1 TFRecord 的作用
TFRecord是用于tensorflow更高效的读取数据,一般会先将与训练(或测试验证)数据交个tfrecord结构化保存,在需要使用到这些数据时从TFRecord中取出来。
TFRecord是以二进制文件方式保存的。
tfrecord数据文件是一种将图像数据和标签统一存储的二进制文件,能更好的利用内存,在tensorflow中快速的复制,移动,读取,存储等。
2 结构及定义
message Example {
Features features = 1;
};
message Features{
map<string,Feature> featrue = 1;
};
message Feature{
oneof kind{
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
从上述代码可以看出,tf.train.Example中包含了属性名称到取值的字典,其中属性名称为字符串,属性的取值可以为字符串(BytesList)、实数列表(FloatList)或者整数列表(Int64List)。
3 使用示例
3.1 将数据保存到TFRecord文件中
import tensorflow as tf
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
num_shards = 2 # 定义了总共写入多少个文件
instances_per_shard = 2 # 定义了每个文件中有多少数据
for i in range(num_shards):
filename = ('/path/data.tfrecords-%.5d-of-%.5d' % (i, num_shards))
# 定义TFRecord文件的writer
writer = tf.python_io.TFRecordWriter(filename)
# 将数据封装成Example结构并且写入TFRecord文件
for j in range(instances_per_shard):
example = tf.train.Example(feature = tf.train.Features(feature={
'label' : _int64_feature(i),
'image' : _int64_feature(j)
}))
writer.write(example.SerializeToString())
writer.close()
运行上面的程序可以看到在/path/ 路径下生成了两个TFRecord文件
filename = ('/path/data.tfrecords-%.5d-of-%.5d' % (i, num_shards))
这行代码为TFRecord文件命名,一般地,将数据分为多个文件时,可以将文件以0000n-of-0000m的后缀区分命名。其中m表示了数据总共被存在了几个文件中,n表示当前的文件编号。这样的方式既方便了通过正则表达式获取文件列表,又在文件名中加入了更多的信息。不要小瞧这个命名规则,这些习惯上的方式已经逐渐成为了编码规范,了解了这些规范能帮助你快速的理解别人的代码,这很重要。
3.2 从TFRecord中获取数据
在从TFRecord文件中获取数据之前先来介绍两个函数:
tf.match_filenames_once 函数和 tf.train.string_input_producer 函数
TensorFlow提供了tf.match_filenames_once函数来获取一个符合正则表达式的所有文件,得到的文件列表可以通过tf.train.string_input_producer函数来进行有效的管理。
tf.train.string_input_producer函数会使用初始化时提供的文件列表创建一个输入队列,输入队列中的原始的元素为文件列表中的所有文件。通过设置shuffle参数,tf.train.string_input_producer函数支持随机打乱文件列表中文件出队顺序。当shuffle为True时,文件在加入队列之前会被打乱顺序,所有出队的顺序是随机的。
tf.train.string_input_producer生成的输入队列可以同时被多个文件读取线程操作,而且输入队列会将队列中的文件均匀的分给不同的线程。
当一个输入队列中的所有文件都被处理完后,它会将初始化时提供的文件列表中的文件重新加入队列。tf.train.string_input_producer可以设置num_epochs参数来限制加载初始化文件列表的最大轮数。
import tensorflow as tf
files = tf.train.match_filenames_once("/home/hxy/husin/Test/TFRecord/data.tfrecords-*")
