1. 背景
虽然C++标准库提供了很多容器以供使用,但是实际上有时候其不能很好地满足一些较为特殊的需求,这时就需要自定义一些容器以满足实际的需要。在自定义一个容器之前,有必要先了解STL。因为STL中提供的容器的完备而优秀的设计,是容器代码的最好范本。
2. STL六大组件
- 容器(containers):各种数据结构,如vector,list,deque,set,map等,用来存放数据。从实现的角度看,STL容器是一种class template;
- 算法(algorithms): 各种常用算法如sort,search,copy,erase等。从实现角度看,STL算法是一种function template;
- 迭代器(iterators):扮演容器与算法之间的胶合剂,是所谓的“泛型指针”,详见第3章,共有五种类型,及其衍生变化。从实现的角度看,迭代器是一种将operator*,operator->,operator++,operator– 等指针相关操作予以重载的class template。所有STL容器都附带有自己专属的迭代器——容器设计者将遍历自己元素的逻辑封装于此。原生指针(native pointer)也是一种迭代器;
- 仿函数(functors):行为类似函数,可作为算法的某种策略(policy),详见第7章,从实现的角度看,仿函数是一种重载了operator()的class或者class template,一般函数指针可视为狭义的仿函数。
- 配接器(adapters):一种用来修饰容器(containers)或仿函数(functors)或迭代器(iterators)接口的东西。例如,STL提供的queue和stack,虽然看似容器,其实只能算是一种容器适配器,因为他们的底层完全借助deque实现。改变functor接口者,称为function adapter;改变container接口者,称为container adapter;改变iterator接口者,称为iterator adapter;
- 配置器(allocators):负责空间配置与管理。从实现的角度来看,配置器是一个实现了动态空间配置、空间管理、空间释放的class template。
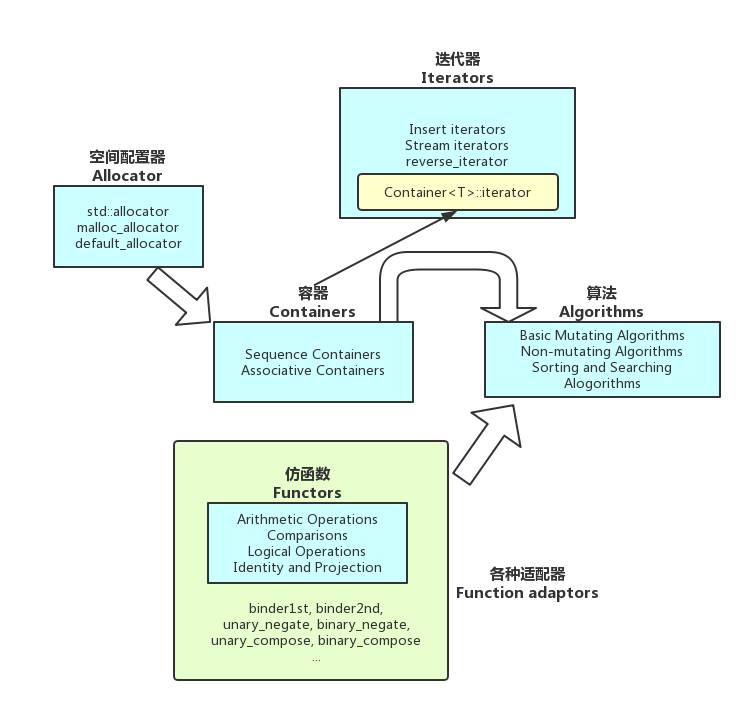
