1.自有度调整复决定系数
设
为调整的复决定系数,
为样本量,
为自变量的个数,则
在一个实际问题的回归建模中,自由度调整复决定系数 越大,所对应的回归方程越好。从拟合优度的角度追求最优,则所有回归子集中 最大者对应的回归方程就是最优方程。
代码实现如下:
data3.1<-read.csv("C:/Users/Administrator/Desktop/data3.1.csv",head=TRUE)
library(leaps)
exps<-regsubsets(y~x1+x2+x3+x4+x5+x6+x7+x8+x9,data=data3.1,nbest=1,really.big=T)
expres<-summary(exps)
res<-data.frame(expres$outmat,调整R平方=expres$adjr2)
res
解释:
第3行调用regsubsets函数式对数据做所有子集(除了全模型)回归分析,共有
个变量子集的模型回归结果,并将结果赋给exps,回归结果中计算了
的值。
其中nbest可以任意赋大于等于1的值
,其主要用于展示包含不同变量个数(1个、2个或多个解释变量)的子集的前
个最佳模型。假如本例中,nbest=3,结果中间首先展示3个最佳的单解释变量的模型,然后展示3个最佳的含有两个解释变量的模型,以此类推,直至展示3个最佳的包含8个解释变量的模型。当nbest=126时,将显示所有的回归子集,但不包含全模型。
输出结果:

根据上面的输出结果可知,依据
准则选出的最优子集为
,同时也可以看出包含变量
的子集回归模型的
取值与最优子集回归模型的
差别很小。如果仅考虑
这一个准则时,则
为最优子集,但是实际应用中应该考虑几个准则来确定最优子集。
2. 统计量
1964年马洛斯从预测的角度提出可一个可以用来选择自变量的统计量,这就是常说的
统计量。根据选模型预测的均方误差比全模型预测的方差更小的性质,也可以知道即使全模型正确,但仍有可能选模型有更小的预测误差。
正是根据这一原理提出来的。
式中,
,为全模型中
的无偏估计。
这样我们就得到一个选择变量的
准则:选择使
最小的自变量子集,这个自变量子集对应的回归方成就是最优回归方程。
代码实现如下:
data3.1<-read.csv("C:/Users/Administrator/Desktop/data3.1.csv",head=TRUE)
library(leaps)
exps<-regsubsets(y~x1+x2+x3+x4+x5+x6+x7+x8+x9,data=data3.1,nbest=1,really.big=T)
expres<-summary(exps)
res<-data.frame(expres$outmat,Cp=expres$cp)
res
输出结果如下:
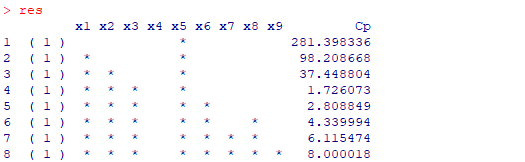
由以上输出结果可知,依据
准则选出最优的子集为
,而且
与其他7个子集所对应的
的取值均有明显差异。
因此,综合
和
的输出结果,我们可以选择包含变量
的回归模型作为最优子集回归模型。