1.简单过滤器
a. pr [OPTION] [FILE]
功能:改变文件打印格式
| 选项 |
功能 |
| -l n |
设定页面长度为n行 |
| -w n |
设定页面总宽度为n个字符(不够会被砍掉) |
| -h str |
设定页眉为str |
| -n |
对行进行编号 |
| -k |
分k列输出 |
| -t |
不显示页眉、页脚和边距 |

b.head [OPTION] [FILE] 默认10行
| 选项 |
功能 |
| -n k |
显示前k行内容 |
tail [OPTION] [FILE]
| 选项 |
功能 |
| -n k |
显示后k行内容 |
| -f |
监控文件内容增长(进程相关) |
c.cut OPTION [FILE]
功能:垂直划分文件
| 选项 |
功能 |
| -cn-m |
剪切n-m列,每列宽度为一个字符 |
| -fn-m |
剪切n-m个字段,字段分隔符由-d选项指定 |
| -fn,m |
剪切第n和m个字段,字段分隔符由-d选项指定 |
| -d |
指定字段分隔符,默认制表符 |


d.paste [OPTION] [FILE]
功能:垂直黏贴文件
| 选项 |
功能 |
| -s |
合并行 |
| -d |
指定字段分隔符 |
e.sort [OPTION] [FILE]
功能:对文件内容排序
| 选项 |
功能 |
| -tchar |
用char作为分隔符识别字段 |
| -k m,n |
对第m个字段开始到第n个字段进行排序 |
| -k m.n |
对第m个字段的第n个字符进行排序 |
| -u |
删除重复行 |
| -n |
数值排序(不指定则为字典序) |
| -r |
逆序 |
| -f |
不区分大小写 |
| -c |
查看文件是否有序 |
| -o file |
将输出存入file,可以和源文件同名(会覆盖) |
f.uniq [OPTION] [INPUT [OUTPUT]]
| 选项 |
功能 |
| -d |
选择并显示输入中的重复行 |
| -u |
选择并显示输入中的非重复行 |
| -c |
显示每行出现的次数(连续的) |
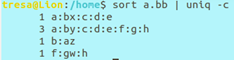
g.tr [OPTION] SET1 [SET2] 只接受标准输入
功能:将SET1中的字符替换为SET2中的相应字符(位置一一对应)
| 选项 |
功能 |
| -d |
删除字符(无需指定SET2) |
| -s |
压缩连续字符 |

h.cmp [OPTION FILE1 FILE2] [OPTION SKIP1 [SKIP2]]
功能:逐字对比两个文件的内容,遇到差异时终止
| 选项 |
功能 |
| -b |
输出第一个差异字节数、行数、字符 |
| -l |
输出所有差异字节数 |
| -i |
忽略文件1起始SKIP1字节和文件2起始SKIP2字节 |
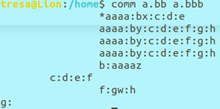
i.comm [OPTION] FILE1 FILE2
功能:逐行对比两个文件的内容,显示相同行和不同行(需要文件有序)
输出结果共三列:FILE1中独有的行;FILE2中独有的行;共有行
| 选项 |
功能 |
| -n |
隐藏第n列 |
?j.diff [OPTION] FILES
功能:显示两个文件的差别
| 选项 |
功能 |
| -q |
只在文件不同时显示 |
| -s |
只在文件相同时显示 |
| -c |
显示相同内容 |
| -u |
显示不同内容 |
| -i |
忽略大小写 |
| -b |
忽略重复空白 |
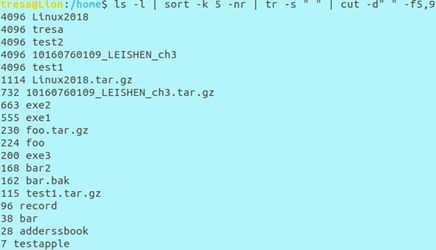
实例a:以从大到小的顺序列出当前目录中的文件
**ls -l的结果中第5列是文件大小,第9列是文件名字 -nr为数值逆序
实例b:统计一个文件中每个单词出现的次数
格式化文件:把空格、制表符、冒号都换成换行符,每行一个单词
对文件进行排序,之后标注每个单词出现的次数
不显示页眉、页脚、边距,一页三列输出

