今天,爬取一个简单的网站,为啥说简单呢?粗略看去,网站没用post方法就能得到页面,而且分页非常简单,直接替换数字就可以。本来觉得非常easy的,等进了详情页后发现,它的内容搞了一个js加密,不能直接用xpath取数据。但是这样用啥用呢?没用减轻服务器的负担,限制爬取,顶多增加了获取数据的难度。
我们先看下这个网站,名字叫上海法院网。
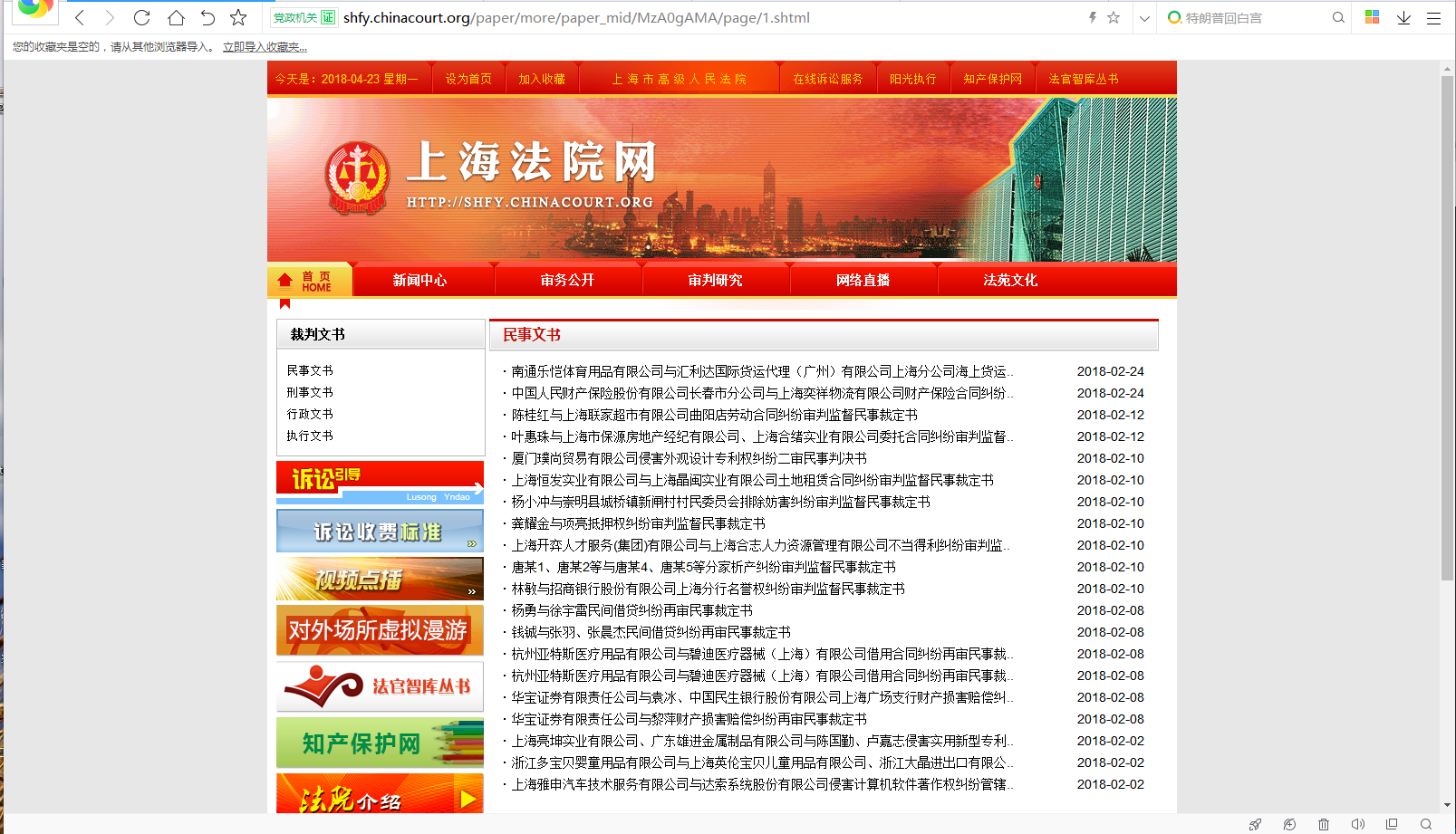
很容易就看出它是get,分页也是简单得数字,非常轻松就能拿到列表页中的标题、url、发布日期。
