文章目录
使用tensorflow的小伙伴肯定对GPU不陌生,在科学矩阵计算上,GPU的性能要比CPU快很多,这样会大大减小我们训练模型的时间,但是一个服务器上往往有多卡,如果能多卡共同训练一个模型岂不快哉?在开始学习tensorflow的时候我就注意到
os.environ["CUDA_VISIBLE_DEVICES"]参数可以设置多卡,开始我也天真的以为这个参数就可以实现自动多卡训练,可是在做了相关的调研之后发现,简直是‘too young too simple’,从原理上就不对劲,不是这样的,但是当然还是能实现的,只不过不是这么简单而已,废话少说,进入正题
1 背景知识
在正式说多卡训练之前,我们最好能搞懂原理,剩下的只不过都是细枝末节了~
我们肯定用过各种optimizer,比如sgd、adam,我们在使用的时候可能对里面的实现关注的比较少,我们也没有必要关注太多,但是每个optimizer里面都有两个特别重要且一定会实现的函数,那就是今天的主角compute_gradients和apply_gradients。梯度修剪主要避免训练梯度爆炸和消失问题,而这就要用到这两个函数了~
所以一个optimizer的minimizer方法实际操作是计算梯度(compute_gradients)和反向传播(apply_gradients)
1.1 compute_gradients
compute_gradients(
loss, # A Tensor containing the value to minimize or a callable taking no arguments which returns the value to minimize. When eager execution is enabled it must be a callable.
var_list=None, # Optional list or tuple of tf.Variable to update to minimize loss. Defaults to the list of variables collected in the graph under the key GraphKeys.TRAINABLE_VARIABLES.
gate_gradients=GATE_OP,#How to gate the computation of gradients. Can be GATE_NONE, GATE_OP, or GATE_GRAPH.
aggregation_method=None,# Specifies the method used to combine gradient terms. Valid values are defined in the class AggregationMethod.
colocate_gradients_with_ops=False, # If True, try colocating gradients with the corresponding op.
grad_loss=None # Optional. A Tensor holding the gradient computed for loss.
)
计算loss中可训练的var_list中的梯度。
相当于minimize()的第一步,返回(gradient, variable)对的list。
1.2 apply_gradients
apply_gradients(
grads_and_vars, #List of (gradient, variable) pairs as returned by compute_gradients().
global_step=None, #Optional Variable to increment by one after the variables have been updated.
name=None # Optional name for the returned operation. Default to the name passed to the Optimizer constructor.
)
minimize()的第二部分,返回一个执行梯度更新的ops。
1.3 手写optimizer.minimize()
#Now we apply gradient clipping. For this, we need to get the gradients,
#use the `clip_by_value()` function to clip them, then apply them:
threshold = 1.0
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
#list包括的是:梯度和更新变量的元组对
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
for grad, var in grads_and_vars]
#执行对应变量的更新梯度操作
training_op = optimizer.apply_gradients(capped_gvs)
伪代码:
lr = tf.minimum(learning_rate, 0.001 / tf.log(999.) * tf.log(tf.cast(self.global_step, tf.float32) + 1))
opt = tf.train.AdamOptimizer(learning_rate = lr, beta1 = 0.8, beta2 = 0.999, epsilon = 1e-7)
grads = self.opt.compute_gradients(loss)
gradients, variables = zip(*grads)
capped_grads, _ = tf.clip_by_global_norm(gradients, config.grad_clip)
train_op = self.opt.apply_gradients( zip(capped_grads, variables),
global_step=self.global_step)
1.4 设备信息
因为multi gpu需要多卡的信息来查看相关变量创建情况,因此可以设置ConfigProto中log_device_placement=True来显示相关的设备log~
# Graph creation.
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# Running the operation.
print(sess.run(c))
result:
The output of TensorFlow GPU device placement logging shown as below:
/job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: Tesla K40c, pci bus
id: 0000:05:00.0
b: /job:localhost/replica:0/task:0/device:GPU:0
a: /job:localhost/replica:0/task:0/device:GPU:0
MatMul: /job:localhost/replica:0/task:0/device:GPU:0
[[ 22. 28.]