filename_queue = tf.train.string_input_producer(files, shuffle=False) # shuffle=False 没有随机打乱样本。但一般在解决真实问题时是会选择打乱的
# 获取并解析一个样本
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'image': tf.FixedLenFeature([], tf.int64)
}
)
with tf.Session() as sess:
# 虽然在本程序中并没有声明任何变量,但使用tf.train.match_filenames_once函数时需要做一次初始化变量
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init_op)
print sess.run(files)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 执行多次数据获取操作
for i in range(8):
print sess.run([features['label'], features['image']])
coord.request_stop()
coord.join(threads)
在不打乱文件列表的情况下(shuffle=False), 会依次读出TFRecord文件中的每一个样例。而且当所有样例都被读完之后,程序会从头开始。
输出如下:
['/home/hxy/husin/Test/TFRecord/data.tfrecords-00000-of-00002'
'/home/hxy/husin/Test/TFRecord/data.tfrecords-00001-of-00002']
[0, 0]
[0, 1]
[1, 0]
[1, 1]
[0, 0]
[0, 1]
[1, 0]
[1, 1]
上述代码中还需要注意到的是:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
上面两行代码十分重要,要是没有这两行代码,该程序运行后会被一直挂起。
这两句实现的功能就是创建线程并使用QueueRunner对象来提取数据。简单来说:使用tf.train函数添加QueueRanner到tensorflow中。在运行任何训练步骤之前,需要调用tf.train.start_queue_runners()函数,否则tensorflow会被一直挂起。
tf.train.start_queue_runners这个函数将会启动输入管道的线程,填充样本到队列中,以便出队操作能拿带样本。这种情况下最好配合使用一个tf.train.Coordinator,这样可以在发生错误的情况下正确地关闭这些线程。
参考文章 :https://blog.csdn.net/happyhorizion/article/details/77894055
4 组合训练数据(batching)
上面介绍了如何从TFRecord文件中读取单个样例,这些样例可以提供给神经网络输入层进行训练了。但一般来说,将多个输入样例组织成一个batch可以提高模型训练的效率。所以在的到单个样例的结果后
,还需要将他们组织成batch,然后提供给网络输入层。
TensorFlow 提供了 tf.train.batch 和 tf.train.shuffle_batch 函数来将单个样例组织成batch的形式。
这两个函数都会生成一个队列,队列的入队操作是生成单个样例的方法,而每次出队得到的是一个batch样例。
这两个个函数唯一的区别在于是否会将数据打乱。
import tensorflow as tf
files = tf.train.match_filenames_once("/home/hxy/husin/Test/TFRecord/data.tfrecords-*")
filename_queue = tf.train.string_input_producer(files, shuffle=False)
# 获取并解析一个样本
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'image': tf.FixedLenFeature([], tf.int64)
}
)
example, label = features['image'], features['label']
batch_size = 3
capacity = 1000 + 3 * batch_size
example_batch, label_batch = tf.train.batch([example, label], batch_size=batch_size, capacity=capacity)
with tf.Session() as sess:
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(2):
cur_example_batch, cur_label_batch = sess.run([example_batch, label_batch])
print cur_example_batch, cur_label_batch
输出结果为:
[0 1 0] [0 0 1]
[1 0 1] [1 0 0]
下面讲解一下代码:
capacity = 1000 + 3 * batch_size
这是组合样例的队列中最多可以存储的样例个数,这个队列太大,那么需要占用很多的资源;如果太小,那么出队操作和可能回因为没有数据而被阻塞,从而导致训练效率降低。一般来说这个队列的大小会和每一个batch的大小相关,上面一行代码给出了设置队列大小的一种方式。
example_batch, label_batch = tf.train.batch([example, label], batch_size=batch_size, capacity=capacity)
使用tf.train.batch函数来组合样例, [example, label]参数给出了需要组合的元素,一般example和label分别代表训练样本和这个样本所对应的标签。batch_size草书给出了每一个batch中的样例个数,capacity给出了队列的最大容量。当队列长度的等于容量时TensorFlow会停止入队操作,而只是等待元素出队。当元素小于容量时,tensorflow将自动重新启动入队操作。
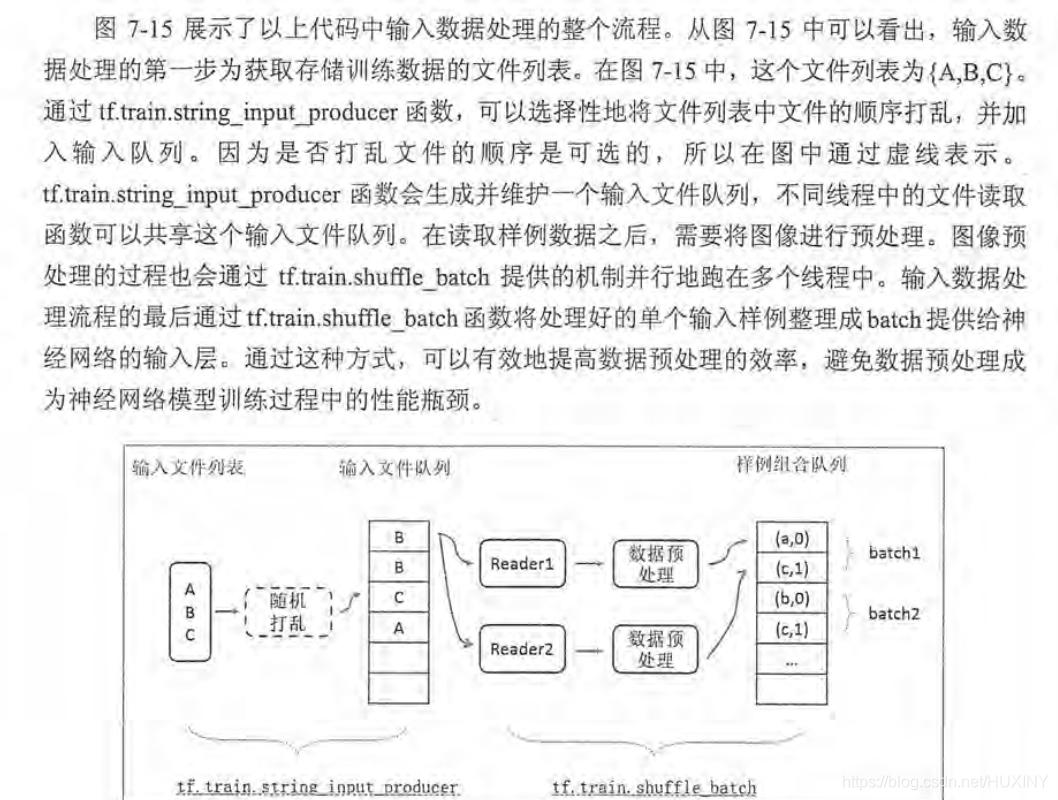
5 输入数据处理框架
这一小结整合上面的内容给出一个TensorFlow输入数据的处理框架。
import tensorflow as tf
import numpy as np
import threading
import time
files = tf.train.match_filenames_once("/home/hxy/husin/Test/TFRecord/data.tfrecords-*")
filename_queue = tf.train.string_input_producer(files, shuffle=False)
# 获取并解析一个样本
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'label': tf.FixedLenFeature([], tf.int64),
'image': tf.FixedLenFeature([], tf.int64),
'height': tf.FixedLenFeature([], tf.int64),
'width': tf.FixedLenFeature([], tf.int64),
'channel': tf.FixedLenFeature([], tf.int64)
}
)
image, label = features['image'], features['label']
height, width = features['height'], features['width']
channels = features['channels']
# 将预处理后的图像和标签数据通过tf.train.shuffle_batch合成神经网络训练时需要的batch
min_after_dequeque = 10000
batch_size = 100
capacity = 1000 + 3 * batch_size
image_batch, label_batch = tf.train.shuffle_batch([image, label], batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeque)
# 定义神经网络结构和优化过程. image_batch可以作为输入提供给神经网络的输入层, label_batch则提供了输入batch中样例的正确答案
logit = inference(image_batch)
loss = calc_loss(logit, label_batch)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
with tf.Session() as sess:
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(TRAINING_ROUDNS):
cur_example_batch, cur_label_batch = sess.run([example_batch, label_batch])
sess.run(train_step)
# 停止所有线程
coord.request_stop()
coord.join()