1.1 什么是Hadoop
1.1.1 Hadoop 概述
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。
1.1.2 Hadoop的历史
Hadoop的源头是Apache Nutch,该项目始于2002年,是Apache Lucene的子项目之一。
1.1.3 Hadoop的功能与作用
1.1.4 Hadoop的优势
高可靠性,高扩展性,高效性,高容错性
1.2 Hadoop 项目及其结构
-
Common:Common是为Hadoop其他子项目提供支持的常用工具,它主要包括FileSystem、RPC和串行化库。
-
Avro:Avro是用于数据序列化的系统。它提供了丰富的数据结构类型、快速可压缩的二进制数据格式、存储持久性数据的文件集、远程调用RPC的功能和简单的动态语言集成功能。
-
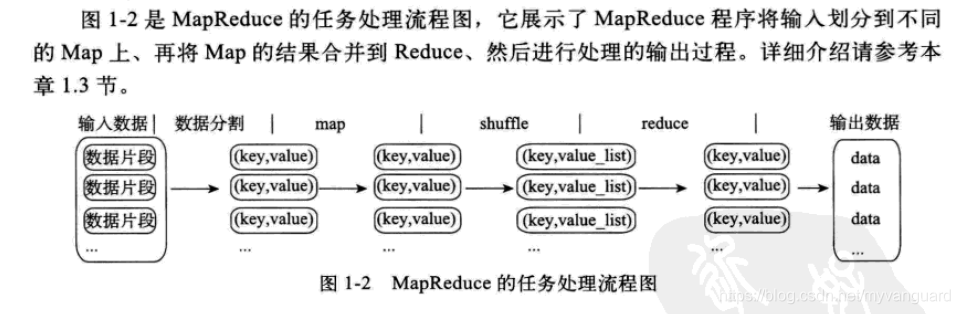
MapReduce:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
-
HDFS:HDFS是一个分布式文件系统。因为HDFS具有高容错性(fault-tolerent)的特点,所以它可以设计部署在低廉(low-cost)的硬件上。
-
Chukwa:Chukwa是开源的数据收集系统,用于监控和分析大型分布式系统的数据。
-
Hive:Hive最早是由Facebook设计的,是一个建立在Hadoop基础之上的数据仓库,它提供了一些用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储的工具。
-
HBase:HBase是一个分布式的、一面向列的开源数据库,该技术来源于Google论文Bigtable
-
Pig:Pig是一个对大型数据集进行分析、评估的平台。
-
ZooKeeper:ZooKeeper是一个为分布式应用所设计的开源协调服务。
-
Sqoop:该工具用于在结构化数据存储(如关系型数据库)和HDFS之间高效批量传输数据
-
Oozie:该服务用于运行和调度Hadoop作业(如MapReduce,Pig,Hive 及Sqoop作业)
1.3 Hadoop体系结构
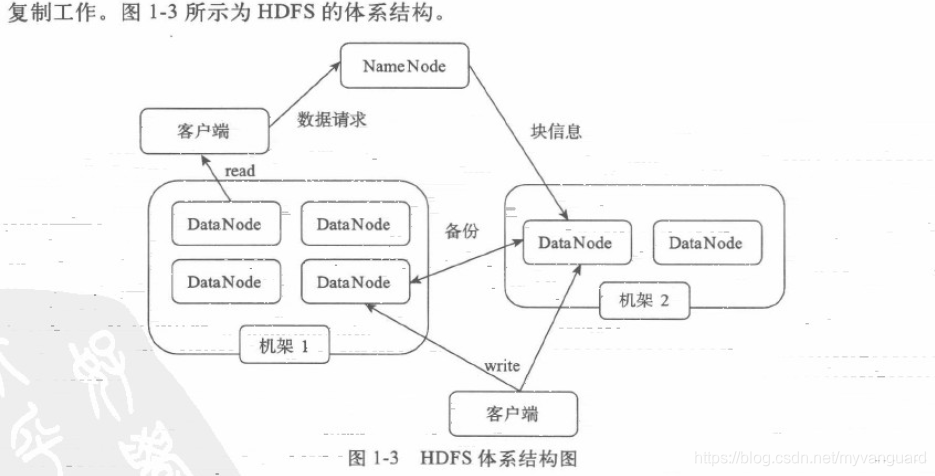
HDFS的体系结构
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。
HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。
MapReduce的体系结构
MapReduce框架是由一个单独运行在主节点的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。
主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前失败的任务;从节点仅负责由主节点指派的任务。
当一个Job被提交时,JobTracker接收到提交作业和其配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
MapReduce是一个批量查询处理器,能够在合理的时间范围内处理针对整个数据集的动态查询。
1.4 Hadoop与分布式开发
分布式系统其实是多处理机体系结构上执行任务的系统
MapReduce编程模型的原理是:利用一个输入的key/value对集合来产生一个输出的key/value对集合。MapReduce库的用户用两个函数来表达这个计算:Map和Reduce。
用户自定义的Map函数接收一个输入的key/value对,然后产生一个中间key/value对的集合。MapReduce把所有具有相同key值的value集合在一起,然后传递给Reduce函数。

