| URI Uniform Resource Identifier |
统一资源标志符 |
|---|---|
| URL Universal Resource Locator |
统一资源定位符 |
| URN Universal Resource Name |
统一资源名称 只命名资源不指定如何定位 |
URI=URL+URN
URL是URI的子集,就是每个URL都是URI,但不是每个URI都是URL
访问资源协议类型
| HTTP Hyper Text Transfer Protocol |
超文本传输协议 | 用于从网络传输超文本数据到本地浏览器的传送协议, 能保证高效而准确地传送超文本文档 |
|---|---|---|
| HTTPS Hyper Text Transfer Protocol over Secure Socket Layer |
以安全为目标的HTTP通道,即HTTP下加入SSL层 通过此传输内容都是经过SSL加密的 |
使用google浏览器 以百度网站为例
【右键】-> 【inspect】-> 选择Network
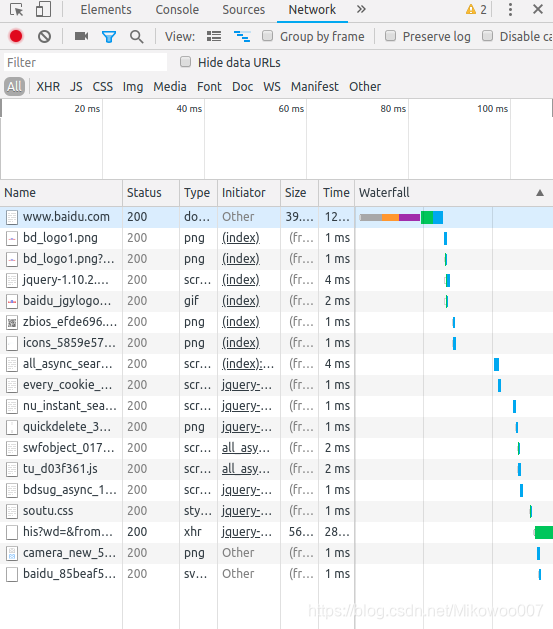
| Name | 请求的名称 |
|---|---|
| Status | 相应的状态码 |
| Type | 请求的文档类型 |
| Initiator | 请求源 |
| Size | 从服务器下载和请求的资源大小 |
| Time | 发起请求到获取影响所用的时间 |
| Waterfall | 网络请求的可视化瀑布流 |
点击条目,可看更详细的信息
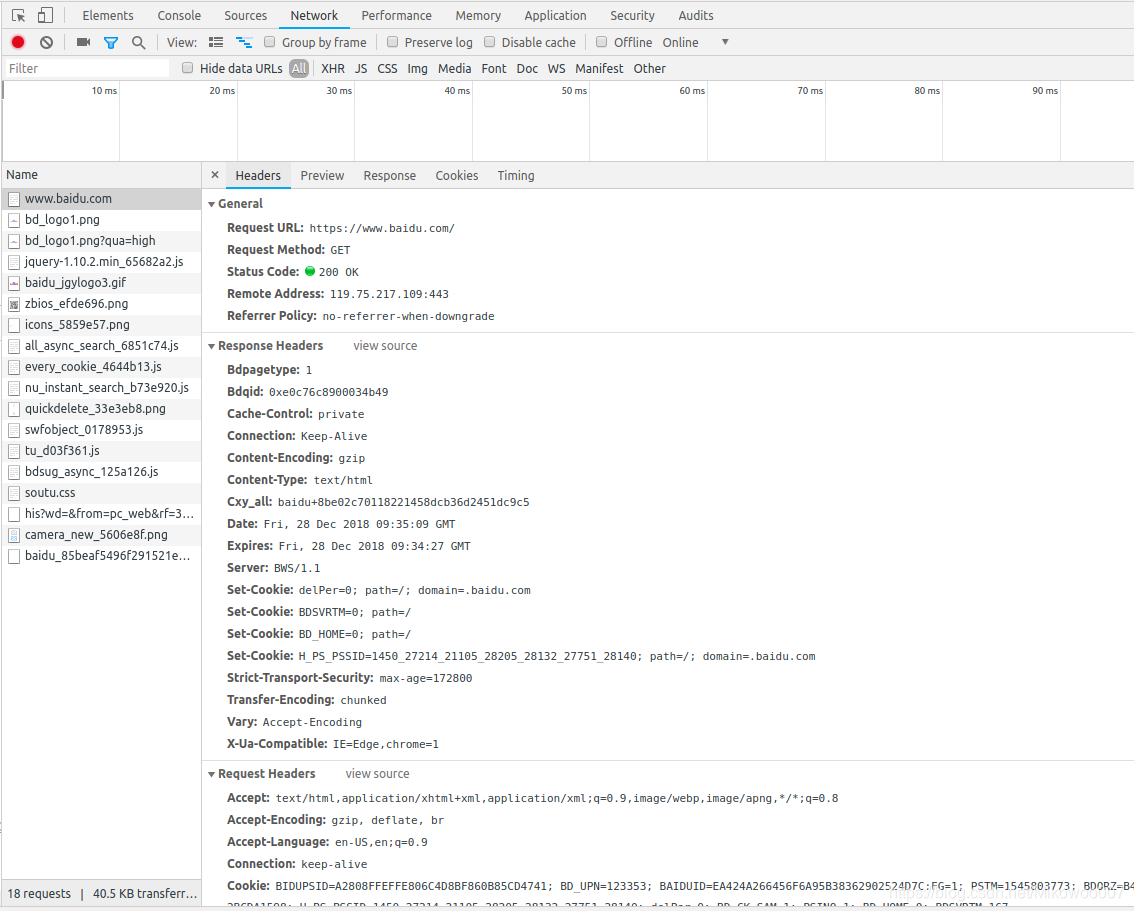
| Request URL | 请求的URL |
|---|---|
| Request Method | 请求的方法 |
| Status Code | 响应状态码 |
| Romote Address | 远程服务器的地址和端口 |
| Referrer Policy | Referrer判别策略 |
请求方法(Request Method)
| Get | 请求中的参数包含在URL里,数据可以在URL中看到 请求提交的数据最多只有1024字节,易造成密码泄露 |
|---|---|
| Post | 请求的URL不会包含数据,数据都是通过表单形式传输的,会包含在请求体中 该方法没有限制,有一定的加密效果 |
| HEAD | 类似GET请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| PUT | 从客户端向服务器传送的数据取代文档中内容 |
| DELETE | 请求服务器删除指定的页面 |
| CONNECT | 把服务器作为跳板,让服务器代替客户端访问其他网页 |