STL六大组件之间的交互关系:Container通过Allocator取得数据储存空间,Algorithm通过Iterator存取Container内容,Functor可以协助Algorithm完成不同的策略变化,Adapter可以修饰或套接Functor。
3. LinkedHashMap
Java中提供了LinkedHashMap,能使得遍历的顺序和插入数据的顺序保持一致,但是C++标准库没有提供,考虑基于JDK的LinkedHashMa的实现思路,实现C++版本的LinkedHashMap。
3.1 底层实现原理
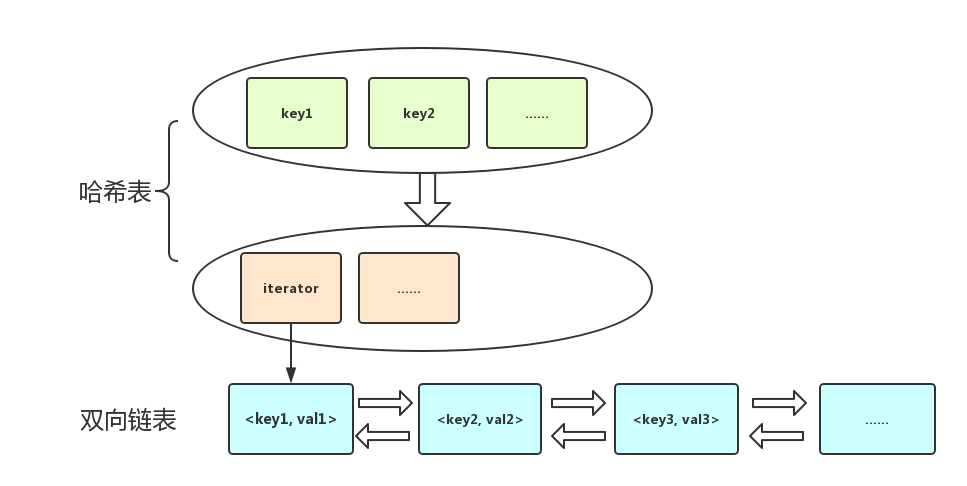
- 在双向链表(
std::list)中存放实际的KV对; - 在哈希表(
std::unordered_map)中存放Key到双向链表中的相应位置迭代器的映射。
这么设计的目的是,在插入和遍历时,可以利用利用双向链表的灵活性,进行随机地插入元素,同时因其迭代器永不失效,所以可以作为哈希表中的value;查找时可以利用哈希表的特性,基于关键字key做平均常数时间复杂度的快速查找。
3.2 技术实现
3.2.1 类声明
C++11后提供了哈希表的实现,clang中标准库 std::unorder_map 的声明如下:
template <class _Key, class _Tp,
class _Hash = hash<_Key>,
class _Pred = equal_to<_Key>,
class _Alloc = allocator<pair<const _Key, _Tp> > >
class _LIBCPP_TEMPLATE_VIS unordered_map
{
...
}可见实例化一个哈希表时,需要关注的几个模板参数是:
1. 键值的类型,即 _key ;
2. 映射值的类型,即 _Tp ;
3. 哈希functor,即 _Hash ;
4. 比较functor,即 _Pred ;
5. 空间配置器,即 _Alloc ;
通常来说提供前四个参数就可以满足绝大多数需求,那么 LinkedHashMap 的声明可以写成:
template <class KeyType, class MappedType,
class Hash = std::hash<KeyType>,
class Pred = std::equal_to<KeyType> >
class LinkedHashMap
{
...
