1. 导读
这期主要分享下String的常量池以及intern方法的使用;
2. JVM内存模型的简介
在介绍String的常量池之前, 先插播下JVM的内存模型, 以便能更好地理解后面的内容;
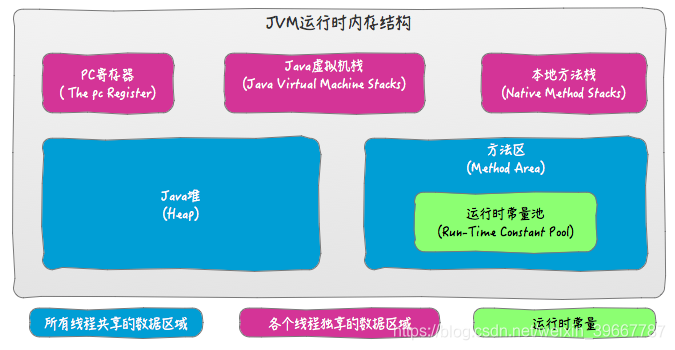
这是一张经典的JVM运行时内存管理图(基于JAVA SE 8), 而我们经常用的HotSpot虚拟机则使用永久代(Permanent Generation)来实现方法区;
本期需要关注的是方法区中运行时常量池, JAVA堆和Java虚拟机栈;
.1 运行时常量池: 他存储两部分数据: 第一部分是class文件中描述的符号引用以及编译产生的常量和直接引用数据; 第二部分是运行时产生的新的常量也会存储在这里, String::intern就是运用了这一特性去拿String常量池的数据的;
.2 Java堆: 简单来说我们每个new出来的对象都会存储在这个区域;
.3 Java虚拟机栈: 这部分存储是方法运行时的数据, 而存储的元素叫做栈帧;
这里先形成个概念, 不同版本的JVM的内存模型也是不同的, 这里只是拿这个举例, 具体等到JVM专题再展开;
3. String::intern
public native String intern();
.1 String::intern是String类中唯一的一个原生方法;
.2 他的作用就是在运行时, 调用String::intern构建String对象时, 先从常量池获取, 如果不存在则新增, 并将新增的String对象放入常量池;
.3 请注意, 我上面说明的是常量池中存的String对象而不是引用; JDK8的源码中有段注释:
/**
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
*/
用大白话讲就是当String::itern被调用时, 会先去StringPool中找是否存在当前的字符串(使用equals判断), 如果不存在会先把String对象添加到StringPool中, 然后返回这个对象的引用;
下面做个实验来说明上面的理论:
public static void main(String[] args) {
String str1 = "123";
String str2 = new String("123");
/**
* 不主动调用intern的情况下 两者虽然底层value[]一致, 但是引用的是两个String对象;
*/
LOGGER.info(String.format("不调用String::intern的地址引用: %s", str1 == str2));
LOGGER.info(String.format("不调用String::intern的对象值是否相同: %s", str1.equals(str2)));
/**
* 主动调用intern
*/
String str3 = new String("123").intern();
LOGGER.info(String.format("调用String::intern的地址引用: %s", str1 == str3));
LOGGER.info(String.format("调用String::intern的对象值: %s", str1.equals(str3)));
char[] tempArray = {'1', '2', '3'};
String str4 = new String(tempArray).intern();
LOGGER.info(String.format("调用String::intern的地址引用: %s", str1 == str4));
LOGGER.info(String.format("调用String::intern的对象值: %s", str1.equals(str4)));
}
.1 str1是直接声明的字符串常量, 会在初始化就把"123"放入到常量池中;
.2 str2是使用"123"再new了一个新的String对象;
.3 str3是new String对象时, 调用了String::intern;
.4 str4是基于char[]new了一个String对象, 并且调用String::intern;
回到上面的结论, 常量池中是存的对象, 且只有调用String::intern时, 才会去常量池中寻找匹配的String对象;那么上面的结果应该是:
. case 1: false(未调用String::intern, 直接返回了新对象(存储在java堆中));
. case 2: true(底层的value[]里面的值相同);
. case 3: true(调用了String::intern, 且在常量池已存在, 直接返回该对象的引用<与str1的对象相同>);
. case 4: true;
. case 5: true(调用了String::intern, 从常量池获取);
. case 6: true;

实际执行的结果也是与我们分析的一致;
划重点:
.1 String::intern是对字符串的缓存, 缓存位置是常量池;
.2 String::intern判断字符串是否相同使用的是String::equals, 故而不管用何种方式声明的字符串, 只要最终的value[]是相同的, 那么都会从常量池获取;
.3 JVM对String str = “1” + “2” + “3”; 这种方式的声明会自动优化成String str = “123”; 所以常量池中只会缓存一个String对象;
4. String::intern的利弊
String::intern的初衷是运用缓存的方式, 提升效率; 但是这种方式真的好吗?
在JDK6的时代, String的常量池还是位于方法区的(永久代), 这块内存区域是有界的, 并且GC效率不高; 假设我们调用String::intern时, 次数高但是相同的String较少, 这时候会导致不断地往方法区中添加String对象, 达到临界值时, 自然就内存溢出(OOM)了;
故而在JDK6时代, 是不推荐使用String::intern的;
在JDK7之后的版本, String的常量池被移动到了堆中, 虽然堆也是有界的, 但是他的大小要比方法区大, 并且堆的GC更频繁, OOM的概率就小了; 但是如果是上面的场景, 依然有概率会导致OOM的;
所以我们在使用String::intern时, 需要考虑实际场景, 如果有大面积的重复字段时, 可以使用String::intern将其缓存起来, 比如用到省份或者省会这种场景; 但是如果是无序并且存在时间较短的字符串, 就没必要将其缓存起来了;
划重点:
.1 JDK6的常量池是位于方法区的, 到了JDK7之后才将其移到java堆的; 故而使用JDK6时, 不推荐使用String::intern, 如果实在需要, 可以考虑自己实现一个HashMap将重复的字符串缓存起来;
.2 使用String::intern时需要考虑实际场景, 如果是无序且存在时间较短的场景, 就没有必要使用String::intern来增加CPU开支了; 如果有涉密以及安全考虑, 也不推荐使用String::intern;
.3 在大多数情况下, 我们该怎么使用String就怎么使用, 不必强求String::intern;
关于String的分享就到这里了, 以上内容如有不足之处, 欢迎指正; 如果看了觉得有收获, 请转发并收藏, 感谢;