区块链入门学习
写在前面
因为本人毕业设计选题与区块链相关,在此之前对区块链仅仅只是有所耳闻。经过一段时间的学习和摸索之后,整理和记录一部分自己的入门心得和收获吧。并不是什么非常深入的文章,同时也借鉴了很多其它文章,博客,论坛回复,同时融入自己的理解。但是可能我的理解会有失偏颇,希望多多指正,多多交流。
参考链接
《区块链技术指南》 版本1.2.0 https://legacy.gitbook.com/book/yeasy/blockchain_guide/details
《区块链入门教程》 阮一峰 http://www.ruanyifeng.com/blog/2017/12/blockchain-tutorial.html
区块链与比特币
2008年11月1日,中本聪(化名)发布了比特币白皮书《Bitcoin: A Peer-to-Peer Electronic Cash System》 ,并于次年1月3日,创造出了比特币的第一个区块(创世区块),挖出了第一批的50个比特币。
比特币作为一种颠覆传统货币的新型数字货币引起了全球广泛的关注,人们发现它的去中心化并不仅仅可以应用在经济金融领域,更可以用在其余包含信任问题的领域中发光发热,于是从中提炼出区块链这门技术。
区块链技术现在已经从比特币项目脱颖而出,在包括金融、贸易、征信、物联网、共享经济等诸多领域崭露头角。现在,除非特别指出是“比特币区块链”,否则当人们提到“区块链技术”时,往往已与比特币没有什么必然联系了。 ——《区块链技术指南》P28
但是作为区块链最初的摇篮,我们仍可以先从比特币中入手,学习区块链。
钱为什么有价值
电子货币是价值符号的符号。纸币和信用货币不是真实的货币,本身并没有内在的价值,只是货币的价值符号。—— 百度百科 “价值符号” 词条
钱是什么,钱不就是一张弄得花里胡哨的纸吗?但是依托国家的信用,人们承认这张红色毛爷爷有着100块钱的购买力,愿意用纸币去交换货物。所以这个纸币只是一个价值的载体。
每张纸币上都有自己独一无二的编号,设想在一个具有相当信任度的社会,我们支付纸币的时候,是不是甚至可以省略掏钱这个步骤,直接使用这串编号,然后某个数据中心记录下这串编号易主,就完成支付的步骤了。
这说明了数据在一定的情况下(这串数据具有唯一性,可归属性),也是有可能成为价值载体的。当我们承认某条数据具有价值的时候,我们就可以使用数据作为我们的“货币”。
从零造出一个数字货币交易系统
假设我们处在一个不存在欺骗,互相坦诚的乌托邦,在这里数据具有价值,我们可以用数据进行商品交易。现在我们要在这里造一个数字货币交易的系统,在这个系统里,人人可以在其中记录自己的交易数据。一个简单的数据记录形式如:交易id,付款方,收款方,金额,时间戳。
一切从0开始,那么首先我们要先发行货币。按照以上的格式,可以添加第一条交易数据,这条数据被我们赋予了价值
| 交易id | 付款方 | 收款方 | 金额 | 时间戳 | 备注 |
|---|---|---|---|---|---|
| 0 | 系统 | 张三 | 50 | 2019/1/22 0:00:00 | 系统发行了50元给张三 |
张三有了最开始的50元,他获得了50元的购买力。 随后他可以分别与李四和王五做交易
| 交易id | 付款方 | 收款方 | 金额 | 时间戳 | 备注 |
|---|---|---|---|---|---|
| 0 | 系统 | 张三 | 50 | 2019/1/22 0:00:00 | 系统发行了50元给张三 |
| 1 | 张三 | 李四 | 20 | 2019/1/22 1:00:00 | 张三支付李四 20元 |
| 2 | 张三 | 王五 | 30 | 2019/1/22 2:00:00 | 张三支付王五 30元 |
| … | … | … | … | … | … |
这是一个不存在欺诈行为的世界,所以人人互相信任,并且有个兢兢业业,任劳任怨的记账工在不断收集交易信息录入系统,让这个系统能够一直运行下去。
但这个系统的货币总量将只有50元,因为最开始我们只在其中发行了50元。
但现实总是很残酷。我们接下来一点一点向这个世界中注入其他残酷的因素。
发行货币
很显然,这个50块根本不够整个社会运作的。甚至一开始这50块凭什么要给张三?为什么不能给李四,王五?