点击进去,可以看到详情页。

审查元素,一切似乎很简单,各个类型的数据包括正文都能用xpath定位。

用scrapy shell试试,问题就出来了,上面显示的数据根本取不到。审查源码,就发现了问题。

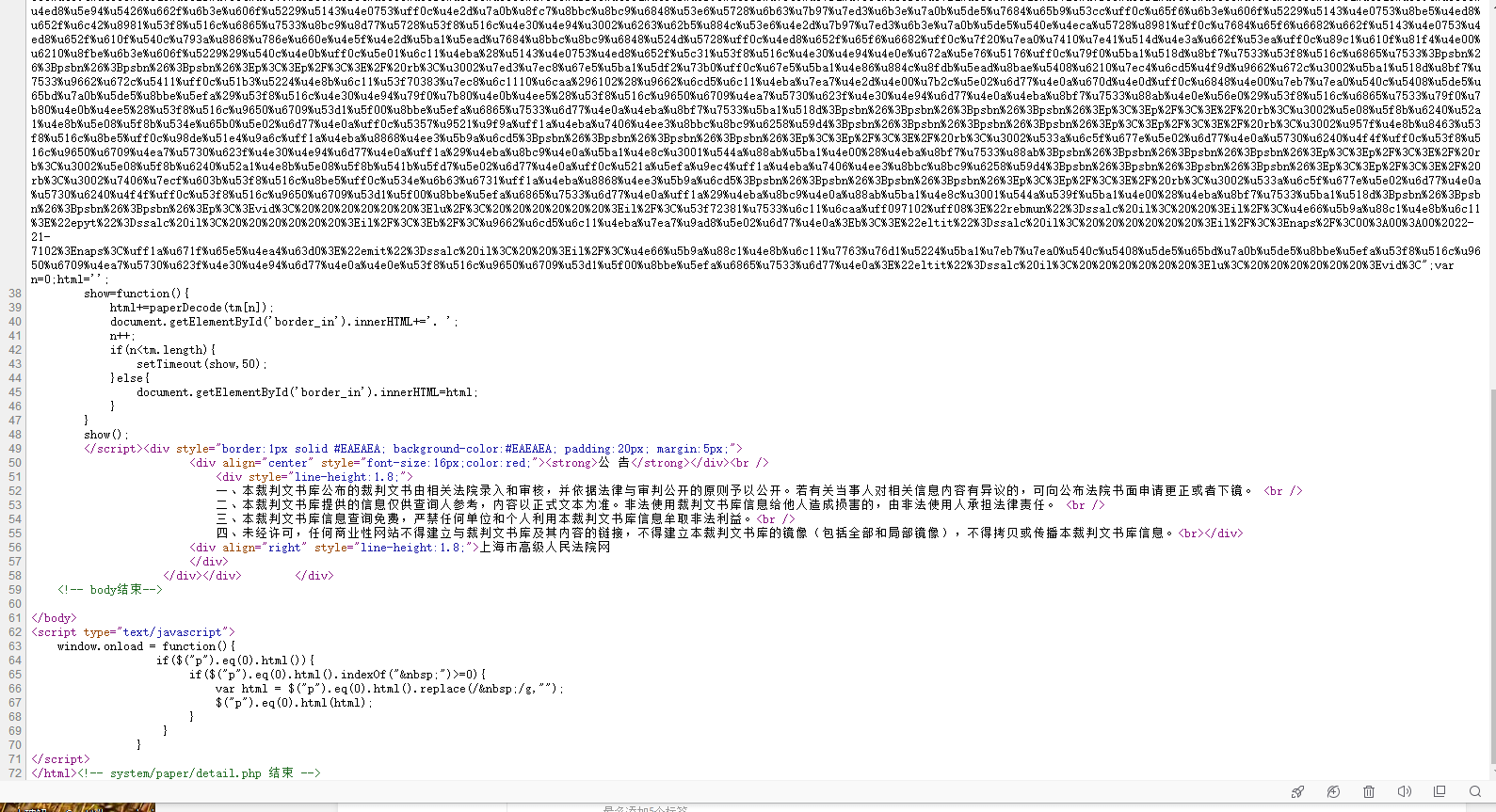
网页源码中并没有数据,而是出现了一堆字符串,没有明显的意思。看下js,是被加密了,真是。。。
没想到这样一个简单得网站,也开始搞js加密。好,就让我们相互伤害吧!
