写在前面
HBase存在存储OpenTSDB源数据的表,了解这个对OpenTSDB的存储机制就会有一定了解。
原地址http://opentsdb.net/docs/build/html/user_guide/metadata.html
OpenTSDB 的主要目的是存储时间序列数据点,并允许对该数据进行各种操作。但是,有助于了解存储的数据类型,并在处理信息时提供一些上下文。OpenTSDB的元数据是有关数据点的数据。其中大部分是用户可配置的,以提供与外部工具(如搜索引擎或问题跟踪系统)的搭配。本章介绍了各种可用的元数据及其用途。
UIDMeta
存储在OpenTSDB中的每个数据点至少有三个与之关联的UID。将始终存在一个metric和一个或多个标记对,其由一个tagk或标记名称和一个tagv或标记值组成。当其中一个UID的新名称进入系统时,将分配唯一ID,以便始终存在UID名称和数字标识符对。
每个UID还可以具有记录在tsdb-uid表中的元数据条目。可用于每个UID数据包括不可变字段,例如uid,type,name和created时间戳反映当第一已分配的UID的时间。另外一些字段可以被编辑,如description,notes,displayName和一组custom键/值对来记录附加信息。有关这些字段的详细信息,请参阅/ api / uid / uidmeta端点。
每当创建或修改新的UIDMeta对象时,如果已经配置并加载了插件,它将被推送到搜索插件。有关UID值的信息,请参阅UID和TSUID。
TSMeta
OpenTSDB中的每个时间序列由其度量标准UID和标记名称/值UID的组合唯一标识,根据UID和TSUID创建TSUID。当接收到新的时间序列时,TSMeta对象可以记录在tsdb-uid由TSUID标识的行中的表中。元对象包括一些不可变字段,例如tsuid,metric,tags,lastReceived和created时间戳反映当TSMeta首次接收的时间。此外,一些领域可以如编辑description,notes和其他人。有关详细信息,请参见/ api / uid / tsmeta。
启用元数据
如果要在OpenTSDB设置中使用元数据,则必须显式启用实时元数据跟踪和/或使用CLI工具。由于对性能的影响,元数据生成有多种选择,因此在启用任何这些设置之前,请在生产中启用设置之前测试对TSD的影响。
有两个可用,从最小的影响开始。
tsd.core.meta.enable_realtime_uid- 启用后,只要为新指标,标记名称或标记值分配UID,就会生成UIDMeta对象,并可选择将其发送到配置的搜索插件。由于UID很少被分配,因此该设置不应对性能产生太大影响。‘-
当tsd.core.meta.enable_realtime_ts与tsd.core.meta.enable_tsuid_incrementing或 tsd.core.meta.enable_tsuid_tracking一起启用时,无论何时到达新的时间序列,都会在元表中标记计数器或标志。
-
注意
:确保启用以下设置之一,否则将无法实时跟踪元数据。
-
tsd.core.meta.enable_tsuid_tracking- 启用后,每次记录数据点时,都会使用给定数据点的时间戳将a1写入tsdb-meta表中。启用此设置将生成两倍的存储放置次数,并且可能需要更多的内存堆。例如,单个TSD应该能够以每秒大约2GB的堆来实现每秒6,000个数据点。 -
tsd.core.meta.enable_tsuid_incrementing- 启用此设置时,写入的每个数据点都将增加tsdb-meta表中与数据点所属时间序列对应的计数器。由于每个数据点都会产生一个增量请求,这会在TSD中产生更大的负载,并且很快就会占用堆空间,所以只有在你可以将负载分散到多个TSD或者写入相当小的情况下才能启用它。启用递增将覆盖该tsd.core.meta.enable_tsuid_tracking设置。例如,单个TSD应该能够以每秒大约6GB的堆来实现每秒3,000个数据点。
-
警告
在启用任何实时元数据设置时,请观察您的JVM堆使用情况。还要观察存储服务器,因为写入流量可能有效地增加一倍或三倍。
对于在将元数据写入存储之前TSD崩溃的情况,或者如果您未启用实时跟踪,您可以定期使用uidCLI工具和metasync子命令生成缺少的UIDMeta和TSMeta对象。有关信息,请参阅uid。
注释
另一种形式的元数据是注释。注释是与时间戳相关联的简单对象,并且可选地是时间序列。注释是记录事件的一种非常基本的方法。它们不是用作事件管理或问题跟踪系统。相反,它们可用于将时间序列链接到这样的外部系统。
每个注释都与开始时间戳相关联。这确定了音符在后端中的存储位置,可能是具有开头和结尾的事件的开始,或者仅用于在特定时间点记录音符。可选地,如果注释表示时间跨度,则可以设置结束时间戳,例如在开始之后的某个时间解决的问题。
另外,注释由TSUID定义。如果TSUID字段设置为有效的TSUID,则将存储注释,并将其与ID定义的时间序列的数据点相关联。这意味着在创建数据点查询时,将检索存储在请求的时间跨度内的任何注释,并可选择将其返回给用户。这些注释被认为是“本地的”。
如果TSUID为空,则注释被视为“全局”表示法,与系统中的所有时间序列相关联。查询时,用户可以指定在查询的时间跨度内提取全局注释。然后将这些注释与“本地”注释一起返回。
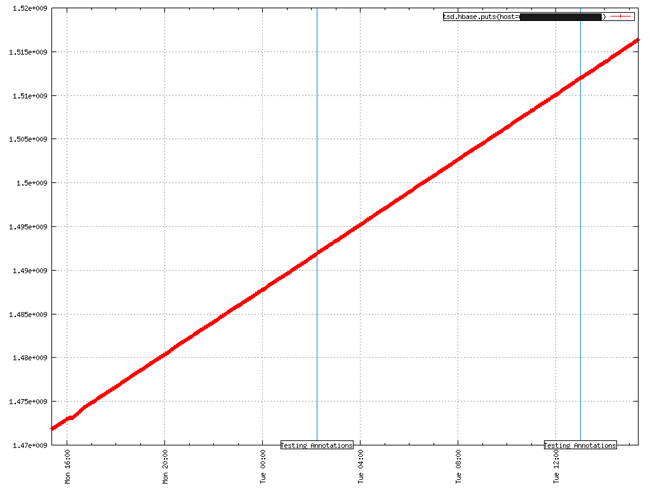
注释应该有一个非常简短的描述,限制在25个字符左右,因为注释可能出现在图表上。如果请求的时间跨度有许多注释,则图表可能会被注释堵塞。然后,用户界面可以让用户选择注释以检索更多细节。该细节可以包括冗长的“注释”和/或键/值对的自定义映射。
用户可以通过Http API在../api_http/annotation中添加,编辑和删除注释。
下面显示了带注释标记的示例GnuPlot图。注意只有description字段出现在一个蓝色线条记录的框中start_time。只有start_time图表上显示。