所以发行货币也需要按照一定的基本法。所以乌托邦定了一套规矩:谁记账,谁拿钱。一方面奖励记账工的辛苦付出,一方面又保证了整个系统中的货币数量发行。
比特币中的记账工就是传说中的矿工
比特币里的记账就是传说中的挖矿
记账工每次会收集大约若干条交易数据(比特币区块链中的一个区块数据不能超过1MB),然后打一个区块,在这些交易数据插入一条系统给自己的转账记录作为自己记账的报酬,然后上传区块到系统中完成记账。
那这样整个货币系统的货币总量随着记账块数增加而增加,将没有限制,岂不是要通货膨胀?所以这时候又添加一条规矩,每记录若干块,记账报酬将减半。那么根据数学计算,这个系统中的货币总量将收敛到一个特定值。
比特币中每挖超过21万个区块奖励减半。最初的报酬奖励是每个区块奖励50个比特币。
因此最后总量将会收敛在2100万枚。
210,000 * 50 * (1 + 1/2 + 1/4 + 1/8 + … ) = 210,000 * 50 * 2 = 21,000,000
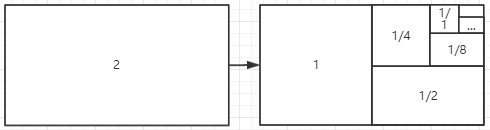
随着记账报酬的越来越少,记账工会越来越消极怠工。所以规定每笔交易中可以给记账工一定的小费。记账员可以自己挑取记录哪个交易,交易的小费越多则会越早被记账员录入系统中。
这样即使将来记账报酬枯竭殆尽,也可以保证记账工的记账积极性。
同时每个区块增加头信息用于存储这个区块的相关的数据,比如区块id,生成时间,区块大小,记账员等信息
现在我们的系统将变成如下情况:
区块一
Head
区块id 生成时间 区块大小 记账员 1 2019/1/23 0:00:00 100 张三 Body
交易id 付款方 付款 收款方 收款 时间戳 备注 0 系统 50 张三 50 2019/1/23 0:00:00 记账员张三获得50元报酬 1 李四 20 王五 15 2019/1/22 0:00:00 李四支付王五 15元,记账员获得20-15=5元小费 2 李四 30 赵六 28 2019/1/22 1:00:00 李四支付赵六 28元,记账员获得30-28=2元小费 … … … … …
区块二
Head
区块id 生成时间 区块大小 记账员 2 2019/1/24 0:00:00 100 李四 Body
交易id 付款方 付款 收款方 收款 时间戳 备注 0 系统 50 李四 50 2019/1/24 0:00:00 记账员李四获得50元报酬 1 张三 20 王五 14 2019/1/23 0:00:00 张三支付王五 14元,记账员获得20-14=6元小费 2 王五 30 赵六 25 2019/1/23 1:00:00 王五支付赵六 25元,记账员获得30-25=5元小费 … … … … …
现在整个账本成为一系列的块状,每个人都有权利去记账获取报酬和小费,同时保证了整个系统的货币不断发行,以及限制了货币的通胀,以及记账员的积极性。
去中心化
中心化指的是一个机构对于数据方面读写的全面掌控。中心化解决了一定程度上的信任问题,比如网络购物中买家和卖家两方之间会存在一个猜疑链——
买家:我要是先付钱,卖家不发货怎么办?
卖家:我要是先发货,买家不给钱怎么办?
这时候像x宝这样的中心化机构则提供了解决方案。
x宝:买家给钱给我,卖家发货给买家,买家确认收货我把钱给卖家,否则退给买家。
其实这时候x宝是受双方信任的,则买家和卖家可以完成整个流程。
但人们的猜疑永远是无休止的,有时候也会对一些中心化机构产生不信任(某黄车出来挨打)
信任问题在记账上尤为重要,人们如果不信任记账系统,则这个记账系统也就没有存在的必要了。
为了打造一个人人都信任的账本系统,现在我们把系统的数据分发到每个记账员的设备中,每个记账员都有一份账本数据。样本多了,造假成本就高了嘛,大家放心多了。
不过这个带来的问题也很明显:
- 首先是效率问题,现在一个记账员在自己的设备里记好了一块,还需要把这一块账本数据广播给其他记账员;
- 广播过程中,网络可能还是不可靠的,有的记账员收的到,有些记账员收不到;
- 有可能有些记账员的设备有问题,会丢失数据;
- 还有个别记账员的诚信问题,会不会篡改数据;
- 等等
这些就后续一个一个解决。
记账竞争问题
现在的系统里允许所有人进行记账,并对记账员提供了激励,因此记账员的数量不断攀升,互相之间成了竞争关系。
假如这个系统中已经存在了2个区块。现在人人都正抢着记录第三个区块,这时候会出现许多号称自己是第三块的区块。
这时候有人说先来后到,谁最早谁算数。但是最早又需要怎么去判断?
中心化的机构里,可以只依照中心机构的时钟来作为标准来实现仲裁,但现在整个系统已经成为分布式的了,系统内部也不会存在一个统一的时钟,每个记账员设备的时钟都不一致,所以根本无法遵循先来后到的原则。
所以这时候大家需要有一个共识机制:共同认可某个区块成为下一个区块的机制。
在比特币中,引入了工作量证明机制(Proof of work,POW)。
工作量证明机制
先来了解下哈希函数,明白的可以跳过啦
一个函数,一个输入对应着一个输出。输入一段任意长度的数据,通过哈希函数运算能输出一个固定长度的数字。比如字符串“123”经过某个哈希函数,会得到一个十六进制数 a8fdc205a9f19cc1c7507a60c4f01b13d11d7fd0 。
这里有几个特性:
- 并没有另一个函数能够从十六进制数a8fdc205a9f19cc1c7507a60c4f01b13d11d7fd0 反推出字符串”123“
- 不同的字符串计算出相同的哈希值的概率极低,近似可以认为不可能发生。
- 稍微对原数据做一点微小的改动,哪怕只是修改一个字,经过处理后的哈希值是面目全非的。
所以有这样的结论
推论1:每个区块的哈希都是不一样的,可以通过哈希标识区块。
推论2:如果区块的内容变了,它的哈希一定会改变。
—— 《区块链入门教程》 阮一峰
我们在区块的头信息中加入这么一个数据叫做Nonce,这个数据是随机值,需要让记账工自己去填充。记账工需要不断去修改这个Nonce,让整个区块的哈希值计算出来以后要小于某个指定的目标值。
该目标值很小,用十六进制数来表示,前面会有很多0,如 0000000000000000000000000123456789abcdef。
前面提到了,对Nonce做一个小的修改,整个区块的哈希值就会面目全非。记账工需要不断尝试穷举不同的Nonce值,最终才会找到一个符合要求的哈希值。
挖矿指的就是寻找这个Nonce值,不断运算哈希函数
所以当一个记账工广播出自己记录的区块的时候,其他记账工会去验证这个区块的哈希是否符合要求,符合要求了,则说明该记账工确实付出了一定的工作量,然后其他没计算出该块Nonce的记账工就会乖乖停下当前的工作,投入到下一个区块的Nonce计算,这时候就初步达成了共识。
这就是矿工追求高性能矿机的原因,是为了能够更快地计算出这个Nonce值。
各种矿卡的出现,让内存、显存颗粒价格升高,让需要升级电脑配置的同学深恶痛绝(恨)。
现在已经没有哪个单独的矿机能挖到矿了,而是一个个矿机联合起来的矿池进行挖矿,然后根据算力贡献再把收益分配到矿池内的其他矿机。矿池相当消耗电力资源,所以都会选择搭建在电力成本较低的地方。
但是也总会有某两个记账工都计算出了自己打包区块的Nonce值,这时候需要如何去裁决?这个问题先暂时放着,我们先利用哈希函数这个利器来解决另一个问题。
防止篡改历史数据
因为人人拥有了本地账本数据的读写权利,他们可以任意修改历史交易数据。一些人可能会勾结起来,修改账本,混淆视听。
根据前面哈希函数得出的推论二:一个区块被改变,它的哈希值也会发生变化,我们是不是可以利用哈希值用于判断是否被篡改?
所以这个系统约定,记账工在进行当前区块的哈希计算的时候,需要把上一个区块的哈希值也加入到本区块的数据一起进行哈希运算,这时候各个区块算是真正意义上的“链”起来了。
所以某个人若想修改某个历史区块的交易数据,一环扣着一环,后续的区块的Nonce也就得重新计算了。
这个作弊的成本远远高于收益,你有这算力,还不如去老老实实打包新的区块。根据博弈论,应该没有哪个蠢货会在没有足够的算力的时候想要去修改历史数据了。正常情况下这个系统参与节点越多,就越难出现一个掌握全网51%算力的集权者,发动“51%攻击”(此处等一个量子超算机的问世,看看能不能打破算力平衡)。但是如果不是出自于对这个系统的极度厌恶,为什么要去篡改数据呢?篡改了以后这个系统的信任度急剧下降,人们纷纷弃用这个系统,篡改者也没有什么收益了。
防止作弊的方式,不同的共识机制有很多种类,后续再讨论,但是核心都是让作弊的损失大于收益,从而规避作弊。
区块选择问题
再次回到刚刚说到的,多个记账员计算出自己的区块的Nonce后的仲裁问题。
让我们想一个场景:在食堂一个窗口排队,有两个人同时到达,难分前后,于是他们决定并排站在一起。这时候就看后面的人愿意站到哪个人身后了。如果没有规则约束,后续的分叉可能会越来越多。这时候为了能正常吃上饭,大家达成又一个共识,就是自觉排到最长的那个队伍里去,其他短分叉就重排。这样一来随着时间的流逝,总会随着某个人的加入队伍,产生出一条最长的队伍。后续进来的人,自然认为该条队伍是最可能可以吃上饭的,所以自然会选择排到那个最长的队伍后面。
同样的,出现了若干个区块近乎同时出现的情况下,决定权就在后续的记账员愿意选取哪个区块的哈希值作为下一个区块Nonce的计算了,总会出现一条最长的分支,短的分支会逐渐被废弃。
当掌握超过全网一半算力时,从概率上就能控制网络中链的走向。这也是所谓 51% 攻击的由来。 ——《区块链技术指南》
所以这个仲裁的过程需要时间,这意味着一个交易被最终确认,也需要一定的时间。
比特币区块链中,当某个分叉点后率先达到6个区块时(约耗费60分钟),因为先前的算力消耗以及共识规则,从概率学的角度可以保证这条链几乎不会被废弃了,即可确认该分叉点的交易达成。
所以比特币并不适合用于高并发的交易。但对于那种手续繁杂,持续数天以上的跨国交易来说,这个确认时间已经大大缩短了。
动态调节区块生成速度
如果区块生成的速度过快,那么就越容易产生分叉,容易造成多余分叉上算力的浪费;如果区块生成的速度越慢,就越难产生分叉,但是这个区块进行哈希计算,消耗的算力也越多。归根到底都是费电。
而控制区块的产出速度,也有利于整个系统的正常货币发行,避免高性能设备的加入,让整个区块产出速度失衡。
所以需要做一个权衡,让这个区块产生的速度在一个相对合理的时间。
比特币区块链目前一个区块产生的时间大约在10分钟左右
前面说到记账员需要调整Nonce计算出一个低于某目标值Target的哈希值,才能让区块被承认。我们可以调节这个目标值,从而实现区块的生成速度。调的越小,那么符合要求的区块哈希值越难被计算出来,区块产生的速度就越慢了。
所以我们在区块的头信息力再加入一个数据,叫做难度系数 Difficulty。这时候 Target = 某个常数/Difficulty 。难度系数越大,目标值越小,Nonce就越难被计算出。随着产出速度,我们对Difficulty进行调整,则可以控制整个系统的区块产出速度在一个合理范围。
比特币中难度系数随着每2016个区块生成而调整一次,按10分钟一个区块的速度大约在两周的时间。每次调整时候会计算前两周的区块平均生成速度,如果比预想的快10%,那么难度系数提高10%,慢10%,那么难度系数降低10%
在前面讲到的区块选择问题上,比特币中不仅仅参考分叉链条的长度,也会参考分叉链条的难度系数。总之就是会选择消耗了最多算力的那条链,作为延伸的主链
战术总结
感觉开了个很大的坑,还有很多东西没有说清楚,先暂时写这么多吧。之后看情况要不要接着更咯。