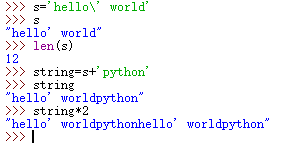
s='hello\' world'![]()
计算长度,拼接,重复
成员运算符 in,返回值是True或False,区分大小写
![]()
for语句
my_str="hello world"
for c in my_str:
print(c)

判断韵母个数
def vowels_count(s):
cnt=0
s1='aeiou'
s2='AEIOU'
for c in s:
if c in s1 or c in s2:
cnt+=1
return cnt
print(vowels_count('hello world'))
![]()
字符串索引

切片

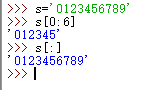
finish越界不会报错
![]()
计数参数

字符串是不可变的

replace方法

find方法

split()方法默认是根据空格划分


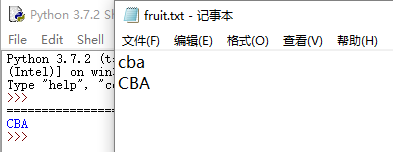
读文件
f=open('C:\\Users\\wdg\\Desktop\\fruit.txt','r')#原路径格式C:\Users\wdg\Desktop
for line in f:
line=line.strip()#去除回车空格等,正常情况下不需要
#print(line.title()) 首字符大写,其余小写
print(line)
f.close()
写文件
f=open('C:\\Users\\wdg\\Desktop\\fruit.txt','w')#原路径格式C:\Users\wdg\Desktop
s='hello python'
f.write(s)
f.close()

判断字符串是否回文
def is_palindrome(name):
low=0
high=len(name)-1
while low<high:
if name[low]!=name[high]:
return False
low+=1
high-=1
return True
print(is_palindrome('aba'))
![]()
递归版判断字符串是否回文
def is_palindrome_rec(name):
if len(name)<=1:
return True
else:
if name[0]!=name[-1]:
return False
else:
return is_palindrome_rec(name[1:-1])
print(is_palindrome_rec('aba'))
字符串比较

判断一个名字是否升序
def is_ascending(name):
p=name[0]
for c in name:
if p>c:
return False
p=c
return True
print(is_ascending('abc'))
递归版本
def is_ascending(string):
if len(string) < 2:
return True
if string[0] > string[1]:
return False
else:
return is_ascending(string[1:])
print(is_ascending('abc'))
字符串格式化
正则表达式

区分大小写的
import re
f=open('C:\\Users\\wdg\\Desktop\\fruit.txt','r')#原路径格式C:\Users\wdg\Desktop
pattern='(C.A)'
for line in f:
line=line.strip()#去除回车空格等,正常情况下不需要
result=re.search(pattern,line)
if result:
print('{}'.format(line))
f.close()
程序运行结果
列表

列表与字符串的相同点和不同点


remove是删除对应元素

列表计算平均数
nums=[]
N=3
for i in range(N):
nums.append(float(input()))
s=0
for num in nums:
s+=num
avg=s/N
print(avg)
使用内建函数sum,还有max和min等
nums=[]
N=3
for i in range(N):
nums.append(float(input()))
avg=sum(nums)/len(nums)#内建函数
print(avg)
列表赋值

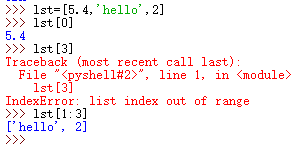
列表的查找,index也可以,如果没有查找到元素,会报错

def search(lst,x):
for i in range(len(lst)):
if lst[i]==x:
return i
return -1
lst=[1,2,3,9]
print(search(lst,8))
时间复杂度介绍


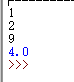
列表的二分查找
def bi_search(lst,x):
low=0
high=len(lst)-1
while low<=high:
mid=int((low+high)/2)
if lst[mid]==x:
return mid
elif lst[mid]>x:
high=mid-1
else:
low=mid+1
return -1
lst=[1,2,3,6,9]
print(bi_search(lst,9))
选择排序
def swap(lst,i,j):
tmp=lst[i]
lst[i]=lst[j]
lst[j]=tmp
def selection_sort(lst):
for i in range(len(lst)):
min_index=i
for j in range(i+1,len(lst)):
if lst[j]<lst[min_index]:
min_index=j
swap(lst,i,min_index)
lst=[10,3,2,8]
selection_sort(lst)
print(lst)
冒泡排序
def swap(lst,i,j):
tmp=lst[i]
lst[i]=lst[j]
lst[j]=tmp
def bubble_sort(lst):
top=len(lst)-1
is_exchange=True
while is_exchange:
is_exchange=False
for i in range(top):
if lst[i]>lst[i+1]:
is_exchange=True
swap(lst,i,i+1)
top-=1
lst=[10,3,2,8]
bubble_sort(lst)
print(lst)