}3.2.2 成员类型
首先因为每个容器都应提供自己的迭代器类型,所以需要重定义 LinedHashMap::iterator ,同时因为KV对是经常操作的一个数据结构,所以将 <Key, Value> 定义为一个类型:
public:
/**
* @brief 保存的entry的类型
*
**/
typedef std::pair<const KeyType, MappedType> EntryType;
/**
* @brief list中的非const迭代器类型
*
**/
typedef typename std::list<EntryType>::iterator iterator;
/**
* @brief list中的const迭代器类型
*
**/
typedef typename std::list<EntryType>::const_iterator const_iterator;实际上,定义成员类型通常是必要的,因为有时需通过这种方式获取某个类的内嵌依赖类型名(nested dependent type name),其中内嵌指的是内嵌是指定义在类名的定义中的,而依赖指的是依赖于一个模板参数,例如上面的 EntryType 依赖于模板参数 KeyType 和 MappedType 。
3.2.3 成员变量
如3.1所示,底层需要借助双向链表( std::list )和哈希表( std::unordered_map )来实现 LinkedHashMap ,所以这二者需要作为成员变量,另外为了方便处理,需要记录当前元素数量,具体如下:
private:
typedef std::unordered_map<KeyType, iterator, Hash, Pred> HashMap;
typedef typename HashMap::iterator _map_itr;
typedef typename HashMap::const_iterator _map_citr;
/**
* @brief entry的数量
*
**/
size_t _size;
/**
* @brief 实际存放entry的双向链表
*
**/
std::list<EntryType> _values;
/**
* @brief 保存key到entry的hashmap
*
**/
HashMap _map_key2entry;这里定义的三个成员类型是方便内部实现的,容器使用者不可见。
3.2.4 成员方法
除了构造函数和析构函数,一个容器最基础的功能是进行插入,遍历,查找和删除,下面分别进行说明:
1. 插入数据
/**
* @brief 在map中插入一个新entry
*
* @param [in] new_entry : 待添加的entry
**/
std::pair<iterator, bool> insert(const EntryType& new_entry) {
_map_itr pIt = _map_key2entry.find(new_entry.first);
if (pIt == _map_key2entry.end()) {
_values.push_back(new_entry);
_map_key2entry.insert(std::pair<KeyType, iterator>(new_entry.first, --_values.end()));
++_size;
}
else {
_values.erase(pIt->second);
_values.push_back(new_entry);
pIt->second = --_values.end();
}
return std::pair<iterator, bool>(--_values.end(), true);
}
/**
* @brief 在map中指定位置插入一个新entry
*
* @param [in] new_entry : 待添加的entry
* @note Since C++11
**/
iterator insert(const_iterator it, const EntryType& new_entry) {
_map_itr pIt = _map_key2entry.find(new_entry.first);
if(pIt != _map_key2entry.end()) {
_values.erase(pIt->second);
--_size;
}
iterator _it = _values.insert(it, new_entry);