| OPTIONS | 允许客户端查看服务的性能 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
请求头(Request Headers)
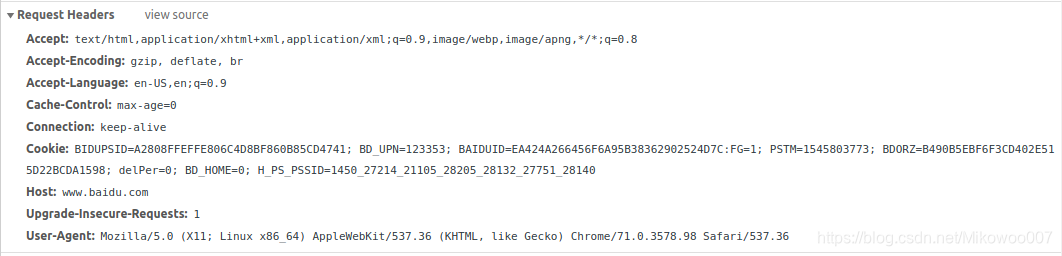
| Accept | 请求报头域,用于指定客户端可接受哪些类型的信息 |
|---|---|
| Accept-Encoding | 指客户端可接受的内容编码 |
| Accept-Language | 指客户端可接受的语言类型 |
| Cookie | 网站为了辨别用户进行会话跟踪而存储在用户本地的数据 主要是维护当前访问会话 |
| Host | 用于指定请求资源的主机IP和端口号, 其内容为请求URL的原始服务器或网关的位置 |
| User-Agent | 简称UA,是一个特殊的字符串头, 可以使用服务器识别客户使用的操作系统及版本、浏览器及版本等信息 |
| Referer | 此内容用来标识这个请求是从哪个页面发过来的, 服务器可以拿到这一信息病做相应的处理 |
| Content-Type | 叫互联网媒体类型(Internet Media Type)或者MIME类型, 在HTTP协议消息头中,它用来标识具体请求中的媒体类型信息 |
请求体 (Request Body)
请求体一般承载的内容是POST请求中的表单数据,而对于GET请求,请求体则为空
响应状态码(Response Status Code)
| 状态码 | 说明 | 详情 |
|---|---|---|
| 100 | 继续 | 请求者应当继续提出请求 服务器已收到请求的一部分,正在等待其余部分 |
| 101 | 切换协议 | 请求者已要求服务器切换协议,服务器已确认病准备切换 |
| 200 | 成功 | 服务器已成功处理了请求 |
| 201 | 已创建 | 请求成功并且服务器创建了新的资源 |
| 202 | 已接受 | 服务器已接受请求,但尚未处理 |
| 203 | 非授权信息 | 服务器已处理了请求,但返回的信息可能来自另一个源 |
| 204 | 无内容 | 服务器成功处理了请求,但没有返回任何内容 |
| 205 | 重置内容 | 服务器成功处理了请求,内容被重置 |
| 206 | 部分内容 | 服务器成功处理了部分请求 |
| 300 | 多种选择 | 针对请求,服务器可执行多种操作 |
| 301 | 永久移动 | 请求的网页已永久移动到新位置,即永久重定向 |
| 302 | 临时移动 | 请求的网页暂时跳转到其他页面,即暂时重定向 |
| 303 | 查看其他位置 | 如果原来的请求是POST,重定向目标文档应该通过GET提取 |
| 304 | 未修改 | 此次请求返回的网页未修改,继续使用上次的资源 |