内建排序函数

嵌套列表
students=[['zhang',84],['wang',77]]
s=0
for stu in students:
s+=stu[1]
print(float(s)/len(students))
列表解析或推导

students=[['zhang',84],['wang',77]]
print(float(sum([x[1] for x in students]))/len(students))
分数排序
students=[['zhang',77],['wang',99]]
def f(a):
return a[1]
students.sort(key=f,reverse=False)
print(students)
![]()
lambda 函数 匿名函数

students=[['zhang',77],['wang',99]]
students.sort(key=lambda x:x[1],reverse=False)
print(students)
元组






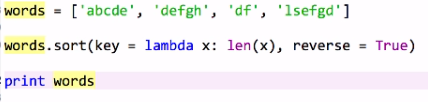
字典




my_dict={'john':1,'Bob':2,'Mike':3}
print(my_dict['Bob'])
my_dict['Wang']=4
print(my_dict['Wang'])
print(my_dict)
print(len(my_dict))
print('Tom' in my_dict)

字母计数
s='abcd'
lst=[0]*26
for i in s:
lst[ord(i)-97]+=1
print(lst)
![]()
使用字典
s='abcd'
d={}
for i in s:
if i in d:
d[i]+=1
else:
d[i]=1
print(d)
![]()
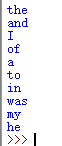
单词统计,统计《简爱》英文小说第一章的频率前10的单词
f=open('C:\\Users\\wdg\\Desktop\\Jane.txt','r')#原路径格式C:\Users\wdg\Desktop
word_freq={}
for line in f:
words=line.strip().split()
for word in words:
if word in word_freq:
word_freq[word]+=1
else:
word_freq[word]=1
freq_word=[]
for word,freq in word_freq.items():
freq_word.append((freq,word))
freq_word.sort(reverse=True)
for freq,word in freq_word[:10]:
print(word)
f.close()
字典反转,统计房间里有哪些人
d1={'zhang':123,'wang':456,'Li':123,'zhao':456}
d2={}
for name,room in d1.items():
if room in d2:
d2[room].append(name)
else:
d2[room]=[name]
print(d2)
![]()
字典


集合的运算符


中文分词

补充遇到的小问题,python2中的unicode()函数在python3中会报错:NameError: name 'unicode' is not defined
There is no such name in Python 3, no. You are trying to run Python 2 code in Python 3. In Python 3, unicode has been renamed to str.
翻译过来就是:Python 3中没有这样的名字,没有。 您正在尝试在Python 3中运行Python 2代码。在Python 3中,unicode已重命名为str。
函数转换:unicode()到 str()为:
//python2:
unicode(nn,'utf-8')
//python3:
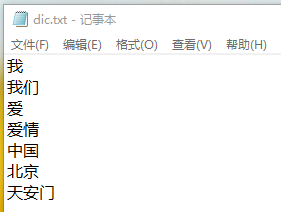
str(nn)filename='C:\\Users\\wdg\\Desktop\\dic.txt'
def load_dict(filename):
word_dict=set()
max_len=1
f=open(filename)
for line in f:
word=str(line.strip())
word_dict.add(word)
if len(word)>max_len:
max_len=len(word)
f.close()
return max_len,word_dict
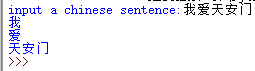
def fmm_word_seg(sent,max_len,word_dict):
begin=0
words=[]
sent=str(sent)
while begin< len(sent):
for end in range(begin+max_len,begin,-1):
if sent[begin:end] in word_dict:
words.append(sent[begin:end])
break
begin=end
return words
max_len, word_dict=load_dict(filename)
sent=input('input a chinese sentence:')
words=fmm_word_seg(sent,max_len,word_dict)
for word in words:
print(word)