最常见的网络之一是CNN(Convolutional Neural Network), 在最近几年席卷计算机视觉等相关领域,因为他强大的特征表述能力和对图像处理的得天独厚优势,CNN的设计和训练也是被研究讨论最多的一个话题。

题主提到深度网络中层结构的设计和layer中节点个数的确定,我在这里姑且以CNN的网络结构设计为例讨论。
首先有一些常识知识是在设计一个CNN时需要知道的,我先简单介绍一下cnn的两三种基本操作:
CNN网络中几种基本网络层结构包括:
- Convolutional Layer(卷积层)
Convolutional Layer对该层输入数据所做的操作其实是这样的:

如上图,左侧绿色的假设为该层的输入(你可以想象成一个输入的图片),我们假设在这里他的输入size为 W=6, H=6, D=1,代表输入的数据的三个维度粉分别是6,6,1(图像数据如rgb格式图像为3层结构,
所以会有3channel的数据,D就可能为不止1)
红色区域的为一次卷积操作的region,他会与一个为3*3的权值矩阵做点乘然后做加和映射到一个数值上,他的过程类似于下图:

要注意的一点是,权值矩阵我这里没有画出来,而且权值矩阵在这里我们称他为filters,一层convolutional layer通常是会有多个filters的,原因是在初始化权值矩阵中的权值的时候,我们通常是采用随机生成的办法产生parameters(基于某些特定的分布),越多的parameters显然会让该层网络有更强大的数据表达能力,但是同时会让网络的训练更慢,代价更大。
Pooling Layers
Pooling层做的事情的目的其实可以这么理解,这么大的3维矩阵放入计算,后面在training阶段还要算梯度来做优化求解参数,小的图像数据还好,如果是一个医学图像,一言不合就 3000*3000 ,再来一个20层的网络结构,当然没法训练。所以我们要想办法让这个数据变小一些,不然所有的模型太难训练都是空谈了。
Pooling 的想法很简答,把例如,我把一个3*3的区域拿出来,只用这9个点中的最大值来代替这个区域的值就好了,这就是max pooling层。与此类似,我们还有均值pooling等等。
下面的图应该很好理解pooling:
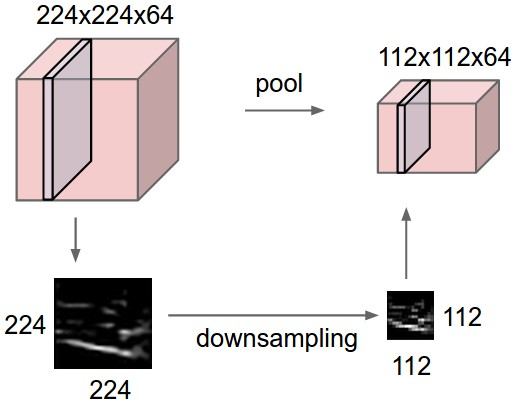 这个图把pooling操作成为downsampling,中文很多人翻译成下采样,其实就是指的只保留的一部分的图像数据,那么有人可能就会有疑问了,这么做不是会丢失很多图像数据吗?
这个图把pooling操作成为downsampling,中文很多人翻译成下采样,其实就是指的只保留的一部分的图像数据,那么有人可能就会有疑问了,这么做不是会丢失很多图像数据吗?
答案是这个的疑问是非常有道理的,在一些简单的图像分类问题上,丢失一些数据不算什么,我仍然能正确的识别分类,但是在一些segmentation的问题上,尤其是在医学图像要求比较严谨的结果的大前提下,这么丢失数据是不妥的,也会导致不准确的segmentation的出现。有一些手段可以解决这个问题,包括将原始图像和他合并来恢复丢失数据等,这些如果你感兴趣可以看看这篇文章:
Von Eicken, Thorsten, et al. "U-Net: A user-level network interface for parallel and distributed computing." ACM SIGOPS Operating Systems Review. Vol. 29. No. 5. ACM, 1995.
还有多的不同操作包括
Fully-connected layer
Normalization Layer
我就不啰嗦展开介绍了,你可以参看
CS231n Convolutional Neural Networks for Visual Recognition
或者
LeCun, Yann, Koray Kavukcuoglu, and Clément Farabet. "Convolutional networks and applications in vision." ISCAS. 2010.
的具体介绍,讲的非常仔细
好吧我还是啰嗦了,一大早没什么状态码代码就打打字活动筋骨了。。- -!!
回到题主的问题,在设计一个cnn的时候层数和每层nodes的个数怎么确定呢?
先说层数,答案是看数据来决定,有可能你根本就不需要多层结构,一个输入输出层就够了,这就一个线性模型。
层数越多的网络,对数据的表达能力也越强这是好理解的,但是显然并不是层数越多越好,一个是训练成本增加,一个也是如果你的训练数据不够多,你根本就不能training一个这么多层数的网络,这对nodes数也是一样的道理。
但是layers的层数在数据足够多足够hold住的情况下,多加一些不会有什么坏处,至于最多的层数有多少,我这里有一些层数非常深的例子:
1. GoogleNet-22层

GoogleNet是用于image recognition 和 Detection的,他的数据是ImageNetLarge-Scale Visual Recognition Challenge 2014(ILSVRC14).
2. ResNet, 152 layers
“Deep Residual Learning for Image Recognition”
这个网络让它们获得ILSVRC & COCO 2015 competitions的第一名,包括ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
所以网络深一些并没有什么坏处。。。。只要你的数据hold的住,机子跑的动,结构要合理。

但是每层节点的个数就不能越多越好了。
Hinton有一个文章叫做:
‘A Practical Guide to TrainingRestricted Boltzmann MachinesVersion 1Geoffrey HintonDepartment of Computer Science, University of Toronto’
有聊到一些design和training的一些基本原则和操作。
我大概摘取其中一些总结概括一下:
然后我想介绍一下一两个比较成功的网络结构的设计思路,参考它们的想法我们也能大概做出比较合适自己数据的结构和层数。
一个叫做U-Net ,一个叫做Fully Convolutional Networks