_map_key2entry.insert(std::pair<KeyType, iterator>(new_entry.first, _it));
++_size;
return _it;
}提供两种最常用的插入函数,分别是插入一个KV对,及在指定迭代器处插入一个KV对。
2. 遍历
/**
* @brief 获取首元素的迭代器
*
* @param [in] null
**/
inline iterator begin() {
return _values.begin();
}
/**
* @brief 获取首元素的const迭代器
*
* @param [in] null
**/
inline const_iterator begin() const {
return _values.begin();
}
/**
* @brief 获取尾元素的迭代器
*
* @param [in] null
**/
inline iterator end() {
return _values.end();
}
/**
* @brief 获取尾元素的const迭代器
*
* @param [in] null
**/
inline const_iterator end() const {
return _values.end();
}提供普通迭代器和常迭代器。实际上,如果编译器支持C++11,那么可以直接使用 for (auto entry : LinkedHashmap) 这种范围for语句来遍历。
3. 查找
/**
* @brief 在map中查找元素,如存在则返回其迭代器,否则返回end()
*
* @param [in] key : 指定的键值
**/
iterator find(const KeyType& key) {
if (_size > 0) {
_map_itr it = _map_key2entry.find(key);
if (it == _map_key2entry.end()) {
return _values.end();
}
iterator find_it = it->second;
return find_it;
}
return _values.end();
}
/**
* @brief find()的const版本
*
* @param [in] key : 指定的键值
**/
const_iterator find(const KeyType& key) const {
if (_size > 0) {
_map_citr it = _map_key2entry.find(key);
if (it == _map_key2entry.end()) {
return _values.end();
}
const_iterator find_it = it->second;
return find_it;
}
return _values.end();
}提供普通查找函数,区别是返回的一个是普通迭代器,一个是常量迭代器。
4. 删除
/**
* @brief 移除位于pos处的entry
*
* @param [in] pos : 指定位置的迭代器
**/
void erase(iterator pos) {
assert(pos != _values.end());
assert(_size != 0);
EntryType v = *pos;
_values.erase(pos);
_map_key2entry.erase(v.first);
--_size;
}
/**
* @brief 移除指定键值的entry
*
* @param [in] key : 指定的键值
**/
void erase(const KeyType& key) {
iterator it = find(key);
if (it != _values.end()) {
erase(it);
}
}
/**
* @brief 清空所有entry
*
* @param [in] null
**/
void clear() {
_values.clear();
_map_key2entry.clear();
_size = 0;
}提供两种删除函数,分别是指定迭代器位置删除和指定键值删除。同时提供一个清空函数,能够清空该map。
5. 容量
/**
* @brief 返回entries的数量
*
* @param [in] null
**/
inline size_t size() {
return _size;
}
/**
* @brief 获取该map是否为空
*
* @param [in] null