2. 正则表达式 RE 过滤器
| 模式语句 |
匹配含义 |
| 基本 BRE |
|
| [pqr] |
p, q, r中的单个字符 |
| [a-z] |
a到z中的单个字符 |
| . |
任意单个字符 |
| a* |
0个或任意多个a字符 |
| .* |
任意多个任意字符 |
| a\{m,n\} |
a字符出现m到n次 |
| [^pqr] |
不是p,q,r的单个字符 |
| ^exp |
exp模式位于行首 |
| exp$ |
exp模式位于行尾 |
| 扩展ERE(-E) |
|
| a+ |
1个或任意多个匹配a字符 |
| a? |
0个或1个a字符 |
| exp1|exp2 |
匹配exp1或exp2 |
| (a1|a2)a3 |
匹配a1a3或a2a3 |
a.grep [OPTIONS] PATTERN [FILE…]
功能:在文件中查找指定模式,单/双引号可加可不加
| 选项 |
功能 |
| -G |
匹配基本正则表达式(默认)BRE |
| -E |
匹配扩展正则表达式ERE |
| -n |
显示匹配行的行号 |
| -c |
显示出现次数 |
| -e |
匹配以连字符开头的表达式 |
| -x |
以整行匹配模式 |
| -i |
忽略大小写 |
| -v |
列出不匹配的行 |
| -l |
只给出匹配模式的文件名 |
练习:
grep –i “^draco” /etc/passwd 在文件/etc/passwd中寻找以draco开头的行,忽略大小写
grep –E “[0-9]+$” files 在文件files中寻找以一个或多个数字结尾的行
grep –l “#include<class1.h>” *.c 在所有以.c结尾的文件中寻找内容包含#include<class1.h>的文件,给出文件名
grep –e “-mtime” files 匹配以-mtime开头的行,若表达式以-开头,需要使用-e选项
grep –v “^draco” files 列出files中不以draco开头的行
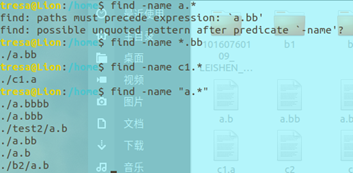
find ./ –name “.c” –exec grep –l “#include<class1.h>” {} \; 精确匹配名字叫.c的文件,并对这些文件执行查找内容#include<class1.h>的操作,输出符合条件的文件名
grep –iE “^(draco|qin).*/bash$” /etc/passwd 忽略大小写,使用扩展正则。查找以draco.或qin.开头,以/bash结尾的行
ps
ind -name “表达式” 没有问题
find -name 表达式 只能匹配出单一结果的情况
我咋知道为什么鸭 - =
b. sed [OPTION] ‘ADDRESS ACTION’ FILES
功能:对数据流进行定位操作;ADDRESS 定位指定行;ACTION 执行指定的编辑操作
| 选项 |
功能 |
| -e |
使用多条指令 |
| -f |
从文件中获取指令 |
| -n |
只打印模式匹配的行 |
定位方式:
指定行号:k 第k行;m,n 从m到n的连续行
指定模式:/pattern/ 模式匹配的行
| ACTION |
功能 |
| i a c |
插入、追加、修改文本 |
| d |
删除行 |
| p |
在标准输出上打印结果 |
| q |
读取到指定行后退出 |
| r fname |
将文件fname的内容放到行后 |
| w fname |
将指定行写入文件fname |
| = |
打印指定行号 |
| s/str1/str2 |
用str2替换指定行中出现的第一个str1 |
| s/str1/str2/g |
用str2替换所有的str1 |
示例:
sed ‘5q’ file 读取文件file的前5行
sed ‘/pattern/s/str1/str2/’ file 在文件file中对于满足pattern的行,使用str2替换str1
sed -n ‘/pattern/p’ file 在标准输出打印满足pattern的行
sed -n ‘$=’ file 打印最后一行的行号,即文件行数
sed -n ‘4,$!p’ file 不输出第4行到最后,即输出1-3行
sed -n “$((`sed -n ‘$=’ file`-4)),\$p” file 输出file倒数5行(从总行数-4开始),双引号里的美元符号需要转义
sed -n ‘/<head>/,/<\/head>/w output’ input 将input中从第一个包含<head>的行到第一个包含<Vhead>的行中间的段落输出到output
sed ‘1i\...’ file 在第一行前插入...
sed ‘1a\...’ file 在第一行后插入...
sed ‘1c\...’ file 修改第一行未...
sed ‘/^#/d’ file 删除注释行(以#开头的行)
sed ‘/^[ ]*$/d’ file 删除空白行(从行的开头到结尾,中间包含任意多个空格)
sed ‘s/:/|/g’ file 将文件中所有:替换成|
sed ‘s/pattern//g’ file 将文件中所有符合pattern的片段(注意,不是整行)
标记正则表达式(TRE)
| & |
在目标中指代源模式 |
| \(pattern\) |
标记源模式中的pattern,在目标中使用\k引用 |