看到这种情况,反而激发了我破解的兴趣。很容易看出,它的解码js。
我们点进去看。

又是一段字符串。。。
这种情况,看不出函数是哪个,不能和之前一样直接用pyv8调用。所以,我下载了一个nodejs,nodejs可以直接运行js代码,比pyv8使用python间接调用要好一点。
运行一波,得到了输出结果。
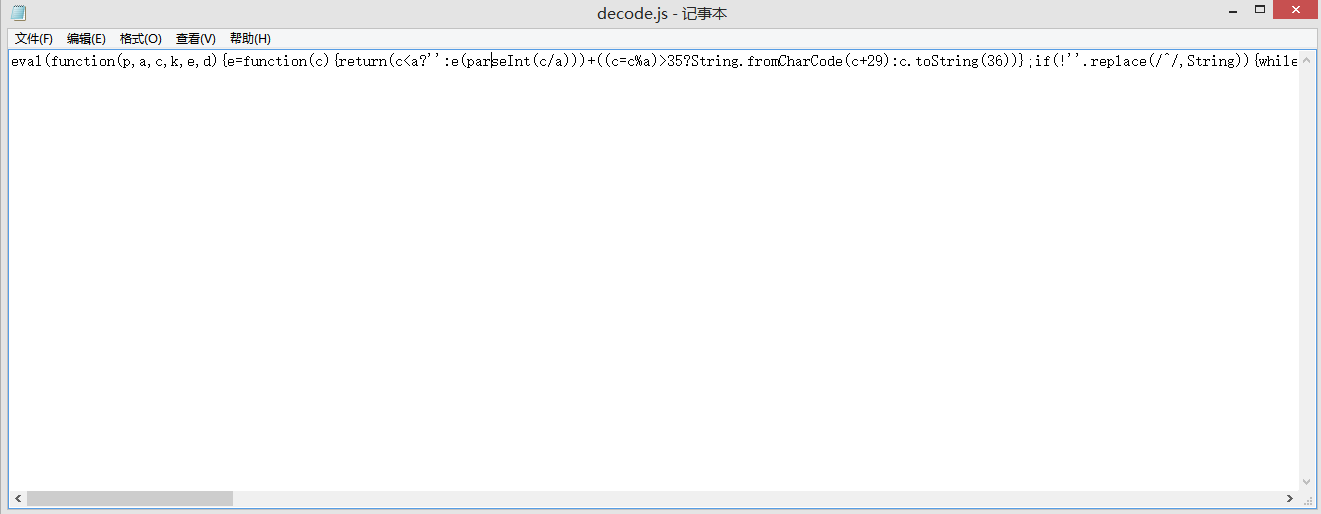
还是一堆字符串。。。再输出一次。
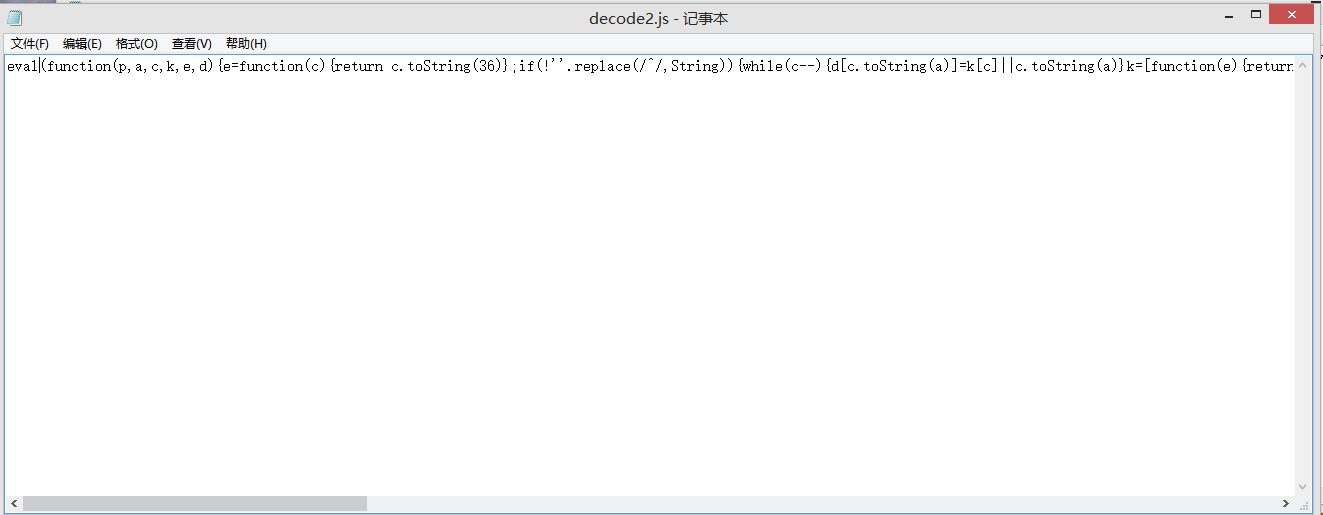