**/
inline bool empty() const {
return _values.empty();
}提供两个函数,方便用户获取容器的当前元素数量和是否为空。
3.3 性能测试
构造100万个std::pair
3.3.1 插入时间
| 序号 | std::unordered_map 插入元素 (ms) | LinkedHashMap 插入元素 (ms) | 插入时间占比 |
|---|---|---|---|
| 1 | 1112.26 | 1385.78 | 124.5913725 |
| 2 | 991.994 | 1294.81 | 130.5259911 |
| 3 | 1001.36 | 1333.16 | 133.1349365 |
| 4 | 983.257 | 1316.26 | 133.8673409 |
| 5 | 1083.24 | 1397.9 | 129.0480411 |
| 平均 | 1034.4222 | 1345.582 | 130.2335364 |
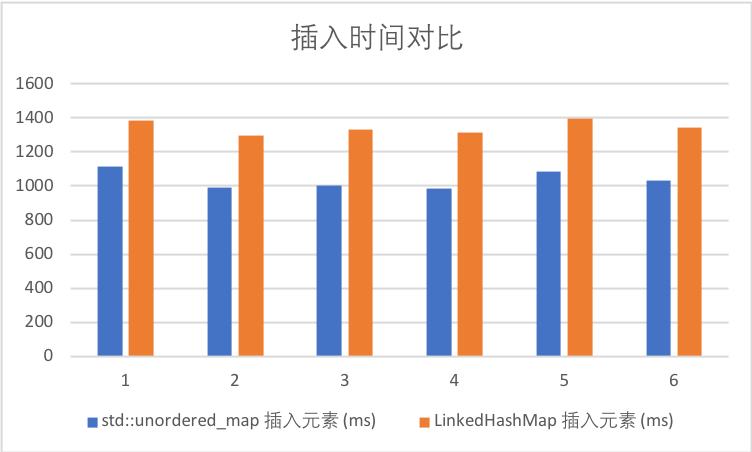
可以看到插入时间相比 std::unordered_map 大约有30%的性能损失。
3.3.2 遍历时间
| 序号 | std::unordered_map 遍历 (ms) | LinkedHashMap 遍历 (ms) | 遍历时间占比 |
|---|---|---|---|
| 1 | 62.959 | 25.526 | 40.543846 |
| 2 | 63.014 | 24.585 | 39.01513949 |
| 3 | 62.48 | 25.136 | 40.23047375 |
| 4 | 63.413 | 25.07 | 39.53448031 |
| 5 | 67.074 | 26.71 | 39.82168948 |
| 平均 | 63.788 | 25.4054 | 39.82912581 |
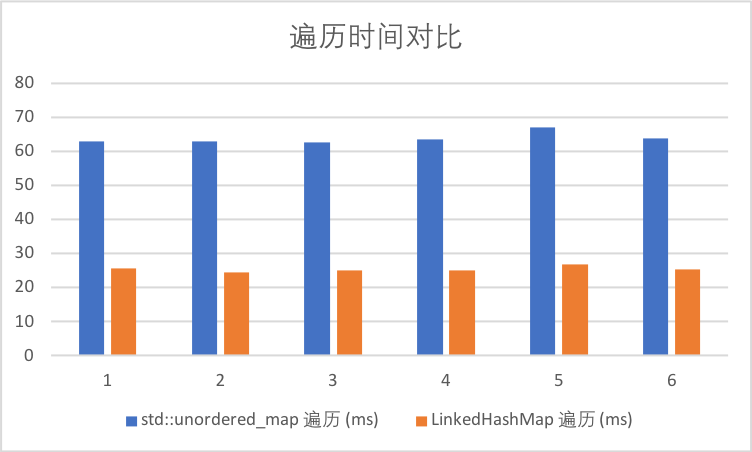
顺序遍历的时间下降到std::unordered_map的40%左右,即速度提高了2.5倍左右;同时LinkedHashMap能够保证遍历的顺序同插入的顺序一致。
3.3.3 随机访问时间
| 序号 | std::unordered_map 随机访问 (ms) | LinkedHashMap 随机访问 (ms) | 随机访问时间占比 |
|---|---|---|---|
| 1 | 505.177 | 566.952 | 112.2283873 |
| 2 | 492.751 | 560.022 | 113.6521286 |
| 3 | 511.388 | 555.392 | 108.6048167 |
| 4 | 480.039 | 540.196 | 112.5316901 |
| 5 | 479.683 | 555.744 | 115.8565136 |
| 平均 | 493.8076 | 555.6612 | 112.5747072 |
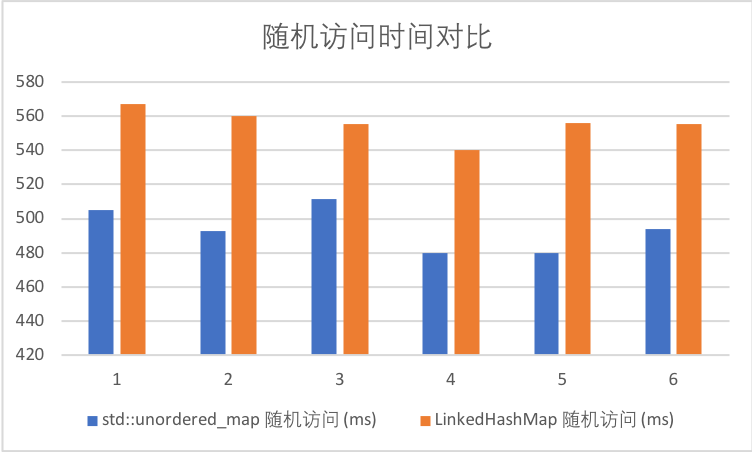
可以看到,随机访问时间有12%左右的性能损失。
3.4 使用注意事项
std::hash 和 std::equal_to 针对大多数类型都是可以正常工作的,其中 std::hash 针对所有C++标准类型都有其响应的特化版本,但是没有对 C 字符串的特化。 std::hash<const char*> 产生指针值(内存地址)的哈希,它不检验任何字符数组的内容。所以在使用字符指针这种比较特征的类型时,如果想要其按照字符指针所指向的字符串的内容来进行哈希和比较的话,需要定义自己的哈希functor Hash 和比较functor Pred :
struct MyHash
{
std::size_t operator()(const char* s) const
{
std::hash<std::string> str_hasher;
std::size_t h1 = str_hasher(s);
return h1;
}
};
struct StrEqual {
bool operator()(const char *val1, const char *val2) const{
return strcmp(val1, val2) == 0;
}
};
LinkedHashmap<const char*, const char*, MyHash, strEqual>;