| 305 | 使用代理 | 请求者应该使用代理访问该网页 |
| 307 | 临时重定向 | 请求的资源临时从其他位置响应 |
| 400 | 错误请求 | 服务器无法解析该请求 |
| 401 | 未授权 | 请求没有进行身份验证或验证未通过 |
| 403 | 禁止访问 | 服务器拒绝此请求 |
| 404 | 未找到 | 服务器找不到请求的网页 |
| 405 | 方法禁用 | 服务器禁用了请求中指定的方法 |
| 406 | 不接受 | 无法使用请求的内容响应请求的网页 |
| 407 | 需要代理授权 | 请求者需要使用代理授权 |
| 408 | 请求超时 | 服务器请求超时 |
| 409 | 冲突 | 服务器在完成请求时发生冲突 |
| 410 | 已删除 | 请求的资源已永久删除 |
| 411 | 需要有效长度 | 服务器不接受不含有效内容长度标头字段的请求 |
| 412 | 未满足前提条件 | 服务器未满足请求者在请求中设置的其中一个前提条件 |
| 413 | 请求实体过大 | 请求实体过大,超出服务器的处理能力 |
| 414 | 请求URI过长 | 请求网址过长,服务器无法处理 |
| 415 | 不支持类型 | 请求格式不被请求页面支持 |
| 416 | 请求范围不符 | 页面无法提供请求的范围 |
| 417 | 未满足期望值 | 服务器未满足期望请求标头字段的要求 |
| 500 | 服务器内部错误 | 服务器遇到错误,无法完成请求 |
| 501 | 未实现 | 服务器不具备完成请求的功能 |
| 502 | 错误网关 | 服务器作为网关或代理,从上游服务器收到无效响应 |
| 503 | 服务不可用 | 服务器目前无法使用 |
| 504 | 网关超时 | 服务器作为网关或代理,但是没有及时从上游服务器收到请求 |
| 505 | HTTP版本不支持 | 服务器不支持请求者所用的HTTP协议版本 |
响应头 (Response Header)
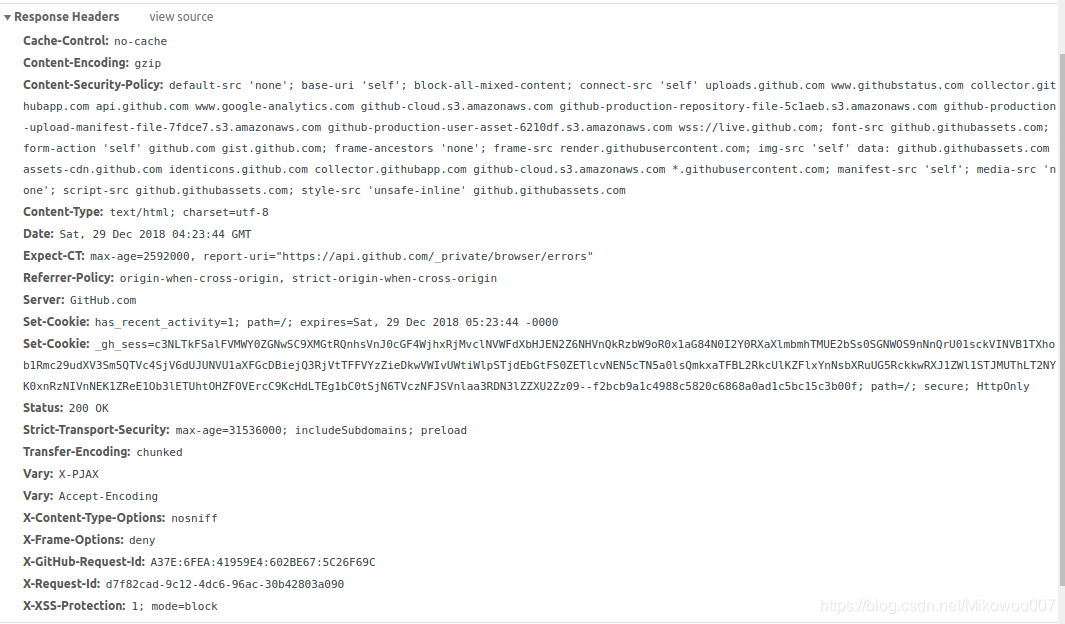
| Date | 标识响应产生的时间 |
|---|---|
| Last-Modified | 指定资源的最后修改时间 |
| Content-Encoding | 指定响应内容的编码 |
| Server | 包含服务器的信息,如名称、版本号 |
| Content-Type | 指定返回的数据类型 |
| Set-Cookie | 设置Cookies 响应头中的Set-Cookie告诉浏览器需要将此内容放在Cookies中,下次请求携带Cookies请求 |
| Expires | 指定响应的过期时间,可以使代理服务器或浏览器将加载的内容更新到缓存中 |
响应体(Response Body)
响应的正本数据都在响应体中,爬虫请求网页后,要解析的内容就是响应体