示例:
sed ‘s/Professor/Associate &/g’ file 在替换模式中使用&指代源模式
ls -l | sed -n ‘/^.\{2,8\}w/p’ 查找具有写权限的文件(w出现在第3位到第9位的任意位置即可)
sed -n ‘/021[0-9]\{8\}/p’ a.bb 查找a.bb中以021开头的11位电话号码(021后有8个数字)
sed ‘s/\([a-zA-Z]*\) *\([a-zA-Z]*\)/\2,\1/’ file 将file中两个全英文字段的顺序颠倒,并用,隔开
c. awk [OPTIONS] ‘SLECTION_CRITERIA {ACTION}’ FILES
SLECTION_CRITERIA:决定程序作用的对象
ACTION:决定了程序操作的行为
功能:
将每一行分成多个字段,默认分隔符为空格和制表符,分隔符可以由-F选项自定义
用$1,$2等来引用每个字段,类似于shell中的命令行位置参数($0表示整行)
可以对各个字段进行正则表达式匹配、比较、条件判断、数值计算等
示例:
awk ‘$4 ~ /.*sbin.*/ {print}’ file 输出第4个字段匹配.*sbin.*的行
awk -F: ‘$3 > 2 {print $2}’ file 用:分隔字段,输出第3个字段>2的行的第2个字段
· 标准输出ACTION
print(默认):未格式化,自动换行 print 参数
printf:格式化,要自己加\n换行符 print“含格式符号的字符串”,参数
print和printf都可以用>和|重定向,目标文件/命令要加引号
| 格式符号 |
含义 |
| % |
格式起始符(必) |
| - |
左对齐(默认右对齐) |
| 0 |
空位补0 |
| m.n |
m为输出宽度,n为输出精度(默认为6) |
| l |
长整形或双精度数 |
| h |
short型 |
| 类型符号 |
含义 |
| d |
十进制 |
| o |
八进制 |
| x |
十六进制 |
| u |
无符号十进制 |
| 类型符号 |
含义 |
| c |
单个字符 |
| s |
字符串 |
| f |
浮点数 |
| e |
指数形式输出实数 |
· 数值操作
数值运算符:+ - * / % ^
赋值运算:+= -= ++ -- ...
· 变量和表达式
变量:第一次使用时自动声明,默认初始值为0或null;名称区分大小写;根据上下文解释成字符串或数字,并自动转换;直接引用,不需要加$
表达式:由字符串、数字、变量、运算符组合而成;字符串总是加双引号,可以用转义符,八进制加\,十六进制加\x;字符串作为操作数参与数字计算时自动转换成0
| 比较与逻辑运算符 |
含义 |
| ~/rexp/ |
匹配正则表达式rexp |
| !~/rexp/ |
不匹配正则表达式rexp |
| i in array |
数组元素array[i]是否存在 |
示例:
$0 ~ /^john/ 整行以john开头
$3 !~ /^[0-9]+$/ 第3个字段不全是数字(可以是空)
/^$/ 空行
· 写在文件内的awk(-f)
awk -F: -f awk_scipt file
awk_script写单引号里的内容
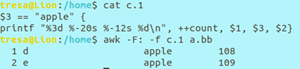
BEGIN和END程序段:
BEGIN{
在awk之前执行
}
普通awk语句
END{
在awk之后执行
}
·shell脚本中的awk
位置参数:可以引用shell的命令行参数,需要多套一层单引号

·内置变量
环境数组:用于存储shell环境变量 ENVIRON[“HOME”] ENVIRON[“PATH”]
内置变量:会自动赋值,也可以重新赋值,引用:变量名
| 变量名 |
功能 |
默认值 |
备注 |
| NR |
当前读取行的记录数 |
- |
|
| FS |
输入字段分隔符 |
空格 |
FS的赋值放在BEGIN中 |
| OFS |
输出字段分隔符 |
空格 |
print语句中参数的分隔符 |
| OFMT |
默认浮点数格式 |
%.6f |
|
| RS |
记录分隔符 |
换行符 |
可将多行合并成一条记录 |
| NF |
当前行的字段数 |
- |
|
| FILENAME |
当前输入文件 |
- |
|
| ARGC |
命令行中的参数个数 |
- |
|
| ARGV |
包含参数列表的数组 |
- |
|
| ENVIRON |
包含所有环境变量的数组 |
- |
| 函数 |
说明 |
| int(x) |
返回x的整数值 |
| sqrt(x) |
返回x的平方根 |
| length() |
返回整个行的长度 |
| length(x) |
返回x的长度 |
| tolower(s) |
将字符串s变为小写 |
| toupper(s) |
将字符串s变为大写 |
| substr(str,m) |
从str的第m个位置开始截取剩余子串 |
| substr(str,m,n) |
从str的第m个位置开始截取长度为n的子串 |
| index(s1,s2) |
返回字符串s2在s1中的位置 |
| split(str,arr,ch) |
以ch为分隔符,将str划分到数组arr中,返回字段数 |
| system(“cmd”) |
运行命令cmd,并返回其退出状态 eg.date |
· 控制流语句
if(条件){语句}else{语句}
while(条件){语句}
for(i=1;1<=10;i++){语句}
for(x in array){语句}
示例:
为每一行薪资计算税款:
awk –F: ‘{
if ($6 <= 30000) tax=0
else { if ($6 > 30000 && $6 <=50000) tax=($6-30000)*0.15 }
}’ lst
将每一行的字段逆向输出:
awk –F: ‘{ line=$NF
for (i=NF-1;i>0;i--)
line=line”:” $i
print line
}’ lst
输出所有环境变量的值:
awk ‘BEGIN {
for (key in ENVIRON)
print key “=” ENVIRON[key]
}’
根据职位分组,统计每个职位的员工数量($3是职位名):
awk –F: ‘{count[$3]++}
END { for (pos in count)
printf “%10s %4d\n”, pos, count[pos]
}’ lst