用户自定义的Reduce 函数接收key和相关的value集合。Reduce函数合并这些value值,形成一个较小的yalue集合。一般来说,每次调用Reduce函数只产生0或1个输出的yalue 值。通常我们通过一个迭代器把中间value 值提供给Reduce函数,这样就可以处理无法全部放入内存中的大量的value值集合了。
MapReduce特点
-
数据分布存储
Hadoop分布式文件系统(HDFS)由一个名字节点(NameNode)和多个数据节点(DataNode)组成 -
分布式并行计算
Hadoop中有一个作为主控的JobTracker,用于调度和管理其他的TaskTracker。JobTracker可以运行于集群中的任意一台计算机上;TaskTracker则负责执行任务 -
本地计算
数据存储在哪一台计算机上,就由哪台计算机进行这部分数据的计算,这样可以减少数据在网络上的传输,降低对网络带宽的需求。 -
任务粒度
在把原始大数据集切割成小数据集时,通常让小数据集小于或等于HDFS中一个Block的大小(默认是64MB),这样能够保证一个小数据集是位于一台计算机上的,便于本地计算。 -
数据分割(Partition)
把Map任务输出的中间结果按使用Hash函数根据Reduce任务的个数划分key的范围,保证某一段范围内的key一定是由一个Reduce任务来处理的,可以简化Reduce的过程。 -
数据合并(Combine)
在数据分割之前,还可以先对中间结果进行数据合并(Combine),即将中间结果中有相同key的<key,value>对合并成一对,从而降低网络流量。 -
Reduce Map任务的中间结果在执行完Combine和Partition之后,以文件形式存储于本地磁盘上。中间结果文件的位置会通知主控JobTracker,JobTracker 再通知Reduce任务到哪一个TaskTracker上去取中间结果。
-
任务管道
有R个Reduce任务,就会有R个最终结果。很多情况下这R个最终结果并不需要合并成一个最终结果,因为这R个最终结果又可以作为另一个计算任务的输入,开始另一个并行计算任务,这也就形成了任务管道。
1.5 Hadoop 计算模型 - MapReduce
一个Map/Reduce作业(Job)通常会把输入的数据集切分为若干独立的数据块,由Map任务(Task)以完全并行的方式处理它们。框架会先对Map的输出进行排序,然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
1.6 Hadoop数据管理
1.6.1 HDFS的数据管理
1.文件写入
- Client 向NameNode 发起文件写人的请求。
- NameNode根据文件大小和文件块配置情况;返回给Client 所管理的DataNode的信息。
- Client 将文件划分为多个Block,根据 DataNode的地址信息按顺序将其写人到每个DataNode块中。
2.文件读取
- Client 向 NameNode.发起文件读取的请求。
- NameNode 返回文件存储的DataNode信息。
- Client 读取文件信息。
3.文件块(Block)复制
- NameNode 发现部分文件的Block不符合最小复制数这要求或部分DataNode失效。
- 通知DataNode 相互复制Block。
- DataNode 开始直接相互复制。
HDFS特点
- 文件块(Block)的放置:一个Block会有三份备份
- 心跳检测:用心跳检测DataNode.的健康状说
- 数据复制:用Hadoop 时可以用HDFS的balancer命令配置Threshold来平衡每一个DataNode的磁盘利用率。
- 数据管道性的写入:直到所有需要写入这个Block的DataNode都成功写入后,客户端才会开始写下一个Block。