[ 49. 64.]]
2.multi GPU
首先贴一张官方的教程图片
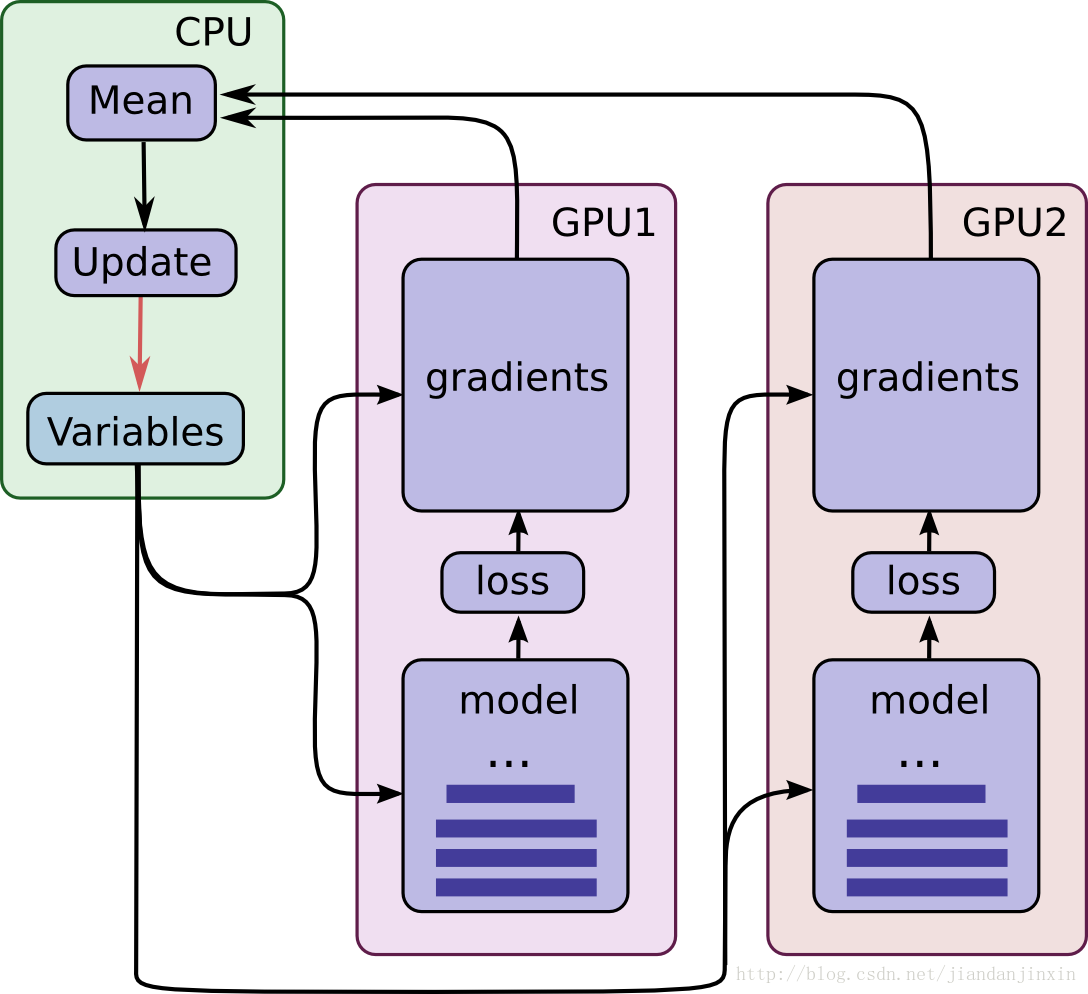
可以清楚的看到CPU中保存变量,GPU们计算整个model和gradients,然后把得到的梯度送回CPU中,CPU计算各个GPU送回来梯度的平均值作为本次step的梯度对参数进行更新。从图中我们可以看到只有当所有的GPU完成梯度计算以后,CPU才能求平均值,所以,整个神经网络的迭代速度将取决于最慢的一个GPU,这也就是同步更新。
所以整体思路就是:
1.在各个GPU上计算梯度(compute_gradients)
2.在CPU上计算平均梯度
3.在各个GPU上执行反向传播操作(apply_gradients)
2.1 baseline
直接上代码,对比单卡和多卡训练,下面的demo并不是官方的版本,但是我感觉对于理解很有帮助,可以先撸一下理解下,然后在看后面的官方版本~(完整代码详见git multi_gpu.py)
import sys
import os
import numpy as np
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
def get_weight_varible(name,shape):
return tf.get_variable(name, shape=shape,
initializer=tf.contrib.layers.xavier_initializer())
def get_bias_varible(name,shape):
return tf.get_variable(name, shape=shape,
initializer=tf.contrib.layers.xavier_initializer())
#filter_shape: [f_h, f_w, f_ic, f_oc]
def conv2d(layer_name, x, filter_shape):
with tf.variable_scope(layer_name):
w = get_weight_varible('w', filter_shape)
b = get_bias_varible('b', filter_shape[-1])
y = tf.nn.bias_add(tf.nn.conv2d(input=x, filter=w, strides=[1, 1, 1, 1], padding='SAME'), b)
return y
def pool2d(layer_name, x):
with tf.variable_scope(layer_name):
y = tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
return y
#inp_shape: [N, L]
#out_shape: [N, L]
def fc(layer_name, x, inp_shape, out_shape):
with tf.variable_scope(layer_name):
inp_dim = inp_shape[-1]
out_dim = out_shape[-1]
y = tf.reshape(x, shape=inp_shape)
w = get_weight_varible('w', [inp_dim, out_dim])
b = get_bias_varible('b', [out_dim])
y = tf.add(tf.matmul(y, w), b)
return y
def build_model(x):
y = tf.reshape(x,shape=[-1, 28, 28, 1])
#layer 1
y = conv2d('conv_1', y, [3, 3, 1, 8])
y = pool2d('pool_1', y)
#layer 2
y = conv2d('conv_2', y, [3, 3, 8, 16])
y = pool2d('pool_2', y)
#layer fc
