版权声明:随意转载,请勿商用。转载请注明出处,谢谢。 https://blog.csdn.net/xinhongyang/article/details/86647294
下文摘选自书籍Java8 实战 仅做笔记用,如有不清楚的地方,请参考原书。
顺序流转换为并行流
并行流内部使用了默认的ForkJoinPool,它默认的线程数量就是你的处理器数量,这个值是由Runtime.getRuntime().available- Processors()得到了。
stream.parallel() //并行执行
.filter(...)
.sequential() //顺序执行
.map(...)
.parallel() //并行执行
.reduce();
Tips
- 注意自动拆装箱,尽量使用数值特化流。
- 依赖于元素顺序的操作在并行流上代价比较大。
- 一个元素通过流水线的成本越大,使用并行流时性能好的可能性比较大。
- 较小的数据量不要用并行流,开销太大。
- 要看数据结构是否易于分解。
- 合并的代价也要考虑在内。

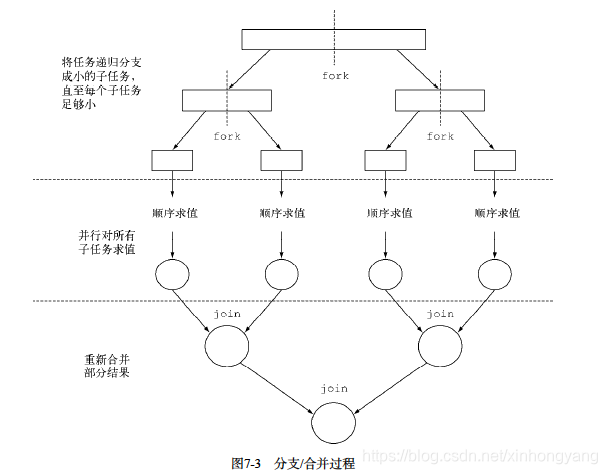
分支/合并框架
目的:将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。下图展示了fork-join的全过程。
RecursiveTask
要把任务提交到ForkJoinPool中,必须创建RecursiveTask<R>的一个子类。其中R是并行化任务产生的结果类型。如果任务不返回结果,则是RecursiveAction类型。
要定义RecursiveTask,需要实现它唯一的抽象方法compute:
protected abstract R compute();
这个方法同时定义了将任务拆分成子任务的逻辑,以及无法再拆分或不方便再拆分的售后,生成单个子任务结果的逻辑。
方法的实现类似下图:

下图展示了一个实现RecursiveTask<R>的例子:

使用方法很简单,就是构造一个ForkJoinSumCalculator,然后调用ForkJoinPool的invoke方法,把task传进去。
Tips
- 对一个任务调用join方法会阻塞调用方,应该在两个任务的计算都开始后再调用它。
- 不应该在
RecursiveTask内部使用ForkJoinPool的invoke方法。应该直接调用compute或fork方法。 - 复用父线程,只把一个子任务调用
fork方法
工作窃取
当某个线程下的任务完成后,会去其他队列尾去取任务进行工作。是一种消费者自行进行平衡负载的方式。
Spliterator
Java8中并行流使用的自动拆分流的机制。这个名字代表了“可分迭代器”。接口定义了若干方法,代码如下:
//T是遍历的元素的类型
public interface Spliterator<T>{
/**
* 类似于普通的Iterator,因为它会按顺序一个一个使用Spliterator中的元素,如果还有其他元素要遍历就返回true。
**/
boolean tryAdvance(Consumer<? super T> action);
/**
* 把一些元素划分出去分给第二个Spliterator(由该方法返回),让它们两个并行处理。
**/
Spliterator<T> trySplit();
/**
* 估计还有多少元素要遍历,不准确
**/
long estimateSize();
/**
* 返回当前Spliterator的特性
**/
int characteristics();
}
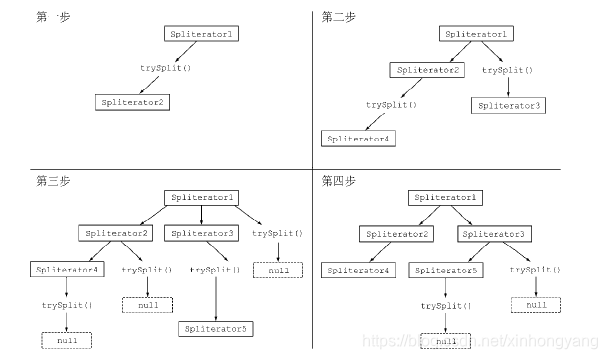
拆分流程
不停的拆分,知道它处理的数据结构不能在分割,这个时候就会返回null。
Spliterator的特性