- 安全模式:当分布式文件系统处于安全模式时,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。
1.6.2HBase的数据管理
HBase在分布式集群上主要依靠由HRegion、HMaster、HClient组成的体系结构从整体上管理数据。
HBase体系结构有三大重要组成部分:
- HBaseMaster:HBase主服务器,与Bigtable的主服务器类似。
- HRegionServer:HBase域服务器,与Bigtable的Tablet服务器类似。
- HBase Client:HBase客户端是由org.apache.hadoop.HBase.client.HTable定义的。
-
HBaseMaster一个HBase只部署一台主服务器,它通过领导选举算法(Leader Election Algorithm)确保只有唯一的主服务器是活跃的
-
HRegionServer HBase域服务器的主要职责有服务于主服务器分配的域、处理客户端的读写请求、本地缓冲区回写、本地数据压缩和分割域等功能。
-
HBaseClient HBase 客户端负责查找用户域所在的域服务器地址。HBase客户端会与HBase主机交换消息以查找根域的位置,这是两者之间唯一的交流。
1.6.3 Hive的数据管理
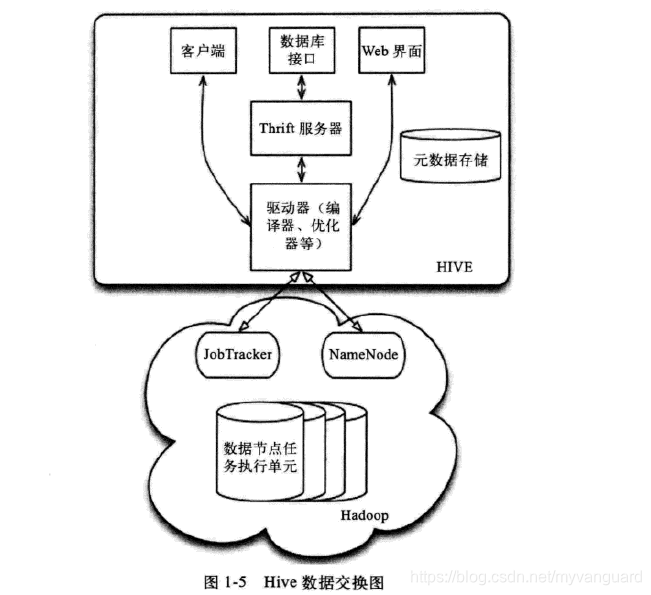
作为一个数据仓库,Hive的数据管理按照使用层次可以从元数据存储、数据存储和数据交换三方面来介绍。
(1)元数据存储
Hive 将元数据存储在RDBMS中,有三种模式可以连接到数据库:
(2)数据存储
首先,Hive没有专门的数据存储格式,也没有为数据建立素引,用户可以非常自由地组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,它就可以解析数据了。
其次,Hive中所有的数据都存储在HDFS中,Hive中包含4种数据模型:Table、External Table、Partition和Bucket。
(3)数据交换
数据交换主要分为以下几部分,如图.1-5所示。
- 用户接口:包括客户端、Web界面和数据库接口。
- 元数据存储:通常存储在关系数据库中,如MySQL、Derby等。
- 解释器、编译器、优化器、执行器。
- Hadoop:利用HDFS进行存储,利用MapReduce进行计算。
1.7 Hadoop集群安全策略
下面从用户权限管理、HDFS安全策略和MapReduce 安全策略三个方面简要介绍Hadoop的集群安全策略。
(1)用户权限管理
Hadoop上的用户权限管理主要涉及用户分组管理;为更高层的HDFS访问、服务访问、Job提交和配置Job等操作提供认证和控制基础。
Hadoop上的用户和用户组名均由用户自己指定;如果用户没有指定,那么Hadoop会调用-Linux的“whoami”命令获取。
(2)HDFS安全策略:
用户和HDFS服务之间的交互主要有两种情况:用户机和NameNode之间的RPC交互获取待通信的DataNode位置;客户机和DataNode交互传输数据块。
RPC.交互可以通过Kerberos 或授权令牌来认证。
数据块的传输可以通过块访问令牌来认证,每一个块访问令牌都由NameNode生成,它们都是特定的。
(3)MapReduce安全策略
MapReduce 安全策略主要涉及Job提交、Task和Shufle三个方面。对于Job提交,用户需要将job配置、输入文件和输入文件的元数据等写入用户home文件夹下,这个文件夹只能由该用户读、写和执行。
任务(Task)的用户信息沿用生成Task的Job的用户信息
当一个Map任务完成时,它的输出被发送给管理此任务的Task Tracker。每一个Reduce将会与TaskTracker通信以获取自己的那部分输出