y = fc('fc', y, [-1, 7*7*16], [-1, 10])
return y
def average_losses(loss):
tf.add_to_collection('losses', loss)
# Assemble all of the losses for the current tower only.
losses = tf.get_collection('losses')
# Calculate the total loss for the current tower.
regularization_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
total_loss = tf.add_n(losses + regularization_losses, name='total_loss')
# Compute the moving average of all individual losses and the total loss.
loss_averages = tf.train.ExponentialMovingAverage(0.9, name='avg')
loss_averages_op = loss_averages.apply(losses + [total_loss])
with tf.control_dependencies([loss_averages_op]):
total_loss = tf.identity(total_loss)
return total_loss
def average_gradients(tower_grads):
average_grads = []
for grad_and_vars in zip(*tower_grads):
# Note that each grad_and_vars looks like the following:
# ((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN))
grads = [g for g, _ in grad_and_vars]
# Average over the 'tower' dimension.
grad = tf.stack(grads, 0)
grad = tf.reduce_mean(grad, 0)
# Keep in mind that the Variables are redundant because they are shared
# across towers. So .. we will just return the first tower's pointer to
# the Variable.
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
def feed_all_gpu(inp_dict, models, payload_per_gpu, batch_x, batch_y):
for i in range(len(models)):
x, y, _, _, _ = models[i]
start_pos = i * payload_per_gpu
stop_pos = (i + 1) * payload_per_gpu
inp_dict[x] = batch_x[start_pos:stop_pos]
inp_dict[y] = batch_y[start_pos:stop_pos]
return inp_dict
def single_gpu():
batch_size = 128
mnist = input_data.read_data_sets('/tmp/data/mnist',one_hot=True)
tf.reset_default_graph()
with tf.Session() as sess:
with tf.device('/cpu:0'):
print('build model...')
