版权声明:转载请注明出处 https://blog.csdn.net/nanhuaibeian/article/details/86619575
1. 观察页面存在二级目录
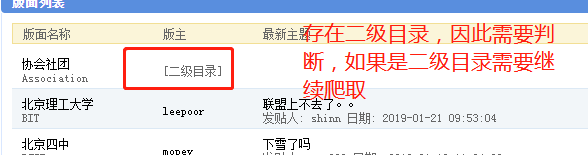

由此编写判断条件
#判断是否为二级目录
if len(columns[1].xpath('a')) == 0:
url = self.domain + board['url']
r = requests.get(url, headers=self.headers)
children_boards = self.get_board_list(r.text)
boards += children_boards
2. 代码实现
import requests
import re
from lxml import etree
class BoardListCrawler:
headers = {
'Accept': "*/*",
'Accept-Encoding': "gzip, deflate",
'Accept-Language': "zh-CN,zh;q=0.9",
'Connection': "keep-alive",
'Host': "www.newsmth.net",
'Referer': "http://www.newsmth.net/nForum/",
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36",
'X-Requested-With': "XMLHttpRequest",
'cache-control': "no-cache",
}
domain = "https://www.newsmth.net"
base_url = domain + "/nForum/section/{}?ajax"
def get_content(self,page_number):
#format函数参考:https://blog.csdn.net/nanhuaibeian/article/details/86591202
url = self.base_url.format(page_number)
response = requests.get(url,headers= self.headers)
return response.text
def get_board_list(self,content):
boards = []
tree = etree.HTML(content)
rows = tree.xpath("//table[@class='board-list corner']/tbody/tr")
# print(rows[0])
for row in rows:
board = {}
columns = row.xpath('td')
board['url'] = columns[0].xpath('a')[0].attrib['href']
board['title'] = columns[0].xpath('a')[0].text
#判断是否为二级目录
if len(columns[1].xpath('a')) == 0:
url = self.domain + board['url']
r = requests.get(url,headers = self.headers)
children_boards = self.get_board_list(r.text)
boards += children_boards
board['num_topics'] = columns[5].text
board['num_posts'] = columns[6].text
boards.append(board)
return boards
if __name__ =='__main__':
blc = BoardListCrawler()
#版面是0-9
for i in range(0,10):
c = blc.get_content(i)
boards = blc.get_board_list(c)
print(boards)