厉害了,还是eval,接着继续上边的操作,终于得到了一个可以看的js。注释掉document,加上原有页面的js。我们得到了一个新的可以在本地运行的js。
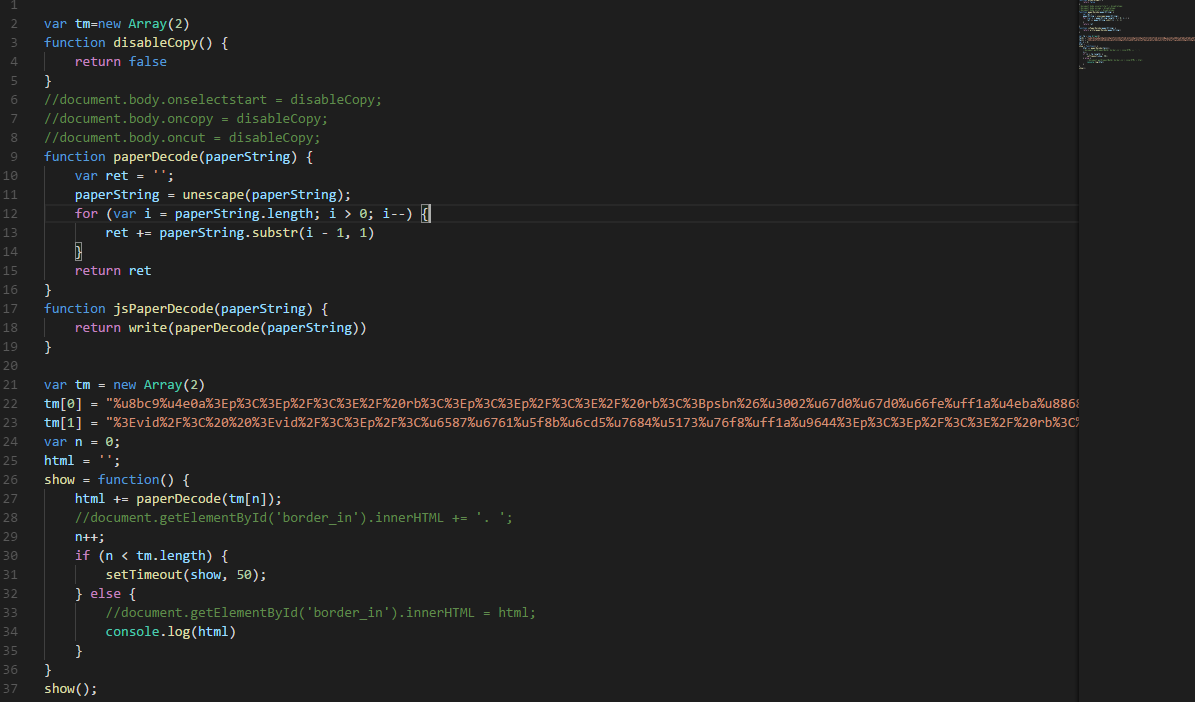
再次用node运行,就得到了想要的数据。

这样就得到了结果,总的来说,这个破解过程还是比较顺利的,因为比起随便几千几万行、混淆加密的js,这个还是比较清晰,比较简单。没学过js,也可以破解。
不过,深入学习爬虫技术,精通js已经越来越急迫,越来越重要了。