print('build model on gpu tower...')
with tf.device('/gpu:0'):
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
pred = build_model(x)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
learning_rate = tf.placeholder(tf.float32, shape=[])
train_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
print('build model on gpu tower done.')
print('reduce model on cpu...')
all_y = tf.reshape(y, [-1,10])
all_pred = tf.reshape(pred, [-1,10])
correct_pred = tf.equal(tf.argmax(all_y, 1), tf.argmax(all_pred, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, 'float'))
print('reduce model on cpu done.')
print('run train op...')
sess.run(tf.global_variables_initializer())
lr = 0.01
for epoch in range(2):
start_time = time.time()
total_batch = int(mnist.train.num_examples/batch_size)
avg_loss = 0.0
print('\n---------------------')
print('Epoch:%d, lr:%.4f' % (epoch,lr))
for batch_idx in range(total_batch):
batch_x,batch_y = mnist.train.next_batch(batch_size)
inp_dict = {}
inp_dict[learning_rate] = lr
inp_dict[x] = batch_x
inp_dict[y] = batch_y
_, _loss = sess.run([train_op, loss], inp_dict)
avg_loss += _loss
avg_loss /= total_batch
print('Train loss:%.4f' % (avg_loss))
lr = max(lr * 0.7,0.00001)
total_batch = int(mnist.validation.num_examples / batch_size)
preds = None
ys = None
for batch_idx in range(total_batch):
batch_x,batch_y = mnist.validation.next_batch(batch_size)
inp_dict = {}
inp_dict[x] = batch_x
inp_dict[y] = batch_y
batch_pred,batch_y = sess.run([all_pred,all_y], inp_dict)
if preds is None:
preds = batch_pred
else:
preds = np.concatenate((preds, batch_pred), 0)
if ys is None:
ys = batch_y
else:
ys = np.concatenate((ys,batch_y),0)
val_accuracy = sess.run([accuracy], {all_y:ys, all_pred:preds})[0]
print('Val Accuracy: %0.4f%%' % (100.0 * val_accuracy))
stop_time = time.time()
elapsed_time = stop_time - start_time
print('Cost time: ' + str(elapsed_time) + ' sec.')
print('training done.')
total_batch = int(mnist.test.num_examples / batch_size)
preds = None
ys = None
for batch_idx in range(total_batch):
batch_x, batch_y = mnist.test.next_batch(batch_size)
inp_dict = {}
inp_dict[x] = batch_x
inp_dict[y] = batch_y
batch_pred, batch_y = sess.run([all_pred, all_y], inp_dict)
if preds is None:
preds = batch_pred
else:
preds = np.concatenate((preds, batch_pred), 0)
if ys is None:
ys = batch_y
else:
ys = np.concatenate((ys, batch_y), 0)
test_accuracy = sess.run([accuracy], {all_y: ys, all_pred: preds})[0]
print('Test Accuracy: %0.4f%%' % (100.0 * test_accuracy))
def multi_gpu(num_gpu):
batch_size = 128 * num_gpu
mnist = input_data.read_data_sets('./data',one_hot=True)
tf.reset_default_graph()
with tf.Session() as sess:
with tf.device('/cpu:0'):
learning_rate = tf.placeholder(tf.float32, shape=[])
opt = tf.train.AdamOptimizer(learning_rate=learning_rate)
print('build model...')
print('build model on gpu tower...')
models = []
for gpu_id in range(num_gpu):
with tf.device('/gpu:%d' % gpu_id):
print('tower:%d...'% gpu_id)
with tf.name_scope('tower_%d' % gpu_id):
with tf.variable_scope('cpu_variables', reuse=gpu_id>0):
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
pred = build_model(x)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
grads = opt.compute_gradients(loss)
models.append((x,y,pred,loss,grads))
print('build model on gpu tower done.')
print('reduce model on cpu...')
