进程的定义
用通俗的话来讲,进程就是出于执行期的程序,当然一个程序不仅仅包含代码(Text section),它还包含其他的资源,比如数据,打开的文件,挂起的信号等等。一个进程就是上述所以内容的集合体。
线程的定义
通常为了让一个进程中也能够支持多个任务的并发执行(其实是调度器在调度),有了线程的概念(写过 Linux C 的都知道 pthread 吧),线程是进程中的活动对象,只不过线程是被囊括在一个进程之内(这里特指用户程序的线程),他能够共享到进程的资源。
进程的描述
在 Linux 内核中,进程使用一个结构体来对一个进程进行描述,那就是大名鼎鼎的 task_struct 了
内核吧进程的列表存放在叫做任务队列(task list)的双向循环链表中,链表中的每一个元素都是一个 task_struct ,称之为进程描述符。它包含了一个进程的所有信息。
task_struct 相对较大,在 32-bit 的机器上,大约有 1.7KB

该结构体巨大,这里就不贴出来了,有兴趣的伙伴可以自行查阅 Kernel 代码(include/linux/sched.h)
进程描述符的分配与放置
当创建一个进程的时候,需要为一个进程分配它的 task_struct 描述符,Linux 系统使用 slab 分配器管理 task_struct 的分配和释放(Slab 分配器在以后的内存管理部分分析,现在只需要知道是一种 Kernel 针对防止产生页内内存碎片的一种小数据的内存分配机制即可)
那分配后的 task_struct 放置在什么地方呢?为了快速访问到当前进程的 task_struct 结构,Linux 将其放置到了内核栈的栈底。如图所示:
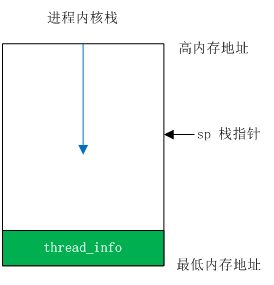
这个 thread_info 又是什么东东呢:
/*
* low level task data that entry.S needs immediate access to.
* __switch_to() assumes cpu_context follows immediately after cpu_domain.
*/
struct thread_info {
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0 => bug */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
__u32 cpu; /* cpu */
__u32 cpu_domain; /* cpu domain */
struct cpu_context_save cpu_context; /* cpu context */
__u32 syscall; /* syscall number */
__u8 used_cp[16]; /* thread used copro */
unsigned long tp_value;
struct crunch_state crunchstate;
union fp_state fpstate __attribute__((aligned(8)));
union vfp_state vfpstate;
#ifdef CONFIG_ARM_THUMBEE
unsigned long thumbee_state; /* ThumbEE Handler Base register */
#endif
struct restart_block restart_block;
};看到了么,其中有一个成员,叫做 task,这个就是进程的描述符啦,所以呢,获得这个结构的首地址,就能够访问到进程的描述符了。这个 thread_info 被放置到了内核栈的尾巴上,那么怎么获取到这个玩意的地址呢?莫慌,请看下面,先插入一条,聊聊内核栈。
内核栈
每个进程都有自己的内核栈,用户空间有他自己的栈,到了内核,使用的是内核栈。比如,一个用户空间的进程,使用了 system call 进入了内核空间,那就用了内核栈了。内核栈一半都很小(相比用户空间的栈),使用宏 THREAD_SIZE 来表示。我看到的这个版本是 8KB:
#define THREAD_SIZE 8192好了,现在知道内核栈的大小为 8KB,那我们怎么去将心仪的玩意搞到手呢(thread_info),如此即可:
static inline struct thread_info *current_thread_info(void)
{
register unsigned long sp asm ("sp");
return (struct thread_info *)(sp & ~(THREAD_SIZE - 1));
}首先通过汇编,获取到了 sp,也就是堆栈指针,然后搞了一个运算 (sp & ~(THREAD_SIZE - 1)),这个 THREAD_SIZE 是 8KB,减去1,也就 0x1FFF,低 12bit 全 12'b0001_1111_1111_1111,其实是什么意思呢?就是一个正在运行的内核态的程序,取出他的任何 sp,然后根据 8KB 的边界,MASK 掉低位,不就直接得到了尾巴了吗。
所以,这个 API 就可以得到当前运行进程的 thread_info,通过 current_thread_info()->task 进而得到进程描述符 task_struct 了
进程的状态
TASK_RUNNING —— 进程是可执行的,或者正在执行或者在运行队列中等待执行
TASK_INTERRUPTABLE —— 可中断,此刻进程在睡眠,等待某些事件达成后,进入可执行状态,此刻进程能够接收到信号被提前唤醒,随时准备工作。
TASK_UNINTERRUPTABLE —— 不可中断,此刻进程在睡眠,不可被信号唤醒,只能等待期望的事件达成(使用少)
__TASK_TRACED —— 被其他进程跟踪,例如 ptrace
__TASK_STOPPED —— 进程停止执行,进程没有投入运行也不能投入运行,通常是收到 SIGSTOP,SIGTSTP,SIGTTOU 等信号时刻,此外在调试期间,收到任何信号,都会进入这种状态。
进程的创建
进程通过 fork 和 exec 调用来进行创建。
fork 通过拷贝当前进程创建一个子进程,区别在于 PID
exec 负责读取可执行文件,并载入地址空间开始运行
对于 fork 这种方式,Linux 出于效率的考虑,并没有在实现的时候直接复制所有信息, 而是使用了一种叫做写时拷贝(copy-on-write,COW)。内核并不复制整个进程地址空间,只有在需要写入的时候,数据才会复制。
fork 是通过 clone() 系统调用来实现的,然后 clone 又去调用 do_fork (kernel/fork.c)
在 do_fork 中调用 copy_process 函数创建一个新的 task_struct 描述符
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*/
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
.......
p = copy_process(clone_flags, stack_start, regs, stack_size,
child_tidptr, NULL, trace);
.......
}而在 copy_process 中进一步调用 dup_task_struct 来获得了 task_struct
/*
* This creates a new process as a copy of the old one,
* but does not actually start it yet.
*
* It copies the registers, and all the appropriate
* parts of the process environment (as per the clone
* flags). The actual kick-off is left to the caller.
*/
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
int cgroup_callbacks_done = 0;
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
/*
* Thread groups must share signals as well, and detached threads
* can only be started up within the thread group.
*/
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* Shared signal handlers imply shared VM. By way of the above,
* thread groups also imply shared VM. Blocking this case allows
* for various simplifications in other code.
*/
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
/*
* Siblings of global init remain as zombies on exit since they are
* not reaped by their parent (swapper). To solve this and to avoid
* multi-rooted process trees, prevent global and container-inits
* from creating siblings.
*/
if ((clone_flags & CLONE_PARENT) &&
current->signal->flags & SIGNAL_UNKILLABLE)
return ERR_PTR(-EINVAL);
retval = security_task_create(clone_flags);
if (retval)
goto fork_out;
retval = -ENOMEM;
p = dup_task_struct(current);
if (!p)
goto fork_out;
.......
}在 dup_task_struct 中,为新的进程创建了内核栈,thread_info,task_struct 并这些值保持和当前的值一样。
然后,将许多的成员都清 0,并调用 alloc_pid() 分配一个 PID,其他更加细节的内容,读者可以自行的看 source code,这里不列举。
fork() --> clone() --> do_fork() --> copy_process() --> dup_task_struct()
线程的实现
前面说了,线程其实和进程共享了一些资源,内核其实把线程当成是一个进程来对待(包括调度,也用 task_struct 来描述),内核看起来,就像是普通的进程一样(一些标志不一样)。
创建线程的时候,和创建进程类似,只不过在调用 clone 的时候,传入了一些参数标志:
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND,0);
这个和普通的 差不多,只是共享了地址空间、文件系统资源、文件描述符、信号处理程序。
内核线程
内核进程需要在后台执行一些操作,这种任务可以通过内核线程(kernel thread)完成。它与普通的线程的区别在于,没有独立地址空间。也就是 task_struct 的 mm 指针为 NULL,他们只在内核空间运行,能被调度和抢占。比如,flush,ksoftirqd等等。
对于内核线程没有自己的独立地址空间的这个说法,具体的理解为:
用户空间:不同进程的线性地址操作虽然仍是统一的,但物理地址却因为独立地址空间的缘故而映射不一致,乃至于影响不到其他进程的资源。独立的地址空间意味着数据修改的彼此独立性,即严防不同进程之间干扰。这符合“进程是系统资源分配的最小单位”的要求。
内核空间,所有线程虚拟地址对应的物理地址都是一样的, 所以说是共享。
打个比方:
A,B为用户进程,C为内核线程。那么,A,B进程的0-3G的线性地址空间是相互独立的,而 C 并独立属于自己的地址空间,它的地址空间在 3G~4G 的地方,这部分是 A,B,C都共享的,所以 C 不能称之为有独立的地址空间。
内核线程通过函数 kthread_create 来创建(我看到的这个版本是 kthread_create_on_node 函数,是不是看上去很熟悉?):
struct task_struct *kthread_create_on_node(int (*threadfn)(void *data),
void *data,
int node,
const char namefmt[],
...)
{
......
}
其中 threadfn 是内核线程的执行函数,data 是传递给 threadfn 的入参,node 是内存节点(NUMA 体系),namefmt 是线程名称。通过这个 API 创建的内核线程不会马上工作,出于一个待唤醒的状态,如果希望其工作,还需调用 wake_up_process 唤醒它才行。
这里内核实现了一个函数 kthread_run 来执行上述两条命令,即调用了这个 kthread_run 函数,内核线程便会立马运行了,它的实现也就是顺序 call 了 kthread_create 和 wake_up_process 。
使用 kthread_stop 来退出。