tower_x, tower_y, tower_preds, tower_losses, tower_grads = zip(*models)
aver_loss_op = tf.reduce_mean(tower_losses)
apply_gradient_op = opt.apply_gradients(average_gradients(tower_grads))
all_y = tf.reshape(tf.stack(tower_y, 0), [-1,10])
all_pred = tf.reshape(tf.stack(tower_preds, 0), [-1,10])
correct_pred = tf.equal(tf.argmax(all_y, 1), tf.argmax(all_pred, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, 'float'))
print('reduce model on cpu done.')
print('run train op...')
sess.run(tf.global_variables_initializer())
lr = 0.01
for epoch in range(2):
start_time = time.time()
payload_per_gpu = batch_size/num_gpu
total_batch = int(mnist.train.num_examples/batch_size)
avg_loss = 0.0
print('\n---------------------')
print('Epoch:%d, lr:%.4f' % (epoch,lr))
for batch_idx in range(total_batch):
batch_x,batch_y = mnist.train.next_batch(batch_size)
inp_dict = {}
inp_dict[learning_rate] = lr
inp_dict = feed_all_gpu(inp_dict, models, payload_per_gpu, batch_x, batch_y)
_, _loss = sess.run([apply_gradient_op, aver_loss_op], inp_dict)
avg_loss += _loss
avg_loss /= total_batch
print('Train loss:%.4f' % (avg_loss))
lr = max(lr * 0.7,0.00001)
val_payload_per_gpu = batch_size / num_gpu
total_batch = int(mnist.validation.num_examples / batch_size)
preds = None
ys = None
for batch_idx in range(total_batch):
batch_x,batch_y = mnist.validation.next_batch(batch_size)
inp_dict = feed_all_gpu({}, models, val_payload_per_gpu, batch_x, batch_y)
batch_pred,batch_y = sess.run([all_pred,all_y], inp_dict)
if preds is None:
preds = batch_pred
else:
preds = np.concatenate((preds, batch_pred), 0)
if ys is None:
ys = batch_y
else:
ys = np.concatenate((ys,batch_y),0)
val_accuracy = sess.run([accuracy], {all_y:ys, all_pred:preds})[0]
print('Val Accuracy: %0.4f%%' % (100.0 * val_accuracy))
stop_time = time.time()
elapsed_time = stop_time-start_time
print('Cost time: ' + str(elapsed_time) + ' sec.')
print('training done.')
test_payload_per_gpu = batch_size / num_gpu
total_batch = int(mnist.test.num_examples / batch_size)
preds = None
ys = None
for batch_idx in range(total_batch):
batch_x, batch_y = mnist.test.next_batch(batch_size)
inp_dict = feed_all_gpu({}, models, test_payload_per_gpu, batch_x, batch_y)
batch_pred, batch_y = sess.run([all_pred, all_y], inp_dict)
if preds is None:
preds = batch_pred
else:
preds = np.concatenate((preds, batch_pred), 0)
if ys is None:
ys = batch_y
else:
ys = np.concatenate((ys, batch_y), 0)
test_accuracy = sess.run([accuracy], {all_y: ys, all_pred: preds})[0]
print('Test Accuracy: %0.4f%%\n\n' % (100.0 * test_accuracy))
def print_time():
now = int(time.time())
timeStruct = time.localtime(now)
strTime = time.strftime("%Y-%m-%d %H:%M:%S", timeStruct)
print(strTime)
if __name__ == '__main__':
single_gpu()
multi_gpu(1)
#multi_gpu(2)
#multi_gpu(3)
#multi_gpu(4)
2.2 官方tutorial
官方教程:git tutorial codes
写在最后
本博小主认为理解差不多了,官方如果4卡加速比大概在2-3倍,但是我在一个LSTM的language model上效果却不太理想,加速比仅能到1.5倍,这里我初步测试感觉是由于CPU和GPU的数据传递导致的,因为在该模型中的最大区别是用了word embedding,并且参数相对多一些,但是具体原因依旧未知,求大佬点播。
这里我也给出相关代码和部分数据,用于探讨,如果有相关的大佬知道原因何在,我们可以共同探讨。代码链接
参考网站: